본 글은 if(kakao)2022 Batch Performance 극한으로 끌어올리기: 1억건 데이터 처리를 위한 노력 발표를 듣고 작성하는 후기 글입니다.
들어가며
이제 곧 회사에서 Spring Batch 중심으로 돌아가는 프로젝트에 들어갈 예정이다.
그에 따라, Spring Batch의 성능 향상을 위해서 어떤 방법들이 있는지 알아보고자
해당 발표 영상을 보고 요약한다.
Batch Application
특정 시간에 많은 데이터를 일괄 처리할 수 있기 때문에, 서버 개발자들이 자주 이용한다.
대량 데이터 READ
- Batch 성능에서 차지하는 비중은 보통 Reader가 Writer보다 크다(조회작업이 더 많다)
- 따라서 Reader 성능 개선을 하는 것이, 전체적인 Batch Application의 성능을 높이는 데 유용하다
- RDMBS에서 Select 쿼리를 개선하는 것 만으로도 큰 성능 향상을 기대할 수 있다.
Chunk Processing
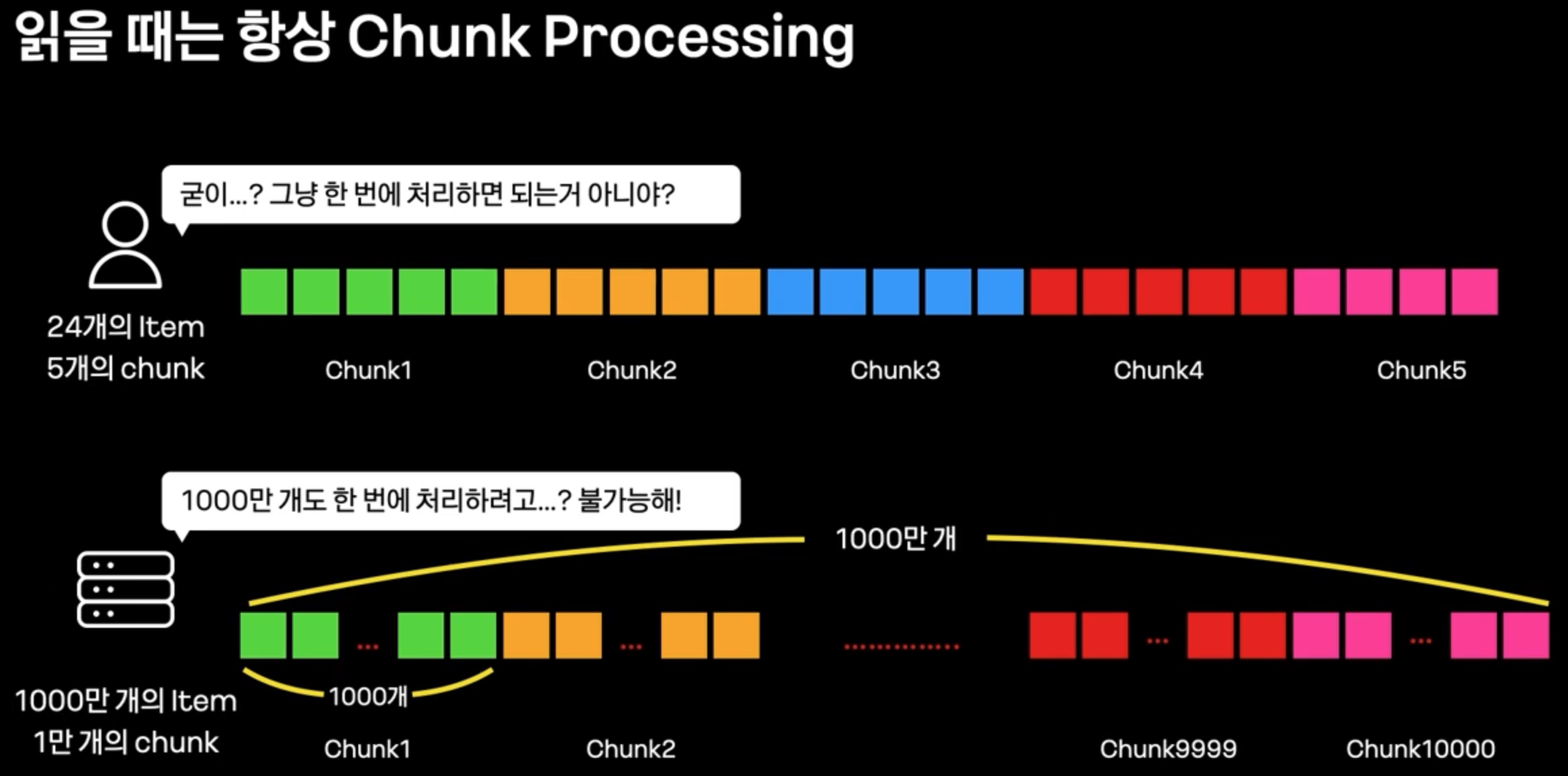
- 다량의 데이터를 처리하기 위해서는, 데이터를 특정 size의 Chunk로 나누어 처리한다.
- Chunk Processing은
JpaPagingItemReader,RepositoryItemReader등으로 pagination을 적용하여 처리한다. - 하지만 이런 방식은 사실 대량 데이터 처리에 부족하다.
Chunk Processing 1 : ZeroOffsetItemReader

- 기존 ItemReader(
JpaPagingItemReader,RepositoryItemReader)는 Select 쿼리에 offset절이 들어가고, offset절은 내부적으로 해당 offset부터 읽는 것이 아닌, 기존 데이터들을 훑기는 하기 때문이다.

- 따라서 특정 key (대표적으로 PK)를 지정하여, where절에서 key값을 이용하여 조회한 후, offset은 고정적으로 0으로 지정하는 방법으로 성능 향상을 기대할 수 있다.
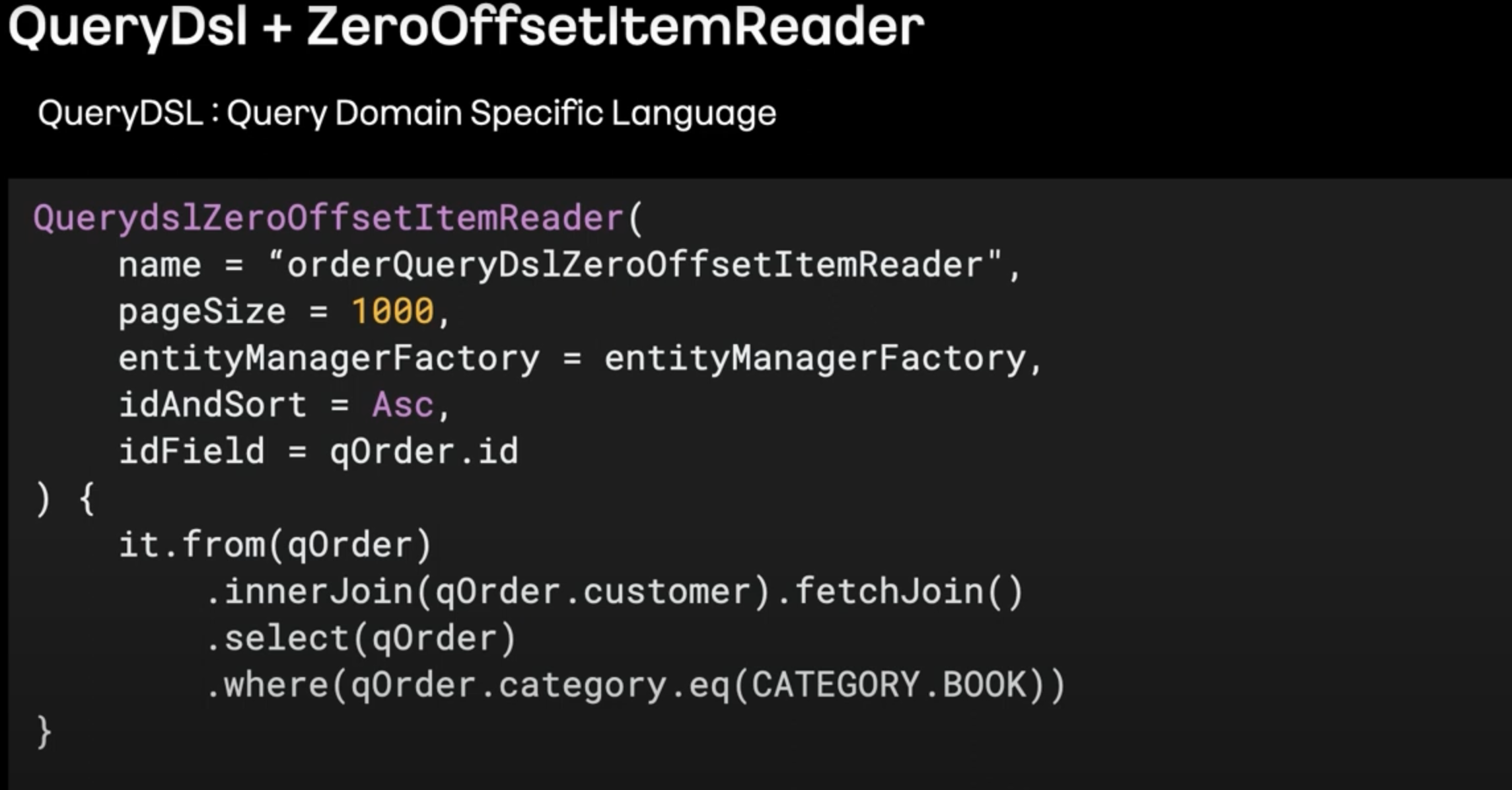
- 위와 같이 QueryDsl을 이용하여 ZeroOffsetItemReader를 구현하는 방법도 있다.
Chunk Processing 2 : Cursor 방식
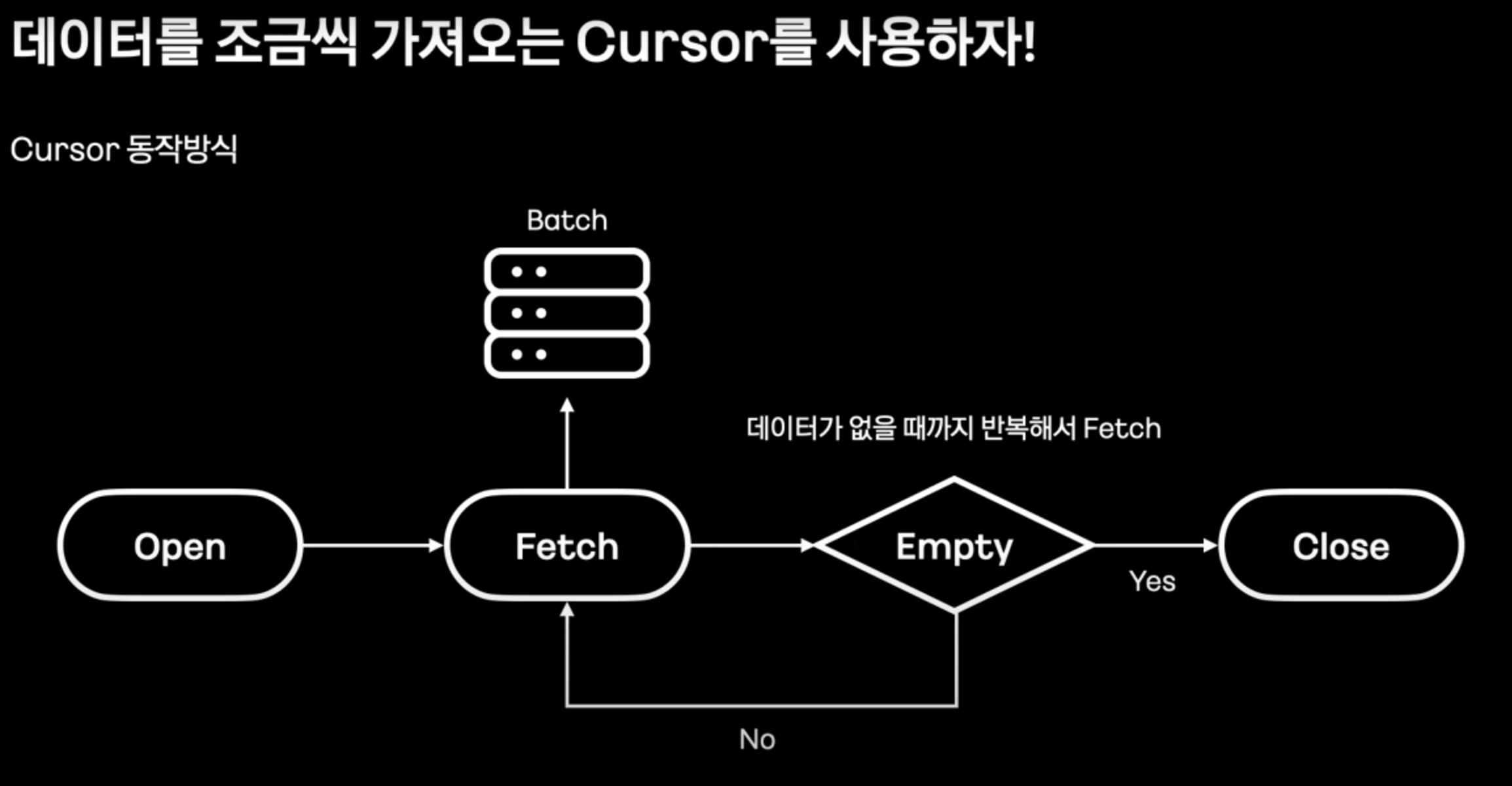
- offset을 이용하는 것이 아닌, cursor를 사용하여 데이터가 없을 때 까지 일정 갯수의 데이터를 가져온다.
- Chunk processing과의 컨셉도 일치한다.
- Cursor를 지원하는 ItemReader는 아래와 같다.
JpaCursorItemReader: MySQL의 커서 방식이 아닌, 데이터를 모두 서버 메모리에 적재하고 서버에서 cursor를 이용하는 방식이다. → OOM을 유발할 수 있으므로, 사용을 지양한다.JdbcCursorItemReader,HibernateCursorItemReader: MySQL의 커서 방식을 이용한다.
사용에 적합하다.
- 다만 Native Query를 이용해야 한다.
메소드 기반으로 cursor를 구현할 수 없을까? : Exposed

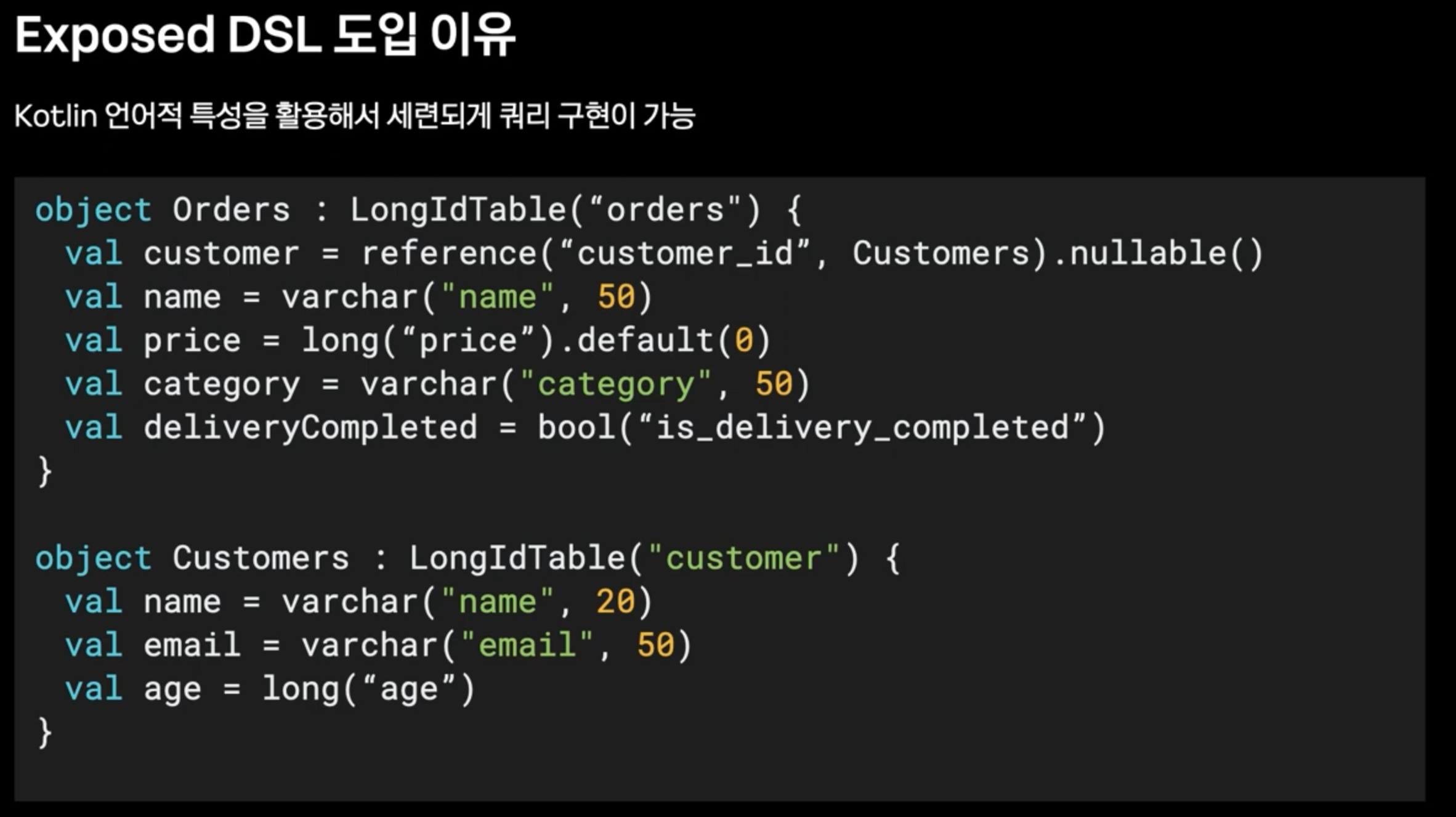
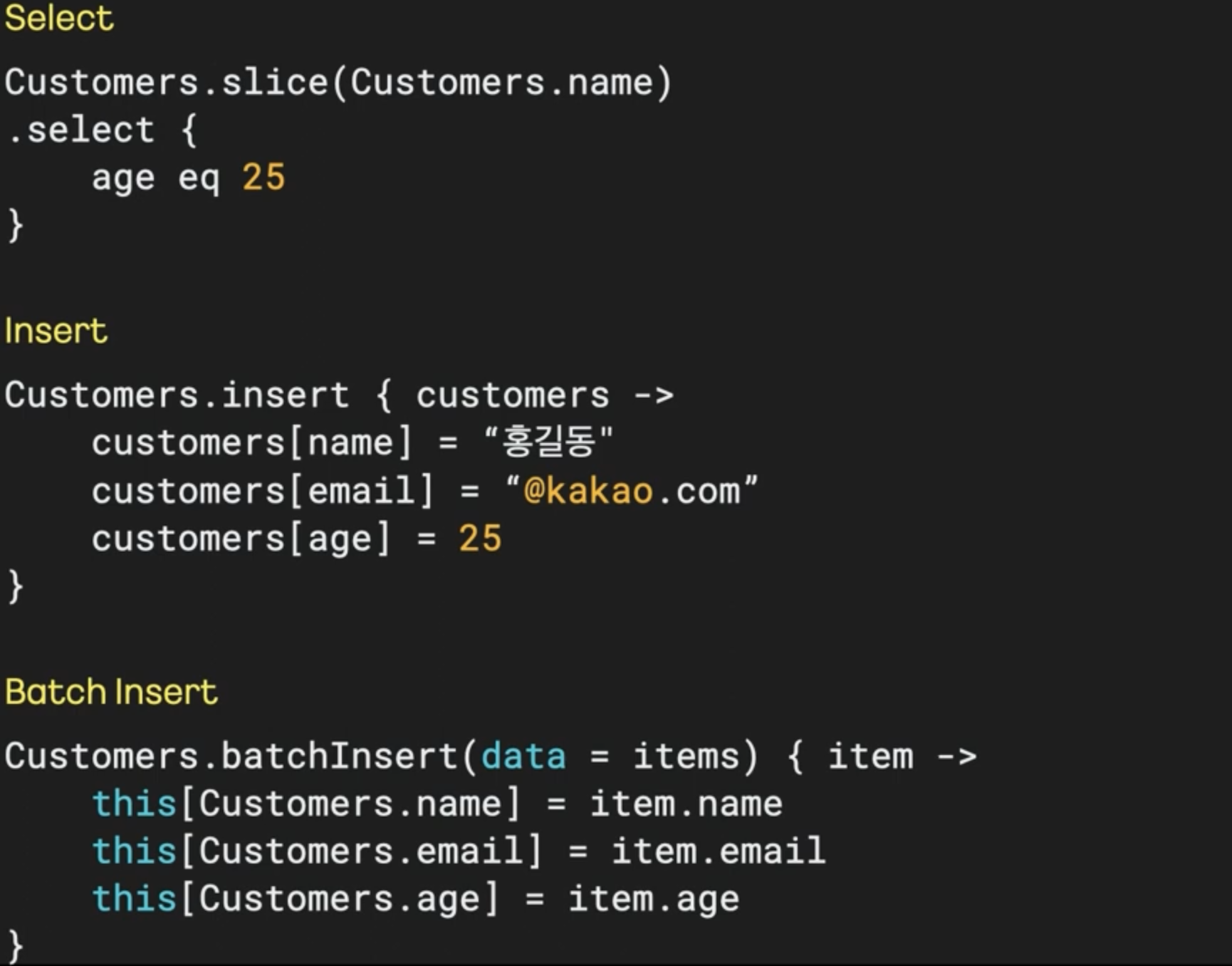
ItemReader 성능 비교
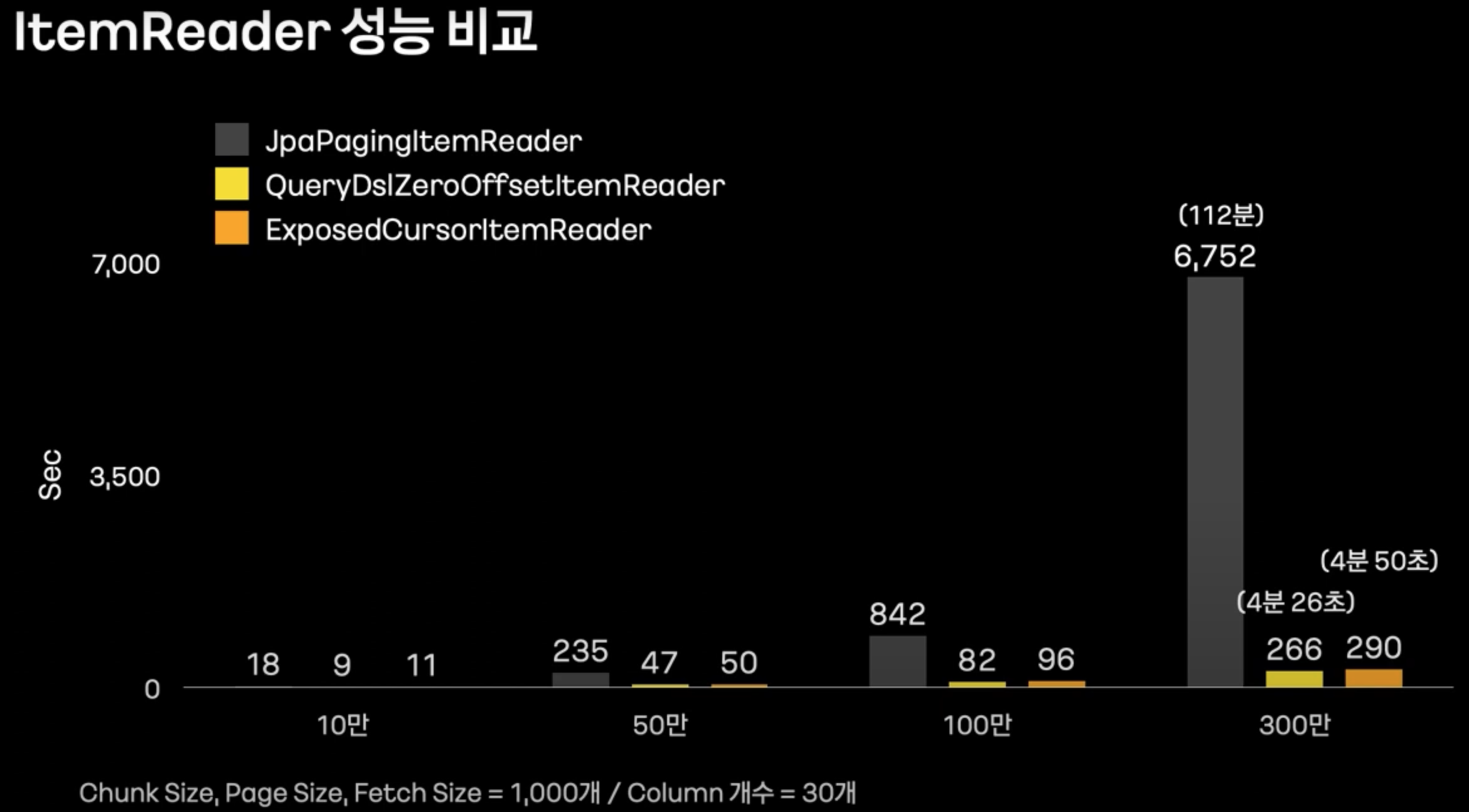
- 위와 같이, JpaPagingItemReader는 offset 쿼리때문에 성능이 많이 안 좋은 것을 볼 수 있다.
데이터 Aggregation 처리
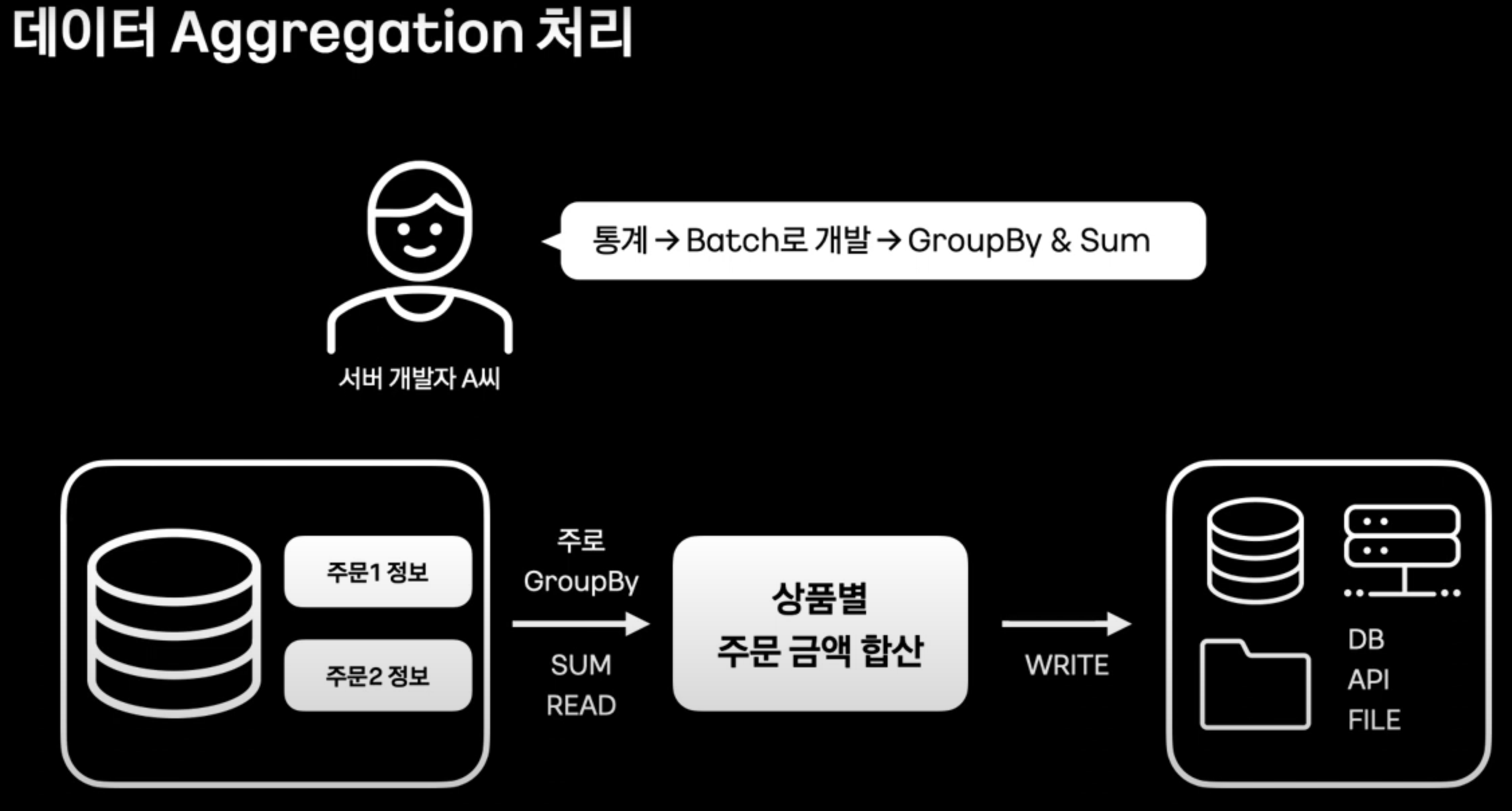
- 위와 같이, 모든 데이터들을 Select 해서 groupby, sum을 이용하는 Batch Job이 있다고 가정해 보자. (모든 데이터라는 것에 집중한다.)
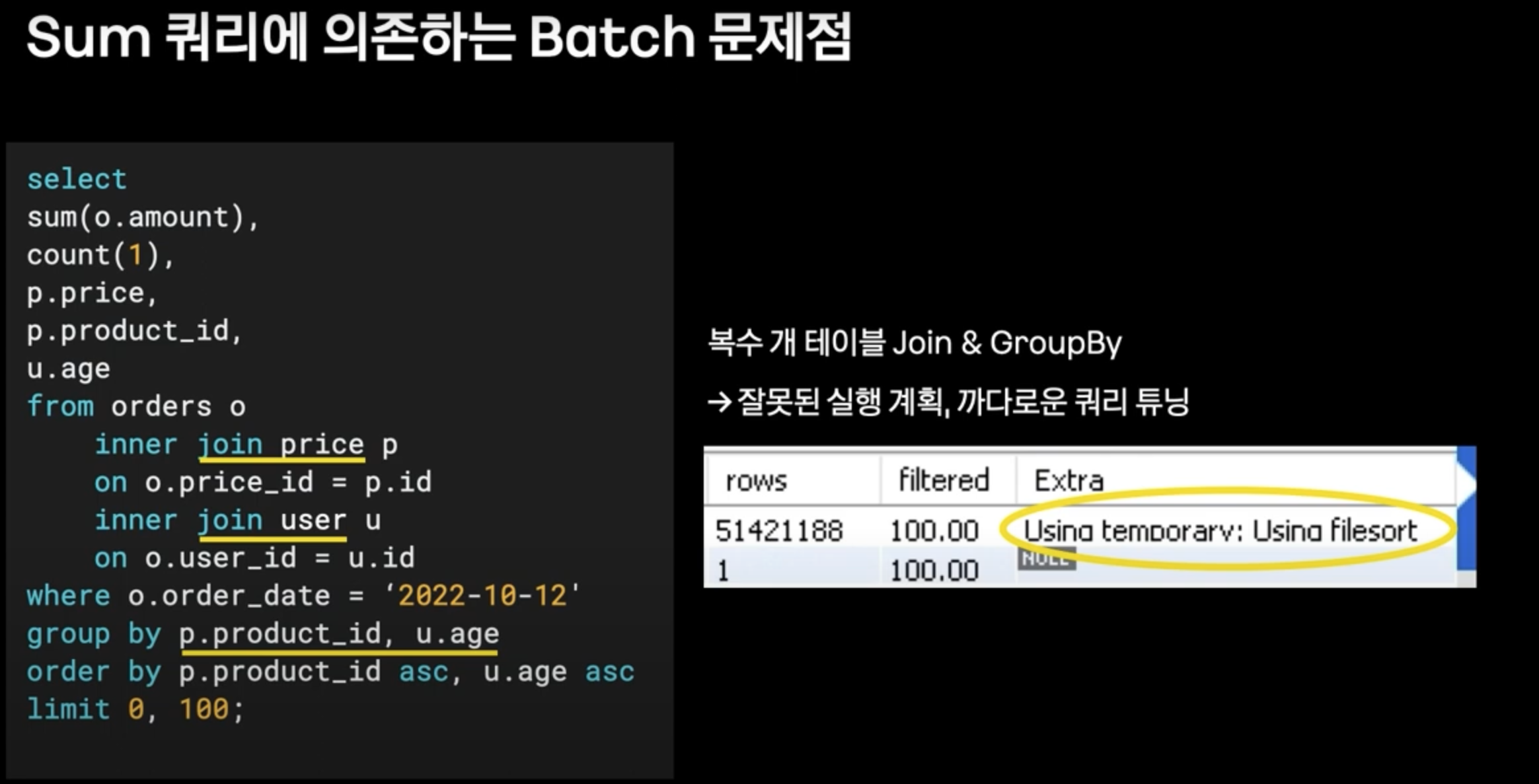
- 그렇게 되면 쿼리 실행 계획이 tmp 테이블 / 파일소트를 타게 되고, 이는 성능에 많은 저하를 안기게 된다.
- 또한 연산이 쿼리에 의존적이게 되어, DB에 부하가 증가된다.
- 결과적으로, ItemReader를 개선한다고 해도 쿼리 자체가 느리기 때문에, 전체적인 성능이 떨어진다.
- (쿼리는 limit 0, 100이지만, 모든 데이터에서 Group by + sum을 실행한다고 가정한다.)
GroupBy 포기

- 그에 따라, 쿼리 실행계획을 개선하여 쿼리 성능을 높이기 위해 GroupBy를 쓰지 않고, 서버단에서 aggregation을 하는 선택을 하셨다고 한다.
문제점
서버단에서 aggregation을 하는 것 자체는 문제가 없지만, 데이터의 갯수가 많은 상황에서 서버에서 aggregation을 하기에는 메모리가 부족하다.
해결
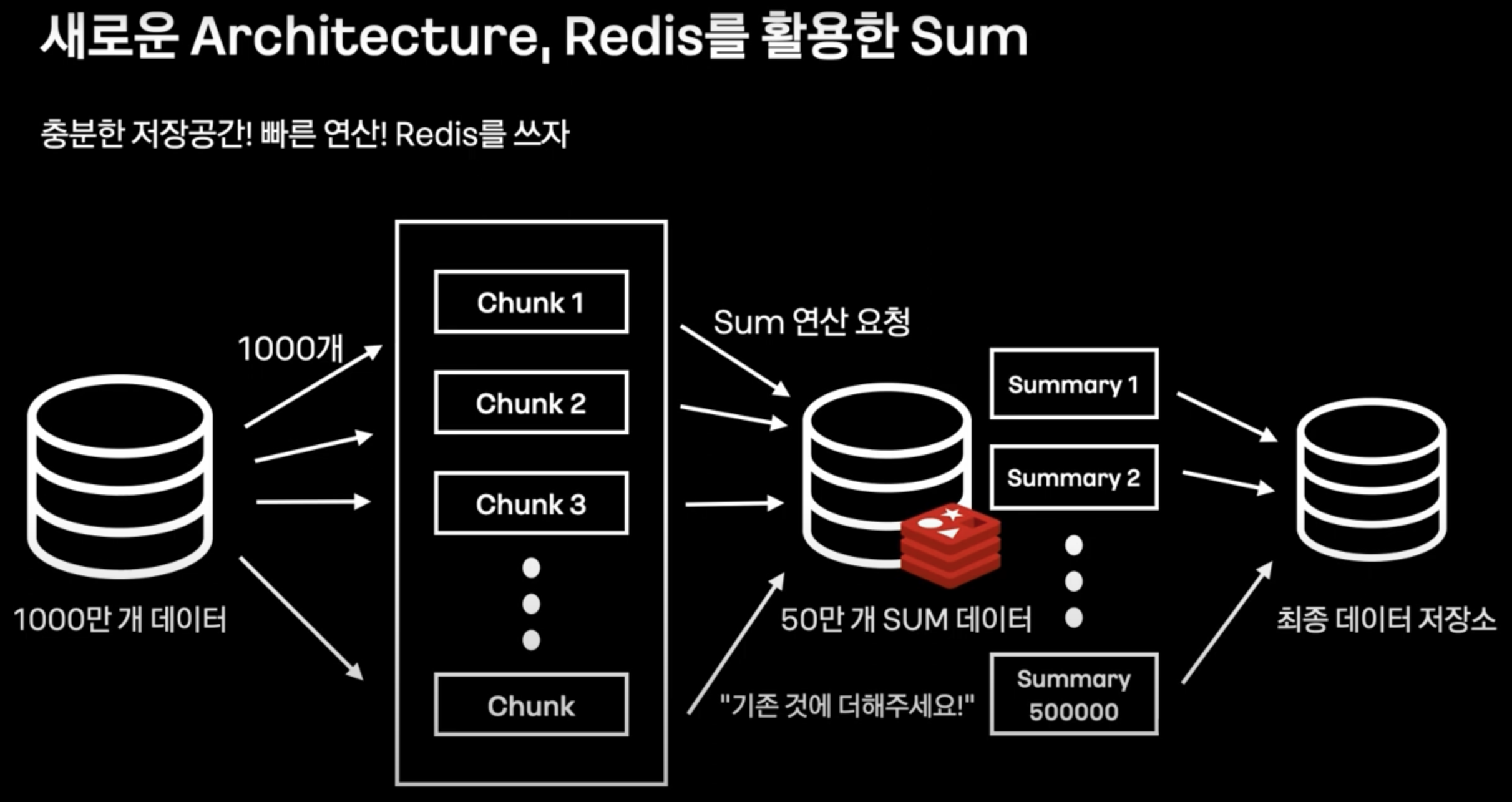
- 모든 데이터를 Chunk로 쪼개서, 각 Chunk의 레코별로 sum연산을 Redis에서 수행한다.
- 이후 모든 sum연산을 다시 합쳐서, 결과적으로 모든 Chunk들의 합(1000만개 데이터의 합)을 db에 영속화시키는 방법으로 Data aggregation을 해결한다.
- (다만 sum 데이터가 왜 50만개 쌓이는건진 모르겠다. 각 Chunk별로 하나씩 sum을 관리한다고 치면, 50만개가 아닌 1만개일텐데..? 1000만(총 데이터) / 1000(Chunk 개수) )
Redis 사용 이유?

또 다른 문제점 : Network I / O
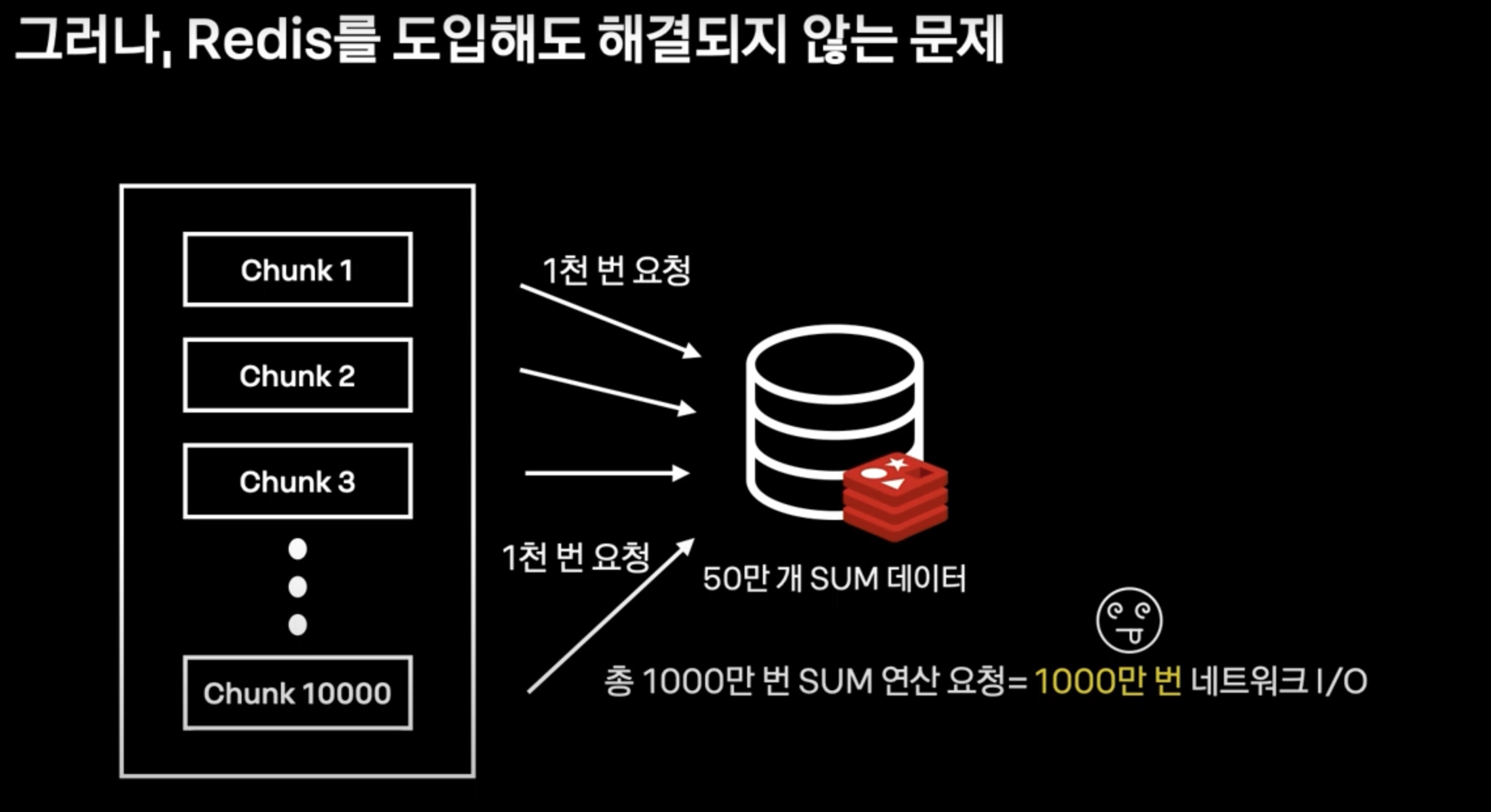
- 각 레코드를 읽어 sum연산을 redis에 요청하게 되면, 결과적으로 레코드 개수 만큼 네트워크 I/O가 발생한다.
해결
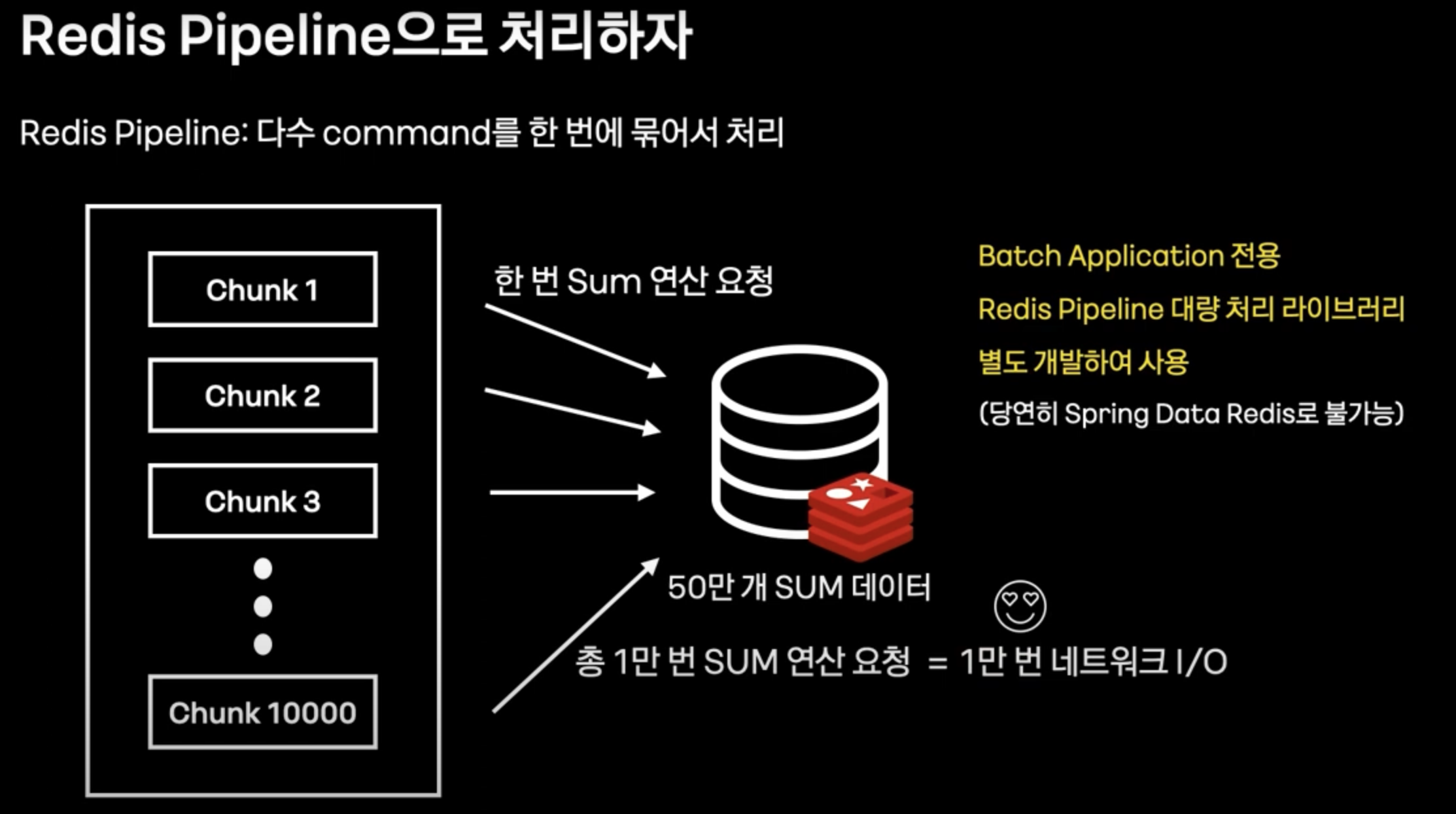
- 1개의 Chunk당 레코드 갯수만큼 sum연산을 하는 것이 아닌, 1개의 Chunk당 한번만의 sum 연산을 요청하도록 Redis pipeline을 실행하도록 한다.
- 다만, Spring data redis에서는 위 기능을 지원하지 않기 때문에, 별도의 라이브러리를 직접 개발하셨다고 한다. (역시 카카오 ..)
대량 데이터 WRITE

- 이제 Reader 성능 향상은 완료하였으므로, Writer의 성능을 향상시킨다.
- 위의 두가지 방법으로 성능 향상을 할 것이다.
- 또한 다음과 같은 이유들로, JPA를 사용하지 않았다.
- Batch 환경에서는 JPA가 맞지 않는다.
- Batch Job에서 대량의 데이터를 처리할 때, JPA의 영속성 컨텍스트가 개입되게 되면 Dirty Checking이 일어나고, 영속성 컨텍스트에서 엔티티들을 관리하게 되어 서버에 큰 부담이 가게 된다.
- 따라서 JPA를 쓰지 않거나, Reader에서 DTO Projection등을 통해 영속성 컨텍스트를 거치지 않게 한다.
- JPA에서는 Batch Insert를 지원하지 않는다.
- 정확히는, 지원 자체는 하지만, ID 생성 전략을 IDENTITY로 하게 되면, Batch Insert를 진행하지 않는다고 한다.(참고 : https://cheese10yun.github.io/jpa-batch-insert/)
- Batch Job에서 대량의 데이터를 처리할 때, JPA의 영속성 컨텍스트가 개입되게 되면 Dirty Checking이 일어나고, 영속성 컨텍스트에서 엔티티들을 관리하게 되어 서버에 큰 부담이 가게 된다.
Batch 구동 환경
기존에는 conrtab, jenkins 등에서 Batch관련 관리를 할 수 있다.
하지만 아래의 어려움들이 있다.
자원관리의 어려움
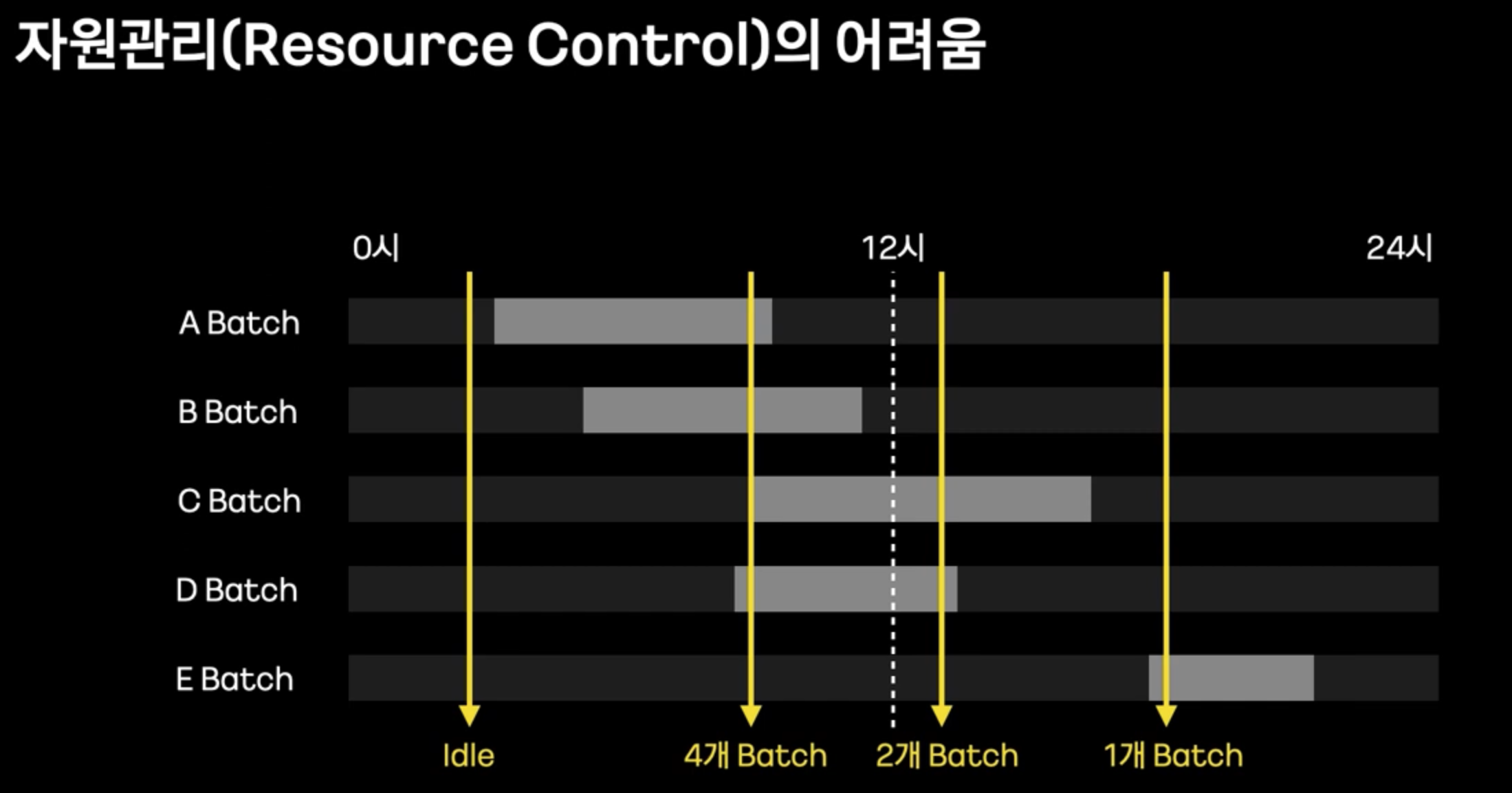
- 항상 인스턴스가 실행중이 아닌, 특정 시간에만 실행된다.
- 특히 하나의 인스턴스에서 여러개의 Batch를 돌리게 된다면, OOM이 발생할 가능성도 존재한다.
모니터링의 어려움

- Batch 관련해서는 로깅이 충분히 지원되지 않는다.
해결

- Spring Cloud Data Flow를 통하여 Batch 오케스트레이션, 모니터링을 강화할 수 있다.

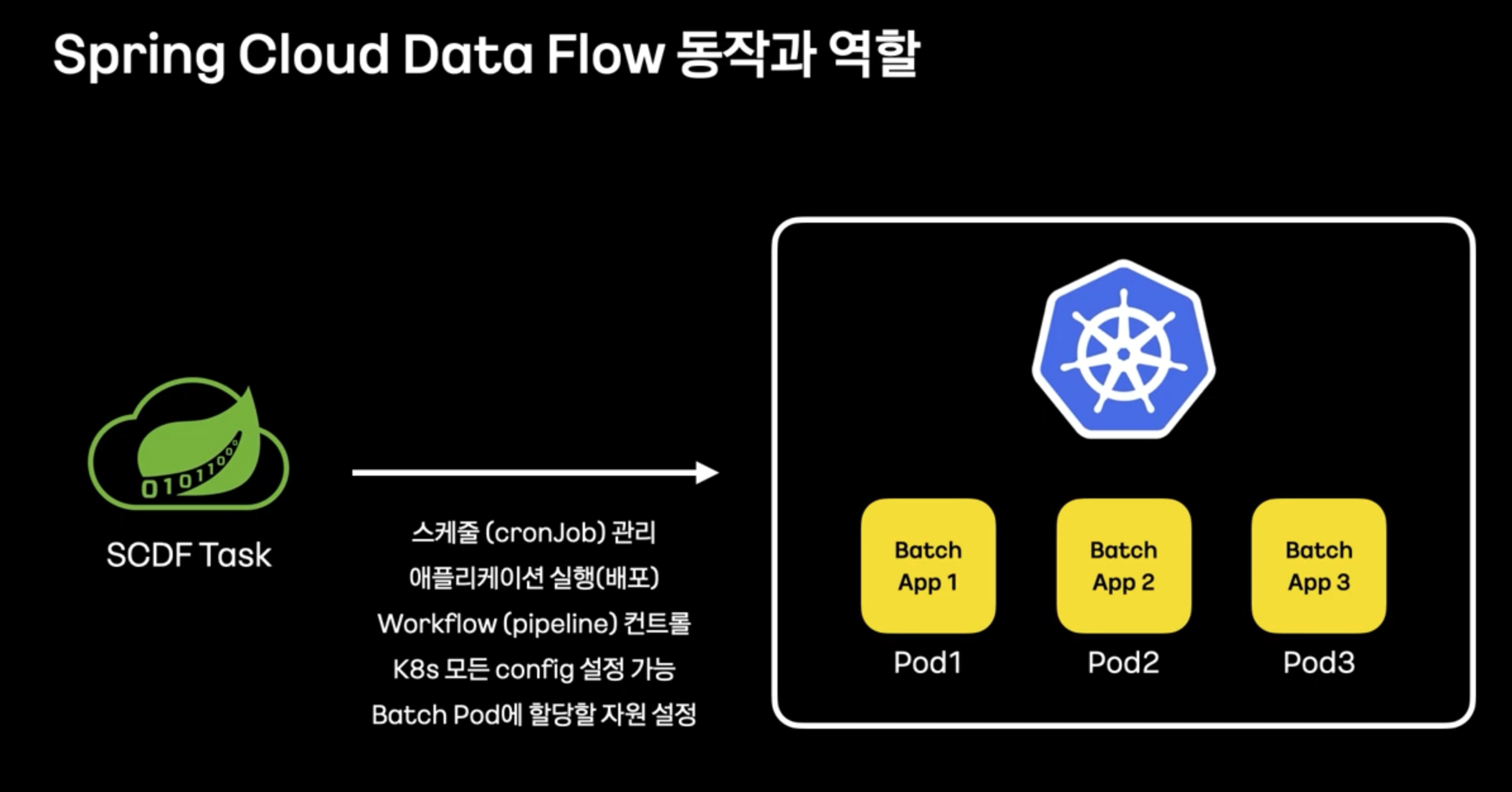
- Spring Cloud Data Flow + k8s를 연동하여, Batch Pod에 할당할 자원을 설정하여 자원관리의 어려움을 해결한다.
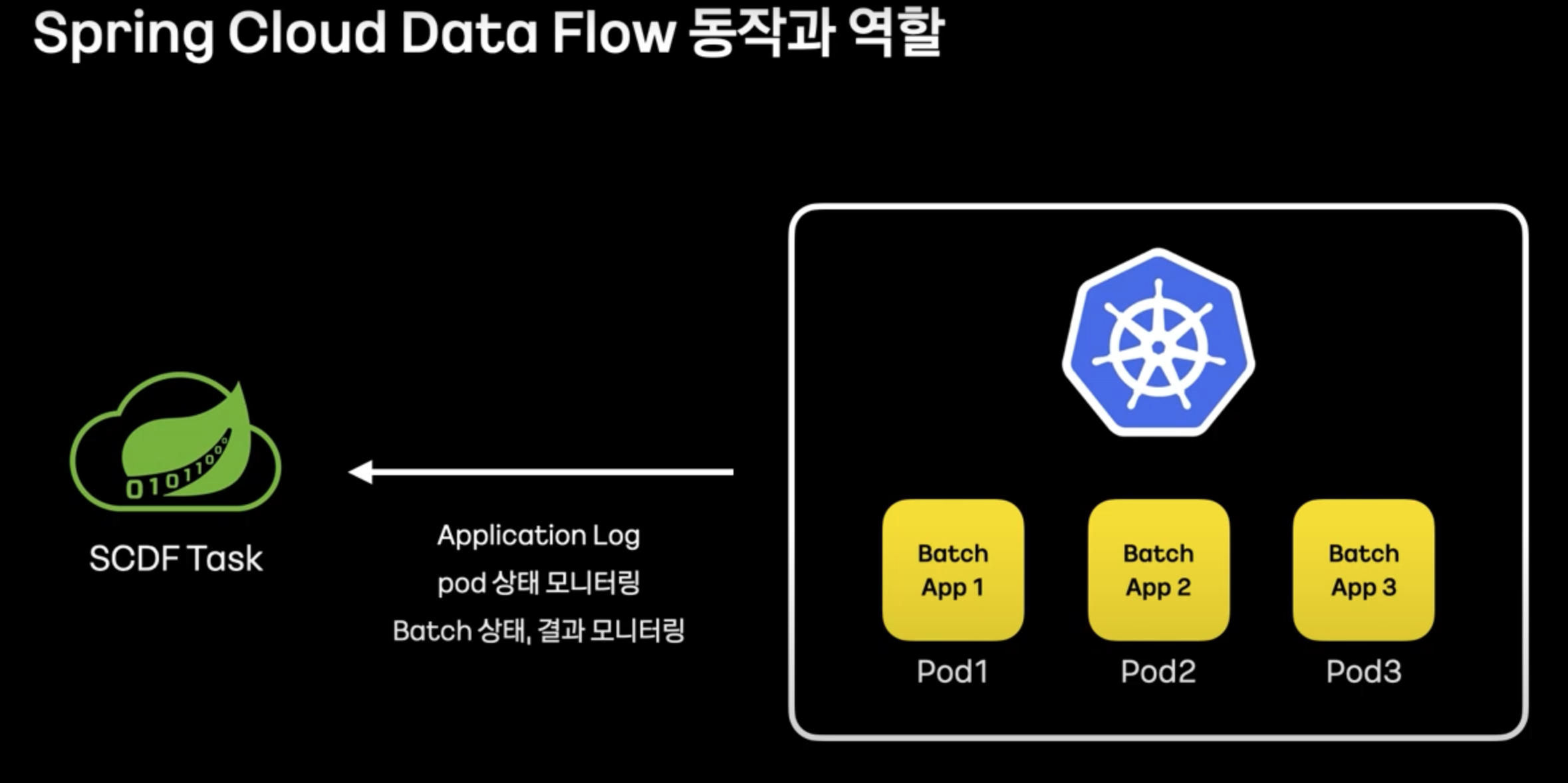
- 모니터링의 어려움 또한 Spring Cloud Data Flow + k8s를 통하여 해결한다.
내가 몰랐던 것 + 더 알아보면 좋을 것
- ID생성전략을 IDENTITY로 할 시, JPA Batch Insert 미지원
- 오케스트레이션

우상향 하는 개발자