분산락에 대한 판단기준 고찰과 개선
(이 글은 나비장터 프로젝트의 진행 중 들었던 고민들을 정리한 글입니다.)
들어가기에 앞서 전제 사항
- 조회수는 실시간으로 업데이트 될 필요가 없다.
- 단, 누락이 존재해서는 안된다.
- 우리 프로젝트는 향후 분산 환경으로 확장할 것을 가정한다.
개선점이 있는 기존 코드
@Async("threadPoolTaskExecutor")
@DistributedLock(key = "#lockName")
public void increaseViewCount(
String lockName,
Long userId,
Long cardId
) {
// 조회수 로직 시작
String cardViewCacheKey = KeyGenerator.generateCardViewCacheKey(cardId); // 조회수 key
String readerCacheKey = KeyGenerator.generateCardReaderCacheKey(userId); // 유저 key
String viewCacheValue = redisDAO.getValue(cardViewCacheKey); // 기존 조회수 값 가져오기
if (viewCacheValue == null) { // 조회수 정보가 캐시에 없을 경우
int viewCountById = cardRepository.getCardViewCountById(cardId); // db 조회
viewCacheValue = String.valueOf(viewCountById);
redisDAO.setValues(cardViewCacheKey, viewCacheValue);
}
int viewCount = Integer.parseInt(viewCacheValue); // 가져온 값은 Integer로 변환
// 유저를 key로 조회한 게시글 ID List안에 해당 게시글 ID가 포함되어있지 않는다면,
if (!redisDAO.getValuesList(readerCacheKey).contains(cardViewCacheKey)) {
redisDAO.setValuesList(readerCacheKey, cardViewCacheKey); // 유저 key로 해당 글 ID를 List 형태로 저장
viewCount++; // 조회수 증가
redisDAO.setValues(cardViewCacheKey, String.valueOf(viewCount)); // 글 ID key로 조회수 저장
}
}우리 프로젝트에서는 인기 카드(물건 + 게시물이라 생각하면 된다)를 조회수로 정렬하여 메인 화면에 노출시키므로, 카드의 조회수가 중요하다고 생각했다. 따라서 카드의 조회수를 늘리는 과정에 있어서 누락이 생기는걸 원하지 않았고,
분산 환경에서도(물론 현재는 단일서버이지만) 동일하게 누락을 없애고 싶었다.
따라서 해결책을 찾아보았고, 분산 환경에서 조회수 업데이트 누락을 없애는 방법은 분산락밖에 답이 없다고 생각해서 위와 같은 코드를 작성했다.
위 코드의 로직을 간단하게 설명하자면 다음과 같다.
- @DistributedLock(커스텀 어노테이션. AOP를 이용하여 새로운 트랜잭션을 만들어서 파라미터로 받은 lockName을 key로써 이용하여 내부적으로 redisson.tryLock을 호출한다.)으로 메소드단에 락을 건다.
- 분산락 어노테이션 덕에 락이 걸리면 사용자 A, B가 동시에 조회수 증가 메소드를 호출하여도 한명이 먼저 lock을 건 덕분에, 한명의 트랜잭션이 끝나고 다음 사람의 트랜잭션이 시작된다. 따라서 조회수에 누락이 없다.
- 조회수 증가 메소드 내부에서는 redis cache에 유저가 기존에 해당 카드를 조회한 이력이 없다면, 기존의 Card Id에 해당하는 조회수를 1 증가시키고, 캐시에 저장한다.
- scheduling을 이용하여 10분마다 캐시 내의 카드 조회수를 읽어서 db단에도 update한다.(참고 : write-back 선택 이유)
피드백
위와 같은 흐름으로 메소드를 작성했었고, 멘토님께 작성 의도를 설명드렸더니 다음과 같은 피드백을 주셨다.
해당 메소드에서 꼭 분산락을 걸어야 하나요? 다른 해결책은 없을까요?
머릿속이 새하얘 졌었다. 나름 update문에 있어서 누락을 방지하고자 여러 방면을 찾아봤었고,
- 분산 환경
- update시 누락을 방지
의 조건을 충족할 수 있는 해결책은 분산락만 있다고 판단을 내렸었다.
왜 그렇게 판단을 내렸었지
위의 조건을 해결하기 위해 분산락을 적용하기로 판단을 내렸던 과정을 나열해 보자.
1. 분산환경
분산경에서는 서버의 local cache를 이용하여 동시성을 해결할 수 없다. 정확히는 적합하지 않다.
local cache로 분산락을 구현하여 lock을 잡는다고 가정해 보자. 하지만 이는 한 서버 내에서에서만 데이터 정합성을 보장하고, 다른 서버에서 해당 자원에 접근하는 것을 막으려면, 추가적으로 pub/sub기능을 구현하거나, Ehcache의 RMI등을 이용하여 하나의 로컬캐시가 lock을 해제했다는 것을 전파해야 한다.
또한 스프링 어플리케이션이 죽으면 로컬 캐시에 저장해 두었던 데이터 또한 날아가지만, redis는 외부 서버를 이용하므로 스프링이 죽어도 데이터가 남아있다는 차이 또한 존재한다. (반대로 말하자면 스프링 어플리케이션은 살아있지만, redis가 죽으면 데이터가 날아가는건 매한가지다.)
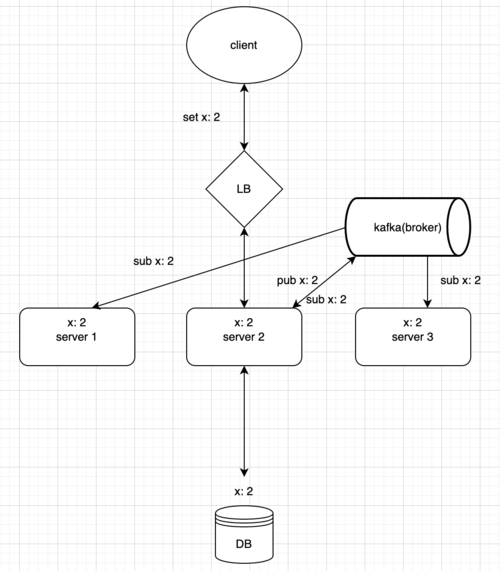
출처 : https://devocean.sk.com/blog/techBoardDetail.do?ID=164373
위와 같은 이유로 분산환경에서는 global cache인 redis를 선택했다.
💡 글로벌 캐시 중에는 memcached도 있는데 굳이 redis를 선택한 이유는?다음과 같다.
2. update시 누락을 방지
멀티쓰레드가 하나의 자원에 동시에 접근하여 업데이트 하면 데이터가 누락된다. 따라서 동시간대에 하나의 쓰레드만 업데이트에 참여해야 한다. → 메소드에 대한 lock이 그 해결책이고, 낙관락, 비관락, 분산락 중 분산락을 선택한 이유는 다음과 같다.
어떻게 개선할 수 있는데?
- 위의 2번에서 개선점이 있다.
꼭 메소드 단에 lock을 걸어야 할까? 자원에 대해서 접근만 막아도 충분하다.
→ redis는 싱글쓰레드이다.
→ 따라서 redis에 card Id를 key로 두고, value를 증가시킬 조회수(증분)로 두면 멀티쓰레드가 동시에 increaseViewCount()메소드를 호출하더라도, redisDAO.getValue(), redisDAO.setValues()를 호출할 때는 하나의 쓰레드만 실행할 수 있다.
→ 메소드단에 분산락을 걸지 않아도 viewCount를 안전하게 증가시킬 수 있다.
- 그냥 로컬 캐시 사용해서 update해도 충분하잖아?
잠깐만. 근데 redis의 분산락을 이용하여 바로 db에 조회수 update로직을 적용하는 것이 아니고, 조회수를 단순히 캐시에 저장한 이후 스케줄링을 이용해서 업데이트 하는 것이라면, local cache만으로도 충분히 해결할 수 있을것 같다.
Example
A서버 local cache - 1번 카드(key) : 10(증가시킬 조회수. value)
B서버 local cache - 1번 카드(key) : 20(증가시킬 조회수. value)
스케줄링이 발생하여 A서버, B서버 순서대로 다음 쿼리를 진행하면, 로컬 캐시로도 커버가 가능하다.
"UPDATE Card c SET **c.viewCount = c.viewCount + :viewCount** WHERE c.cardId = :cardId"찾아보니 Ehcache는 동시성 해결 + ttl + eviction policy까지 제공하는 local cache library이다.
당장 지금 조회수 증가 로직에서 redis → ehcache로 바꾸더라도 조회수 증가시 동시성 문제를 block할 수 있고, 더 가볍다.
(다만, 캐싱 자체는 동시성 문제를 해결할 수 있지만 스케줄링 시에 A서버, B서버 동시에 스케줄링이 발생한다면 이것 또한 동시성 문제가 발생할 수 있겠다.)
(참고 : https://velog.io/@wnguswn7/Hibernate-ehcache를-이용한-캐싱)
분산락 vs Non분산락 판단 기준
서론이 길었다. 결국 분산락에 대한 기준을 고찰하는것이 이 글의 작성 이유였다.
나는 멘토님의 피드백과 내 고민을 합쳐 분산락 적용을 다음과 같은 상황에서 고려하도록 기준을 세웠다.
- 다중 서버 환경인 경우
- 메소드의 사용 순서가 중요한 상황.
(ex : A쓰레드 실행 이후 B쓰레드 실행 결과와 B쓰레드 실행 이후 A쓰레드 실행 결과가 다를 수 있는경우. 즉, 이후에 실행될 쓰레드에게 멱등성이 보장되지 않을 경우.) - 실시간 업데이트가 중요한 상황.
로컬 캐시에 저장 이후 추후에 업데이트 해야하지 않고, 당장 메소드단에 락을 걸어서 바로 db에 업데이트를 해야 할 상황.
(ex : 재고가 한정되어 있어 바로바로 업데이트 하여 다음 사용자가 구매할 수 있는지 여부를 표시해야 할 경우.)
아직 부족한 점
일단은 분산락을 제외하고, redis에 캐싱하는 부분만 조회수 증가 로직에 남겨두자.
다만 로컬 캐시로 migration 할 수 있다는 확실한 근거가 파악되면, 바로 그럴 것이다.
다만 프로젝트 종료가 당장 내일이므로, 부득이하게 기존에 쓰던 기술을 이어 사용해야 할 것 같다.
나의 부족했던 점
- 다수의 case가 분산락이 해결책이라는 점을 제시했지만, 정말 나의 상황에 부합했을 때의 해결책인지, 나의 상황과 달랐을 때의 해결책인지 깊게 생각해 보지 못한 점. 스스로 좀 더 고민을 하지 못했던 점.
- 아는 것과 안다고 생각하는 점은 천차만별이라는 점.
남들에게 설명할수 있는가 ? → 아는 것.
못하는가 ? → 안다고 생각하는 것. - 프로젝트 막바지 기간이라 프로덕트 개선이 빨리 되어야 하는 시점이라 생각하여 조금 더 깊게 생각하지 못했던 점.
잘했던 점
- 전제 상황과 문제 상황을 문서화 하고, 해결책 또한 문서화하여 나열하고 그 중에서 제일 좋다고 생각한 것을 고른 점.
느낀 점
- 발전할 부분이 더 있어서 기쁘다.
우리 프로젝트가 프로덕트로써 발전할 부분이 있고, 나 또한 개발자로서 문제 해결에 대한 시각을 넓혀야 되는 부분이 있다.
- 개선점을 알려주시고 피드백을 해주시는 주변 사람이 있어서 감사하다.
어영부영 넘어갔다면 더 나은 해결책을 지나친 꼴이 되었을 것이다. 그렇지 않고 부족했던 점을 알려주신 멘토님들게 진심으로 감사하다.
- 문제해결을 위한 고민을 할 수 있다는 사실 하나만으로도 기쁘다.
이전까지는 반복적인 CRUD작업을 해왔다고 생각한다. 이번에는 제대로 된 문제해결을 위한 사고를 하는 과정이 있었고, 그런 상황이 닥친 것이 기쁘다.
