fetch join
fetch join은 조회하는 엔티티와 지연로딩으로 연관된 엔티티를 함께 조회할때 쓰인다고 한다.
지연로딩으로 설정하면 다음과 같은 과정을 거친다.
- 엔티티A와 연관된 엔티티B가 지연로딩으로 설정되어 있다.
- 먼저 엔티티A를 조회하고 엔티티A에서 엔티티B로 접근할 때 엔티티B에 대한 조회쿼리가 나간다.
엔티티A와 B를 한번에 사용하고 싶어도 지연로딩으로 불필요한 쿼리가 발생할 수 있고(N + 1), 이런 상황에 fetch join이 자주 사용된다고 한다.
엔티티의 중복
1:N를 조회할 때 엔티티가 중복될 수 있다.
예를 들어 member1와 member2가 team1에 소속되어 있을 때, team1의 members를 조회하면 데이터가 다음과 같이 조회된다.
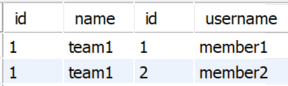
JPQL은 SQL로 번역되어 나가기 때문에 결국 이런 데이터가 조회된다.
JPA의 영속성 컨텍스트에서 team1은 같은 식별자를 가지고 같은 객체를 가리킨다.
하지만 getResultList()로 조회한 결과에는 같은 team1엔티티가 두 번 들어가 있다. 실제 DB에서 넘어온 조회결과가 위와 같기 때문이다.
중복을 줄이고 싶다면 JPQL에 DISTINCT문을 넣어주면 되는데, 단순히 SQL에 DISTINCT를 넣어주는 것 외에 조회된 결과에 중복된 엔티티가 있다면 제거해 주는 역할까지 한다.
앞서 나온 데이터에서는 쿼리에 DISTINCT가 있다고 두 데이터를 같은 데이터로 판단하지 않는다. 결과적으로 DB에서 넘어오는 데이터는 같다.
하지만 넘어온 데이터에서 team1의 엔티티가 중복되어 있다면 JPQL의 DISTINCT가 중복을 제거해 준다고 한다.
해당 내용의 학습을 진행하면서 JPQL에 따로 DISTINCT를 넣어주지 않아도 중복이 제거되어 있길래 찾아보았는데
Hibernate 6부터는 따로 적어주지 않아도 된다고 한다. 링크

