
🍽️ Set 자료 구조를 이용한 직접 구현
package collection.set;
import java.util.Arrays;
public class MyHashSetV0 {
private int[] elements = new int[10];
private int size = 0;
// O(n)
public boolean add(int value) {
if (contains(value)) {
return false;
}
elements[size] = value;
size++;
return true;
}
// 중복 체크: O(n)
public boolean contains(int value) {
for (int element : elements) {
if (element == value) {
return true;
}
}
return false;
}
public int size() {
return size;
}
@Override
public String toString() {
return "MyHashSetV0{" +
"elementData=" + Arrays.toString(Arrays.copyOf(elements, size)) +
", size=" + size +
'}';
}
}위 코드에 중복을 허용하지 않고, 순서를 보장하지 않는 Set 자료 구조를 적용해보면서 리팩토링 해보도록 하자. 위 코드는 add() 메서드로 중복 데이터가 있는지 없는지 항상 확인해야 하는 번거로움이 있다. 데이터를 찾을 때도 전체 데이터를 다 뒤져봐야 해서 성능이 O(n)으로 느리다. 해시 알고리즘을 이용해서 성능을 O(1)으로 끌어 올리자.
package collection.set;
import java.util.Arrays;
import java.util.LinkedList;
public class MyHashSetV1 {
static final int DEFAULT_CAPACITY = 16;
LinkedList<Integer>[] buckets;
private int size;
private int capacity = DEFAULT_CAPACITY;
public MyHashSetV1() {
initBuckets();
}
public MyHashSetV1(int capacity) {
this.capacity = capacity;
initBuckets();
}
// 연결 리스트들로 배열을 채움
private void initBuckets() {
buckets = new LinkedList[capacity];
for (int i = 0; i < capacity; i++) {
buckets[i] = new LinkedList<>();
}
}
// 중복 데이터는 저장하지 않음
public boolean add(int value) {
int hashIndex = hashIndex(value); // 해시 인덱스 사용
LinkedList<Integer> bucket = buckets[hashIndex];
if (bucket.contains(value)) {
return false;
}
bucket.add(value);
size++;
return true;
}
// Set에 searchValue가 있는지 체크
public boolean contains(int searchValue) {
int hashIndex = hashIndex(searchValue); // 해시 인덱스 사용
LinkedList<Integer> bucket = buckets[hashIndex];
return bucket.contains(searchValue);
}
// Set에 있는 값을 제거
public boolean remove(int value) {
int hashIndex = hashIndex(value); // 해시 인덱스 사용
LinkedList<Integer> bucket = buckets[hashIndex];
boolean result = bucket.remove(Integer.valueOf(value));
if (result) {
size--;
return true;
} else {
return false;
}
}
public int hashIndex(int value) {
return value % capacity;
}
public int getSize() {
return size;
}
@Override
public String toString() {
return "MyHashSetV1{" +
"buckets=" + Arrays.toString(buckets) +
", size=" + size +
'}';
}
}배열 안에 연결 리스트를 추가하고, 그 연결 리스트 안에 데이터가 추가되는 구조다. 해시 충돌이 발생할 경우, 그 연결 리스트 안에 여러 데이터가 저장될 수 있도록 한 것이다. 실행 결과를 살펴 보자.
package collection.set;
public class MyHashSetV1Main {
public static void main(String[] args) {
MyHashSetV1 set = new MyHashSetV1(10);
set.add(1);
set.add(2);
set.add(5);
set.add(8);
set.add(14);
set.add(99);
set.add(9); // 해시 인덱스 중복
System.out.println(set);
// 검색
int searchValue = 9;
boolean result = set.contains(searchValue);
System.out.println("set.contains(" + searchValue + ") = " + result);
// 삭제
boolean removeResult = set.remove(searchValue);
System.out.println("removeResult = " + removeResult);
System.out.println(set);
}
}
/*
MyHashSetV1{buckets=[[], [1], [2], [], [14], [5], [], [], [8], [99, 9]], size=7}
set.contains(9) = true
removeResult = true
MyHashSetV1{buckets=[[], [1], [2], [], [14], [5], [], [], [8], [99]], size=6}
*/현재 99와 9가 같은 해시 인덱스 값을 갖기 때문에 해시 충돌이 일어났다. 따라서 9번 인덱스 안에 있는 연결 리스트에 함께 값들이 삽입되었다. 아래 9를 검색하는 로직을 작성하면, 9번 인덱스의 연결 리스트에 있는 모든 데이터와 비교를 하면서 찾는다.
지금은 단순히 해당 인덱스에 그 인덱스에 해당하는 숫자 값을 저장하고 있어서 등록, 검색, 삭제 작업이 아주 단순하다. 하지만 데이터가 숫자가 아닌 문자열이라면 어떻게 될까? 문자열인데 해시 인덱스를 어떻게 적용하지?
🎁 문자열 해시 코드
아래 코드를 살펴보자.
package collection.set;
public class StringHashMain {
static final int CAPACITY = 10;
public static void main(String[] args) {
char charA = 'A';
char charB = 'B';
System.out.println(charA + " = " + (int)charA); // 정수형으로 캐스팅
System.out.println(charB + " = " + (int)charB); // 정수형으로 캐스팅
// 해시 코드
System.out.println("=== 해시 코드 ===");
System.out.println("hashCode(A) = " + hashCode("A"));
System.out.println("hashCode(B) = " + hashCode("B"));
System.out.println("hashCode(AB) = " + hashCode("AB"));
// 해시 인덱스
System.out.println("=== 해시 인덱스 ===");
System.out.println("hashIndex(A) = " + hashIndex(hashCode("A")));
System.out.println("hashIndex(B) = " + hashIndex(hashCode("B")));
System.out.println("hashIndex(AB) = " + hashIndex(hashCode("AB")));
}
// 문자열의 아스키 코드 값 단순 합산
static int hashCode(String str) {
char[] charArr = str.toCharArray();
int sum = 0;
for (char c : charArr) {
sum += c;
}
return sum;
}
static int hashIndex(int value) {
return value % CAPACITY;
}
}
/*
A = 65
B = 66
=== 해시 코드 ===
hashCode(A) = 65
hashCode(B) = 66
hashCode(AB) = 131
=== 해시 인덱스 ===
hashIndex(A) = 5
hashIndex(B) = 6
hashIndex(AB) = 1
*/보다시피 모든 문자는 본인만의 고유한 숫자를 가지고 있다. 연속된 문자의 경우, 해당 문자들의 고유한 값을 단순히 더하면 된다. 이 점을 이용해서 위 코드에서 hashCode() 메서드를 만들었다. 이제 문자를 숫자 형식으로 뽑아낼 수 있기 때문에 원래 숫자를 이용했던 것처럼 해시 인덱스를 사용할 수 있게 되었다.
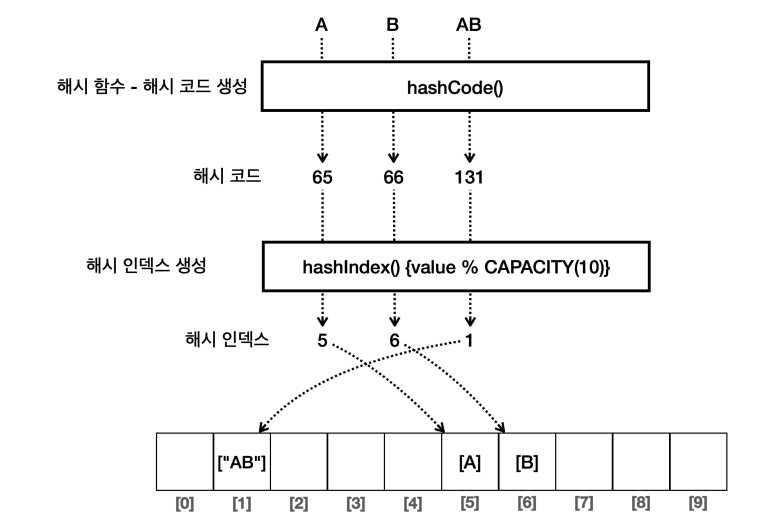
문자가 hashCode() 메서드를 거쳐 정수 형식으로 변환된 해시 코드가 반환되면, 그걸 바탕으로 해시 인덱스를 생성해서 배열의 인덱스로 활용하는 것이다.
🤔 해시 함수?
해시 함수는 임의의 길이의 데이터를 입력 받아서 고정된 길이의 해시값(해시 코드)을 출력하는 함수다. 여기서 고정된 길이라는 것은 저장 공간의 크기를 뜻한다. 예를 들어 int 형의 경우, 값 하나마다 4byte씩 고정된 길이만큼 차지하고 있다. 해시 함수는 같은 데이터를 입력하면 항상 같은 해시 코드(데이터를 대표하는 값)를 출력한다는 특징을 가지고 있다. 하지만 여전히 해시 충돌은 고려해야 한다. (ex. “BC” 의 해시 코드는 133인데, “AD”의 해시 코드도 133이다.)
정리하자면…
-
해시 코드: 데이터를 대표하는 값
-
해시 함수: 해시값을 생성하는 함수
-
해시 인덱스: 해시값을 사용해서 데이터의 저장 위치를 결정하는 값으로, 보통 해시 코드의 결과에 배열의 크기를 나눠서 구한다.
이제 숫자가 오든 문자가 오든 해시 코드를 이용해서 해시 인덱스를 구할 수 있다는 자신감이 생겼다. 하지만 안타깝게도 자바에는 다른 타입도 많고, 심지어 개발자가 직접 정의한 사용자 정의 타입의 경우, 어떻게 해시 코드를 구할지 막막하다...
🤔 자바의 hashCode()
모든 타입을 해시 자료 구조에 저장하고 싶다면, 모든 객체가 숫자 해시 코드를 제공할 수 있어야 할 것이다. 근데 생각해보니, Object 클래스에도 hashCode() 메서드가 있었던 것 같다. 오버라이딩 해서 사용하라는 자바 형님의 큰 뜻으로 보인다. 이 메서드의 기본 구현은 객체의 참조값을 기반으로 해시 코드를 생성한다. 객체의 인스턴스 참조값이 다르면 해시 코드가 다르다는 것이다. 좀 다듬어서 사용할 필요가 있다.
package collection.set.member;
import java.util.Objects;
public class Member {
private String id;
public Member(String id) {
this.id = id;
}
public String getId() {
return id;
}
// id값을 기준으로 비교
@Override
public boolean equals(Object object) {
if (this == object) return true;
if (object == null || getClass() != object.getClass()) return false;
Member member = (Member) object;
return Objects.equals(id, member.id);
}
// id값을 기준으로 해시 코드 생성
@Override
public int hashCode() {
return Objects.hash(id);
}
@Override
public String toString() {
return "Member{" +
"id='" + id + '\'' +
'}';
}
}package collection.set;
import collection.set.member.Member;
public class JavaHashCodeMain {
public static void main(String[] args) {
// Object의 기본 해시 코드는 객체의 참조값을 기반으로 생성된다.
Object obj1 = new Object();
Object obj2 = new Object();
System.out.println("obj1.hashCode() = " + obj1.hashCode()); // 객체의 참조값이 반환됨
System.out.println("obj2.hashCode() = " + obj2.hashCode()); // 객체의 참조값이 반환됨
// 각 클래스마다 해시 코드를 오버라이딩 해 놓은 상태
Integer i = 10;
String str1 = "A";
String str2 = "AB";
System.out.println("정수 10의 hashCode: " + i.hashCode());
System.out.println("문자 A의 hashCode: " + str1.hashCode());
System.out.println("문자열 AB의 hashCode: " + str2.hashCode());
// 해시 코드는 음수 값을 가질 수 있다.
System.out.println("-1의 hashCode: " + Integer.valueOf(-1).hashCode());
// 동일성/동등성 비교
Member member1 = new Member("id1");
Member member2 = new Member("id1");
// equals 메서드와 해시 코드를 오버라이딩 하지 않은 경우와 그렇지 않은 경우를 비교
System.out.println("(member1 == member2) = " + (member1 == member2));
System.out.println("member1 equals member2 = " + (member1.equals(member2)));
System.out.println("member1의 해시 코드: " + member1.hashCode());
System.out.println("member2의 해시 코드: " + member2.hashCode());
}
}
/*
obj1.hashCode() = 713338599
obj2.hashCode() = 1067040082
정수 10의 hashCode: 10
문자 A의 hashCode: 65
문자열 AB의 hashCode: 2081
-1의 hashCode: -1
(member1 == member2) = false
member1 equals member2 = true
member1의 해시 코드: 104054
member2의 해시 코드: 104054
*/Object 클래스가 제공하는 hashCode() 메서드의 경우, 각각의 인스턴스 참조값을 해시 코드로 사용한다. 따라서 현재 obj1과 obj2의 해시 코드값이 다른 것을 확인할 수 있다. 다른 자바 클래스에서는 내부 값을 기반으로 해시 코드를 구할 수 있도록 hashCode() 메서드를 오버라이딩 해야 한다. 참고로 해시 코드는 음수값을 가질 수도 있다.
위의 Member 클래스에서는 회원의 id를 통해 논리적으로 같은 회원인지 판단하도록 Object 클래스의 hashCode() 메서드를 오버라이딩 했다. 따라서 인스턴스의 참조값이 다르다 하더라도 id 값이 같다면 같은 해시 코드를 반환한다. 만일 오버라이딩 하지 않는다면 아래처럼 Object의 hashCode() 메서드가 사용되기 때문에 다른 해시 코드를 반환한다.

이제 모든 데이터 타입을 저장할 수 있도록 코드를 리팩토링 해보자.
package collection.set;
import java.util.Arrays;
import java.util.LinkedList;
public class MyHashSetV2 {
static final int DEFAULT_CAPACITY = 16;
private LinkedList<Object>[] buckets; // 모든 데이터 타입을 넣을 수 있도록 함
private int size;
private int capacity = DEFAULT_CAPACITY;
public MyHashSetV2() {
initBuckets();
}
public MyHashSetV2(int capacity) {
this.capacity = capacity;
initBuckets();
}
private void initBuckets() {
buckets = new LinkedList[capacity];
for (int i = 0; i < capacity; i++) {
buckets[i] = new LinkedList<>();
}
}
public boolean add(Object value) {
int hashIndex = hashIndex(value);
LinkedList<Object> bucket = buckets[hashIndex];
if (bucket.contains(value)) {
return false;
}
bucket.add(value);
size++;
return true;
}
public boolean contains(Object searchValue) {
int hashIndex = hashIndex(searchValue);
LinkedList<Object> bucket = buckets[hashIndex];
return bucket.contains(searchValue);
}
public boolean remove(Object value) {
int hashIndex = hashIndex(value);
LinkedList<Object> bucket = buckets[hashIndex];
boolean result = bucket.remove(value);
if (result) {
size--;
return true;
} else {
return false;
}
}
public int hashIndex(Object value) {
// Object의 hashCode() 메서드 활용
// 음수가 나올 수도 있으므로 절댓값 처리
return Math.abs(value.hashCode()) % capacity;
}
public int getSize() {
return size;
}
@Override
public String toString() {
return "MyHashSetV2{" +
"buckets=" + Arrays.toString(buckets) +
", size=" + size +
", capacity=" + capacity +
'}';
}
}모든 타입을 저장할 수 있도록 buckets는 Object를 사용하도록 변경하고, 추가, 검색, 삭제할 때도 모든 데이터 타입을 대상으로 수행할 수 있도록 변경했다. 그리고 hashIndex() 부분이 변경되었다. 먼저 Object 클래스의 hashCode() 메서드를 이용하여 해시 코드를 찾아서 거기에 배열의 크기로 나머지 연산을 수행하여 해시 인덱스를 계산한다. 아까 말했다시피 hashCode()의 결과가 음수가 나올 수도 있기 때문에 절댓값 처리를 해줬다.
package collection.set;
public class MyHashSetV2Main1 {
public static void main(String[] args) {
MyHashSetV2 set = new MyHashSetV2(10);
set.add("A");
set.add("B");
set.add("C");
set.add("D");
set.add("AB");
set.add("SET");
System.out.println(set);
System.out.println("A의 해시 코드: " + "A".hashCode());
System.out.println("B의 해시 코드: " + "B".hashCode());
System.out.println("AB의 해시 코드: " + "AB".hashCode());
System.out.println("SET의 해시 코드: " + "SET".hashCode());
// 검색
String searchValue = "SET";
boolean result = set.contains(searchValue);
System.out.println("set.contains(" + searchValue + "): " + result);
}
}
/*
MyHashSetV2{buckets=[[], [AB], [], [], [], [A], [B, SET], [C], [D], []], size=6, capacity=10}
A의 해시 코드: 65
B의 해시 코드: 66
AB의 해시 코드: 2081
SET의 해시 코드: 81986
set.contains(SET): true
*/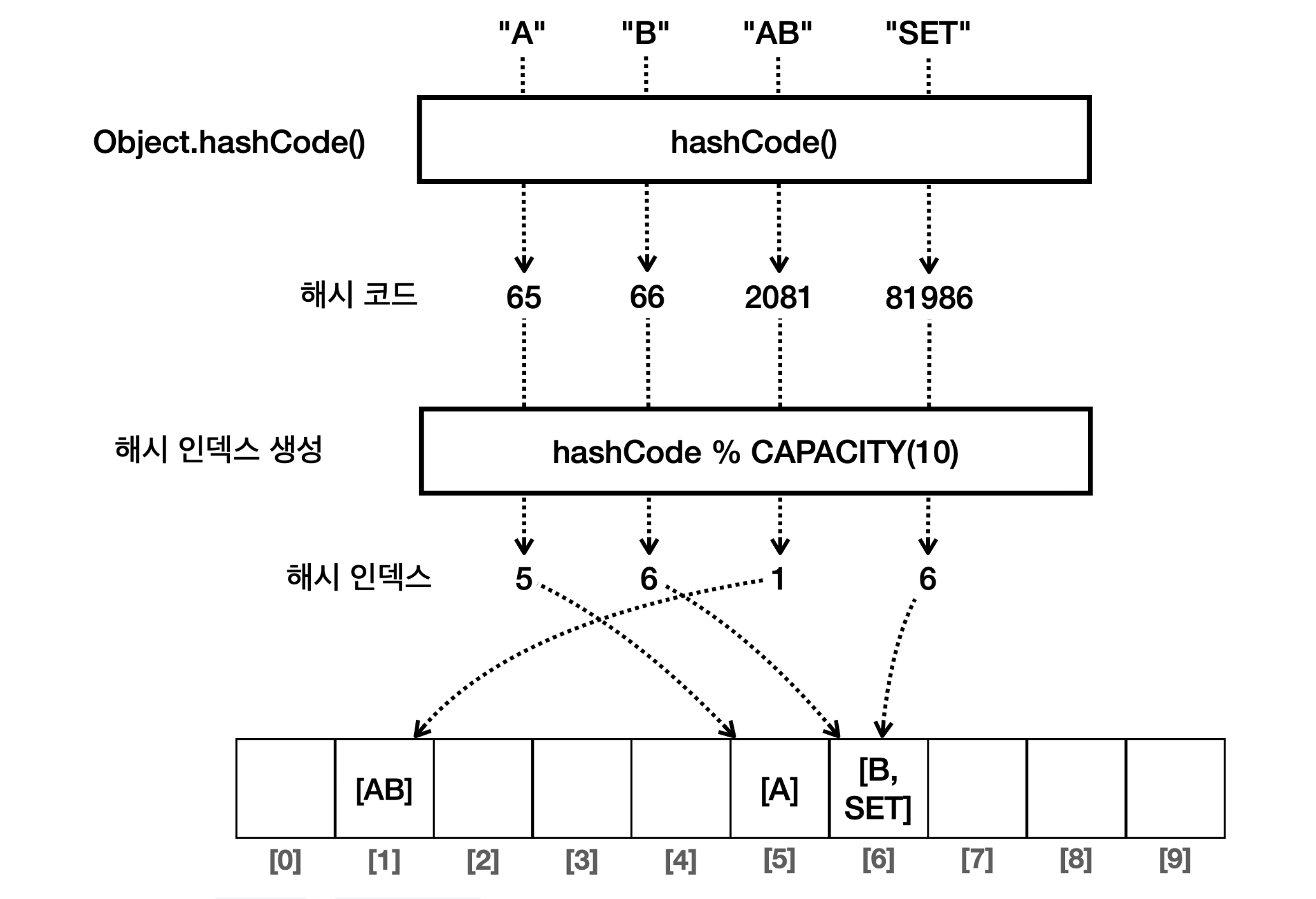
알다시피, String 클래스에는 hashCode() 메서드가 오버라이딩 되어 있기 때문에 그냥 사용해도 된다. 그렇게 반환된 해시 코드를 기반으로 해시 인덱스를 생성한다. 이제 모든 데이터 타입을 연결 리스트에 보관할 수 있게 되었다. 근데 여기서 매우 조심해야 할 점이 있는데, hashCode() 메서드 뿐만 아니라, equals() 메서드도 반드시 구현해야 한다는 점이다. 아래 코드를 보자.
package collection.set;
import collection.set.member.Member;
public class MyHashSetV2Main2 {
public static void main(String[] args) {
MyHashSetV2 set = new MyHashSetV2(10);
Member hi = new Member("hi");
Member java = new Member("java");
Member spring = new Member("spring");
Member jpa = new Member("JPA"); // 대문자인 점을 주의!
System.out.println("hi의 해시 코드: " + hi.hashCode());
System.out.println("java 해시 코드: " + java.hashCode());
System.out.println("spring의 해시 코드: " + spring.hashCode());
System.out.println("jpa의 해시 코드: " +jpa.hashCode());
set.add(hi);
set.add(java);
set.add(spring);
set.add(jpa);
System.out.println(set);
// 검색
Member searchValue = new Member("JPA");
boolean result = set.contains(searchValue);
System.out.println("set.contains(" + searchValue + ") = " + result);
}
}
/*
hi의 해시 코드: 3360
java 해시 코드: 3254849
spring의 해시 코드: -895679956
jpa의 해시 코드: 73690
MyHashSetV2{buckets=[[Member{id='hi'}, Member{id='JPA'}], [], [], [], [], [], [Member{id='spring'}], [], [], [Member{id='java'}]], size=4, capacity=10}
set.contains(Member{id='JPA'}) = true
*/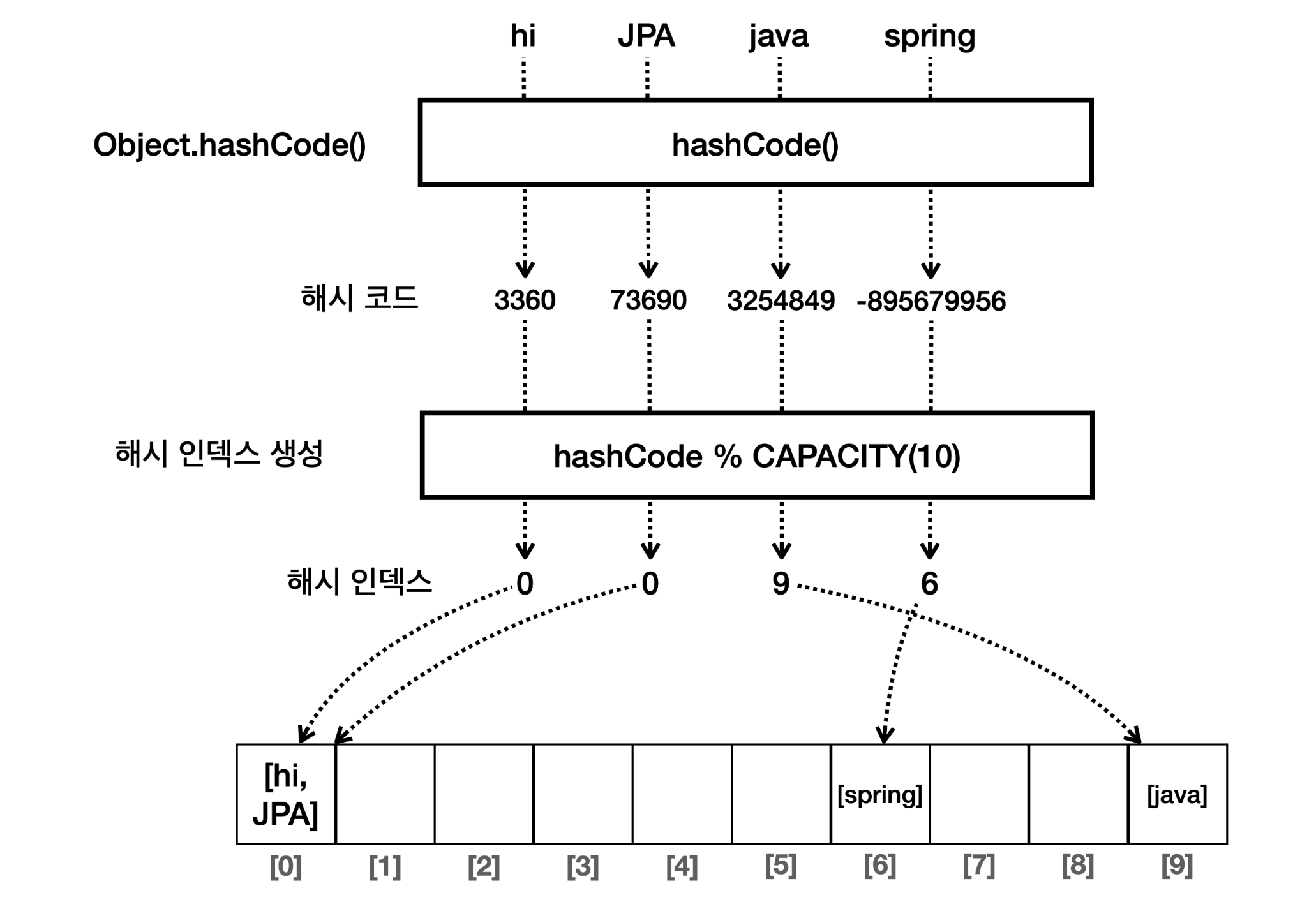
원래 하던대로 잘 됐는데? equals() 메서드를 왜 구현해야 한다는거지? 그냥 사용하면 될 것 같은데… 근데 만약 “JPA" 를 검색한다고 하면, 0번 인덱스를 뒤져봐야 한다. 그 인덱스 안에 들어있는 각각의 값과 비교할 때 equals() 메서드가 사용되는 것이다.
💥 equals(), hashCode()의 중요성
위처럼 해시 충돌이 일어날 때를 대비해서 equals() 메서드를 재정의해야 한다는 것이다. 해시 인덱스가 같다 하더라도 실제 저장된 데이터는 다를 수 있기 때문에, 특정 인덱스에 데이터가 하나만 있어도 equals() 메서드로 찾고 있는 데이터가 맞는지 검증해야 한다. 실제로 구현하지 않으면 여러 문제가 발생할 수 있다. “데이터는 잘 저장되어 있는데… 왜 값이 제대로 안 나오지…??” 그래도 그닥 와 닿지 않는다… 그렇다면 equals() 메서드나 hashCode() 메서드를 구현하지 않는다면 어떤 문제가 발생하는지 살펴보자.
1. hashCode(), equals()를 모두 구현하지 않은 경우
package collection.set.member;
// hashCode()와 equals() 구현 안 한 경우
// 자동으로 Object가 제공하는 hashCode()와 equals()를 사용한다.
public class MemberNoHashNoEquals {
private String id;
public MemberNoHashNoEquals(String id) {
this.id = id;
}
public String getId() {
return id;
}
@Override
public String toString() {
return "MemberNoHashNoEquals{" +
"id='" + id + '\'' +
'}';
}
}package collection.set.member;
import collection.set.MyHashSetV2;
public class HashAndEqualsMain1 {
public static void main(String[] args) {
MyHashSetV2 set = new MyHashSetV2(10);
MemberNoHashNoEquals m1 = new MemberNoHashNoEquals("A");
MemberNoHashNoEquals m2 = new MemberNoHashNoEquals("A");
System.out.println("m1.hashCode() = " + m1.hashCode());
System.out.println("m2.hashCode() = " + m2.hashCode());
System.out.println("m1.equals(m2) = " + m1.equals(m2));
set.add(m1);
set.add(m2);
System.out.println(set); // Set 자료 구조인데 데이터가 중복으로 들어갔다...? 이미 망한 상황
// 검색 실패
MemberNoHashNoEquals searchValue = new MemberNoHashNoEquals("A");
System.out.println("searchValue의 hashCode(): " + searchValue.hashCode());
boolean contains = set.contains(searchValue);
System.out.println("contains = " + contains);
}
}
/*
m1.hashCode() = 1247233941
m2.hashCode() = 140435067
m1.equals(m2) = false
MyHashSetV2{buckets=[[], [MemberNoHashNoEquals{id='A'}], [], [], [], [], [], [MemberNoHashNoEquals{id='A'}], [], []], size=2, capacity=10}
searchValue의 hashCode(): 295530567
contains = false
*/보다시피 m1과 m2의 경우 같은 “A” 라는 문자를 가지고 있지만 hashCode()를 오버라이딩 하지 않았기 때문에 참조값이 다르게 출력된다. 데이터를 검색할 때도 전혀 다른 해시값을 가지고 있기 때문에 엉뚱한 위치에서 데이터를 찾고 있다.
2. hashCode()는 구현했지만, equals()는 구현하지 않은 경우
package collection.set.member;
import java.util.Objects;
// hashCode()만 구현한 경우
public class MemberOnlyHash {
private String id;
public MemberOnlyHash(String id) {
this.id = id;
}
public String getId() {
return id;
}
// hashCode만 오버라이딩 해 놓은 상태
@Override
public int hashCode() {
return Objects.hash(id);
}
@Override
public String toString() {
return "MemberOnlyHash{" +
"id='" + id + '\'' +
'}';
}
}package collection.set.member;
import collection.set.MyHashSetV2;
public class HashAndEqualsMain2 {
public static void main(String[] args) {
MyHashSetV2 set = new MyHashSetV2(10);
MemberOnlyHash m1 = new MemberOnlyHash("A");
MemberOnlyHash m2 = new MemberOnlyHash("A");
System.out.println("m1.hashCode() = " + m1.hashCode());
System.out.println("m2.hashCode() = " + m2.hashCode());
System.out.println("m1.equals(m2) = " + m1.equals(m2)); // 객체의 참조값이 다르기 때문에 false를 반환
set.add(m1);
set.add(m2);
System.out.println(set); // 해시 인덱스가 같으니까 일단 같은 위치에 들어감.
// 검색 실패
MemberOnlyHash searchValue = new MemberOnlyHash("A");
System.out.println("searchValue의 hashCode(): " + searchValue.hashCode()); // 해시 코드도 같은데 왜 검색이 안 되지...?
boolean contains = set.contains(searchValue);
System.out.println("contains = " + contains);
// m1과 m2의 참조값은 엄연히 다른 것을 확인할 수 있다. (+ searchValue도 다름)
System.out.println("System.ref(m1) = " + System.identityHashCode(m1));
System.out.println("System.ref(m2) = " + System.identityHashCode(m2));
System.out.println("System.ref(searchValue) = " + System.identityHashCode(searchValue));
}
}
/*
m1.hashCode() = 96
m2.hashCode() = 96
m1.equals(m2) = false
MyHashSetV2{buckets=[[], [], [], [], [], [], [MemberOnlyHash{id='A'}, MemberOnlyHash{id='A'}], [], [], []], size=2, capacity=10}
searchValue의 hashCode(): 96
contains = false
m1과 m2, searchValue 모두 참조값이 서로 다르다.
System.ref(m1) = 357863579
System.ref(m2) = 1811044090
System.ref(searchValue) = 745160567
*/hashCode()는 오버라이딩 했기 때문에 같은 해시 인덱스에 데이터가 저장된다. 하지만 중복 데이터를 체크해야 하는데 equals() 메서드는 오버라이딩 하지 않았기 때문에 Object의 equals()를 사용할 것이다. 따라서 인스턴스의 참조값이 다르므로 false가 반환된 것을 볼 수 있다. 그래서 그냥 중복 데이터가 없다고 판단하고 m1과 m2를 모두 저장하는 것이다.
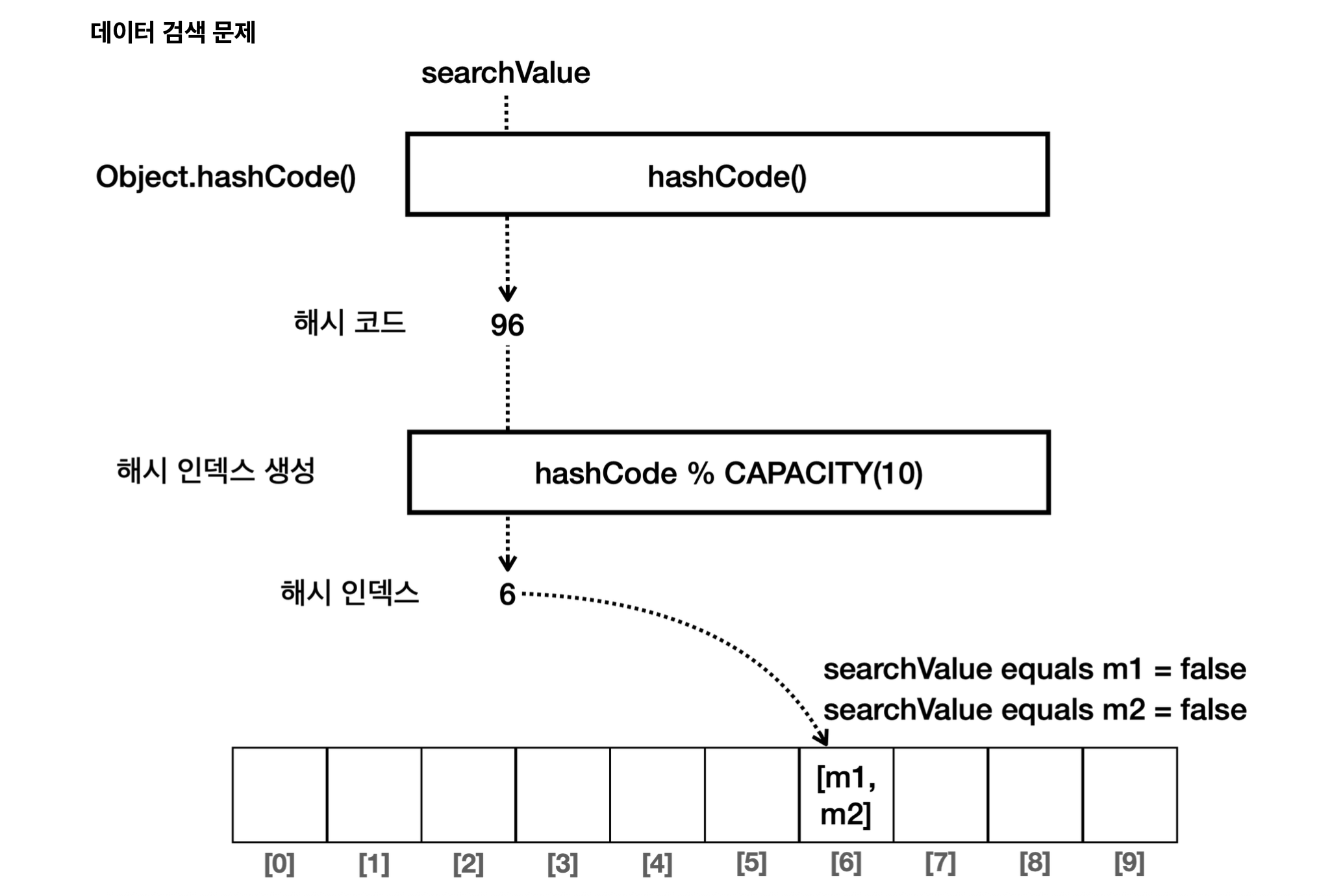
그리고 “A” 라는 데이터를 검색하기 위해 searchValue를 따로 생성했는데, 얘는 6번 인덱스로 정확히 찾아가긴 한다. 찾아가서 Object 클래스의 equals() 메서드를 통해 해당 데이터가 있는지 확인하는데 당연하게도 데이터를 찾지 못하고 방황한다. 왜냐? m1, m2, searchValue 모두 참조값이 다르기 때문에...
3. hashCode(), equals() 모두 구현한 경우
위에서 살펴본 문제들 때문에 두 가지 메서드를 반드시 재정의해야 하는 것이다. 기존의 Member 클래스를 활용해보자.
package collection.set.member;
import collection.set.MyHashSetV2;
public class HashAndEqualsMain3 {
public static void main(String[] args) {
// 중복 등록 되지 않음
MyHashSetV2 set = new MyHashSetV2(10);
Member m1 = new Member("A");
Member m2 = new Member("A");
System.out.println("m1.hashCode() = " + m1.hashCode());
System.out.println("m2.hashCode() = " + m2.hashCode());
System.out.println("m1.equals(m2) = " + m1.equals(m2));
set.add(m1);
set.add(m2);
System.out.println(set);
// 검색 성공
Member searchValue = new Member("A");
System.out.println("searchValue의 hashCode(): " + searchValue.hashCode()); // 해시 코드도 같은데 왜 검색이 안 되지...?
boolean contains = set.contains(searchValue);
System.out.println("contains = " + contains);
}
}
/*
m1.hashCode() = 96
m2.hashCode() = 96
m1.equals(m2) = true
MyHashSetV2{buckets=[[], [], [], [], [], [], [Member{id='A'}], [], [], []], size=1, capacity=10}
searchValue의 hashCode(): 96
contains = true
*/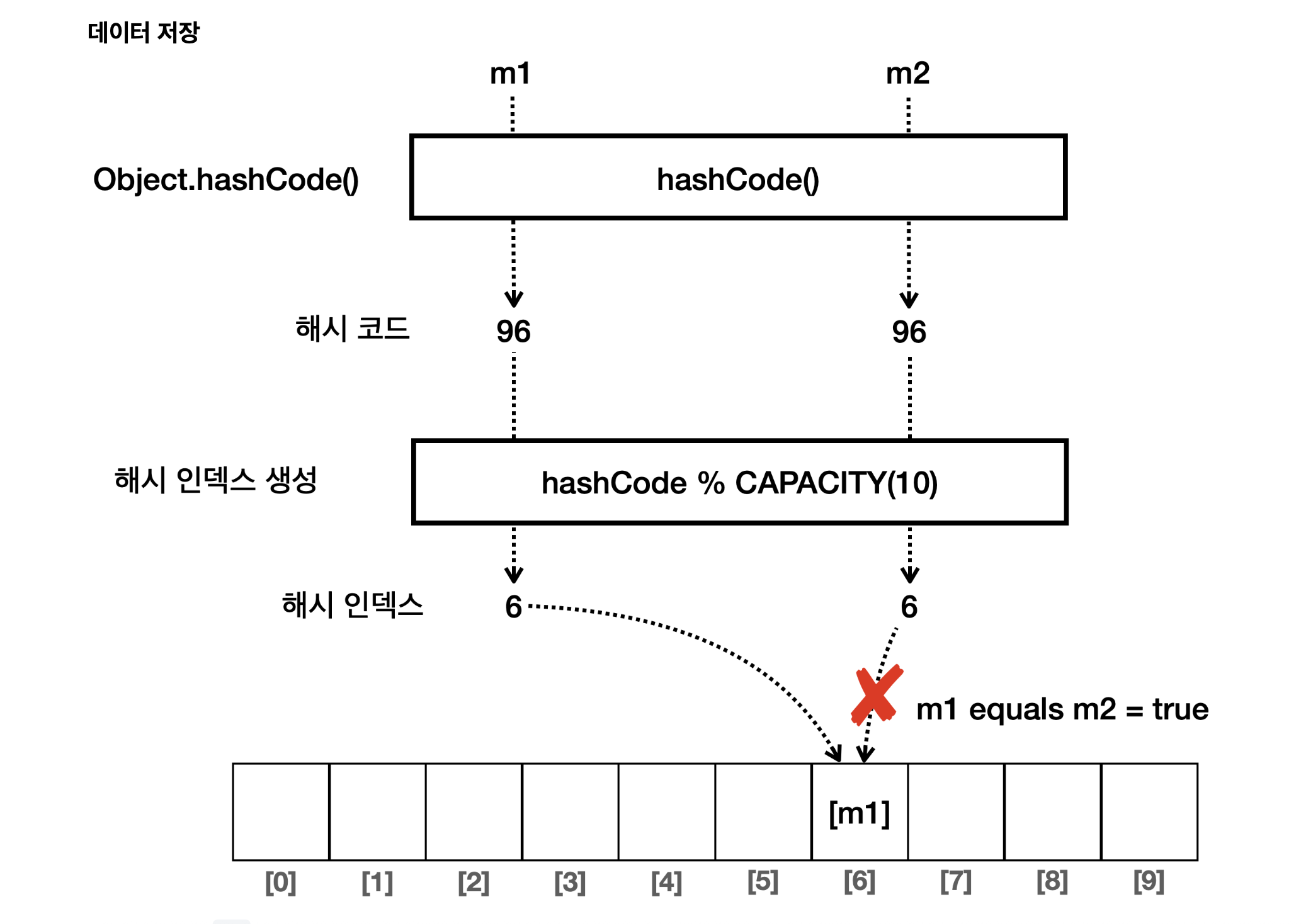
일단 처음에 m1을 저장하고 그 다음으로 m2의 저장을 시도했을 때, m1과 m2는 모두 같은 해시 코드를 사용하므로 일단 6번 인덱스로 찾아간다. 근데 equals() 메서드를 통해 같은 데이터가 있는 것을 알아차리고 m2는 튕겨낸다. 이런 식으로 중복 데이터가 저장되지 않도록 한다.
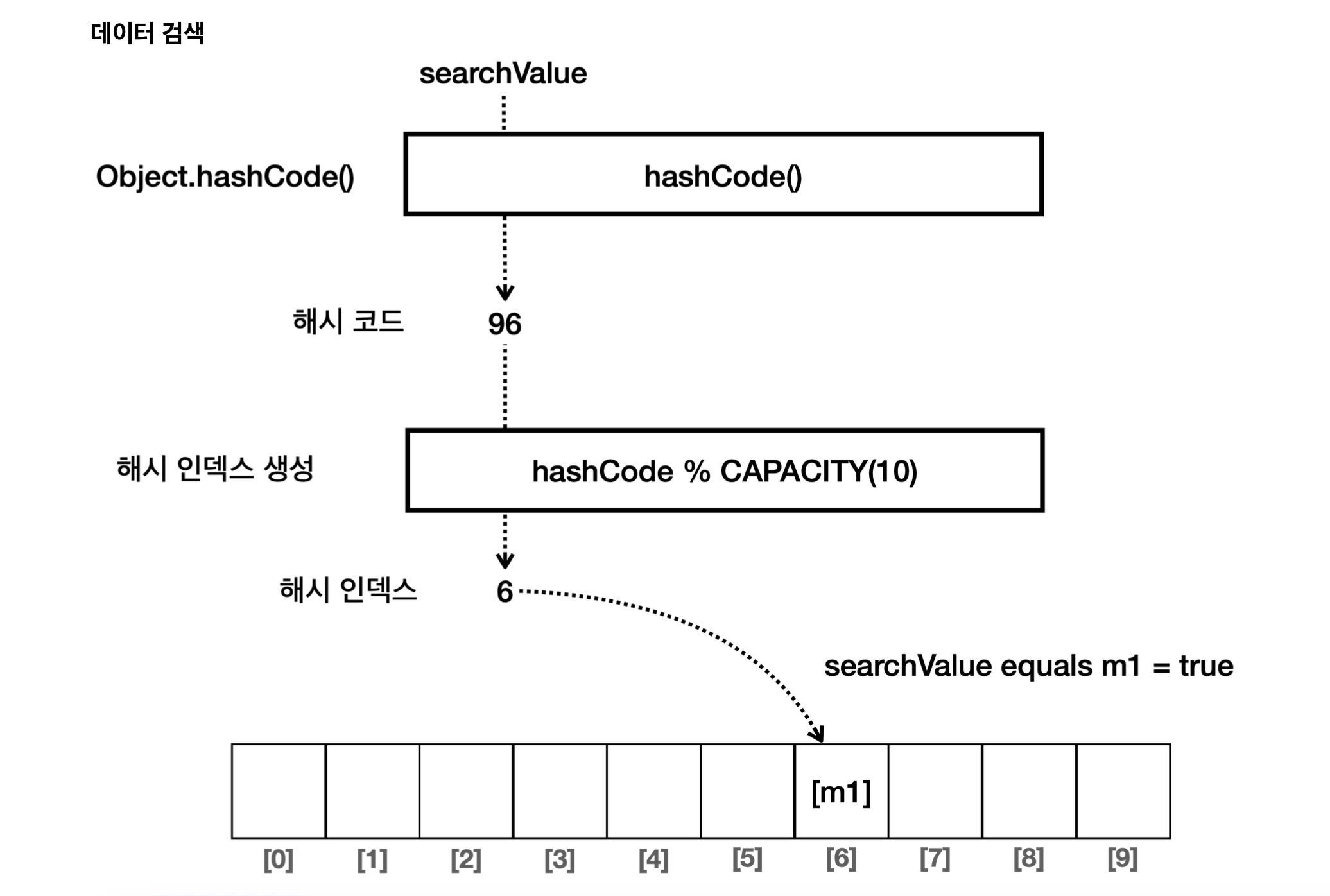
데이터를 검색할 때도 마찬가지다. searchValue의 해시 코드로 6번 인덱스를 찾아가서, 내부의 모든 데이터를 equals() 메서드로 비교한다. m1의 값과 같기 때문에 데이터를 성공적으로 찾을 수 있다.
워낙 중요하기 때문에 다시 한번 정리해보자.
“
hashCode()메서드를 항상 재정의해야 하는 것은 아니지만, 해시 자료 구조를 사용한다면hashCode()와equals()를 반드시 함께 오버라이딩 해야 한다.”
🤔 참고 사항
해시 함수는 최대한 해시 코드가 충돌되지 않도록 설계되어야 한다. 따라서 자바의 해시 함수는 문자의 숫자를 단순히 더하기만 하는 것이 아니라 아래 이미지처럼 내부에서 복잡한 추가 연산을 수행한다. 그로 인해 아주 다양한 범위의 해시 코드가 만들어져서 해시 충돌 가능성이 현저히 낮아진다.
그리고 해시 함수는 같은 입력에 대해 항상 동일한 해시 코드를 반환해야 한다. 좋은 해시 함수는 해시 코드가 한 곳에 뭉치는 것이 아닌, 균일하게 분포하는 것이 좋다. 그래야 해시 자료 구조의 성능을 최적화할 수 있다. 하지만, 자바가 제공하는 해시 함수를 사용해도 같은 해시 코드가 생성되어서 해시 코드가 충돌하는 경우도 가끔 존재한다.
“Aa”.hashCode()의 해시 코드: 2112“BB”.hashCode()의 해시 코드: 2112
위와 같이 해시 인덱스가 같을 수도 있다. 하지만 equals() 메서드를 사용해서 다시 비교하기 때문에 해시 코드가 충돌되더라도 문제가 되지는 않는다. 그리고 매우 낮은 확률로 충돌하기 때문에 성능에 대한 부분도 크게 걱정하지 않아도 된다.
🎭 제네릭과 인터페이스 도입
package collection.set;
public interface MySet<E> {
boolean add(E e);
boolean remove(E e);
boolean contains(E e);
}코드에서 사용되던 핵심 기능(추가, 검색, 삭제)을 따로 인터페이스로 뽑았다. 해당 인터페이스를 구현하면 해시 기반은 물론이고, 다른 자료 구조 기반의 Set도 만들 수 있게 된다. 일단 MyHashSetV2를 리팩토링 해보자.
package collection.set;
import java.util.Arrays;
import java.util.LinkedList;
public class MyHashSetV3<E> implements MySet<E> {
static final int DEFAULT_CAPACITY = 16;
private LinkedList<E>[] buckets; // 모든 데이터 타입을 넣을 수 있도록 함
private int size;
private int capacity = DEFAULT_CAPACITY;
public MyHashSetV3() {
initBuckets();
}
public MyHashSetV3(int capacity) {
this.capacity = capacity;
initBuckets();
}
private void initBuckets() {
buckets = new LinkedList[capacity];
for (int i = 0; i < capacity; i++) {
buckets[i] = new LinkedList<>();
}
}
public boolean add(E value) {
int hashIndex = hashIndex(value);
LinkedList<E> bucket = buckets[hashIndex];
if (bucket.contains(value)) {
return false;
}
bucket.add(value);
size++;
return true;
}
public boolean contains(E searchValue) {
int hashIndex = hashIndex(searchValue);
LinkedList<E> bucket = buckets[hashIndex];
return bucket.contains(searchValue);
}
public boolean remove(E value) {
int hashIndex = hashIndex(value);
LinkedList<E> bucket = buckets[hashIndex];
boolean result = bucket.remove(value);
if (result) {
size--;
return true;
} else {
return false;
}
}
public int hashIndex(E value) {
// Object의 hashCode() 메서드 활용
// 음수가 나올 수도 있으므로 절댓값 처리
return Math.abs(value.hashCode()) % capacity;
}
public int getSize() {
return size;
}
@Override
public String toString() {
return "MyHashSetV3{" +
"buckets=" + Arrays.toString(buckets) +
", size=" + size +
", capacity=" + capacity +
'}';
}
}단지 Object로 다루던 부분들을 제네릭의 타입 매개 변수 E로 변경했을 뿐이다. 이렇게만 해주면 타입 안정성까지 높은 자료 구조가 완성된 것이다.
package collection.set;
public class MyHashSetV3Main {
public static void main(String[] args) {
MySet<String> strSet = new MyHashSetV3<>(10);
strSet.add("A");
strSet.add("B");
strSet.add("C");
System.out.println(strSet);
// 검색
String searchStringValue = "A";
boolean strResult = strSet.contains(searchStringValue);
System.out.println("strSet.contains(" + searchStringValue + ") = " + strResult);
MySet<Integer> intSet = new MyHashSetV3<>(10);
intSet.add(1);
intSet.add(2);
intSet.add(3);
intSet.add(4);
System.out.println(intSet);
Integer searchIntegerValue = 3;
boolean intResult = intSet.contains(searchIntegerValue);
System.out.println("intSet.contains(" + searchIntegerValue + ") = " + intResult);
}
}
/*
MyHashSetV3{buckets=[[], [], [], [], [], [A], [B], [C], [], []], size=3, capacity=10}
strSet.contains(A) = true
MyHashSetV3{buckets=[[], [1], [2], [3], [4], [], [], [], [], []], size=4, capacity=10}
intSet.contains(3) = true
*/