
🔭 Iterable, Iterator 직접 구현해보기
자료 구조에 들어 있는 데이터를 차례대로 접근해서 처리하는 것을 순회(Traversal)라고 한다.
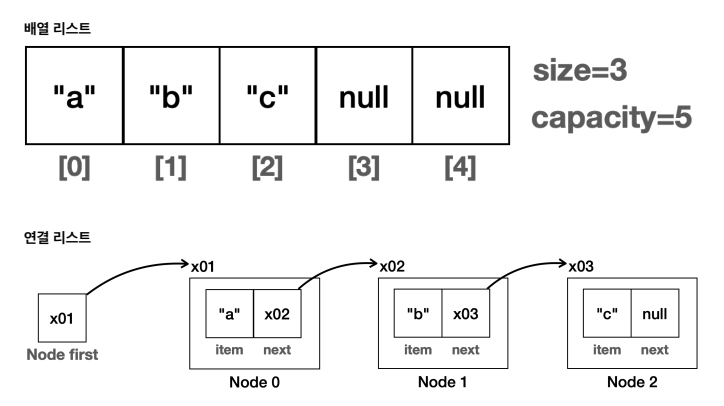
ArrayList의 경우, 인덱스를 배열을 차지하고 있는 데이터 개수만큼 차례로 증가하면서 순회해야 하고, LinkedList의 경우, Node의 next 필드가 null일 때까지 순회해야 한다. 이처럼 각각의 자료 구조는 순회하는 방법이 모두 다르다. 따라서 각 자료 구조가 어떻게 순회하는지 알아야 하고, 그러기 위해서는 해당 자료 구조의 내부 구조를 당연히 숙지하고 있어야 한다.
근데… 각 자료 구조가 어떤 방식으로 순회하는지 알려고 하는 것은 엄청난 공부량이 필요할 것이다. 모든 자료 구조에 대해 순회할 수 있는 일관성 있는 방식이 있다면 개발자는 너무 행복할 것 같다… 아주 다행스럽게도 자바 형님이 Iterable과 Iterator라는 인터페이스를 제공하시고 있다.
<Iterable 인터페이스 내부 구조>
public interface Iterable<T> {
Iterator<T> iterator(); // Iterator 반환
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
<Iterator 인터페이스 내부 구조>
public interface Iterator<E> {
boolean hasNext(); // 다음 요소가 있는지 확인
E next(); // 다음 요소를 반환
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
생각해보면, 자료 구조 안의 데이터를 순회하는 방법은 꽤 단순하다. 그냥 다음 요소가 있는지 물어보고, 있으면 그 요소를 꺼내는 과정을 반복하면 끝이다. 직접 Iterable과 Iterator을 구현한 구현체를 만들어보자.
package collection.iterable;
import java.util.Iterator;
// 배열을 반복할 수 있는 반복자를 만든다.
public class MyArrayIterator implements Iterator<Integer> {
private int currentIndex = -1; // 현재 인덱스
private int[] targetArr; // 순회할 대상 배열
public MyArrayIterator(int[] targetArr) {
this.targetArr = targetArr;
}
// 다음 항목이 있는지 검사, 배열의 끝에 다다르면 false를 반환
@Override
public boolean hasNext() {
return currentIndex < targetArr.length - 1;
}
// 현재 인덱스를 하나 증가하고 항목을 반환
@Override
public Integer next() {
return targetArr[++currentIndex];
}
}먼저 Iterator의 구현체를 살펴보면, 생성자를 통해 반복자가 사용할 배열, 즉 순회할 배열을 참조한다. 이제 next() 메서드를 호출할 때마다 currentIndex가 하나씩 증가하는 것이다. 그리고 hasNext() 메서드를 통해 다음 항목이 있는지 체크한다. 만약 다음 항목이 없다면 배열의 끝에 온 것이기 때문에 false를 반환하도록 한다.
추가로 Iterator는 단독으로 사용할 수 없다. 어떤 자료를 순회할 것인지 정해야 한다. 그러기 위해 Iterator를 통해 순회의 대상이 되는 자료 구조를 만들어보자.
package collection.iterable;
import java.util.Iterator;
public class MyArray implements Iterable<Integer> {
private int[] numbers;
public MyArray(int[] numbers) {
this.numbers = numbers;
}
@Override
public Iterator<Integer> iterator() {
return new MyArrayIterator(numbers); // 사용할 반복자 반환
}
}보다시피 int형 배열을 가지는 아주 단순한 자료 구조다. 여기서 Iterable 인터페이스를 구현했는데, 배열에 사용할 반복자(Iterator)를 반환하도록 했다. 이때 MyArrayIterator는 생성자를 통해 MyArray의 내부 배열인 numbers를 참조하도록 한다. 이제 코드를 실행해보면…
package collection.iterable;
import java.util.Iterator;
public class MyArrayMain {
public static void main(String[] args) {
MyArray myArr = new MyArray(new int[]{1, 2, 3, 4});
Iterator<Integer> iterator = myArr.iterator();
System.out.println("iterator 사용...");
while (iterator.hasNext()) {
Integer value = iterator.next();
System.out.println("value = " + value);
}
}
}
/*
iterator 사용...
value = 1
value = 2
value = 3
value = 4
*/클래스 구조도를 통해 흐름이 어떻게 되는지 자세히 살펴보자.
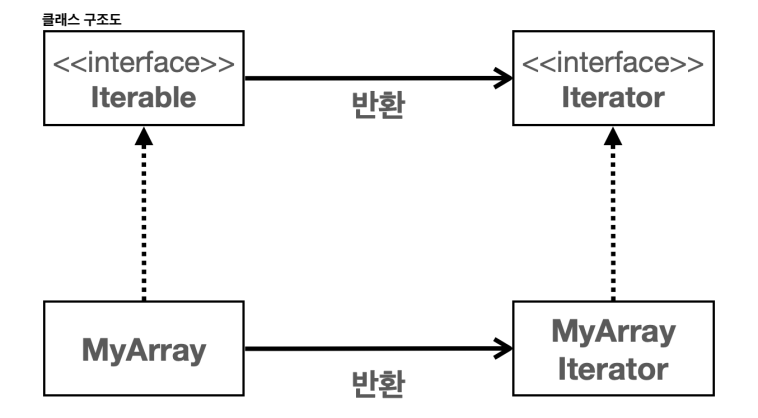
MyArray는 Iterable 인터페이스를 구현했다. 이 말은 MyArray는 반복할 수 있다는 뜻이 된다. Iterable 인터페이스를 구현하면, iterator() 메서드를 구현해야 한다. 이 메서드는 Iterator 인터페이스를 구현한 반복자(MyArrayIterator)를 반환한다.
이제 실행 중의 과정을 살펴보자면…
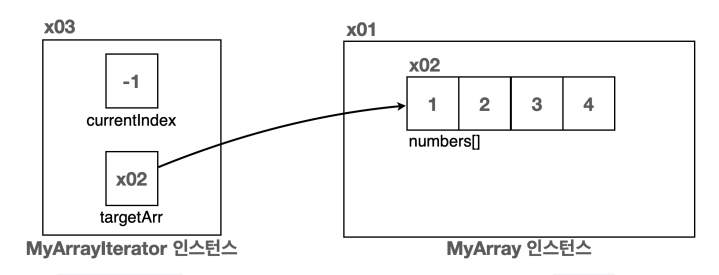
알다시피 MyArrayIterator 인스턴스를 생성할 때, 생성자에서 순회할 대상(MyArray)을 지정했었다. 그럼 MyArrayIterator 인스턴스는 내부에서 MyArray의 배열(numbers)을 참조하게 된다. 이제 데이터를 next() 메서드를 호출해서 현재 인덱스를 하나씩 증가시키면서 마지막 인덱스까지 순회하기만 하면 된다.
💉 향상된 for문
MyArrayMain.main()에 코드를 살짝 추가해서 결과를 살펴보자.
package collection.iterable;
import java.util.Iterator;
public class MyArrayMain {
public static void main(String[] args) {
MyArray myArr = new MyArray(new int[]{1, 2, 3, 4});
Iterator<Integer> iterator = myArr.iterator();
System.out.println("iterator 사용...");
while (iterator.hasNext()) {
Integer value = iterator.next();
System.out.println("value = " + value);
}
// 코드 추가
System.out.println("for-each 사용");
for (int value : myArr) {
System.out.println("value = " + value);
}
}
}
/*
iterator 사용...
value = 1
value = 2
value = 3
value = 4
for-each 사용
value = 1
value = 2
value = 3
value = 4
*/흔히 for-each 문이라고 부르는 향상된 for 문은 자료 구조를 순회하는 것이 목적이다. 근데 저 for-each 문... 원래 자바가 제공하는 기능 아닌가? 향상된 for 문을 사용하려면 배열이거나, java.lang.iterable이어야 한다. 그렇지 않으면 아래처럼 컴파일 오류가 발생한다.
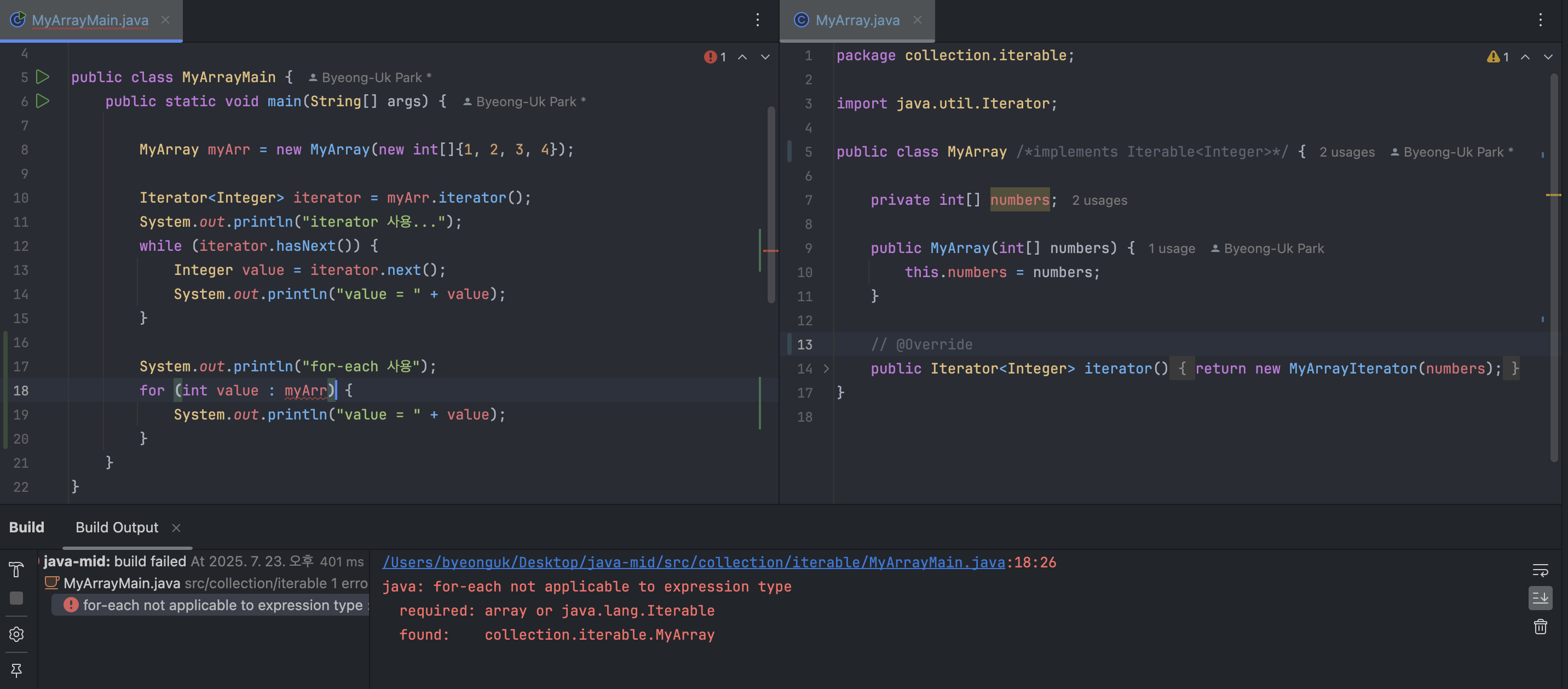
"자바는
Iterable인터페이스를 구현한 객체에 대해서만향상된 for 문을 사용할 수 있게 해주는 것이다."
System.out.println("for-each 사용");
for (int value : myArr) {
System.out.println("value = " + value);
}위 코드가 컴파일 시점에 아래와 같이 코드가 변경되는 것이다.
while (iterator.hasNext()) {
Integer value = iterator.next();
System.out.println("value = " + value);
}
두 개의 코드는 완전히 같은 코드다. 정리하자면, 특정 자료 구조가 Iterable, Iterator를 구현한다면, 해당 자료 구조를 사용하는 개발자는 단순히 hasNext(), next() 메서드를 통해, 혹은 향상된 for 문을 사용해서 손쉽게 순회할 수 있다. 이것이 바로 인터페이스가 주는 큰 장점이다.
🥞 자바가 제공하는 Iterable, Iterator
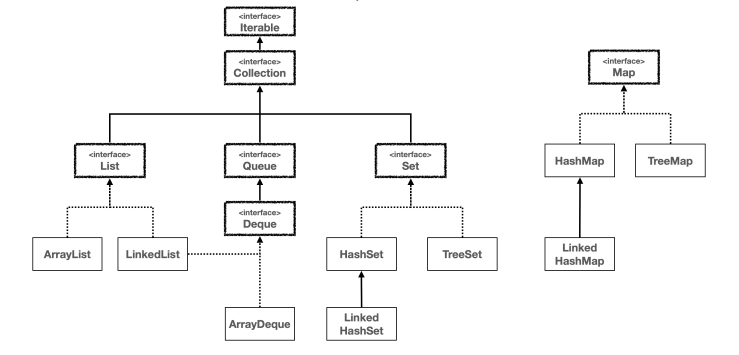
자바 컬렉션 프레임워크는 보다시피 아주 다양한 자료 구조를 제공한다. 그에 따라 편리하고 일관된 방식으로 자료 구조를 순회할 수 있도록 Iterable 인터페이스가 제공되고, 이미 각각의 구현체에 맞는 Iterator도 모두 구현되어 있다.
보다시피 Collection 인터페이스 상위에 Iterable 인터페이스가 존재한다는 말은, 모든 컬렉션을 Iterable과 Iterator를 사용해서 순회할 수 있다는 뜻이다. 하지만, Map의 경우, 키(Key)와 값(Value)을 가지고 있기 때문에 바로 순회할 수는 없지만, 키(Key)나 값(Value) 중에 기준을 선택해서 순회할 수 있다.
알다시피 keySet(), values() 메서드를 각각 호출하면 Set과 Collection을 반환하기 때문에 가능한 것이다.
바로 코드로 하나씩 확인해보자.
package collection.iterable;
import java.util.*;
public class JavaIterableMain {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
printAll(list.iterator());
printAll(set.iterator());
forEach(list);
forEach(set);
}
private static void printAll(Iterator<Integer> iterator) {
System.out.println("iterator: " + iterator.getClass());
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
private static void forEach(Iterable<Integer> iterable) {
System.out.println("iterable = " + iterable.getClass());
for (Integer integer : iterable) {
System.out.println(integer);
}
}
}
/*
iterator: class java.util.ArrayList$Itr
1
2
3
iterator: class java.util.HashMap$KeyIterator
1
2
3
iterable = class java.util.ArrayList
1
2
3
iterable = class java.util.HashSet
1
2
3
*/printAll(Iterator<Integer> iterator)에서 List든, Set이든 그냥 Iterator를 구현한 자료 구조라면 모두 순회 가능한 것이다.
forEach(Iterable<Integer> iterable)도 그냥 반복자(iterator)를 반환하고 hasNext()와 next()를 쓸 수 있다는 것이 전부다. List 전용 forEach() 라든지 Set 전용 forEach()를 구현한다? 그럴 필요가 없다는 것이다… 그냥 List, Set의 부모인 Iterable로 받도록 하면 된다.
🤔 참고 사항
Iterator(반복자) 패턴은 컬렉션의 요소들을 순회할 때 사용되는 디자인 패턴이다. 컬렉션의 내부 표현 방식을 노출시키지 않으면서 그 안의 각 요소에 순차적으로 접근할 수 있게 해준다. 그리고 컬렉션의 구현과는 독립적으로 요소들을 탐색할 수 있는 방법을 제공하며, 이로 인해 코드의 복잡성을 줄이고 재사용성을 높일 수 있다.
🎰 Comparable, Comparator
이제 데이터를 정렬하는 방법에 대해 알아보자.
package collection.compare;
import java.util.Arrays;
public class SortMain1 {
public static void main(String[] args) {
Integer[] arr = {3, 2, 1};
System.out.println(Arrays.toString(arr));
System.out.println("기본 정렬 후");
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
}
}
/*
[3, 2, 1]
기본 정렬 후
[1, 2, 3]
*/알다시피, Arrays.sort() 메서드를 통해 손쉽게 데이터를 정렬할 수 있다. 정렬 알고리즘의 작동 방식은 대략 아래와 같다.
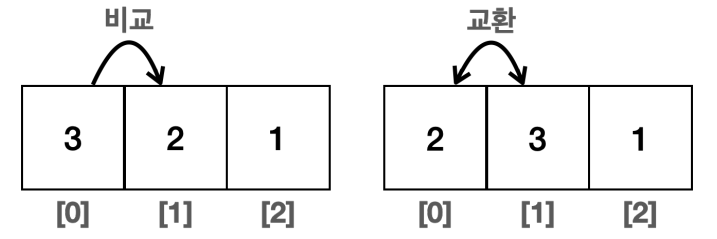
먼저 가장 왼쪽에 있는 데이터와 그 다음에 있는 데이터를 비교해서 뒤에 있는 데이터의 값이 더 크다면 둘을 교환한다. 이런 식으로 처음부터 끝까지 비교하면 마지막 항목은 가장 큰 값이 된다. 그리고 처음으로 돌아가 다시 비교를 시작하는 것이다.
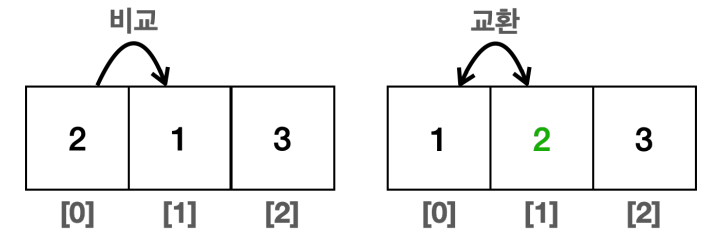
이러면 최종적으로 1, 2, 3으로 정렬되는 것이다. 이는 아주 단순한 예시일 뿐이고, 실제로는 다양한 정렬 알고리즘이 존재한다. 자바는 초기에는 QuickSort를 사용하다가 지금은 기본형 배열의 경우, Dual-Pivot QuickSort를 사용하고, 객체 배열의 경우 TimeSort를 사용한다. 이 알고리즘들은 평균 O(log n)의 성능을 제공한다.
🎏 비교자 - Comparator
근데 만약 3, 2, 1로 뒤집어서 정렬하고 싶으면 어떻게 해야 할까? 이처럼 정렬의 기준을 내가 정하고 싶을 때 비교자(Comparator)를 사용하면 된다. 어떤 두 값을 비교할 때 기준을 제공할 수 있는 방법이다.
🔍 Comparator 인터페이스 내부 구조
public interface Comparator<T> {
int compare(T o1, T o2); // 이걸 구현해서 비교하면 된다.
boolean equals(Object obj);
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
}
default <U> Comparator<T> thenComparing(
Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator)
{
return thenComparing(comparing(keyExtractor, keyComparator));
}
default <U extends Comparable<? super U>> Comparator<T> thenComparing(
Function<? super T, ? extends U> keyExtractor)
{
return thenComparing(comparing(keyExtractor));
}
default Comparator<T> thenComparingInt(ToIntFunction<? super T> keyExtractor) {
return thenComparing(comparingInt(keyExtractor));
}
default Comparator<T> thenComparingLong(ToLongFunction<? super T> keyExtractor) {
return thenComparing(comparingLong(keyExtractor));
}
default Comparator<T> thenComparingDouble(ToDoubleFunction<? super T> keyExtractor) {
return thenComparing(comparingDouble(keyExtractor));
}
public static <T extends Comparable<? super T>> Comparator<T> reverseOrder() {
return Collections.reverseOrder();
}
@SuppressWarnings("unchecked")
public static <T extends Comparable<? super T>> Comparator<T> naturalOrder() {
return (Comparator<T>) Comparators.NaturalOrderComparator.INSTANCE;
}
public static <T> Comparator<T> nullsFirst(Comparator<? super T> comparator) {
return new Comparators.NullComparator<>(true, comparator);
}
public static <T> Comparator<T> nullsLast(Comparator<? super T> comparator) {
return new Comparators.NullComparator<>(false, comparator);
}
public static <T, U> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator)
{
Objects.requireNonNull(keyExtractor);
Objects.requireNonNull(keyComparator);
return (Comparator<T> & Serializable)
(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),
keyExtractor.apply(c2));
}
public static <T, U extends Comparable<? super U>> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor)
{
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));
}
public static <T> Comparator<T> comparingInt(ToIntFunction<? super T> keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> Integer.compare(keyExtractor.applyAsInt(c1), keyExtractor.applyAsInt(c2));
}
public static <T> Comparator<T> comparingLong(ToLongFunction<? super T> keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> Long.compare(keyExtractor.applyAsLong(c1), keyExtractor.applyAsLong(c2));
}
public static<T> Comparator<T> comparingDouble(ToDoubleFunction<? super T> keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> Double.compare(keyExtractor.applyAsDouble(c1), keyExtractor.applyAsDouble(c2));
}
}
아주 복잡하지만, 그냥 compare 메서드를 오버라이딩하고 두 인수를 비교해서 결과 값을 반환하면 된다.
package collection.compare;
import java.util.Arrays;
import java.util.Comparator;
public class SortMain2 {
public static void main(String[] args) {
Integer[] arr = {3, 2, 1};
System.out.println(Arrays.toString(arr));
System.out.println("Comparator 비교");
Arrays.sort(arr, new AscComparator());
System.out.println("AscComparator: " + Arrays.toString(arr));
Arrays.sort(arr, new DescComparator());
System.out.println("DescComparator: " + Arrays.toString(arr));
Arrays.sort(arr, new AscComparator().reversed()); // DescComparator와 같음
System.out.println("AscComparator.reversed: " + Arrays.toString(arr));
}
// 오름차순 정렬
static class AscComparator implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println("o1 = " + o1 + ", o2 = " + o2);
return (o1 < o2) ? -1 : ((o1 == o2) ? 0 : 1);
}
}
// 내림차순 정렬
static class DescComparator implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println("o1 = " + o1 + ", o2 = " + o2);
return ((o1 < o2) ? -1 : ((o1 == o2) ? 0 : 1)) * -1;
}
}
}
/*
[3, 2, 1]
Comparator 비교
o1 = 2, o2 = 3
o1 = 1, o2 = 2
AscComparator: [1, 2, 3]
o1 = 2, o2 = 1
o1 = 3, o2 = 2
DescComparator: [3, 2, 1]
AscComparator.reversed: [3, 2, 1]
*/이처럼 비교자를 사용하면 정렬의 기준을 자유롭게 변경할 수 있다.
만약 개발자가 직접 정의한 클래스로 객체를 만든다면, 그 객체는 어떻게 정렬할 수 있을까? 이때는 Comparable 인터페이스를 구현하면 된다. 이 인터페이스는 객체에 비교 기능을 추가해준다.
🔍 Comparable 인터페이스 내부 구조
public interface Comparable<T> {
public int compareTo(T o);
}자기 자신과 인수로 넘어온 객체를 비교해서 결과 값을 반환하면 된다. 바로 Comparable을 구현한 클래스를 만들어보자.
package collection.compare;
// 1. Comparable 구현하고...
public class MyUser implements Comparable<MyUser> {
private String id;
private int age;
public MyUser(String id, int age) {
this.id = id;
this.age = age;
}
public String getId() {
return id;
}
public int getAge() {
return age;
}
// 2. 정렬 기준을 나이순으로 설정!
@Override
public int compareTo(MyUser o) {
return this.age < o.age ? -1 : (this.age == o.age ? 0 : 1);
}
@Override
public String toString() {
return "MyUser{" +
"id='" + id + '\'' +
", age=" + age +
'}';
}
}compareTo() 메서드를 보면 나이를 기준으로 오름차순 정렬하도록 오버라이딩 했다. 이처럼 Comparable을 통해 구현한 순서를 자연 순서(Natural Ordering)이라고 한다. 실행 결과를 확인해보자.
package collection.compare;
import java.util.Arrays;
public class SortMain3 {
public static void main(String[] args) {
MyUser myUser1 = new MyUser("a", 30);
MyUser myUser2 = new MyUser("b", 20);
MyUser myUser3 = new MyUser("c", 10);
MyUser[] arr = {myUser1, myUser2, myUser3};
System.out.println("기본 데이터");
System.out.println(Arrays.toString(arr));
System.out.println("Comparable 기본 정렬");
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
}
}
/*
기본 데이터
[MyUser{id='a', age=30}, MyUser{id='b', age=20}, MyUser{id='c', age=10}]
Comparable 기본 정렬
[MyUser{id='c', age=10}, MyUser{id='b', age=20}, MyUser{id='a', age=30}]
*/Arrays.sort(arr)를 보면, 기본 정렬을 시도하고 있다. 이때는 객체가 스스로 가지고 있는 Comparable 인터페이스를 사용해서 비교한다. 아까 MyUser에서 나이를 기준으로 오름차순 정렬하는 것으로 구현했으므로 그에 맞게 결과가 나오는 걸 확인할 수 있다.
🤔 다른 기준으로 정렬하고 싶다면?
만약 Comparable의 기본 정렬이 아닌, 아이디를 기준으로 정렬하고 싶다면 어떻게 해야 할까? 아래와 같이 코드를 작성해보자.
package collection.compare;
import java.util.Comparator;
public class IdComparator implements Comparator<MyUser> {
@Override
public int compare(MyUser o1, MyUser o2) {
return o1.getId().compareTo(o2.getId());
}
}
그리고 기존 실행 코드에서 일부를 추가해서 정렬 결과를 확인해보면…
package collection.compare;
import java.util.Arrays;
public class SortMain3 {
public static void main(String[] args) {
MyUser myUser1 = new MyUser("a", 30);
MyUser myUser2 = new MyUser("b", 20);
MyUser myUser3 = new MyUser("c", 10);
MyUser[] arr = {myUser1, myUser2, myUser3};
System.out.println("기본 데이터");
System.out.println(Arrays.toString(arr));
System.out.println("Comparable 기본 정렬");
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
// 아이디를 기준으로 추가 정렬
System.out.println("IdComparator 정렬");
Arrays.sort(arr, new IdComparator()); // 비교자를 생성해서 인수로 넘겨준다.
System.out.println(Arrays.toString(arr));
// 거꾸로 정렬
System.out.println("IdComparator().reversed() 정렬");
Arrays.sort(arr, new IdComparator().reversed());
System.out.println(Arrays.toString(arr));
}
}
/*
기본 데이터
[MyUser{id='a', age=30}, MyUser{id='b', age=20}, MyUser{id='c', age=10}]
Comparable 기본 정렬
[MyUser{id='c', age=10}, MyUser{id='b', age=20}, MyUser{id='a', age=30}]
IdComparator 정렬
[MyUser{id='a', age=30}, MyUser{id='b', age=20}, MyUser{id='c', age=10}]
IdComparator().reversed() 정렬
[MyUser{id='c', age=10}, MyUser{id='b', age=20}, MyUser{id='a', age=30}]
*/이처럼 기본 정렬이 아닌, 내가 지정한 정렬 방식으로 정렬하고 싶다면 Arrays.sort()의 인수로 비교자(Comparator)를 만들어서 넘겨주면 된다. 이런 식으로 비교자를 만들어서 따로 전달해주면 객체가 기본으로 가지고 있는 Comparable은 무시되고, 전달한 비교자를 통해 정렬한다.
정리해보자… 객체의 기본 정렬 방법은 객체에 Comparable을 구현해서 정의한다고 했다. 근데 다른 기준으로 정렬하고 싶다면 Comparator를 별도로 구현하고 생성해서 메서드의 인수로 넘겨주면 된다. 이 경우 항상 전달한 Comparator가 우선권을 가진다.
💥 주의 사항
만약 Comparable도 구현하지 않고, Comparator도 제공하지 않으면 런타임 오류가 발생한다.
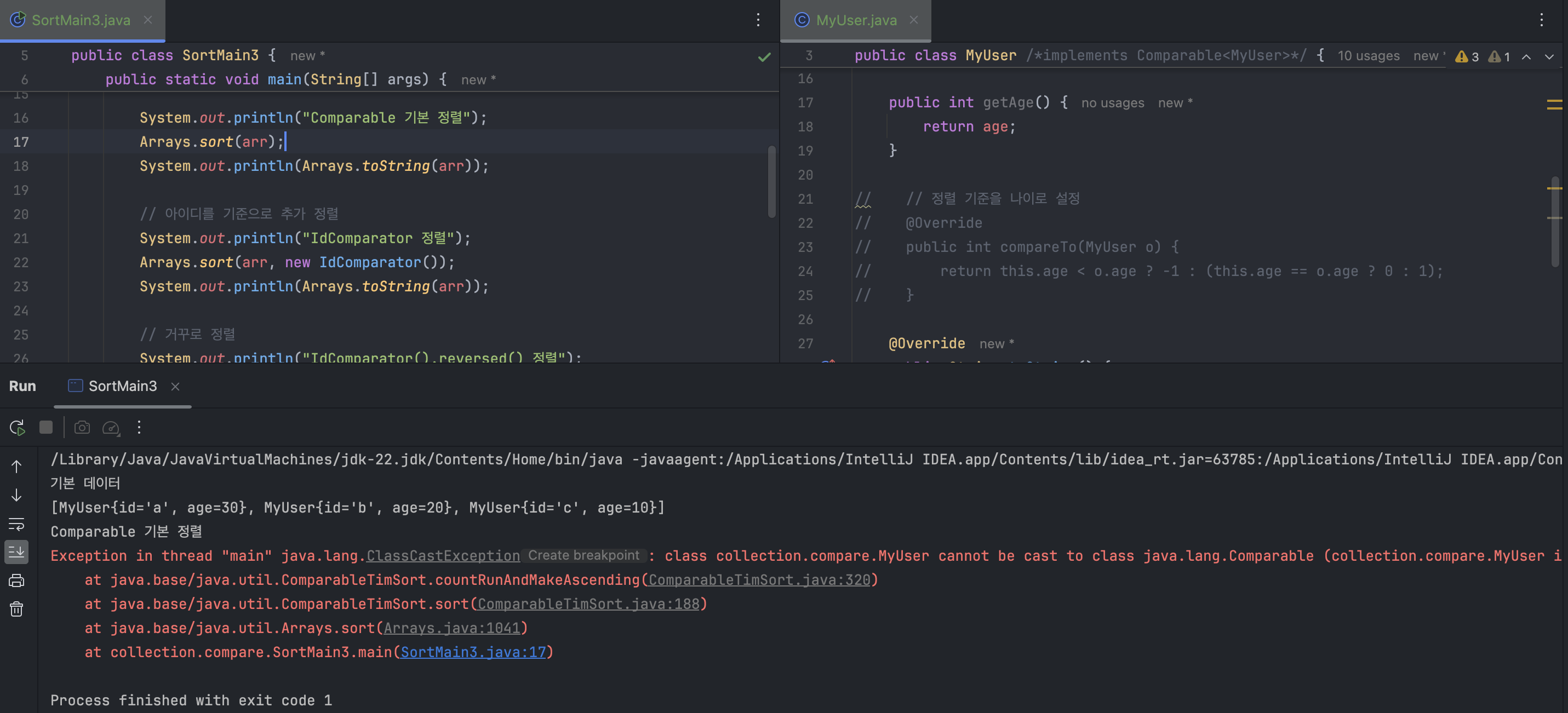
Comparator가 없으니 기본 정렬을 사용해야 하는데… 뭐지? Comparable도 구현 안 해놨네? 바~로 MyUser는 java.lang.Comparable로 캐스팅 할 수 없다면서 런타임 오류가 터진다.
📝 최종 정리(Comparable / Comparator)
-
Comparable<T>인터페이스:int compareTo(T o)메서드를 오버라이딩 해야 하고, 부호로 크기를 결정한다. -
Comparator<T>인터페이스:int compare(T o1, T o2)메서드를 오버라이딩 해야 하고,Comparable인터페이스를 구현하지 않은 객체나Comparable에서 정한 기준 이외의 기준으로 정렬할 때 사용하면 된다.
🧮 다른 자료 구조에서의 정렬
🔧 List에서의 정렬
정렬은 순서가 존재하는 List와 같은 자료 구조에서도 사용될 수 있다.
package collection.compare;
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
public class SortMain4 {
public static void main(String[] args) {
MyUser myUser1 = new MyUser("a", 30);
MyUser myUser2 = new MyUser("b", 20);
MyUser myUser3 = new MyUser("c", 10);
List<MyUser> list = new LinkedList<>();
list.add(myUser1);
list.add(myUser2);
list.add(myUser3);
System.out.println("기본 데이터");
System.out.println(list);
System.out.println("Comparable 기본 정렬");
list.sort(null); // 현재 정렬 기준이 없음, 자연 정렬 적용 (권장 방식)
// Collections.sort(list); // 이런 식으로 해도 가능
System.out.println(list);
System.out.println("IdComparator 정렬");
list.sort(new IdComparator()); // 정렬 기준이 아이디 (권장 방식)
// Collections.sort(list, new IdComparator()); // 이런 식으로 해도 가능
System.out.println(list);
}
}
/*
기본 데이터
[MyUser{id='a', age=30}, MyUser{id='b', age=20}, MyUser{id='c', age=10}]
Comparable 기본 정렬
[MyUser{id='c', age=10}, MyUser{id='b', age=20}, MyUser{id='a', age=30}]
IdComparator 정렬
[MyUser{id='a', age=30}, MyUser{id='b', age=20}, MyUser{id='c', age=10}]
*/List는 컬렉션이므로 Collections.sort(list) 메서드로 기본 정렬할 수 있지만, 이 방식보다는 객체 스스로 정렬 메서드를 가지고 있는 list.sort()를 사용하는 것이 권장된다. 객체가 이미 자신의 데이터를 가지고 있기 때문에 그걸 바탕으로 정렬하는 것이 좀 더 객체 지향적이라고 할 수 있다.
🔨 Set에서의 정렬
이번엔 Tree 구조에서의 정렬을 살펴보자. TreeSet과 같은 이진 탐색 트리 구조는 데이터를 보관할 때, 데이터를 정렬하면서 보관한다. 따라서 정렬 기준을 제공하는 것이 필수적이다.
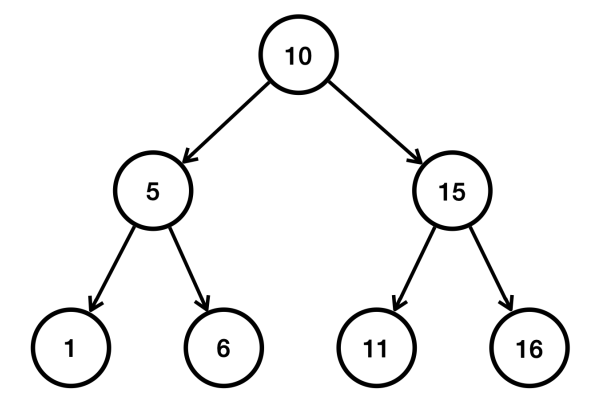
위의 트리 구조만 보더라도 데이터를 저장할 때 왼쪽으로 가서 저장할지, 오른쪽으로 가서 저장할지 비교하는 작업이 필요하다. 이처럼 TreeSet이나 TreeMap 같은 자료 구조는 데이터를 추가할 때부터 비교하는 과정이 포함되므로 반드시 Comparable 또는 Comparator 구현이 필수적인 것이다. 아래 코드를 보자.
package collection.compare;
import java.util.TreeSet;
public class SortMain5 {
public static void main(String[] args) {
MyUser myUser1 = new MyUser("a", 30);
MyUser myUser2 = new MyUser("b", 20);
MyUser myUser3 = new MyUser("c", 10);
TreeSet<MyUser> treeSet1 = new TreeSet<>(); // Comparable의 기본 정렬 사용
treeSet1.add(myUser1);
treeSet1.add(myUser2);
treeSet1.add(myUser3);
System.out.println("Comparable 기본 정렬");
System.out.println(treeSet1); // 트리에 넣을 때부터 정렬이 발생
TreeSet<MyUser> treeSet2 = new TreeSet<>(new IdComparator()); // 트리에 정렬 기준을 부여
treeSet2.add(myUser1);
treeSet2.add(myUser2);
treeSet2.add(myUser3);
System.out.println("IdComparator 정렬");
System.out.println(treeSet2);
}
}
/*
Comparable 기본 정렬
[MyUser{id='c', age=10}, MyUser{id='b', age=20}, MyUser{id='a', age=30}]
IdComparator 정렬
[MyUser{id='a', age=30}, MyUser{id='b', age=20}, MyUser{id='c', age=10}]
*/정말 편리하다… 자바의 정렬 알고리즘은 거의 완성형에 가깝고 매우 복잡하다. 개발자가 정렬 알고리즘을 신경 쓰지 않으면서 정렬의 기준만 간단히 변경할 수 있도록 정렬의 기준을 Comparable과 Comparator 인터페이스를 통해 추상화한 것이다.
결론: 객체의 정렬이 필요하면 Comparable 인터페이스를 구현해서 자연 정렬, 다른 기준으로 정렬하고 싶으면 Comparator를 별도로 구현하자.
⚒ 컬렉션 유틸
이번엔 컬렉션을 좀 더 편리하게 사용할 수 있는 방법에 대해 간단히 알아보자.
package collection.utils;
import java.util.ArrayList;
import java.util.Collections;
public class CollectionsSortMain {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Integer max = Collections.max(list);
Integer min = Collections.min(list);
System.out.println("max = " + max);
System.out.println("min = " + min);
System.out.println("list = " + list);
Collections.shuffle(list);
System.out.println("shuffle list = " + list);
Collections.sort(list);
System.out.println("sort list = " + list);
Collections.reverse(list);
System.out.println("reverse list = " + list);
}
}
/*
max = 5
min = 1
list = [1, 2, 3, 4, 5]
shuffle list = [2, 4, 1, 3, 5]
sort list = [1, 2, 3, 4, 5]
reverse list = [5, 4, 3, 2, 1]
*/max(): 정렬 기준으로 최댓값을 찾아 반환한다.min(): 정렬 기준으로 최솟값을 찾아 반환한다.shuffle(): 컬렉션을 랜덤하게 섞는다.sort(): 정렬 기준으로 컬렉션을 정렬한다.reverse(): 정렬 기준의 반대로 컬렉션을 정렬한다.
package collection.utils;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class OfMain {
public static void main(String[] args) {
// 편리한 불변 컬렉션 생성
List<Integer> list = List.of(1, 2, 3);
Set<Integer> set = Set.of(1, 2, 3);
Map<Integer, String> map = Map.of(1, "one", 2, "two");
System.out.println("list = " + list);
System.out.println("set = " + set);
System.out.println("map = " + map);
System.out.println("list class = " + list.getClass());
}
}
/*
list = [1, 2, 3]
set = [3, 1, 2]
map = {2=two, 1=one}
list class = class java.util.ImmutableCollections$ListN
*/of() 메서드를 사용하면 불변 컬렉션을 편리하게 생성할 수 있다. 불변이기 때문에 변경하려고 한다면 당연히 컴파일 오류가 발생한다.
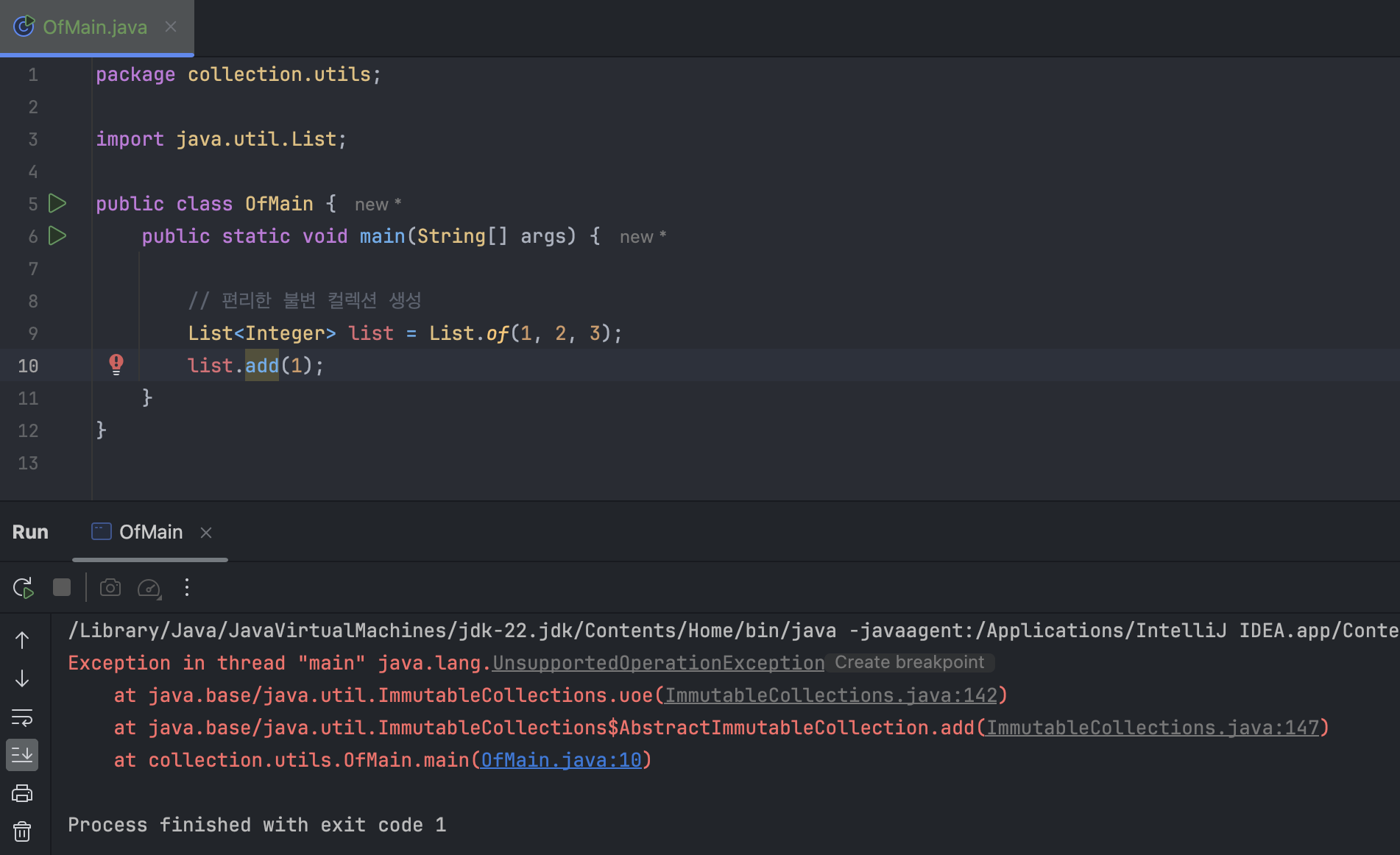
List 뿐만 아니라, Set, Map 모두 of() 메서드를 지원한다. 그리고 불변으로 생성되지만 원한다면 가변 컬렉션으로 전환할 수도 있다.
package collection.utils;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class ImmutableMain {
public static void main(String[] args) {
// 불변 리스트 생성
List<Integer> list = List.of(1, 2, 3);
// 가변 리스트로 변경
ArrayList<Integer> mutableList = new ArrayList<>(list);
mutableList.add(4);
System.out.println("mutableList = " + mutableList);
System.out.println("mutableList class = " + mutableList.getClass());
// 다시 불변 리스트로 변경
List<Integer> unmodifiableList = Collections.unmodifiableList(mutableList);
// unmodifiableList.add(5); // java.lang.UnsupportedOperationException 예외 발생
System.out.println("unmodifiableList class = " + unmodifiableList.getClass());
}
}
/*
mutableList = [1, 2, 3, 4]
mutableList class = class java.util.ArrayList
unmodifiableList class = class java.util.Collections$UnmodifiableRandomAccessList
*/보다시피, 불변 리스트를 가변 리스트로 변경하려면 new ArrayList<>()처럼 리스트를 생성해서 기존 불변 리스트를 복사해주면 되고, 다시 불변 리스트로 변환하려면 Collections.unmodifiableList()를 사용하면 된다. 각 자료 구조마다 unmodifiableXXX() 형태로 있으니까 안심해도 된다.
그리고 빈 가변 리스트도 생성 가능하다. 원하는 컬렉션의 구현체를 직접 생성하면 된다. 생성 방법에는 2가지가 있는데 하나는 Collections.emptyList()로 하는 방법이고, 다른 하나는 List.of()로 생성하는 방법이다. 이 중에서 후자를 사용하는 것을 권장한다.
package collection.utils;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class EmptyListMain {
public static void main(String[] args) {
// 빈 가변 리스트 생성
List<Integer> list1 = new ArrayList<>();
List<Integer> list2 = new ArrayList<>();
// 빈 불변 리스트 생성
List<Integer> list3 = Collections.emptyList(); // 자바 5
List<Integer> list4 = List.of(); // 자바 9 (권장)
System.out.println("list3 = " + list3.getClass());
System.out.println("list4 = " + list4.getClass());
}
}
/*
list3 = class java.util.Collections$EmptyList
list4 = class java.util.ImmutableCollections$ListN
*/Arrays.asList() 메서드를 사용해도 리스트를 생성할 수 있다. 이 메서드로 생성한 리스트는 고정된 크기를 가지지만, set() 메서드를 통해 요소들은 변경할 수 있다. add(), remove() 같은 메서드로 크기를 변경할 수 없다. 변경하면 바~로 UnsupportedOperationException이 터진다. 그래서 리스트 내부의 요소를 변경해야 하는 경우나 그럴 경우는 많이 없겠지만 자바 9 이전 버전으로 작업해야 하는 경우에만 Arrays.asList()를 사용하고 나머지는 List.of()를 사용하는 것이 권장된다.
package collection.utils;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class SyncMain {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
System.out.println("list class = " + list.getClass());
List<Integer> synchronizedList = Collections.synchronizedList(list);
System.out.println("synchronizedList class = " + synchronizedList.getClass());
}
}
/*
list class = class java.util.ArrayList
synchronizedList class = class java.util.Collections$SynchronizedRandomAccessList
*/그리고 위 코드처럼 Collections.synchronizedList를 사용하면 동기화 작업으로 인해 일반 리스트보다 성능은 조금 느리지만, 일반 리스트를 멀티스레드 상황에서 동기화 문제가 발생하지 않는 안전한 리스트로 만들 수 있다. 참고만 하고 넘어가도록 하자.
