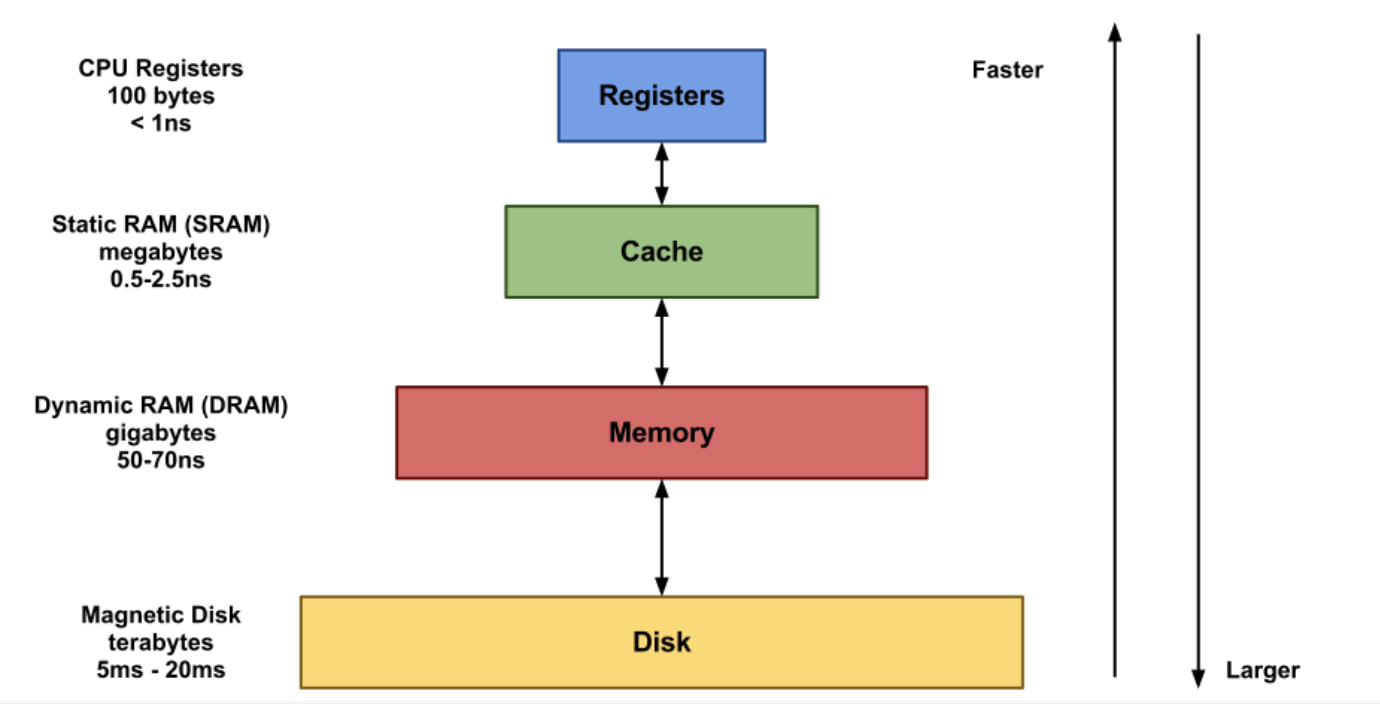
캐시 메모리(Cache Memory)
CPU는 메모리와 계속해서 데이터를 주고 받으며 처리한다. 하지만 CPU의 처리 속도는 매우 빠르고 그에 비해 메모리의 처리 속도는 느리기 때문에 효율적이지 않다.
캐시 메모리는 CPU와 메인 메모리의 중간 버퍼 역할을 하며 CPU와 메모리의 속도 차이로 인한 병목 현상 을 최소화하는 역할을 한다.
캐시 메모리의 동작
- CPU는 메모리에 데이터를 요청하기 전에 캐시 메모리에 접근하여 데이터의 존재 유무를 확인한다.
- 만약, 캐시 메모리가 해당 데이터를 가지고 있다면
Cache Hit라고 칭하며 데이터를 빠르게 전송해줄 수 있다. - 캐시 메모리에 해당 데이터가 없다면 CPU는 메인 메모리에 접근하여 데이터를 요청한다. 이것은
Cache Miss라고 칭한다.
내부 탐색
캐시 메모리는 데이터를 탐색하고 관리하기 위해 데이터 메모리와 태그 메모리를 사용한다.
블록: 데이터의 기본 단위인 워드의 집합데이터 메모리: 메모리의 데이터들이 저장된 블록으로 구성되어 있다.태그 메모리: 데이터 메모리의 블록을 탐색할 정보를 포함한다.
태그 메모리의 엔트리는 데이터 메모리 블록과 쌍을 이루면서 태그, 유효 비트, 갱신 비트를 포함한다. 또한 CPU 주소와 태그를 비교하는 비교기를 가지고 있다.태그(tag): CPU가 요청한 데이터를 탐색하는데 사용할 주소의 일부. 캐시 블록 주소에서 인덱스로 사용되지 않는 부분이다.유효 비트(valid bit): 캐시 블록이 유효한 데이터인지 나타낸다.갱신 비트(dirty bit): 캐시로 블록을 가져온 후 CPU가 블록을 수정했는지 나타낸다.
- CPU가 캐시 메모리에 주소를 전송한다.
- 태그 메모리에서 탐색한다.
- 일치하는 태그를 발견한다면
Cache Hit, 데이터 메모리에서 블록을 추출한다. - 일치하는 태그를 발견하지 못한다면
Cache Miss, 주소를 메인 메모리로 전송하여 대응하는 블록을 캐시에 저장한다.
- 일치하는 태그를 발견한다면
- 데이터를 선택한 후 CPU가 요청한 데이터를 캐시가 전송한다.
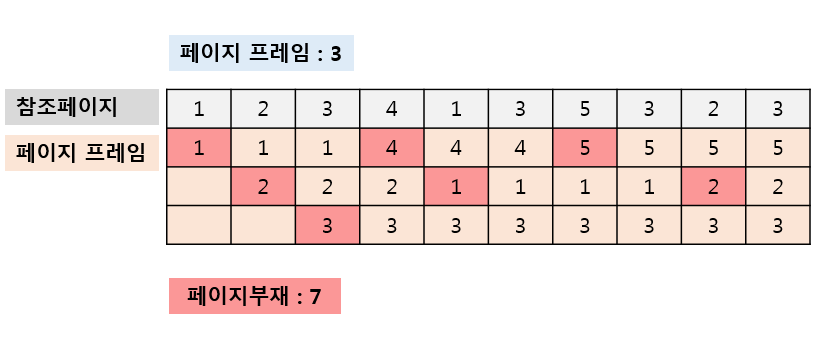
캐시 교체 알고리즘
LRU(Least Recently Used)- 캐시 내에서 가장 오랫동안 사용되지 않은 블록을 교체한다.FIFO(First In First Out)- 캐시 내에서 가장 오랫동안 존재한 블록을 교체한다.LFU(Least Frequency Used)- 가장 적게 참조된 블록을 교체한다.RR(Round Robin)- 공평하게 돌아가면서 블록을 교체한다.Random- 무작위로 블록을 교체한다.
LRU(Least Recently Used) 대체적으로 사용된다.
LRU(Least Recently Used) 알고리즘
쓰기 정책
Write Through- 데이터 변경 시 캐시와 메모리에 곧바로 기록한다. 구현이 쉬우며 일관성 문제가 발생하지 않는다. 잦은 쓰기로 속도가 느리다.Write Back- 캐시에 먼저 기록하고 메모리엔 나중에 기록한다. 속도가 빠르지만 일관성 문제가 발생 가능성이 있다.
HashMap과 LRU
Hash는 임의의 key 값을 해쉬 함수를 사용하여 고정 길이로 변환하고 버킷의 주소 값으로 연결한다.
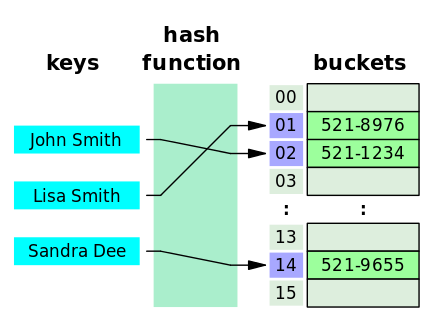
해쉬 함수 덕분에 많은 데이터들을 탐색하지 않더라도 value 값에 도달할 수 있다. 평균 시간복잡도는 O(1)이다.
하지만 데이터의 충돌이 발생하기도 한다. 비둘기집 원리에 의해서 해시 함수의 결과값이 중복되는 경우도 발생하고 이를 해시 충돌이라고 한다.
비둘기집 원리는 n+1개의 물건을 n개의 상자에 넣을 때 적어도 어느 한 상자에는 두 개 이상의 물건이 들어 있다는 원리를 말한다.
OverFlow
결과값을 저장하는 버킷(buckets)의 공간도 정해져있다. 여러 개의 키 값이 하나의 버킷을 가리키는 경우가 발생하기도 하며 정해진 공간보다 초과할 경우 모든 데이터를 저장할 수 없게 된다.
즉, 해시 함수를 효율적으로 작성하여 데이터가 집중되는 것을 최소화하여 효율성을 높여야 한다.
그에 반해 LRU는 Linked List를 사용한다. 일정한 공간 내에서 가장 오랫동안 사용되지 않는 데이터를 교체하기 때문에 Hash 처럼 원치 않게 Overflow 되는 경우는 없다. 하지만 특정 데이터를 추출하기 위해 많은 데이터를 탐색해야 한다. Linked List 탐색의 평균 시간 복잡도는 O(n)이다.
