
1. Real-Time CPU Scheduling
실시간 운영체제에서 CPU를 스케줄링을 할 때는 일반적으로 Soft real-time System과 Hard real-time System으로 구분한다. 전자는 실시간 성능을 요구하고 달성하지 못하면 성능 저하되는게 전부(ex. Zoom), 다시 말해 그냥 답답하고 마는 시스템이지만 후자는 주어진 데드라인을 지키지 못하면 목적 자체를 이루지 못하는 엄격한 시스템이다.
이러한 실시간 시스템의 성능에 영향을 주는 요소가 있는데, 바로 "Interrupt latency" 와 "Dispatch latency" 이다.
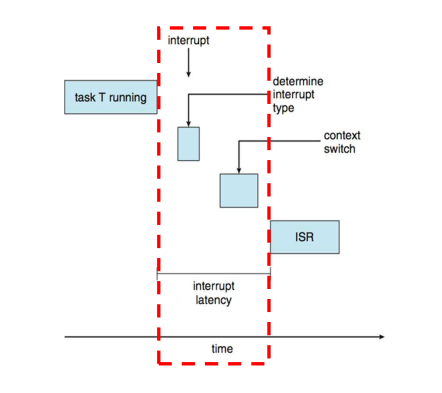
Interrupt latency (인터럽트 지연시간) : CPU에 인터럽트가 발생한 시점부터 해당 인터럽트 처리 루틴이 시작하기까지의 시간. 인터럽트가 발생하면 OS는 일단 수행 중인 명령어를 완수하고 발생한 인터럽트의 종류를 결정한다. 해당 인터럽트 서비스 루틴(ISR)을 사용하여 인터럽트를 처리하기 전에 현재 수행 중인 프로세스의 상태를 저장해 놓아야 한다. 이러한 작업을 모두 수행하는 데 걸리는 시간이 인터럽트 지연시간이다.
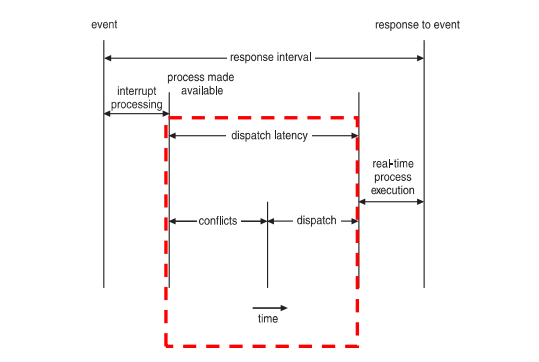
Dispatch latency (디스패치 지연시간) : 스케줄링 연산 후, 선택된 Task가 현재 CPU를 잡기까지 걸리는 시간. CPU를 즉시 사용해야 하는 실시간 Task가 있다면, 실시간 OS는 이 지연시간을 최소화해야 한다.
디스패치 지연을 증가시키는 방해 요소 중 충돌 단계에서는 "커널에서 동작하는 프로세스에 대한 선점"과 "높은 우선순위의 프로세스가 필요한 자원을 낮은 우선순위 프로세스 자원이 방출하는 경우"로 구성되어 있고, 디스패치 단계에는 우선순위가 높은 프로세스를 사용 가능한 CPU에 스케줄한다.
2. Priority-based Scheduling
각각의 프로세스의 중요성에 따라 그 우선순위를 부여하는 방식.실시간 운영체제에서 가장 중요한 기능은 실시간 프로세스에 CPU가 필요할 때 바로 응답을 해주는 것이다. 따라서 실시간 운영체제의 스케줄러는 선점을 이용한 우선순위 기반의 알고리즘을 지원해야만 한다.
Hard real-time System의 경우, 반드시 데드라인을 충족시켜야 하므로 부가적인 스케줄링 기법이 필요하다. 그 전에 처리될 프로세스들의 특성들을 정의해야 하는데 첫 번째로 작업이 "주기성"을 가진다 는 것이다. 즉, 프로세스들은 일정한 간격으로 CPU가 필요하다. 각각의 주기 프로세스들은 CPU를 할당받을 때마다 고정된 수행 시간 t, 실행을 마쳐야 할 데드라인 d와 주기 p가 정해져 있다.
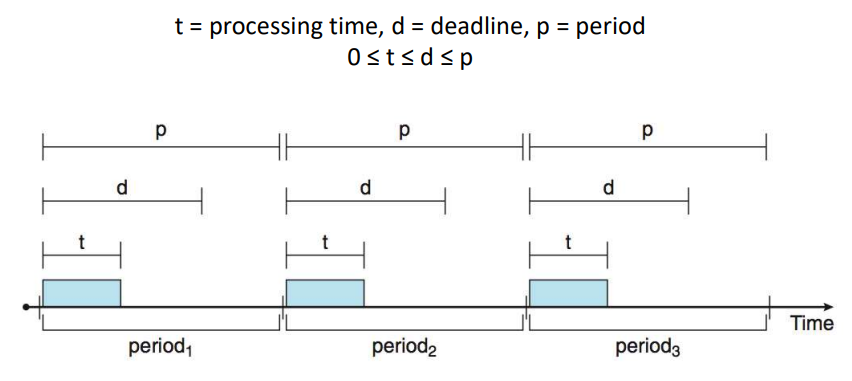
주기 Task의 실행 빈도는 1/p 이다. 스케줄러는 주기, 데드라인, 수행 시간 사이의 관계를 고려하여 데드라인과 주기적 프로세스의 실행 빈도에 따라서 우선순위를 정한다.
3. Rate-Monotonic Scheduling (RM)
각 작업의 주기가 주어졌을 때, 작업의 주기에 반비례하여 우선순위를 할당하는 방식.
즉, 주기가 짧은 작업은 우선순위가 높고, 주기가 긴 작업은 우선순위가 낮다.CPU를 더 자주 필요로 하는 태스크에 더 높은 우선순위를 주려는 것이다.
예를 들어, 두 개의 프로세스 P1, P2가 있다고 해보자. P1의 주기는 50이고 P2의 주기는 100이다. 수행 시간은 각각 20, 35라고 가정하고 각 프로세스의 데드라인은 다음 주기가 시작하기 전까지이다.
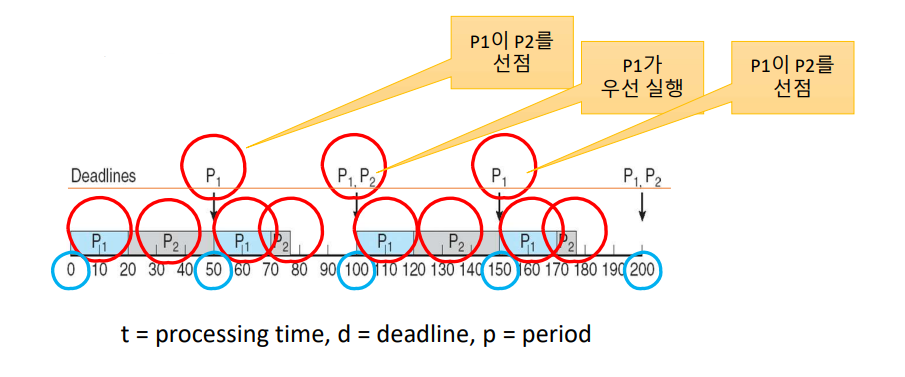
RM 스케줄링을 사용하면 P1의 주기가 P2의 주기보다 짧기 때문에 P1의 우선순위가 P2보다 높다. 그림처럼 P1이 먼저 수행을 시작하여 20에 끝나면 데드라인을 넘기지 않는다. 곧바로 P2가 실행되어 50까지 수행을 끝낸다. 이때 남은 5만큼의 CPU 할당 시간이 남아 있기는 하지만, P1에게 선점된다. P2가 끝나기 전에 P1의 주기가 먼저 도달했기 때문이다. 다시 P1이 20만큼 실행되고 남은 5만큼 P2가 이어서 실행되어 75에 수행을 끝내고 자신의 첫 번째 데드라인을 만족한다. 시스템은 100까지 유휴 시간을 갖다가 P1이 다시 스케줄된다.
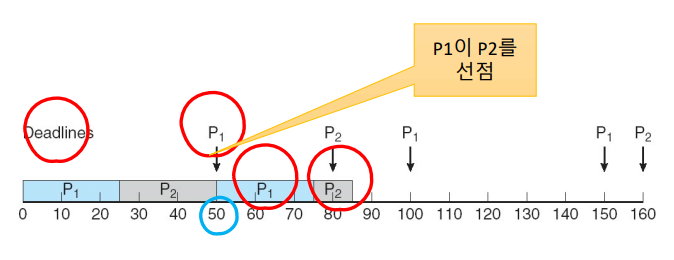
반면, RM 스케줄링 기법을 이용해서 스케줄할 수 없는 프로세스 집합도 있다. 예를 들어, 위의 그림처럼 P1은 주기 50와 25의 수행 시간을 갖고 P2는 주기 80과 35의 수행 시간을 갖는다고 하자. P1의 주기가 더 짧기 때문에 우선순위가 더 높을 것이다. P1은 문제가 없어 보이지만, P2는 자신의 데드라인인 80을 넘어가버렸다.
4. Earliest Deadline First Scheduling (EDF)
데드라인에 따라서 우선순위를 동적으로 부여하는 방식.
데드라인이 빠를수록 우선순위는 높아지고, 늦을수록 낮아진다.프로세스가 실행 가능하게 되면 자신의 데드라인을 시스템에 알려야 하고,우선순위는 새로 실행 가능하게 된 프로세스의 데드라인에 맞춰서 다시 조정된다.이 점이 우선순위가 고정되어 있는 RM 기법과 다른 점이다.
아래 예시를 통해 자세히 알아보자.
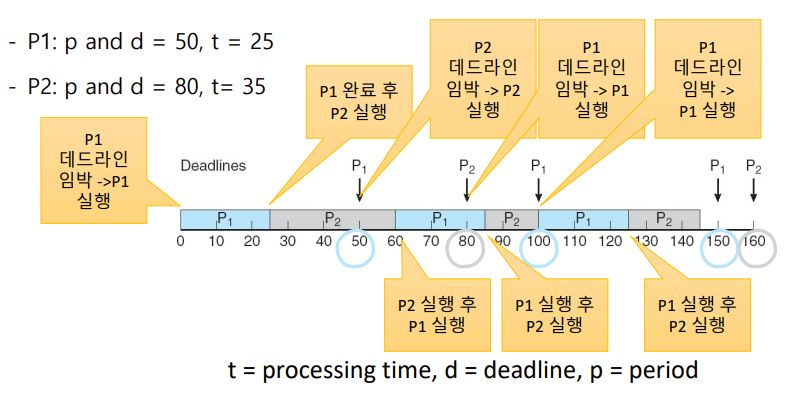
처음에 P1의 데드라인(50)이 더 빠르기 때문에 P1의 우선순위가 더 높다. P1이 실행되고 난 후, RM 방식에서는 시간 50의 다음 주기에 P1이 P2를 선점했던 것과는 달리 EDF 방식에서는 P2가 계속 수행된다. 왜냐하면 P2의 데드라인(80)이 P1의 데드라인(100)보다 빠르기 때문에 이젠 P2의 우선순위가 더 높다. P1은 60에 다시 수행을 시작해서 시간 85에 두 번째 CPU 할당을 끝낸다. 시간이 100 이내이기 때문에 두 번째 데드라인을 만족시켰다. P2는 다시 수행을 시작하고 다음 주기인 100에 P1에게 선점된다. P1의 데드라인(150)이 P2의 데드라인(160)보다 빠르기 때문이다. 125에 P1은 CPU 할당량을 완수하고, P2가 수행을 시작하여 시간 145에 끝나게 되어 데드라인을 만족시킨다. 시간 150까지 시스템은 유휴 시간을 갖고 다시 P1이 스케줄되어 수행을 시작한다.
정리 : RM 알고리즘과 달리 EDF 알고리즘은 프로세스들이 주기적일 필요도 없고, CPU 할당 시간도 상수 값으로 정해질 필요가 없다. 그러나 프로세스가 실행 가능해질 때 자신의 데드라인을 스케줄러에게 알려줘야 한다.
