가정
본 글의 독자는, 기존의 JPA에서 IDENTITY 전략 사용시, bulk insert가 되지 않는 한계점에 대해 이해하고 있다고 가정한다.
모델
엔티티 모델은 다음과 같다.
@Entity
@Table(name = "parents")
@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Parent {
@Id
@Column(name = "parent_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
@Column(name = "random_uuid", columnDefinition = "BINARY(16)")
private UUID randomUUID;
@OneToMany(fetch = FetchType.LAZY, mappedBy = "parent")
List<Child> children = new ArrayList<>();
public void identifyParent(UUID randomUUID) {
this.randomUUID = randomUUID;
}
}@Entity
@Table(name = "children")
@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Child {
@Id
@Column(name = "child_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
@JoinColumn(name = "parent_id")
@ManyToOne(cascade = CascadeType.ALL)
private Parent parent;
public void updateParent(Parent parent) {
this.parent = parent;
parent.getChildren().add(this);
}
}
문제상황
JPA의 bulk insert 사용 제약으로 인해, jdbc를 이용하여 bulk insert를 진행하려 한다.
이때, 단순히 M개의 row를 insert하는 것이 아닌, 각각 N개의 1대 다 연관관계를 갖고 있는 row를 M개 삽입하는 상황이다.
말로 풀어서 설명하려니, 모호하다. 예시를 살펴보자.
부모 엔티티(이하 Parent)와 자식 엔티티(이하 Child)가 1:N(여기서 N은 3이라고 가정) 연관관계를 갖고 있다.
이때, 한 건의 요청을 받아, 3개의 Child와 매핑되는 1개의 Parent를, 총 2개 영속화 시켜야 하는 상황을 떠올려 보자.
아래와 같은 요청이 들어올 것이다.
(Parent : 2개,
Child: 6개 (하나의 Parent당 Child가 3개씩 매핑)
-> 총 2개의 Parent, 6개의 Child)
{
"request": [
{
"parentName": "parent1",
"childNames": [
"child1",
"child2",
"child3",
]
},
{
"parentName": "parent2",
"childNames": [
"child4",
"child5",
"child6"
]
}
]
} 나의 지금까지의 경험으로는, 단순히 N개의 row만 bulk insert만 해 보았다.
위의 요청대로라면, (Parent M개 + M개에 매핑된 N개씩의 Child)를 저장할 때, 쿼리 호출 횟수를 최소화 하기 위한 bulk insert를 고려해 봐야 한다.
플로우 정립
먼저, 최악의 해결방법을 살펴보자.
- 각 parent마다 Child와 연관관계를 맺어, JPARepository.saveAll();을 호출한다. -> 총 8건의 단건 insert 쿼리 발생








위에서 볼 수 있듯이, jpaRepo의 saveAll은 각각의 entity마다 단건 insert 쿼리가 발생하기 때문에, 정말 좋지 않다.
따라서, 앞서 떠올려 본 (Parent M개에 매핑된 N * M개의 Child)를 bulk insert하기 위해, 다음과 같은 거시적인 플로우를 따른다.
1. Parent N개 bulk insert
2. Parent insert 이후 채번된 Parent의 id를 가지고, 각각의 Parent에 매핑되는 Child의 FK에 Parent id를 세팅한다.
3. 이후, N * M개의 Child를 bulk insert
2번 항목에서 어려운 점이 두가지 있다.
1. Parent insert 이후 jdbc를 이용해 채번된 Parent id는 어떻게 찾아 올 것이며,
2. 채번된 Parent id를 가져오더라도, 각각의 Parent에 매핑되는 Child는 어떻게 찾아 올 것인가?
이와 관련하여 선례를 찾아보니, 향로님의 블로그에서 힌트를 얻을 수 있고, 향로님의 플로우는 다음과 같다.
✅ 향로님의 플로우 요약
-
Parent(Entity A)에 UUID와 같은 유니크 컬럼을 추가하고, 애플리케이션에서 직접 생성하여 세팅한다.
-
Parent와 연관된 Child(Entity B)를 객체 간 연관관계로 설정해둔다.
-
<UUID, Parent> 형태의 Map을 구성한다.
-
QueryDSL의 EntityQL을 사용하여 Parent를 bulk insert한다.
-
executeWithKeys()를 통해 insert된 Parent의 DB 채번 ID들을 가져온다.
-
ID 리스트로 Parent를 다시 조회하여, UUID와 채번된 ID를 모두 갖는 객체를 얻는다.
-
조회된 UUID를 기준으로 Map에서 원본 Parent 객체를 찾아 연관된 Child 목록을 획득한다.
-
Parent와의 관계가 설정된 Child 리스트를 한 번에 bulk insert한다.
위의 플로우를 조금 수정하여, 나는 다음과 같은 플로우로 구현을 진행할 것이다.(위의 4,5번 과정이 3번 하나로 압축되었다.)
✅ 이를 참고한 나의 구현 플로우
-
Parent에 UUID 컬럼을 추가하고, 애플리케이션에서 UUID를 직접 세팅하며, 연관된 Child 리스트도 함께 설정한다.
-
<UUID, List> 형태의 Map을 구성하여 각 Parent와 연관된 Child 리스트를 준비한다.
-
JdbcTemplate을 이용해 Parent를 bulk insert하고, KeyHolder.getKeyList()를 통해 채번된 ID 목록을 가져온다.
-
해당 ID 목록으로 Parent를 다시 쿼리하여, UUID와 ID가 모두 세팅된 영속 객체 리스트를 획득한다.
-
UUID를 기준으로 Map에서 연관된 Child 리스트를 꺼내고, 각 Child의 FK에 채번된 Parent ID를 세팅한다.
-
모든 FK가 세팅된 Child 리스트를 bulk insert한다.
✅ 요약
플로우가 조금 복잡해 보이지만,
결국 여러번 실행되던 insert 쿼리를
한번의 Parent list bulk insert
한번의 Parent list find
한번의 Child list bulk insert
위의 3개의 쿼리로 마친 것을 볼 수 있다.
(물론, bulk insert할 엔티티가 너무 많다면, 이때는 chunk단위로 나누어 bulk insert를 몇번씩 수행할 수 있겠다.)
실제 구현
향로님의 블로그에서는, 자세한 플로우 4,5번에서 EntityQL을 이용하는 것을 볼 수 있다.
하지만, EntityQL의 러닝커브를 감당하기 보다는, 다른 피쳐가 없을까 하다가, jdbc 진영에서 제공해 주는
KeyHolder라는 클래스를 발견했다.
docs를 읽어보니 JDBC insert 구문 이후, 채번된 key를 뽑아올 수 있는 클래스로 구현되어 있어,
나에게 알맞은 솔루션이라고 느껴져, 구현에 적용하였다.
세부적인 구현을 플로우 순서대로 서술하겠다.
1. 부모에 UUID같은, 유니크한 컬럼을 테이블에 추가한다.
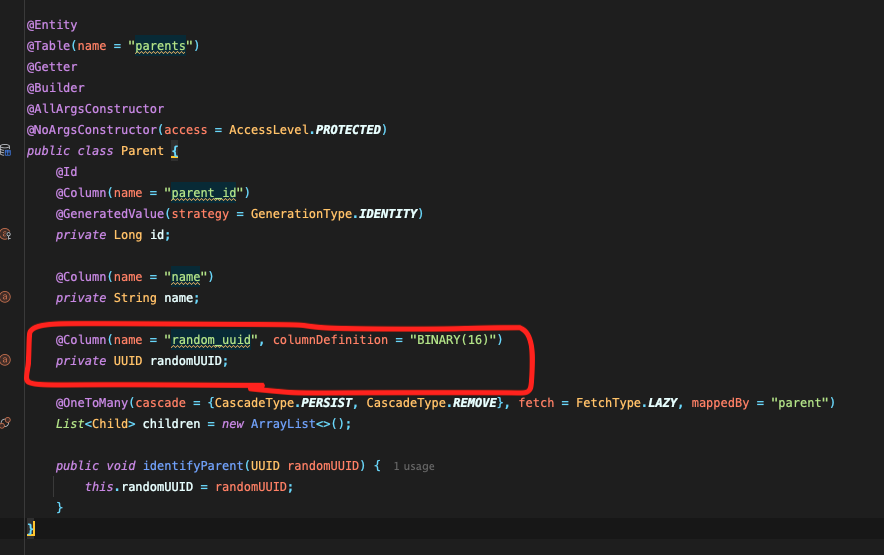
2. 이후, 어플리케이션 단에서 UUID를 생성하여 컬럼에 세팅해준다.(다른 기본 컬럼 또한 당연히 세팅한다. 특히, 자식 엔티티와 연관관계를 맺어놓는다.)
3. Map같은 컬렉션을 사용하여, <key, value>를 <부모의 UUID, List>로써 갖는 컬렉션을 생성한다.
List<Parent> parents = new ArrayList<>();
for (SaveParentAndChildRequestDto dto : childRequests) {
...
List<Child> children = new ArrayList<>();
Parent parent = Parent.builder()
.name(parentName)
.children(children)
.build();
for (String childName : childNames) {
Child child = Child.builder()
.name(childName)
.build();
children.add(child);
}
UUID randomUUID = UUID.randomUUID(); // 2. UUID 생성
parent.identifyParent(randomUUID); // 2. UUID 부모에 세팅
parents.add(parent);
childMap.put(randomUUID, children); // 3. UUID 에 매핑되는 Child List 컬렉션에 저장
}
return parents;4. Jdbc를 이용하여 부모 엔티티 bulk insert 이후, KeyHolder의 getKeyList() 메서드를 이용하여, 채번된 id를 가져온다.(List형태를 가져옵니다.)
KeyHolder keyHolder = new GeneratedKeyHolder(); // 4. 채번된 id를 가져올 KeyHolder 객체
jdbcTemplate.batchUpdate(
con -> { // 실제 bulk insert query
String insertQuery = "INSERT INTO parents(name, random_uuid) VALUES (?, ?)";
// Statement.RETURN_GENERATED_KEYS enum을 두번째 인자로 넘겨, 채번된 id를 받아올 수 있음
return con.prepareStatement(insertQuery, Statement.RETURN_GENERATED_KEYS);
}, new BatchPreparedStatementSetter() { // bulk insert query의 파라미터 매핑
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, parents.get(i).getName());
ps.setBytes(2, convertUUIDToBytes(parents.get(i).getRandomUUID()));
}
@Override
public int getBatchSize() { // bulk insert size
return parents.size();
}
},
keyHolder // KeyHolder 객체를 batchUpdate() 인자로 넣어주어, batchUpdate 이후 채번된 id를 KeyHolder 객체에 매핑
);
List<Map<String, Object>> keyList = keyHolder.getKeyList(); // bulk insert 실행 이후, 실제 채번된 id 가져옴
List<Long> ret = new ArrayList<>();
for (Map<String, Object> map : keyList) {
BigInteger generatedKey = (BigInteger) map.get("GENERATED_KEY"); // 채번된 id는 GENERATED_KEY라는 key값의 value로 존재
ret.add(generatedKey.longValue());
}
return ret;5. 4번에서 받아온 id list를 이용하여, 부모 list를 쿼리한다. (findAllbyIds() 메서드를 이용하여 쿼리한 이후, List를 반환합니다.)
parents = saveParentPort.findAllByIds(parentIds);6. 5번에서 쿼리한 Parent List는, 영속화 된 객체이므로 PK + UUID 둘다 온전하게 갖고 있는 엔티티이다.
따라서, UUID를 이용해 특정 Parent에 종속된 Child List를 map에서 찾아와, Child에 Parent의 PK를 세팅해 준다.(즉, Child의 FK가 세팅이 됩니다.)
// 6-1. 특정 Parent에 종속된 Child List를 map에서 찾아온다.
private List<Child> extractChildFromParents(
List<Parent> parents,
Map<UUID, List<Child>> childMap
) {
List<Child> insertChildList = new ArrayList<>();
for (Parent parent : parents) {
List<Child> childList = childMap.get(parent.getRandomUUID());
for (Child child : childList) {
child.updateParent(parent); // 6-2. Child에 Parent의 PK를 세팅한다(다대일 연관관계 매핑 진행)
}
insertChildList.addAll(childList);
} return insertChildList;
}7. 이후, 모든 FK가 세팅이 된 Child List를 bulk insert 한다.
public void bulkInsertChildren(List<Child> children) {
String insertQuery = "INSERT INTO children(name, parent_id) VALUES (?, ?)";
jdbcTemplate.batchUpdate(
insertQuery,
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, children.get(i).getName());
ps.setLong(2, children.get(i).getParent().getId());
}
@Override
public int getBatchSize() {
return children.size();
}
}
);
}bulk insert 적용 결과
-
parent bulk insert

-
parent select

-
child bulk insert

이슈
1. Child 중복 insert 이슈
쿼리 로그 일부
2025-05-13T10:44:29.556+09:00 INFO 20048 --- [nio-8080-exec-2] MySQL : [QUERY] INSERT INTO children(name, parent_id) VALUES ('child1', 11),('child2', 11),('child3', 11),('child4', 12),('child5', 12),('child6', 12)
2025-05-13T10:44:49.962+09:00 INFO 20048 --- [nio-8080-exec-2] MySQL : [QUERY] insert into children (name,parent_id) values ('child2',11)
Hibernate:
insert
into
children
(name, parent_id)
values
(?, ?)
2025-05-13T10:44:49.963+09:00 INFO 20048 --- [nio-8080-exec-2] MySQL : [QUERY] insert into children (name,parent_id) values ('child3',11)
Hibernate:
insert
into
children
(name, parent_id)
values
(?, ?)
2025-05-13T10:44:49.964+09:00 INFO 20048 --- [nio-8080-exec-2] MySQL : [QUERY] insert into children (name,parent_id) values ('child1',11)
Hibernate:
insert
into
children
(name, parent_id)
values
(?, ?)
2025-05-13T10:44:49.965+09:00 INFO 20048 --- [nio-8080-exec-2] MySQL : [QUERY] insert into children (name,parent_id) values ('child5',12)
Hibernate:
insert
into
children
(name, parent_id)
values
(?, ?)
2025-05-13T10:44:49.966+09:00 INFO 20048 --- [nio-8080-exec-2] MySQL : [QUERY] insert into children (name,parent_id) values ('child6',12)
Hibernate:
insert
into
children
(name, parent_id)
values
(?, ?)
2025-05-13T10:44:49.966+09:00 INFO 20048 --- [nio-8080-exec-2] MySQL : [QUERY] insert into children (name,parent_id) values ('child4',12)
이상한 점이 보이는가? 이미 bulk insert가 이루어 졌음에도,
다시 한번 children entity가 단건 insert가 되는 것을 볼 수 있다.
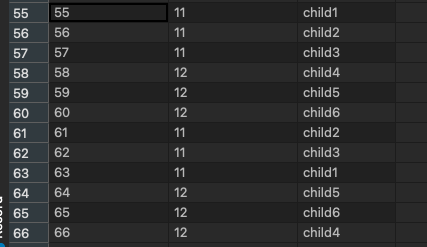
실제로 위의 사진과 같이, 6개만 저장되어야 할 child entity가, 12개 저장된 것을 확인할 수 있다.
이유는 무엇일까?
먼저 결론부터 설명하자면, @Transactional 어노테이션 때문이였다.

위의 사진처럼, batchUpdate()메서드가 아닌 executeUpdate() 메서드에 디버깅이 걸리는데, 이것이 Child 엔티티의 개수만큼 실행되고 있었다.
그 아래의 Stack trace들을 따라가보면 아래와 같다.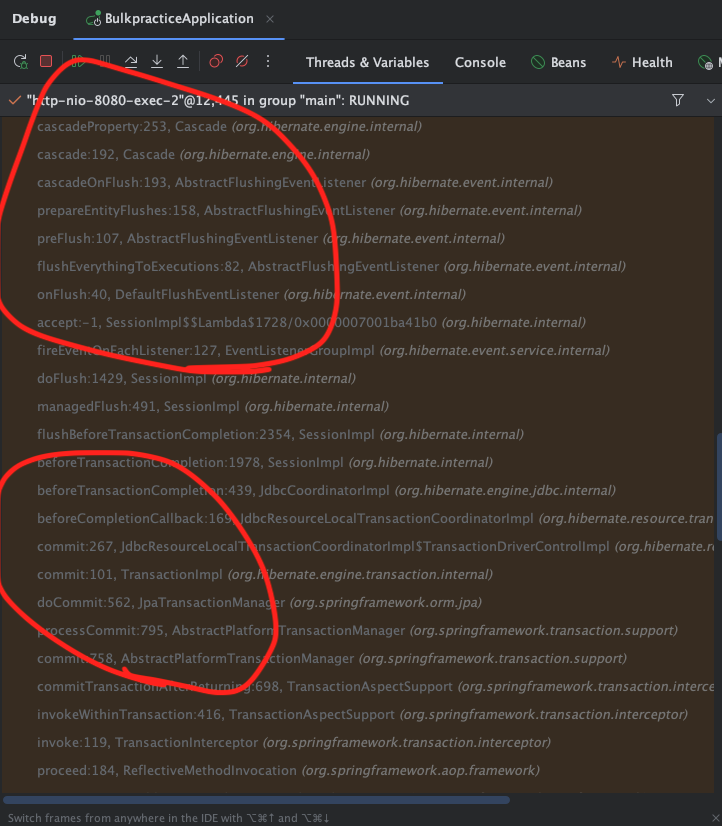
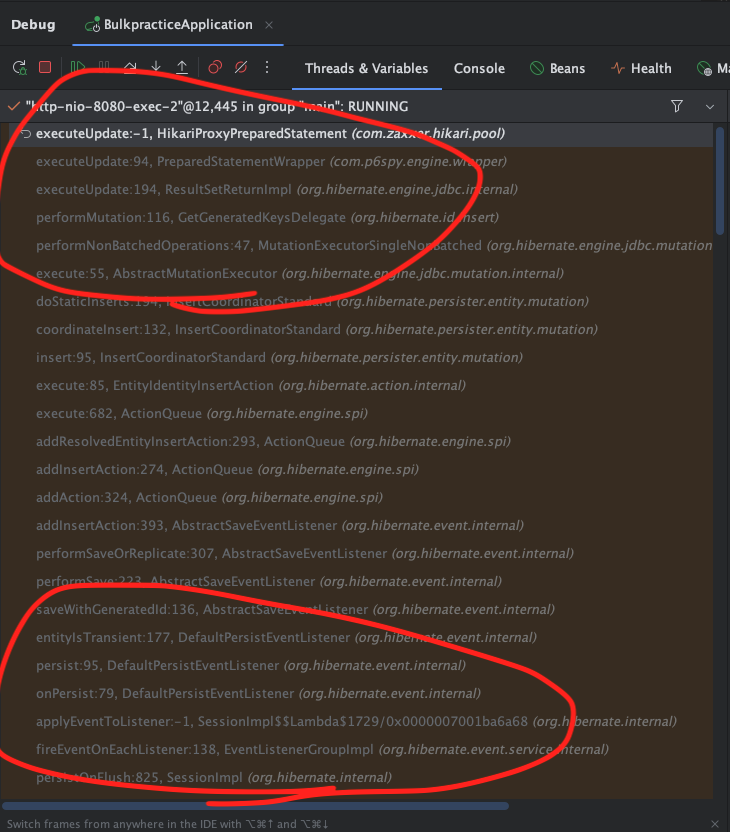
무수히 많은 hibernate 관련 메서드가 doCommit()메서드를 기점으로 실행되고 있었다.
그렇다면, @Transactional 어노테이션을 제거하고 Stack trace를 살펴보면 어떨까?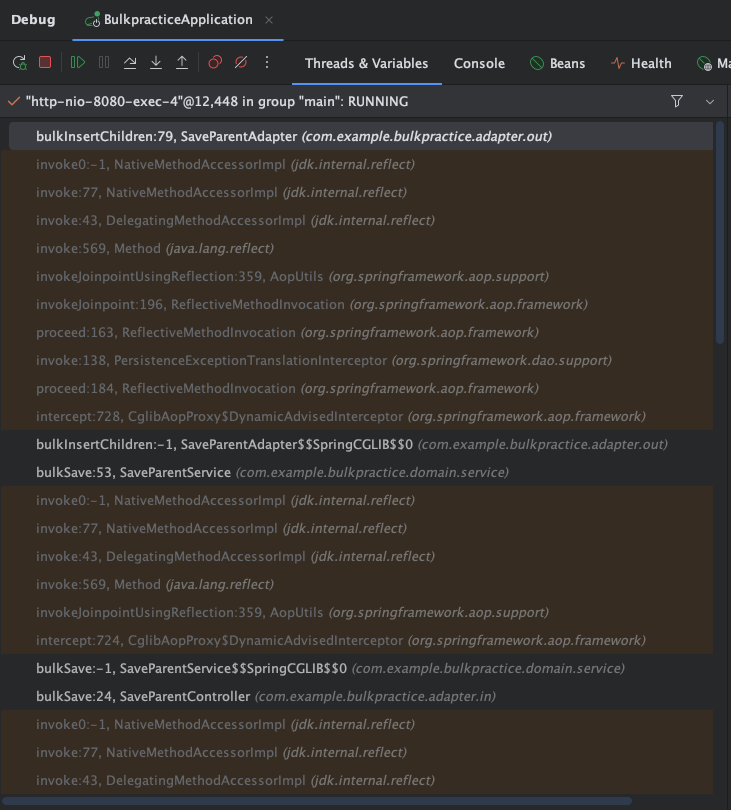
별다른 doCommit(), Hibernate 관련 메서드 호출은 찾아볼 수 없다.
쿼리 로그 또한, bulk insert 쿼리밖에 찾아볼 수 없다.
그렇다면, @Transactional 어노테이션을 붙인다고 왜 Child entity 단건 insert쿼리가 N * M개 나가고 있었을까?
Stacktrace를 살펴보면, @Transactional 어노테이션으로부터 시작되는, invoke를 통해
commit, doflush등이 호출된다.
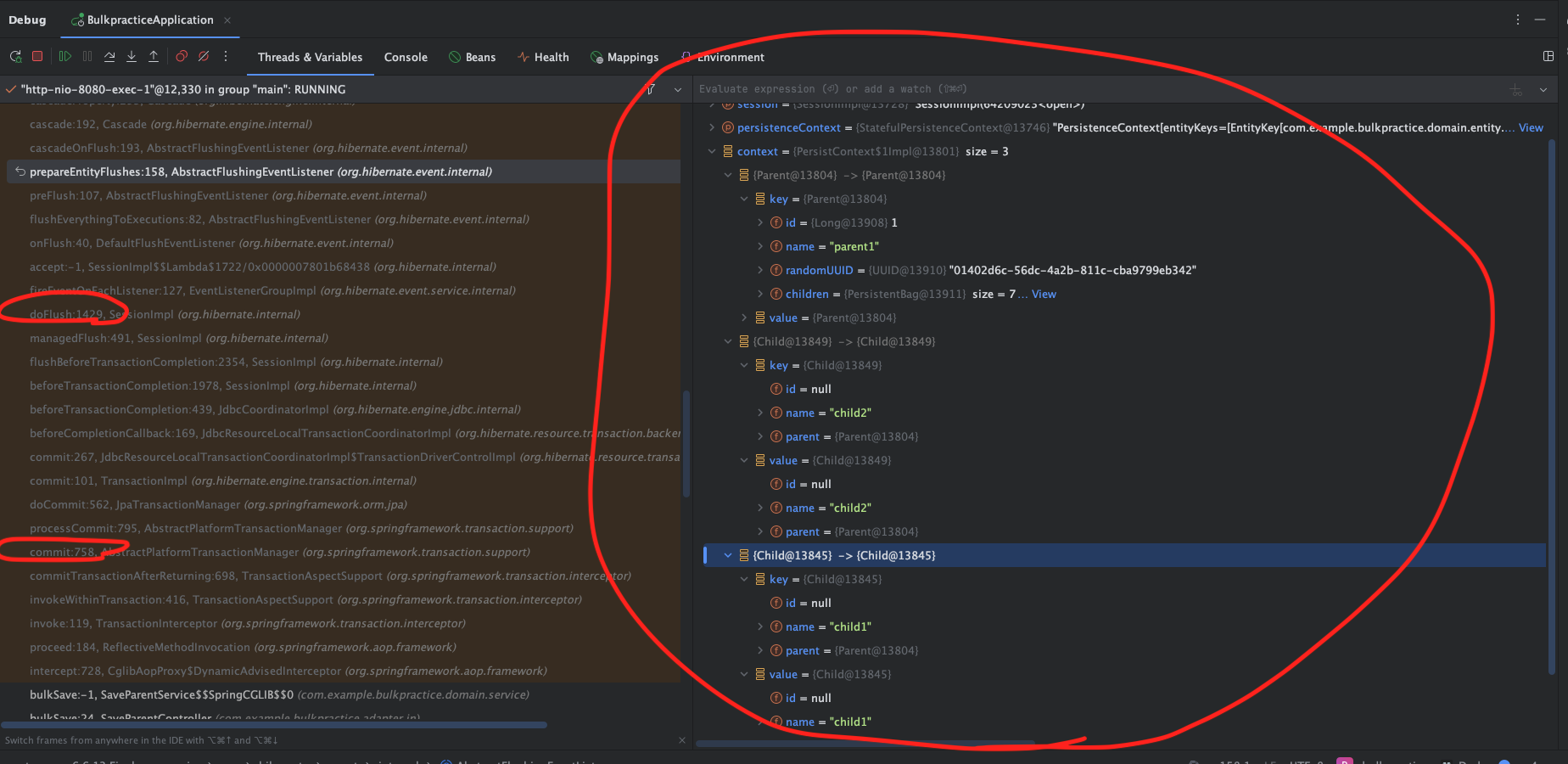
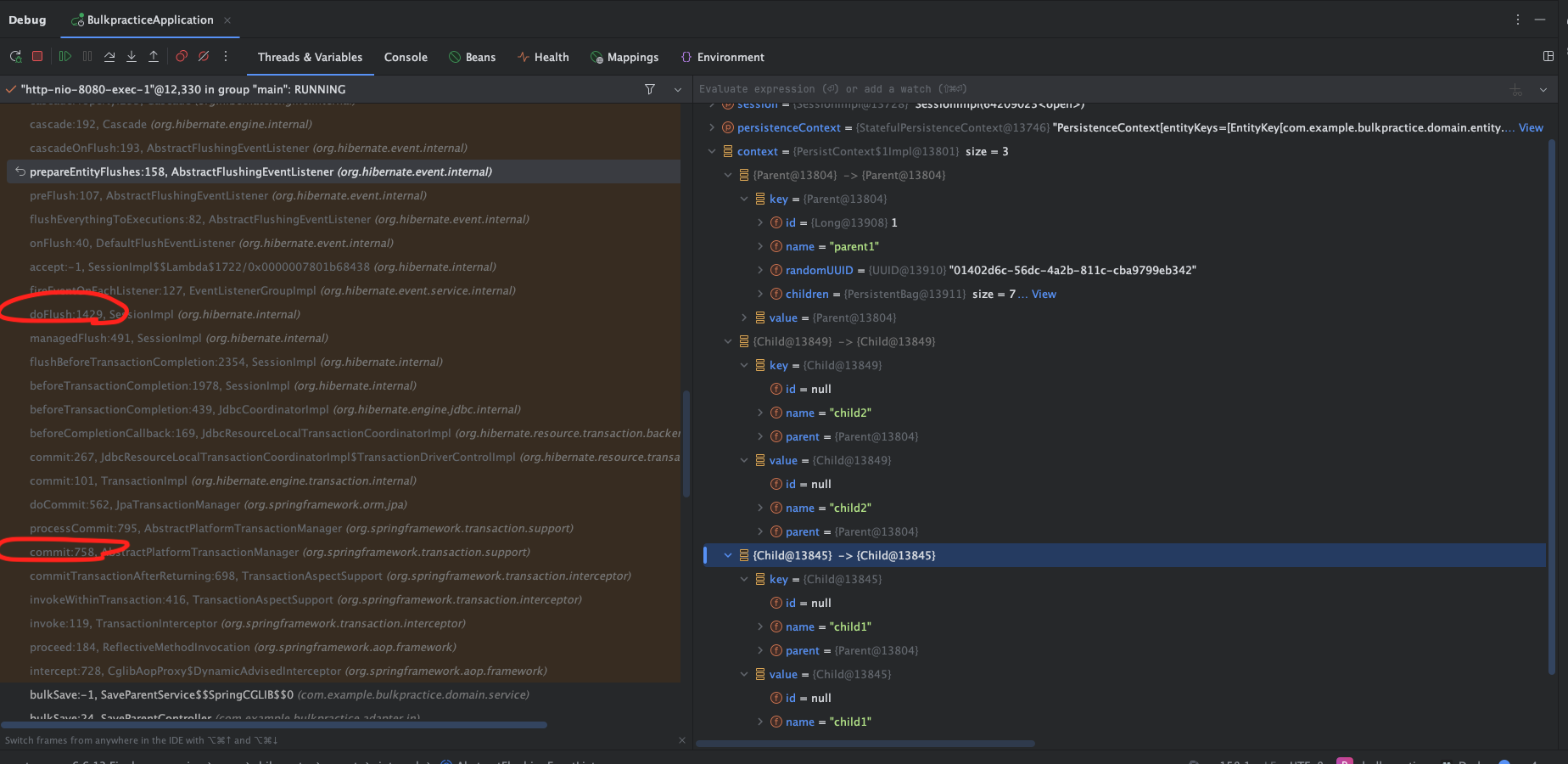
이후 prepareentityFlushes()메서드의 stacktrace 시점을 살펴보면, 영속성 컨텍스트에 parent, child 엔티티가 차 있는것을 확인할 수 있다.
정답은 jpa 연관관계에 있었다.
1. Parent - Child는 1:N 연관관계를 맺고 있으며, Parent측에서 cascade전략을 PERSIST, REMOVE로 관리하였다.(아래 사진 참고)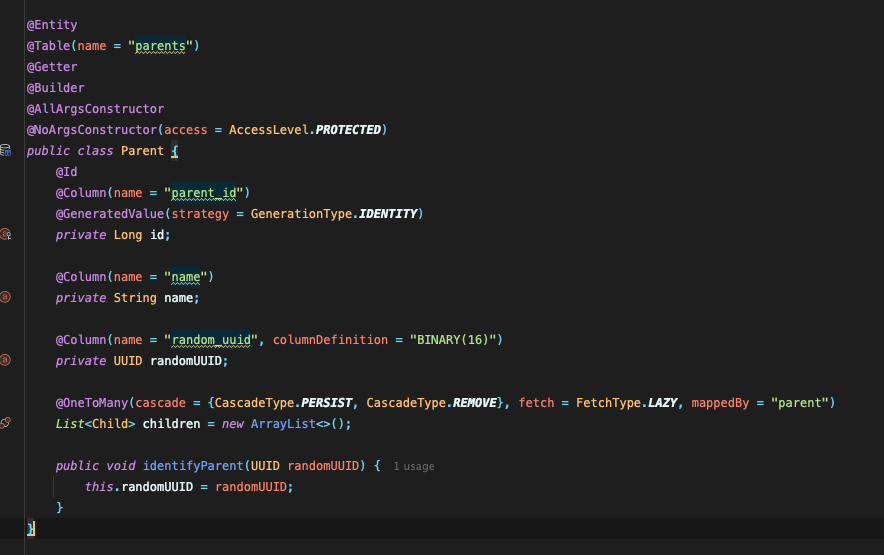
2. Child에서 연관관계 매핑시, 양방향 연관관계 매핑을 해 주었다.(즉, Parent의 Child list에 자신을 add해 주었다. 아래 사진 참고)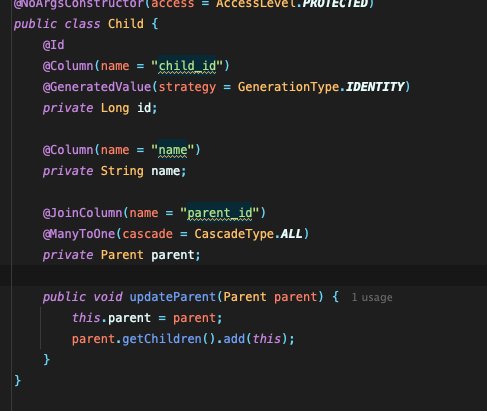
따라서, 5번 과정에서 queryDsl을 사용하여 부모 엔티티를 쿼리한 이후,
Child에서 연관관계 매핑에 의해, 영속성 컨텍스트에 관리되는 부모의 child List의 변경감지가 이루어져
부모 엔티티가 persist됨 + 동시에 Child까지 cascade하게 persist되는 과정이 발생했던 것이다.
해결방법
- @Transactional 어노테이션은 그대로 두고, 부모의 @OneToMany 어노테이션에서 cascade 옵션을 제거한다.
- 양방향 연관관계 매핑시, 부모의 list에 child를 add하는 메서드를 없앤다.
- Transaction 커밋 이전, 영속성 컨텍스트를 비운다(entityManager.clear()).
