
지금까지 프로세스 주소 공간 전체를 메모리에 탑재하는 것을 가정했다. base와 limit 레지스터를 사용하면 OS는 프로세스를 물리 메모리의 다른 부분으로 쉽게 재배치할 수 있다. 이러한 형태의 주소 공간에 대해,
스택과 힙 사이에 사용되지 않는 큰 공간이 존재한다는 것을 짐작할 수 있다.
사용되지 않는 스택과 힙 사이의 공간은 주소 공간을 물리 메모리에 재배치할 때 물리 메모리를 차지한다. base와 limit 레지스터 방식은 메모리 낭비가 심하고, 주소 공간이 물리 메모리보다 큰 경우 실행이 매우 어렵다는 문제점이 있다.
❓ MMU와 Virtual memory는 뭘까?
Memory Management Unit(MMU) : CPU 패키지 내에 존재하며 메인 메모리 또는 장치 메모리 접근을 위한 물리 주소 변환을 담당한다. CPU가 Load/Store 명령에서 사용하는 Virtual address(VA)들을 최종적인 Physical address(PA)로 주소 변환을 하기 위해서 별도의 주소 변환 테이블을 사용한다.
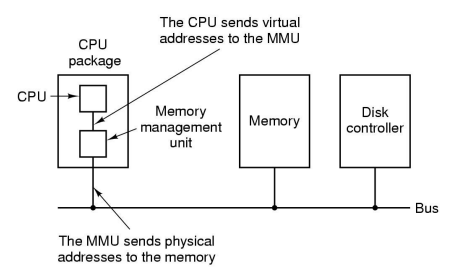
❓ 주소 공간(Address Space)을 왜 관리해야 할까?
Virtual memory는 프로세스가 자유롭게 사용할 수 있는 Virtual address space를 제공하지만 실제 물리 메모리의 용량은 충분하지 않을 수 있기 때문이다.
Address Space는 가상 머신이나 보안을 위한 영역 등 상위 구조를 가질 수 있지만, 결국 linear address로 표현되어야 하고 실제 저장된 물리 메모리의 위치와 매핑되어야 하기 때문이다.
OS 관점에서 다수의 프로세스들이 빈번한 메모리를 할당 및 해제를 수행하는데 이는 메모리 공간 내의 Internal/External Fragmentation 문제를 야기한다. 특히 한정된 물리 메모리를 위해 효율적인 여유 메모리(Free memory) 관리가 필요하기 때문이다.
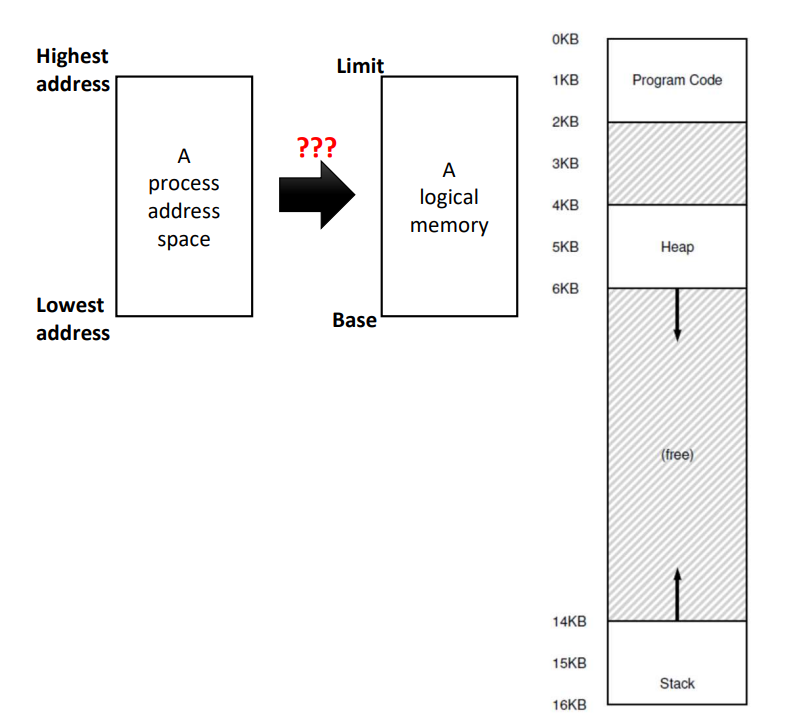
주소 공간을 하나의 메모리 덩어리라고 가정해보자. 프로세스마다 주어진 logical memory로 간주하고 그걸 주소 공간에 할당하려고 한다. Base는 주소 공간의 시작 주소, Limit는 주소 공간의 끝 주소로 설정함으로써 간단히 logical memory 체계로 구성이 가능하지만 생각보다 code 및 data의 크기가 크지 않기 때문에 낭비가 심하다. 나머지 영역에서 큰 부분을 차지하는 Heap과 Stack 영역이 늘 실제 메모리를 차지하고 있어야 한다면 그것 또한 낭비다. 다수의 프로세스가 공존하는 경우, 여유 메모리 공간(Free address space)을 효율적으로 관리할 필요가 있다. 즉, Address space 전체를 하나의 logical memory로 간주하고 관리하는 것은 매우 비효율적이다.
🔥 Segmentation : base/bound의 일반화
위의 문제를 해결하기 위해 바로 세그멘테이션(Segmentation) 이 등장했다. MMU에 하나의 Base와 Limit 값이 존재하는 것이 아니라 세그멘트(segment) 마다 Base와 limit 값이 존재한다는 것이다. 세그멘테이션을 사용하면 OS는 각 세그멘트를 독립적으로 물리 메모리에 배치할 수 있고, 사용되지 않는 가상 주소 공간이 물리 메모리를 차지하는 것을 방지할 수 있다.
정리하자면, Segmentation의 의미는 주소 공간을 다수로 분할하여 관리하고 각 분할 영역에 대해 확장된 속성을 부여하는 것이 가능하다. Segment는 분할된 각각의 메모리 단위를 의미하는 특정 길이를 가지는 연속적인 주소 공간이다. 세그먼트의 수가 많다는 것은, 분할 정도가 높다는 것이다. 이 경우, 유지 비용이 증가한다.
👉 세그멘테이션에서 보호가 필요한 이유
만약 하나의 가상 주소 공간만 주어진다면 프로그램 실행 중에 얼마든지 다른 공간을 침범할 우려가 있다.
트리 노드를 계속 추가한다든지 테이블의 엔트리가 증가한다든지 Heap에서 새로운 메모리를 할당하든지 동적 자료구조의 사용에 따라서 증가한다.
침범한 메모리 영역에 민감한 데이터가 존재한다면 프로그램의 정상적인 실행이 불가능하다.
👉 세그멘테이션을 H/W로 구현하는 방법(보호)
메인 메모리 내에 세그먼트 테이블(Segment Table)을 두어 관리하는 방법이 있다. 이 테이블이 어디서 시작하는지 얼마만큼의 크기를 차지하는지 알기 위해 MMU가 STBR(Segment table base 주소 적재) 레지스터와 STLR(Segment table length를 적재) 레지스터를 직접 사용해서 주소가 아닌 세그먼트 번호로 구분하여 메모리를 참조 한다. 만약 잘못된 세그먼트 번호(테이블에 없는 번호)를 참조한다면 예외가 발생하도록 처리한다.
예시로, 2bits의 세그먼트 번호, 12bits offset인 14bits 세그멘테이션의 가상 주소 4200(0x1068)인 경우를 생각해보자.
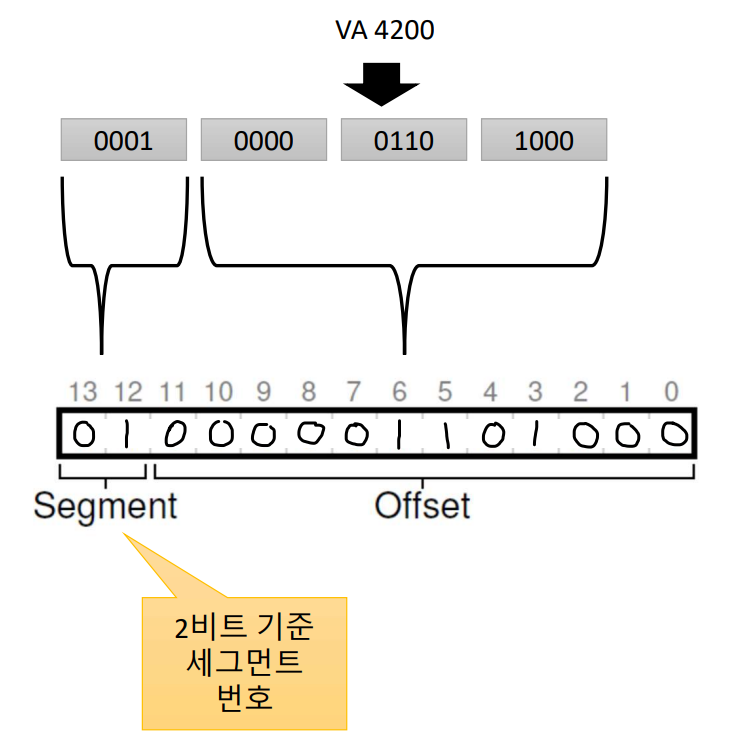
세그먼트 번호는 2bits이므로 0001에서 하위 2bits, 즉 "01"만 기입한다. 따라서 4200의 가상 주소는 세그먼트 번호로 치면 1번에 해당하는 세그먼트에 Base 주소가 있다 는 뜻이다. 1번에 해당하는 테이블에 가보면 Base 주소가 어딘가에 기록이 되어있다. 그걸 읽어와서 나머지 비트에 적재되어 있는 offset 값과 더해서 하드웨어는 최종 물리 주소를 계산한다.
추가적으로, Segment는 기존 logical memory의 확장한 형태로 Base, Limits(=bounds) 및 확장된 필드들이 있는데 그 중 하나가 Direction bit 이다. 이걸 왜 쓰냐? Stack을 예로 들어 보자.
낮은 주소에서 상위 주소로 성장하는 Heap이나 일반적인 메모리 주소와는 달리, Stack은 반대 방향으로 확장된다. 그래서 Direction bit를 이용하여 1(positive)이면 일반적으로 증가하는 방향, 0(negative)이면 감소하는 방향 으로 설정한 것이다.
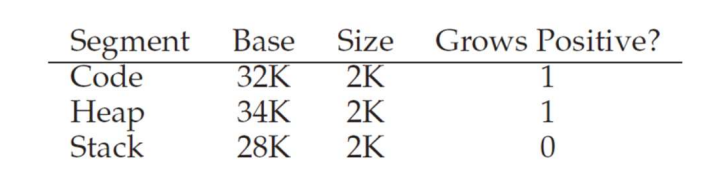
위 표에서 가상 주소 15KB에 접근하려고 한다고 가정해보자. 이 가상 주소를 이진 형태로 바꾸면 11 1100 0000 0000(16진수 0x3C00)이 되는데, 하드웨어는 상위 2비트 11를 사용하여 세그먼트를 지정한다. 이러면 3KB의 offset이 남는데 올바른 음수 offset을 얻기 위해서 3KB에서 세그먼트의 최대 크기를 빼야 한다. 현재 세그먼트의 최대 크기가 4KB이고 따라서 올바른 offset은 3KB에서 4KB를 뺸 -1KB이다. 이 값에 Base(28KB)를 더하면 올바른 물리 주소 27KB를 얻을 수 있다.
👉 Sharing in Segmentation(메모리 공유)
프로그램 메모리의 일부를 공유할 수 있다면 많은 이점이 존재하는데, 여러 프로그램 간의 효율적인 데이터 교환이 가능하고 라이브러리 등에서 필요한 프로그램 코드의 재활용이 가능하다는 점이다. 하지만, 그냥 무턱대고 공유하는 것이 아니라 "Protection bit" 를 추가하여 세그먼트를 읽거나 쓸 수 있는지 혹은 세그먼트의 코드를 실행시킬 수 있는지를 나타낸다. 읽기/쓰기/실행의 권한 조합을 통해 해당 권한이 있는 프로세스는 공유가 가능해지는 것이다. 권한이 없다면, 예를 들어 사용자 프로세스가 읽기 전용 페이지에 쓰기를 시도하는 경우 하드웨어는 "예외(Exception)" 를 발생시켜서 OS가 위반 프로세스를 처리할 수 있게 해준다.
🔥 Pure Segmentation의 결과 (외부 단편화 -> 압축)
가상 메모리 내에서는 얼마든지 세그먼트를 생성 가능하고 생성한 세그먼트들은 결국 물리 메모리에 최종 배치되어야 프로세스가 사용할 수 있다. 그러나 세그먼트들의 크기는 서로 다 다를 수 있다. 아래 그림을 보자.
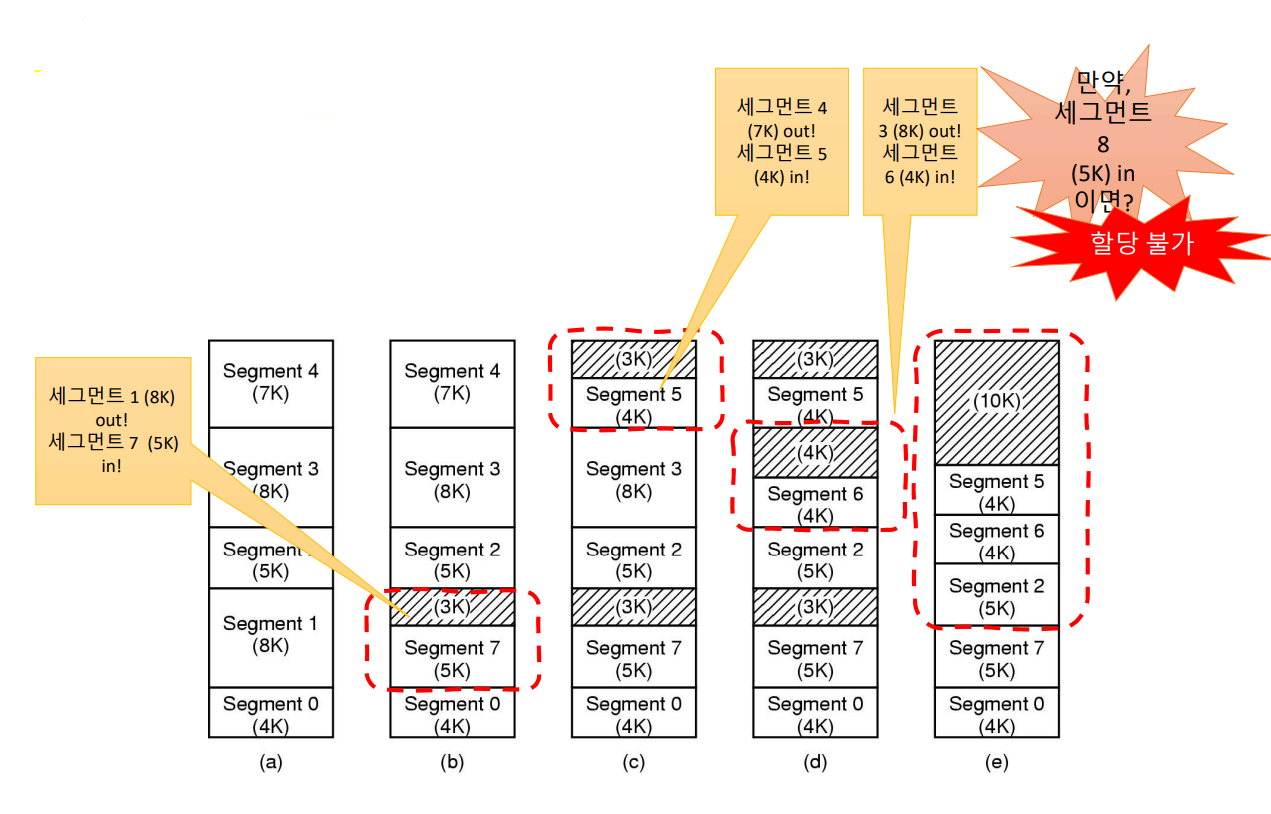
나에게 주어진 메모리에 비어 있는 공간을 찾아 세그먼트들이 들어갈 위치를 찾아 들어간다. 먼저 (b)에서 다 쓴 애들, 새로 들어온 애들이 혼재하면 빈 공간(3K)이 생기기 마련이다. (c)와 (d)에서도 마찬가지이다. 하지만 (d)에서 크기가 5K인 세그먼트 8이 들어가려 하면 보다시피 자리가 없기 때문에 할당이 불가능하다. 이 문제를 "External Fragmentation(외부 단편화)" 라고 부른다.
이 문제를 해결할 수 있는 방법 중 하나는 기존의 세그먼트를 정리하여 물리 메모리를 압축(Compact)하는 것, 다른 말로 여유 메모리를 확보하기 위해 기존의 세그먼트들을 재배열하는 것 이다.
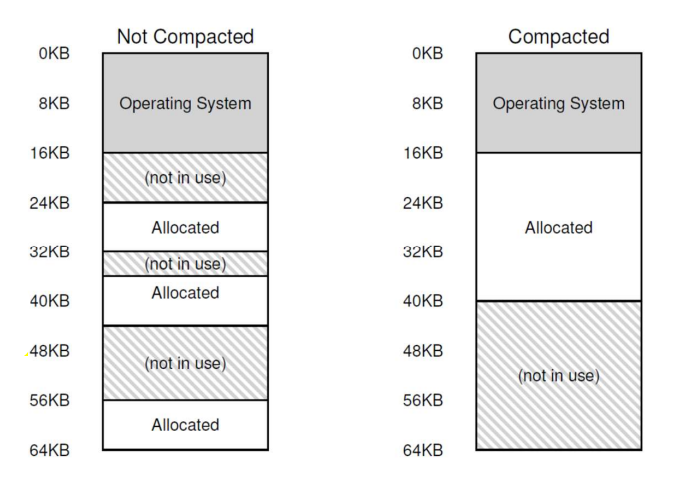
수행 중인 프로세스들을 멈추고, 필요한 크기의 연속된 메모리 영역에 데이터를 복사하고 새로운 물리 메모리 영역을 가리키도록 세그먼트 레지스터를 변경하여 자신이 작업할 큰 빈 공간을 확보할 수 있다. 이렇게 함으로써 OS는 새로운 할당 요청을 충족시킬 수 있다.
하지만, 이는 메모리 복사 연산이 필요하고 일반적으로 상당량의 프로세서 시간을 사용(CPU를 많이 소모함)하기 때문에 비용이 많이 든다. 이를 위한 간단한 방법은 "여유 메모리 관리 알고리즘" (할당 가능한 메모리 영역들을 리스트 형태로 유지)을 사용하는 것 이다.
세그먼트 적재 시 Free list 내 영역 선택 정책
First-fit (최초 적합) : 비어 있는 메모리 영역 가운데, 현재 세그먼트를 적재 가능한 경우 가장 처음의 공간을 선택한다. 이는 연산이 빠르고 구현이 쉽다.
Best-fit (최적 적합) : 현재 세그먼트의 크기와 가장 차이가 적은 비어 있는 공간을 선택한다. 만약 크기에 의해 정렬되지 않았다면 전체 여유 공간 리스트를 검색해야 한다.
Worst-fit (최악 적합) : 현재 세그먼트의 크가와 가장 차이가 큰 비어 있는 공간을 선택한다. 마찬가지로 정렬이 필요하며, 안된 경우에는 전체 영역을 모두 검색해야 한다.
