.png)
지도 학습과 비지도 학습
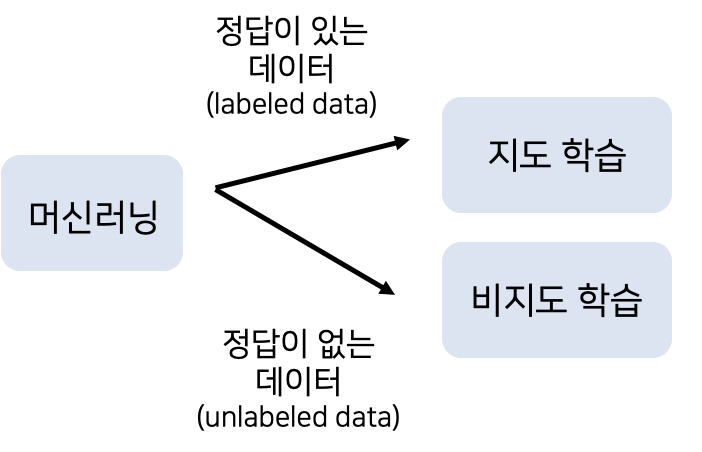
지도 학습(supervised learning)
: 입력과 정답 데이터를 사용하는 학습 알고리즘.
비지도 학습(unsupervised learning)
: 정답 없이 입력 데이터만 사용하는 학습 알고리즘.
훈련 데이터 세트와 테스트 데이터 세트
훈련 데이터 세트 (training dataset)
: 학습에 사용되는 데이터
테스트 데이터 세트(test dataset)
: 평가에 사용되는 데이터
K-NN을 이용한 도미와 빙어 분류 모델 - 훈련 데이터 세트와 테스트 데이터 세트 분리
입력 데이터, 정답 데이터 numpy 배열로 변환하기
numpy.array(리스트 이름)로 리스트를 numpy 배열로 변환할 수 있다.
[코드]
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
fish_data = [[l, w] for l, w in zip(fish_length, fish_weight)]
fish_target = [1] * 35 + [0] * 14
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)
print(input_arr.shape)
print(input_arr)
print('_____________________________________________________________________________')
print(target_arr.shape)
print(target_arr)[결과]
(49, 2)
[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]
[ 29.7 450. ]
[ 29.7 500. ]
[ 30. 390. ]
[ 30. 450. ]
[ 30.7 500. ]
[ 31. 475. ]
[ 31. 500. ]
[ 31.5 500. ]
[ 32. 340. ]
[ 32. 600. ]
[ 32. 600. ]
[ 33. 700. ]
[ 33. 700. ]
[ 33.5 610. ]
[ 33.5 650. ]
[ 34. 575. ]
[ 34. 685. ]
[ 34.5 620. ]
[ 35. 680. ]
[ 35. 700. ]
[ 35. 725. ]
[ 35. 720. ]
[ 36. 714. ]
[ 36. 850. ]
[ 37. 1000. ]
[ 38.5 920. ]
[ 38.5 955. ]
[ 39.5 925. ]
[ 41. 975. ]
[ 41. 950. ]
[ 9.8 6.7]
[ 10.5 7.5]
[ 10.6 7. ]
[ 11. 9.7]
[ 11.2 9.8]
[ 11.3 8.7]
[ 11.8 10. ]
[ 11.8 9.9]
[ 12. 9.8]
[ 12.2 12.2]
[ 12.4 13.4]
[ 13. 12.2]
[ 14.3 19.7]
[ 15. 19.9]]
_____________________________________________________________________________
(49,)
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0]랜덤으로 훈련 데이터 세트와 테스트 데이터 세트 나누기
numpy.random.shuffle() : numpy random 패키지의 shuffle() 함수는 주어진 배열을 무작위로 섞음.
numpy.random.seed() : seed의 값을 파라미터로 받음. seed의 값이 같으면 같은 숫자들의 집합이 결과물로 나옴. 즉, 랜덤으로 나오는 숫자들을 예측할 수 있게 함.
- 본 실습에서는 같은 결과물을 얻기 위해 seed = 42를 사용함.
-numpy.arange(start, stop, step): 일정한 간격의 정수 혹은 실수 배열을 만듦. start는 범위의 시작을 의미하고, 해당 값을 포함함. 기본값은 0. stop은 범위의 끝을 의미하지만 해당 값을 포함하지 않음. 즉, start 이상 stop 미만까지로 보면 됨. 기본 step은 1.
<단계 1> 0부터 48까지 인덱스 만들기
[코드]
index = np.arange(49)
print(index)[결과]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48]<단계 2> 0부터 48까지 인덱스를 랜덤하게 섞기
[코드]
np.random.seed(42)
index = np.arange(49)
np.random.shuffle(index)
print(index)[결과]
[13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33
30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28
38]<단계 3> 훈련 데이터 세트, 테스트 데이터 세트 나누기
- 훈련 데이터 세트는 35개, 테스트 데이터 세트는 14개
[코드]
train_input = input_arr[index[: 35]]
train_target = target_arr[index[: 35]]
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]
print(train_input.shape)
print(train_target.shape)
print(test_input.shape)
print(test_target.shape)[결과]
(35, 2)
(35,)
(14, 2)
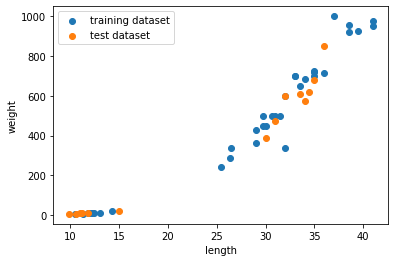
(14,)훈련 데이터 세트, 테스트 데이터 세트 분포 확인하기
[코드]
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(test_input[:,0], test_input[:,1])
plt.xlabel('length')
plt.ylabel('weight')
plt.legend(('training dataset', 'test dataset'))
plt.show()[결과]
모델 훈련하고, 평가하기
[코드]
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)[결과]
1.0
- 100%의 정확도로 테스트 세트에 있는 모든 생선을 맞혔다.
모델을 이용하여 테스트 데이터 예측하기
[코드]
kn.predict(test_input)[결과]
array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])
[코드]
test_target[결과]
array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])
- 테스트 데이터에 대한 예측 결과가 정답과 모두 일치한다.
- 출처: 혼자 공부하는 머신러닝+딥러닝 (박해선)
.jpg)
데이터 분석을 공부하는 🌱