00. 의사결정나무가 갑자기 왜 나와?
의사결정나무, decision tree에 대해서는 많이들 들어왔을 듯 합니다. 다만 본격적으로 해당 모형이 어떻게 작동하는지에 대해서는 모르는 사람들이 많을 듯 하여 해당 글을 작성하게 되었습니다. 제가 그렇거든요.
회사에서 마케팅팀에서는 타겟마케팅을 진행하는 일이 꽤 많습니다. 그럴 때 브레이즈와 같은 툴을 이용한다면 쉽게 고객을 타겟할 수 있겠지만 가끔은 더 고도화된 형태로 고객들에게 타겟마케팅을 진행하고 싶을 때가 있습니다. 그럴 때 다양한 고객 형태를 고민하게 되는데 비용 효율화의 측면에서는 다음과 같은 고민을 할 수 있습니다. 이 고객에게 내가 괜한 푸시메시지, 혜택을 주고 있는 건 아닐까? 이 고객에게 굳이 추가 혜택을 주지 않더라도 이 고객이 알아서 구매를 잘 할 것 같은 고객이라면 내가 비효율적으로 비용을 쓰고 있는 건 아닐까? 그래서 그런 고객들, 즉 특별히 어떤 추가적인 혜택을 주지 않더라도 구매를 할 것 같은 고객을 분류하고 싶습니다. 가능하면 YES or NO가 아니라 그럴 확률을 점수화해서 보면 더욱 좋겠군요. 그런 데이터분석가와 마케터를 위해서 분류라는 것이 도움이 될 듯 합니다.

모르는 상황에서 보면 사실 점성술이나 다를 바 없는 이야기이기도 합니다. 회사에서도 그런 분들을 설득하기 위해, 그리고 제가 더 잘 이해하기 위해서 이 글을 작성하게 되었습니다 :)
머신러닝에서 분류(Classification)는 데이터를 정의된 클래스 또는 범주로 구분하는 작업을 말합니다. 즉, 지도학습(Supervised Learning)의 한 종류로, 입력 데이터와 그에 해당하는 클래스 정보가 함께 제공되면 모델이 이를 학습하고 새로운 데이터에 대해 예측을 수행하는 방식으로 이루어집니다. 즉, 기존 데이터가 어떤 클래스에 속하는지 알고리즘을 통해 파악한 후 새로운 데이터에 대한 클래스를 판별하는 것입니다. 그러한 분류를 도와주어 의사 결정에 도움이 되는 모델의 대표적인 것이 의사결정나무(결정트리)입니다. 의사결정나무는 데이터를 기반으로 여러 결정 규칙을 생성하고 이를 통해 데이터를 분류하는 알고리즘입니다.
의사결정나무는 특징을 기반으로 데이터를 분할하고, 이에 속하는 데이터들의 클래스를 예측하는 규칙을 생성합니다. 이 규칙들을 트리 구조로 표현하여 직관적이고 해석하기 쉬운 모델을 제공합니다.
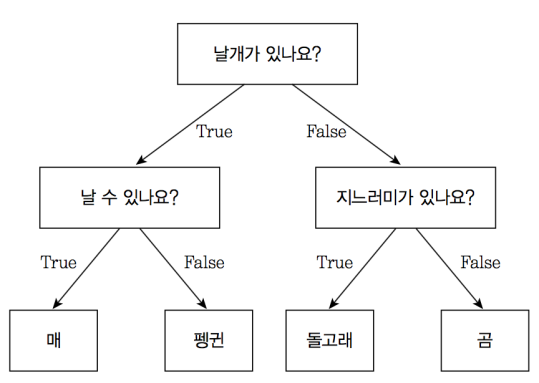
출처 : 귀퉁이 서재
의사결정나무는 주로 분류 문제를 해결하는데 도움이 되지만 뿐만 아니라 회귀, feature selection, outlier detection 분야에서도 많은 도움을 줍니다.
결정트리가 어떻게 실제로 데이터 분석을 하는지 예시를 들어보겠습니다.
어떤 음식 배달 서비스가 고객들에게 할인 쿠폰을 제공하고자 합니다. 이때, 어떤 고객에게 할인 쿠폰을 제공할지를 결정하기 위해 결정트리를 사용할 수 있습니다.
- 데이터 수집: 고객들에게 관련된 정보를 수집합니다. 예를 들어, 고객의 나이, 성별, 거주 지역, 주문 이력, 결제 방식, 고객 등급 등의 데이터를 수집합니다.
- 데이터 전처리: 수집한 데이터를 정리하고 전처리합니다. 예를 들어, 누락된 데이터나 이상치를 처리하고, 범주형 데이터를 숫자형으로 변환하는 등의 작업을 수행합니다.
- 특징(feature) 선택: 결정트리에 사용할 특징(feature)을 선택합니다. 예를 들어, 고객의 나이, 성별, 거주 지역 등이 특징으로 선택될 수 있습니다.
- 데이터 분할: 데이터를 학습 데이터와 테스트 데이터로 분할합니다. 학습 데이터는 결정트리를 학습시키는 데 사용되고, 테스트 데이터는 학습된 결정트리의 성능을 평가하는 데 사용됩니다.
- 결정트리 학습: 학습 데이터를 사용하여 결정트리를 학습시킵니다. 의사결정나무는 데이터를 특징(feature)에 따라 분할하는 과정을 거치며, 정보이득(information gain)이나 지니불순도(Gini impurity) 등의 지표를 사용하여 가장 효과적인 분할을 선택합니다.
- 결정트리 평가: 학습된 결정트리를 사용하여 테스트 데이터에 대해 예측을 수행하고, 예측 결과를 평가합니다. 정확도, 정밀도, 재현율 등의 평가 지표를 사용하여 결정트리의 성능을 평가합니다.
- 모델 개선: 필요에 따라 모델을 개선합니다. 예를 들어, 결정트리의 최대 깊이(maximum depth)를 조절하거나 가지치기(pruning)를 수행하여 과적합(overfitting)을 방지하거나 성능을 향상시킬 수 있습니다.
01. 의사결정나무의 작동 원리
의사결정나무는 데이터를 분석하여 결정 규칙을 생성하는데, 다음과 같은 작동 원리를 가지게 됩니다.
- 데이터 분할 (Data Splitting) : 데이터의 특징들을 기반으로 분할 기준을 설정하고, 해당 기준에 따라 데이터를 분할합니다. 이 때 데이터를 가장 잘 분할하는 특징을 선택하고, 해당 특징의 분할 기준을 결정하는데에 다양한 알고리즘이 사용됩니다.
- 결정 규칙 생성 : 데이터를 분할하면서 생성된 각각의 분할된 영역에 대해 예측을 위한 결정 규칙을 생성합니다. 이 규칙은 분할 기준을 통해 생성되며, 각 분할된 영역에 대해 예측이 가장 정확하게 이루어질 수 있는 규칙을 생성하게 됩니다.
- 트리 구조 형성 : 데이터를 분할하고 결정 규칙을 생성한 후, 이를 트리 구조로 표현합니다. 트리 구조는 root node, branch node, leaf node로 구성되며, 해당 노드를 내려가는 경로가 결정 규칙을 형성합니다.
이렇게 생성된 의사결정나무는 매우 직관적이며 pruning 과정을 통해 데이터의 과적합을 방지할 수 있습니다. 또한 비교적 빠른 예측 속도를 가지고 있으며 직관적이기 때문에 해석하고 설명하는데 매우 용이합니다.
02. 의사결정나무 공부하기
그럼 이제 본격적으로 의사결정나무에 대해서 알아보도록 하겠습니다. 의사결정나무는 기본적으로 데이터를 분할하는 과정에서 레이블의 값이 순수해지도록 분할 기준을 형성합니다. 이러한 분할 기준은 순수, 즉 불순도(impurity)를 최소화하는 것을 목적으로 합니다. 불순도는 분할된 데이터가 얼마나 순수한 상태인지, 즉 각 노드에서의 클래스의 혼잡도를 측정합니다. 대표적인 불순도 지표로는 엔트로피, 지니계수, 분류오차 등이 있습니다. 예를 들어 지니계수는 각 클래스의 확률을 제곱하여 합한 것에서 1을 뺀 값으로 계산됩니다. 즉, 만약 데이터의 클래스가 총 k개이고, 각 클래스의 확률이 P1, P2, ... Pk라면 지니계수는 다음과 같이 계산됩니다.
Gini Index = 1 - (P1^2 + P2^2 + ... + PK^2)
이렇듯 불순도를 최소화는 방향으로 분할 기준을 하게 되는데 이 때 단순히 위 목적만 가지고 진행한다면 데이터에 과적합이 있을 수 있습니다. 따라서 pruning이라는 과정이 필요합니다. pruning, 가지치기는 의사결정나무를 단순화하여 일반화 능력을 향상시키는 과정으로, 어떤 노드에서 규칙을 삭제할 것인지를 결정하는 과정이 필요합니다. 가지치기는 크게 사전가지치기, 사후가지치기로 나뉘게 됩니다. 사전가지치기는 분기를 결정하는 기준을 더 강하게 설정하여 가지의 수를 제한하는 방법입니다. 예를 들어, 최대 깊이를 제한하거나 노드에 속한 샘플의 최소 개수를 설정하는 방식입니다. 사후 가지치기는 의사결정나무 생성 후, 가지치기를 진행합니다. 검증 데이터를 사용하며 예측 성능을 평가하고 이 중 최적인 모델을 선택하는 방식으로 이루어집니다. 대표적으로 교차검증 기반 방식과 비용 복잡도 방식이 있습니다.
다시 보자면 의사결정은 최대한 균일한 데이터 세트를 구성할 수 있도록 분할하는 방향으로 진행됩니다. 균일하다는 것은 데이터 세트 안에 최대한 한 쪽으로 데이터가 구성되는 것을 의미합니다.
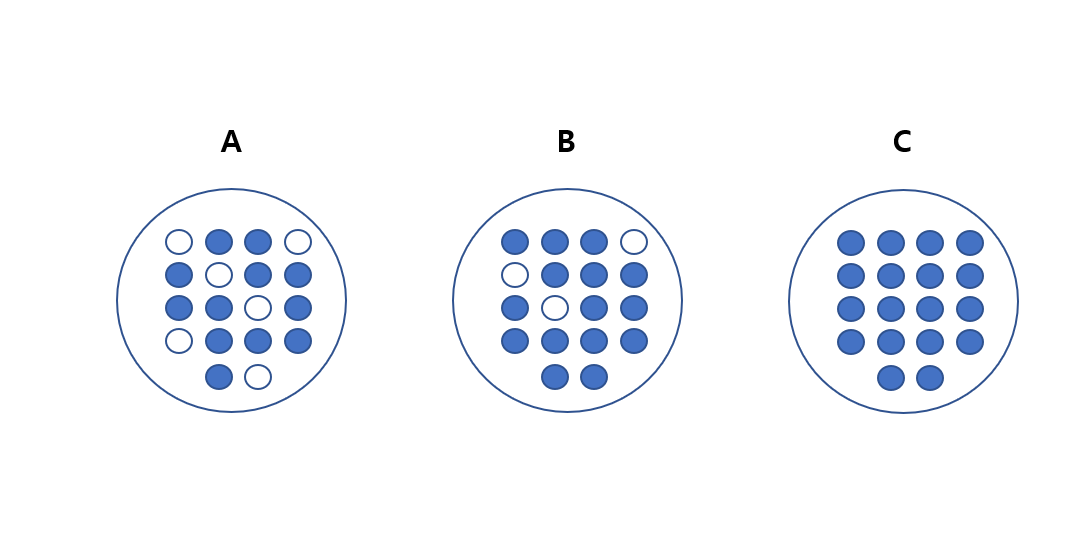
위 그림에서 가장 균일도가 높은 것은 c입니다. 데이터가 균일하면 해당 데이터 세트에서 데이터를 구분하는데 많은 리소스가 필요하지 않다는 의미입니다. 이런 식으로 균일도가 가장 높은 데이터 세트를 구성할 수 있도록 트리는 데이터를 분할하게 됩니다. 이러한 균일도를 측정하는 방법이 위에서 말한 지니계수가 있습니다. 우리가 사이킷런에서 사용하는 DecisionTreeClassifier도 지니계수를 사용합니다.
그리고 의사결정나무는 단일 트리로만 구성될 수도 있지만, 앙상블 기법을 활용할 수도 있습니다. 대표적으로 random forest가 있는데 이는 여러 의사결정나무를 결합하여 예측 결과를 향상시키는 방법입니다.
04. Python에서 살펴보기
파이썬 환경에서 실제 결정 트리를 확인해보기 위해서 사이킷런에서 제공하는 make_classification()을 사용해서 예시 데이터를 생성 후 확인해보도록 하겠습니다.
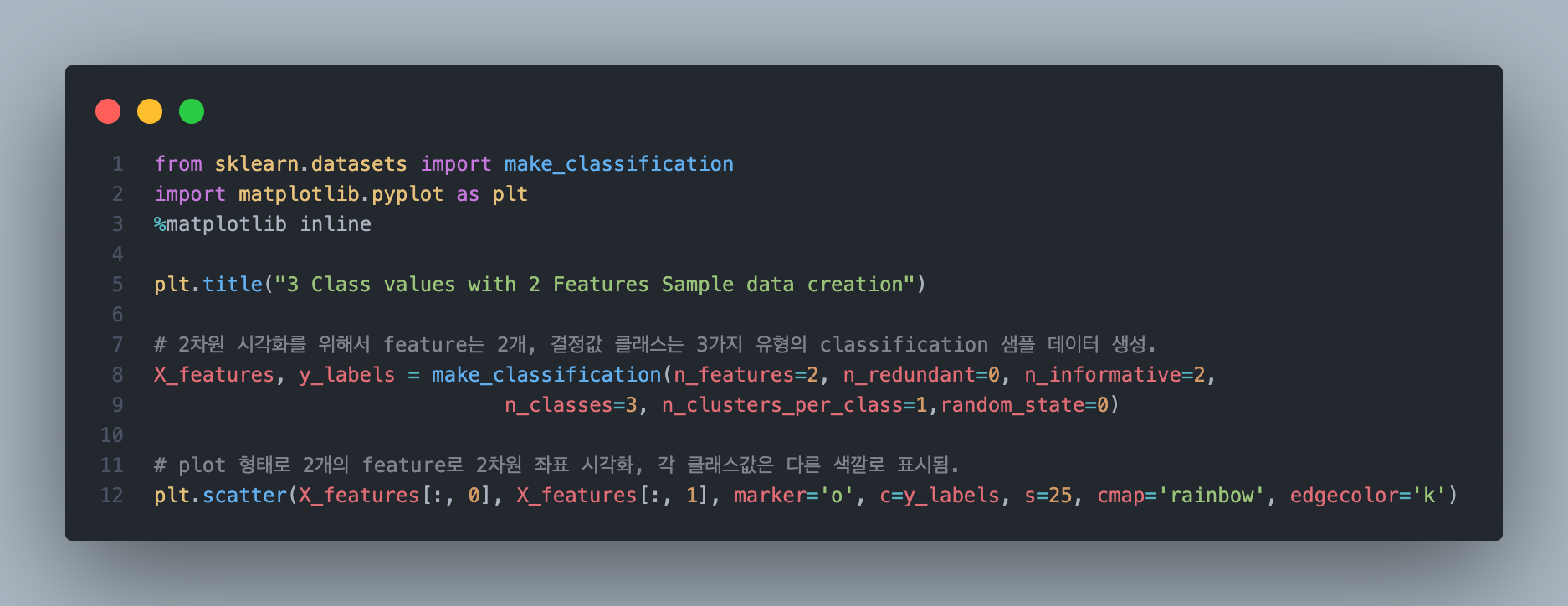
위 코드를 통해 2개의 피처를 가진 데이터를 3개의 클래스에 분류하는 데이터 세트를 생성해보도록 하겠습니다.
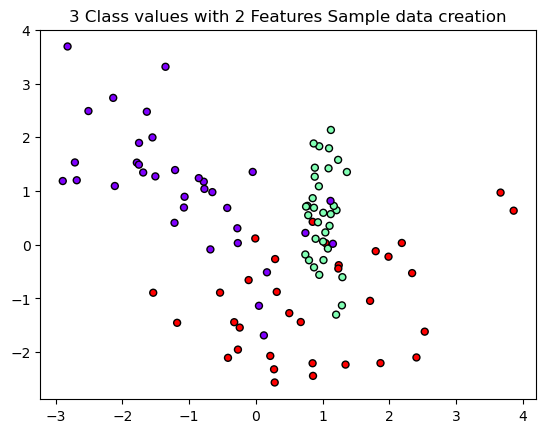
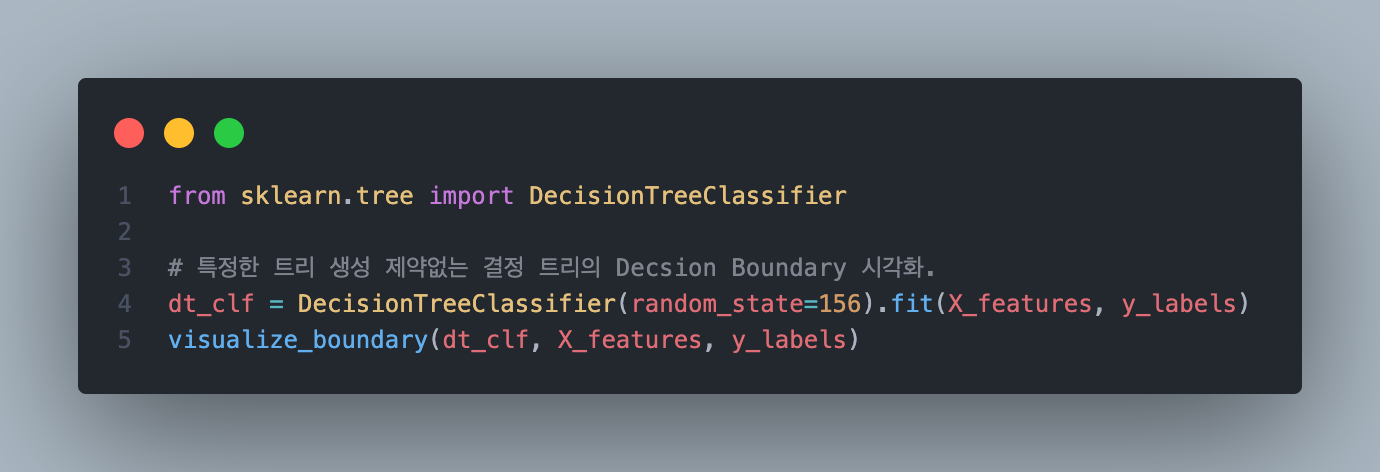
위처럼 디폴트로 결정 트리를 생성해서 분류를 진행하게 되면 아래와 같은 결과를 얻을 수 있습니다.
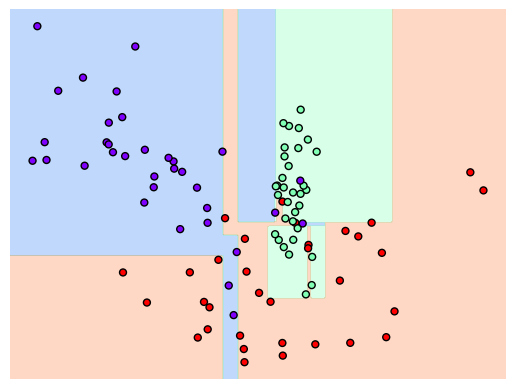
아웃라이어 또한 분류를 하기 위해서 시각화 상 복잡한 형태를 보입니다. 이 때 min_sample_leaf를 조정하여 다르게 시각화를 해보도록 하겠습니다.

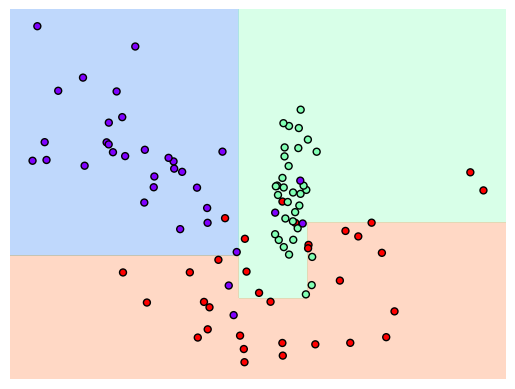
이상치는 무시하면서 더 일반적인 데이터 분류를 할 수 있음을 확인할 수 있습니다.
다음에는 이러한 결정트리를 이용한 랜덤 포레스트와 이러한 모델을 평가하는 방법에 대해서 추가적으로 작성해보고자 합니다.
Reference.
귀퉁이 서재 - 머신러닝 - 4. 결정 트리(Decision Tree)
파이썬 머신러닝 완벽 가이드 - 권철민 지음(위키북스)
