
📃 스레드 기본 정보
Thread 클래스는 스레드를 생성하고 관리하는 기능을 제공한다. 자바가 실행될 때 기본으로 제공되는 main 스레드와 직접 만든 스레드의 정보를 코드로 확인해보도록 하자.
package thread.controll;
import thread.start.HelloRunnable;
import static util.MyLogger.log;
public class ThreadInfoMain {
public static void main(String[] args) {
Thread mainThread = Thread.currentThread();
log("mainThread = " + mainThread);
log("mainThread.threadId()=" + mainThread.threadId());
log("mainThread.getName()=" + mainThread.getName());
log("mainThread.getPriority()=" + mainThread.getPriority());
log("mainThread.getThreadGroup()=" + mainThread.getThreadGroup());
log("mainThread.getState()=" + mainThread.getState());
Thread myThread = new Thread(new HelloRunnable(), "myThread");
log("myThread = " + myThread);
log("myThread.threadId()=" + myThread.threadId());
log("myThread.getName()=" + myThread.getName());
log("myThread.getPriority()=" + myThread.getPriority());
log("myThread.getThreadGroup()=" + myThread.getThreadGroup());
log("myThread.getState()=" + myThread.getState());
}
}
/*
13:44:41.921 [ main] mainThread = Thread[#1,main,5,main]
13:44:41.925 [ main] mainThread.threadId()=1
13:44:41.925 [ main] mainThread.getName()=main
13:44:41.928 [ main] mainThread.getPriority()=5
13:44:41.928 [ main] mainThread.getThreadGroup()=java.lang.ThreadGroup[name=main,maxpri=10]
13:44:41.928 [ main] mainThread.getState()=RUNNABLE
13:44:41.929 [ main] myThread = Thread[#21,myThread,5,main]
13:44:41.929 [ main] myThread.threadId()=21
13:44:41.929 [ main] myThread.getName()=myThread
13:44:41.929 [ main] myThread.getPriority()=5
13:44:41.929 [ main] myThread.getThreadGroup()=java.lang.ThreadGroup[name=main,maxpri=10]
13:44:41.929 [ main] myThread.getState()=NEW
*/위의 코드를 보다시피, 스레드를 생성할 때 실행할 Runnable 인터페이스의 구현체 및 스레드의 이름을 정할 수 있다. 현재 코드에서는 스레드가 작업할 내용을 담고 있는 Runnable 인터페이스를 HelloRunnable로 구현하고, myThread라고 이름 지었다.
threadId() 메서드는 스레드의 고유 식별자를 반환한다. 스레드의 id는 자바가 내부적으로 스레드가 생성될 때 할당되고 직접 지정할 수 없으며, 절대 중복되지 않는다. getPriority()는 스레드의 우선 순위를 반환하는 메서드다. 값이 높을수록 우선 순위가 높은 것이다. setPriority()로 우선 순위를 변경할 수 있고, 우선 순위는 스레드 스케줄러가 어떤 스레드를 우선 실행할지 결정하는 데 사용된다. 그러나 실제 실행 순서는 JVM 구현과 OS에 따라 달라질 수 있다.
getThreadGroup() 메서드는 스레드가 속한 스레드 그룹을 반환한다. 일반적으로 모든 스레드는 부모 스레드와 같은 스레드 그룹에 속한다. 스레드 그룹으로 묶으면 여러 스레드들에게 특정 작업을 수행하도록 할 수 있다. 여기서 부모 스레드란, 새로운 스레드를 생성하는 스레드를 말한다. main 스레드를 제외한 스레드는 기본적으로 다른 스레드에 의해 생성된다. 지금 위의 코드에서 myThread를 예로 들면, main 스레드에 의해 생성되었으므로 main 스레드가 부모 스레드가 되는 것이다. 일단 스레드 그룹 기능에 대해서는 이 정도만 알고 넘어가도록 하자.
그리고 “스레드의 현재 상태를 반환해주는 getState() 메서드” 가 있다. 반환되는 값은 Thread.State의 ENUM으로 정의되어 있는 값들 중 하나다. 아래를 보자.
NEW: 스레드가 아직 시작되지 않은 상태RUNNABLE: 스레드가 실행 중이거나 실행될 준비가 된 상태BLOCKED: 스레드가 동기화 락을 기다리는 상태WAITING: 스레드가 다른 스레드의 특정 작업이 완료되기를 기다리는 상태TIMED_WAITING: 일정 시간 동안 기다리는 상태TERMINATED: 스레드가 실행을 마친 상태
위 코드의 출력 결과를 보면, main 스레드는 실행되고 있기 때문에 RUNNABLE 상태고, myThread는 생성되고 아직 start()로 시작하지 않았기 때문에 NEW 상태인 걸 확인할 수 있다.
💞 스레드의 생명 주기
이처럼 스레드는 생성부터 시작, 종료되는 생명 주기를 가진다.
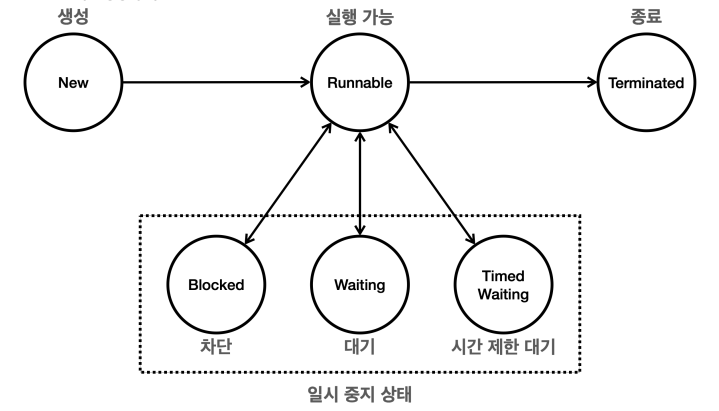
RUNNABLE 상태는 실행되다가 그대로 종료될 수도 있고 차단, 대기, 시간 제한 대기 상태를 왔다 갔다 거릴 수도 있다. 그리고 BLOCKED, WAITING, TIMED_WAITING의 경우, 스레드가 기다리는 상태라는 것을 이해하기 쉽게 “일시 중지 상태” 라고 한 것이다. 이 3가지 상태에서는 스레드가 CPU 실행 스케줄러에 들어가지 않기 때문에 코드를 실행하지 않고 가만히 놀고 있는 상태를 말한다. 실제로는 자바에서 스레드의 “일시 중지 상태” 라는 것은 없다. 이제 생명 주기에 대해 더 자세히 살펴보자.
-
NEW (새로운 상태)- 스레드가 생성되고 아직 시작되지 않은 상태
Thread객체가 생성되지만, 아직start()메서드가 호출되지 않은 상태를 말한다.- ex)
Thread thread = new Thread(runnable)
-
Runnable (실행 가능 상태)- 스레드가 실행될 준비가 된 상태로, 이제 스레드는 실제 CPU에서 실행될 수 있는 것이다.
start()메서드가 호출되었을 때, 스레드는 이Runnable상태로 되는 것이다.Runnable상태에 있는 모든 스레드가 동시에 실행되는 것은 아니다. OS의 스케줄러가 각 스레드에 CPU 시간을 할당해서 실행하기 때문에, 스케줄러의 실행 대기열에 포함되어 있다가 순차적으로 CPU에서 실행되는 것이다.
-
Blocked (차단 상태)- 스레드가 다른 스레드에 의해 동기화 락을 얻기 위해 기다리는 상태를 말한다.
synchronized블록에 진입하기 위해 락을 얻어야 하는 경우, 이 상태에 들어간다.
-
Waiting (대기 상태)- 스레드가 다른 스레드의 특정 작업이 완료되기를 무기한 기다리는 상태다.
wait(),join()메서드가 호출될 때 이 상태가 된다.- 스레드는 다른 스레드가
notify()또는notifyAll()메서드를 호출하거나,join()이 완료될 때까지 기다린다.
-
Timed Waiting (시간 제한 대기 상태)- 스레드가 특정 시간 동안 다른 스레드의 작업이 완료되기를 기다리는 상태를 말한다.
sleep(long millis),wait(long timeout),join(long millis)메서드가 호출될 때, 이 상태가 된다.- 주어진 시간이 경과되거나 다른 스레드가 해당 스레드를 깨우면 이 상태를 벗어나게 된다.
-
Terminated (종료 상태)- 스레드의 실행이 완료된 상태다.
- 스레드가 정상적으로 종료되거나, 예외가 발생해서 종료된 경우에 이 상태로 들어간다.
- 스레드는 한 번 종료되면 다시 시작할 수 없다. 새로운 스레드를 생성해야 한다.
이제 스레드의 생명 주기를 코드를 통해 확인해보자.
package thread.control;
import static util.MyLogger.log;
public class ThreadStateMain {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new MyRunnable(), "myThread");
log("myThread.state1 = " + thread.getState());
log("myThread.start()");
thread.start();
Thread.sleep(1000); // main 스레드 1초 sleep
log("myThread.state3 = " + thread.getState());
Thread.sleep(4000); // main 스레드 4초 sleep
log("myThread.state5 = " + thread.getState());
log("end");
}
static class MyRunnable implements Runnable {
@Override
public void run() {
try {
log("start");
log("myThread.state2 = " + Thread.currentThread().getState());
log("sleep() start");
Thread.sleep(3000);
log("sleep() end");
log("myThread.state4 = " + Thread.currentThread().getState());
log("end");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
/*
14:28:28.889 [ main] myThread.state1 = NEW
14:28:28.891 [ main] myThread.start()
14:28:28.891 [ myThread] start
14:28:28.891 [ myThread] myThread.state2 = RUNNABLE
14:28:28.891 [ myThread] sleep() start
14:28:29.894 [ main] myThread.state3 = TIMED_WAITING
14:28:31.896 [ myThread] sleep() end
14:28:31.898 [ myThread] myThread.state4 = RUNNABLE
14:28:31.898 [ myThread] end
14:28:33.900 [ main] myThread.state5 = TERMINATED
14:28:33.900 [ main] end
*/myThread라는 스레드를 생성하고 실행하다가 Thread.sleep(1000)를 호출한다면, main 스레드는 TIMED_WAITING 상태가 되면서 특정 1초 만큼 대기한다. 여기서 Thread.sleep() 은 InterruptedException이라는 체크 예외를 던지는데, run() 메서드 안에서 체크 예외를 반드시 잡아야 한다. 일단 이 정도만 인지하고 그림을 통해 흐름을 정확히 파악해보자.
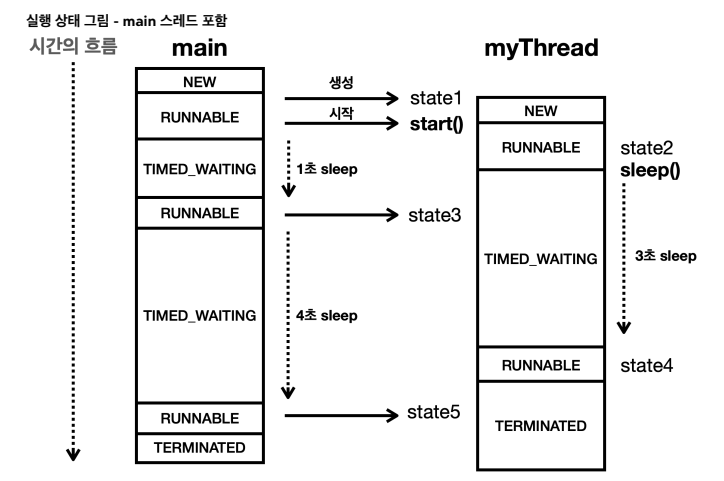
main 스레드가 myThread 스레드를 생성하고, start() 메서드를 호출함으로써 myThread 스레드에게 작업을 지시하게 되었을 때, myThread 스레드는 RUNNABLE 상태로 들어가게 된다. 그리고 myThread 스레드는 Thread.sleep(3000)로 3초간 대기한다. 따라서 이때 myThread 스레드의 상태를 조회해보면 TIMED_WAITING 상태가 된 것을 볼 수 있다. 3초가 지나면 다시 실행될 수 있는 상태인 RUNNABLE 상태로 변하고, myThread가 run() 메서드를 종료하고 나면 TERMINATED 상태가 된다. 이렇게 마지막 run() 메서드까지 실행되면 스택이 완전히 비어 해당 스택을 사용하는 스레드가 종료된다.
💥 체크 예외 오버라이딩
이제 위에서 언급했던 run() 메서드를 오버라이딩 할 때, InterruptedException 체크 예외를 밖으로 던질 수 밖에 없는 이유에 대해 알아보자.
알다시피, Runnable 인터페이스는 run() 메서드 하나만 달고 다닌다.
public interface Runnable {
void run(); // 아무 예외도 던지지 않고 있음.
}
자바에서 메서드를 오버라이딩 할 때, 예외와 관련해서 지켜야 할 규칙이 있다.
-
체크 예외일 경우- 부모 메서드가 체크 예외를 던지지 않는 경우, 오버라이딩 된 자식 메서드도 체크 예외를 던질 수 없다.
- 자식 메서드는 부모 메서드가 던질 수 있는 체크 예외의 같은 타입이나 하위 타입만 던질 수 있다.
-
언체크(런타임) 예외일 경우- 그냥 아무 상관없이 던질 수 있다.
현재 Runnable 인터페이스의 run() 메서드에서는 체크 예외 자체를 던지지 않고 있기 때문에 run() 메서드를 오버라이딩 하는 곳에서도 당연히 체크 예외를 던질 수 없다. 따라서 아래와 같은 코드는 컴파일 오류가 발생한다.
public class CheckExceptionMain {
public static void main(String[] args) throws Exception {
throw new Exception();
}
static class CheckedRunnable implements Runnable {
@Override
public void run() throws Exception { // 컴파일 오류 발생
throw new Exception(); // 컴파일 오류 발생
}
}
}
자바는 왜 이런 규칙을 정했을까? 자식 클래스가 더 넓은 범위의 예외를 던지게 되면 해당 코드는 모든 예외를 제대로 처리하지 못할 수 있기 때문이다. 이는 예외 처리의 일관성을 해치고, 예상하지 못한 런타임 오류를 초래할 수 있다. 말로 해서는 잘 와닿지 않는다. 아래 임의의 코드를 통해 확인해보자.
class Parent {
void method() throws InterruptedException {
// ...
}
}
class Child extends Parent {
@Override
void method() throws Exception {
// ...
}
}
public class Test {
public static void main(String[] args) {
Parent p = new Child();
try {
p.method();
} catch (InterruptedException e) {
// InterruptedException 처리
}
}
}클라이언트 코드를 보면, 인스턴스는 Child지만, 분명 호출자 타입이 Parent이기 때문에 컴파일러는 Parent의 method()를 호출해야 한다고 생각할 것이다. 근데 Parent의 method()를 봤더니 “얘는 InterruptedException이 터지네? 음… try-catch문으로 InterruptedException을 잡아야겠다!” 라고 생각할 것이다. 하지만 안타깝게도 Child에 method() 메서드가 오버라이딩 되어 있기 때문에, 런타임에는 Child의 method()가 호출될 것이다. 근데 이 자식이라는 놈은 Exception이라는 부모가 감당할 수 없는 대형 사고를 터뜨리네? 체크 예외는 무조건 잡거나 던져야 하는데… 지금 체크 예외를 못 잡는 상황이 된 것이다. 전혀 예상하지 못한 상황이 벌어져 체크 예외 규칙이 다 깨져버리는 것이다.
근데 Runnable 인터페이스의 run() 메서드는 왜 하필 저렇게 설계되었을까? 그냥 애초에 run() 메서드에 예외를 던져주도록 설계했다면 이런 복잡한 일이 없었을 텐데… 그 이유는, 체크 예외를 던질 수 없도록 강제해야 개발자가 그 상황을 인지하고 try-catch문으로 처리하게 된다. 그래야 예외 발생 시 예외가 적절히 처리되지 않아 프로그램이 비정상적으로 종료되는 것을 방지할 수 있다. 예를 들어, 스레드가 run() 메서드를 벗어나면 끝나는 건데, 스레드가 끝나기 전에 예외가 터질 수도 있으니 개발자로 하여금 최종 방어선을 구축하도록 강제하는 것이다.
💤 Sleep 유틸리티
Thread.sleep()은 InterruptedException 체크 예외를 발생시킨다. try-catch문을 매번 작성하는게 불편하니 편의를 위해 유틸리티 클래스를 만들도록 하자.
package util;
import static util.MyLogger.log;
public abstract class ThreadUtils {
public static void sleep(long millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
log("인터럽트 발생, " + e.getMessage());
throw new RuntimeException(e);
}
}
}📛 join() 메서드
WAITING 상태는 스레드가 다른 스레드의 특정 작업이 완료되기를 “무기한” 기다리는 상태라고 했다. 일단 아래 코드를 보자.
package thread.control.join;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class JoinMainV0 {
public static void main(String[] args) {
log("Start");
Thread thread1 = new Thread(new Job(), "thread-1");
Thread thread2 = new Thread(new Job(), "thread-2");
thread1.start();
thread2.start();
log("End");
}
static class Job implements Runnable {
@Override
public void run() {
log("작업 시작");
sleep(2000);
log("작업 완료");
}
}
}
/*
21:42:39.348 [ main] Start
21:42:39.350 [ thread-1] 작업 시작
21:42:39.350 [ main] End
21:42:39.350 [ thread-2] 작업 시작
21:42:41.355 [ thread-1] 작업 완료
21:42:41.355 [ thread-2] 작업 완료
*/그냥 main 스레드가 thread-1 스레드와 thread-2 스레드를 생성하고, 실행해서 각각의 특정 작업을 수행하도록 한 것이다. 출력 결과를 보면, main 스레드가 먼저 종료되고, thread-1 스레드와 thread-2 스레드가 종료된다. 근데 이게 뭐가 문제인지 감이 안 온다. 그럼 예시를 들어보자.
1부터 100까지 더하는 작업을 수행하는데, CPU 코어를 더 효율적으로 사용하기 위해 이를 1부터 50까지 더하는 작업과 51부터 100까지 더하는 작업으로 나눠서 마지막에 합치도록 하자.
package thread.control.join;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class JoinMainV1 {
public static void main(String[] args) {
log("Start");
SumTask task1 = new SumTask(1, 50);
SumTask task2 = new SumTask(51, 100);
Thread thread1 = new Thread(task1, "thread-1");
Thread thread2 = new Thread(task2, "thread-2");
thread1.start(); // main 스레드: thread1 일 시작해!
thread2.start(); // main 스레드: thread2 일 시작해!
log("task1.result = " + task1.result);
log("task2.result = " + task2.result);
int sumAll = task1.result + task2.result;
log("task1 + task2 = " + sumAll);
log("End");
}
static class SumTask implements Runnable {
int startValue;
int endValue;
int result;
public SumTask(int startValue, int endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
public void run() {
log("작업 시작");
sleep(2000);
int sum = 0;
for (int i = startValue; i <= endValue; i++) {
sum += i;
}
result = sum;
log("작업 완료 result = " + result);
}
}
}
/*
22:13:48.883 [ main] Start
22:13:48.885 [ thread-1] 작업 시작
22:13:48.885 [ thread-2] 작업 시작
22:13:48.887 [ main] task1.result = 0
22:13:48.887 [ main] task2.result = 0
22:13:48.887 [ main] task1 + task2 = 0
22:13:48.887 [ main] End
22:13:50.891 [ thread-1] 작업 완료 result = 1275
22:13:50.891 [ thread-2] 작업 완료 result = 3775
*/설계한 것처럼, 1부터 50까지 더하는 작업을 task1 스레드에게 맡기고, 51부터 100까지 더하는 작업은 task2에게 맡겨서 마지막에 합친 결과를 main 스레드가 받도록 했다. 근데 결과는…? main 스레드는 합친 결과를 받아 보지도 못하고 끝나버렸다… 뭔가 main 스레드가 억울한 것 같다. 하지만, 그림으로도 한 번 살펴보자.
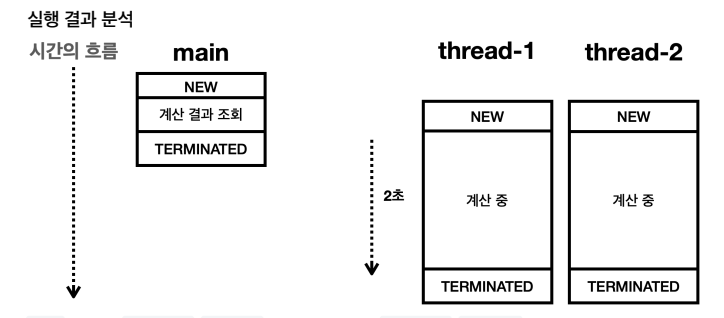
다시 살펴보니, main 스레드가 방금 업무를 줬는데 주자마자 “다 하셨나요?” 라고 묻는 킹받는 상황이었다. 메모리 구조로 더 자세히 알아보자.
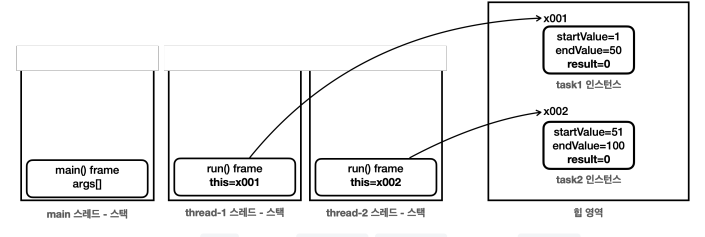
main 스레드는 thread-1, thread-2를 생성하고 start()로 실행한다. 그럼 thread-1과 thread-2는 본인에게 주어진 과업을 열심히 수행하기 위해 SumTask 인스턴스의 run() 메서드를 본인의 스택에 올리고 run() 메서드를 실행해서 작업을 수행한다. 근데 main 스레드는 두 스레드를 시작한 다음에 바로 task1.result , task2.result를 통해 인스턴스에 있는 결과 값을 조회한 것이다. 두 스레드가 계산을 완료하고, result에 연산 결과를 담을 때까지 2초 정도 시간이 걸리는데, 그 전에 main 스레드가 result를 조회해버린 상황이라는 말이다. 그러니 당연히 값이 없지…
🤔 this의 비밀?
어떤 메서드를 호출한다는 의미는, 정확히 말하면 “특정 스레드가 어떤 메서드를 호출하는 것” 이다.
코드를 다시 살펴보면…
Thread thread1 = new Thread(task1, "thread-1");
Thread thread2 = new Thread(task2, "thread-2");
thread1.start(); // main 스레드: thread1 일 시작해!
thread2.start(); // main 스레드: thread2 일 시작해!
...
static class SumTask implements Runnable {
int startValue;
int endValue;
int result;
public SumTask(int startValue, int endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
...
@Override
public void run() {
log("작업 시작");
sleep(2000);
int sum = 0;
...
}
}힙 영역에 task1 인스턴스와 task2 인스턴스가 있는데, run() 메서드는 하나다. 그럼 run() 이라는 이름 하나만으로 어떤 인스턴스가 호출하는건지 구분할 수 있을까?
인스턴스의 메서드를 호출하게 되면, 어떤 인스턴스의 메서드를 호출했는지 기억하기 위해 해당 인스턴스의 참조값을 스택 프레임 내부에 저장해둔다. “이게 바로 this인 것이다.” 그래서 특정 메서드 안에서 this를 호출하면 바로 스택 프레임 안에 있는 this 값을 불러서 사용하게 된다. 위의 코드를 봐도, sum은 어차피 지역 변수니까 스택 프레임에 들어가니까 됐고, startValue나 endValue를 꺼낼 때는 어느 인스턴스에 있는 값을 꺼내야 하는지 문제가 되는데, 이때 run() 메서드를 호출한 스택 프레임은 자신의 인스턴스 참조값(this)을 스택 프레임 안에 갖고 있기 때문에 본인의 startValue나 endValue를 꺼낼 수 있는 것이다.
마저 얘기하자면, 일단 지금 해결해야 할 문제는 thread-1, thread-2의 계산이 끝날 때 까지 main 스레드가 기다려줘야 한다는 것이다. 일단 무식하면서도 가장 간단한 방법은 main 스레드에 sleep()을 때려주는거다.
package thread.control.join;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class JoinMainV2 {
public static void main(String[] args) {
log("Start");
SumTask task1 = new SumTask(1, 50);
SumTask task2 = new SumTask(51, 100);
Thread thread1 = new Thread(task1, "thread-1");
Thread thread2 = new Thread(task2, "thread-2");
thread1.start(); // main 스레드: thread1 일 시작해!
thread2.start(); // main 스레드: thread2 일 시작해!
log("main 스레드 sleep()");
sleep(3000);
log("main 스레드 깨어남");
log("task1.result = " + task1.result);
log("task2.result = " + task2.result);
int sumAll = task1.result + task2.result;
log("task1 + task2 = " + sumAll);
log("End");
}
static class SumTask implements Runnable {
int startValue;
int endValue;
int result;
public SumTask(int startValue, int endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
public void run() {
log("작업 시작");
sleep(2000);
int sum = 0;
for (int i = startValue; i <= endValue; i++) {
sum += i;
}
result = sum;
log("작업 완료 result = " + result);
}
}
}
/*
22:27:06.155 [ main] Start
22:27:06.156 [ main] main 스레드 sleep()
22:27:06.156 [ thread-1] 작업 시작
22:27:06.156 [ thread-2] 작업 시작
22:27:08.171 [ thread-1] 작업 완료 result = 1275
22:27:08.171 [ thread-2] 작업 완료 result = 3775
22:27:09.162 [ main] main 스레드 깨어남
22:27:09.163 [ main] task1.result = 1275
22:27:09.164 [ main] task2.result = 3775
22:27:09.164 [ main] task1 + task2 = 5050
22:27:09.165 [ main] End
*/근데 잠깐 생각해봐도, 완전 비효율적일 가능성이 높다. 다른 작업들이 얼마나 걸릴지도 모르는데 기다릴 시간을 지정해 놓는다는 것도 웃기고, 만약 기다리는데 성공한다고 하더라도 시간을 낭비할 수도 있다.
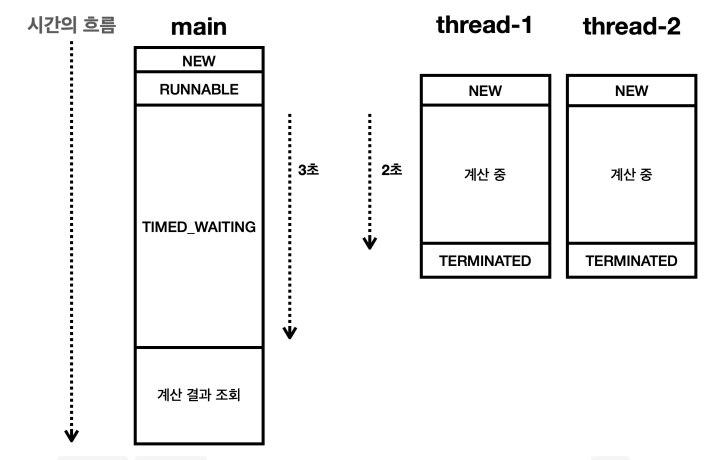
위 코드에서도 thread-1과 thread-2 스레드가 계산을 다 끝냈음에도 main 스레드는 1초를 더 기다리고 있다. 좋지 않다… 그냥 join() 메서드를 사용하자!
package thread.control.join;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class JoinMainV3 {
public static void main(String[] args) throws InterruptedException {
log("Start");
SumTask task1 = new SumTask(1, 50);
SumTask task2 = new SumTask(51, 100);
Thread thread1 = new Thread(task1, "thread-1");
Thread thread2 = new Thread(task2, "thread-2");
thread1.start(); // main 스레드: thread1 일 시작해!
thread2.start(); // main 스레드: thread2 일 시작해!
// 스레드가 종료될 때까지 대기한다.
log("join() - main 스레드가 thread1, thread2 종료까지 대기...");
thread1.join();
thread2.join();
log("main 스레드 대기 완료!");
log("task1.result = " + task1.result);
log("task2.result = " + task2.result);
int sumAll = task1.result + task2.result;
log("task1 + task2 = " + sumAll);
log("End");
}
static class SumTask implements Runnable {
int startValue;
int endValue;
int result;
public SumTask(int startValue, int endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
public void run() {
log("작업 시작");
sleep(2000);
int sum = 0;
for (int i = startValue; i <= endValue; i++) {
sum += i;
}
result = sum;
log("작업 완료 result = " + result);
}
}
}
/*
22:33:29.333 [ main] Start
22:33:29.334 [ thread-1] 작업 시작
22:33:29.334 [ main] join() - main 스레드가 thread1, thread2 종료까지 대기...
22:33:29.334 [ thread-2] 작업 시작
22:33:31.350 [ thread-1] 작업 완료 result = 1275
22:33:31.350 [ thread-2] 작업 완료 result = 3775
22:33:31.351 [ main] main 스레드 대기 완료!
22:33:31.352 [ main] task1.result = 1275
22:33:31.352 [ main] task2.result = 3775
22:33:31.353 [ main] task1 + task2 = 5050
22:33:31.353 [ main] End
*/성공적으로 5050이라는 결과를 받은 것을 볼 수 있다. main 스레드에서 join() 메서드를 사용하게 되면, 스레드들이 종료될 때까지 main 스레드는 WAITING 상태가 된다.
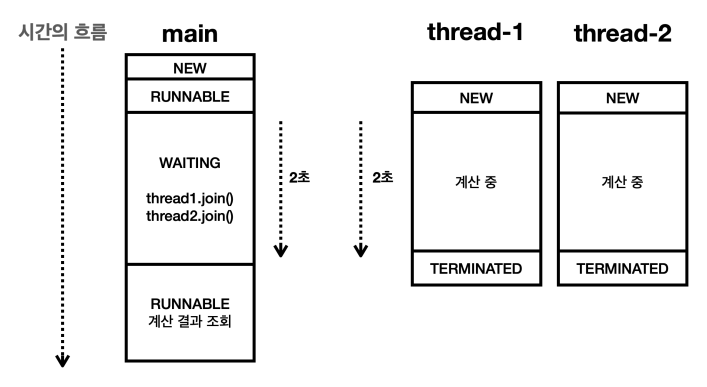
thread-1 스레드가 아직 종료되지 않았다면, main 스레드는 thread1.join() 코드 안에 갇히게 된다. thread-1 스레드가 종료돼야 main 스레드는 RUNNABLE 상태가 되고 다음 코드로 넘어갈 수 있는 것이다. thread-2도 마찬가지다. 하지만, 순수 join() 메서드를 사용하면 다른 스레드가 완료될 때까지 무기한 기다려야 할 수도 있다. 식당 웨이팅을 하는데 자리가 날 때까지 몇 시간이고 기다려야 하는 상황인 것이다. 심지어 중간에 나갈 수도 없는 것이다.
그럼 일정 시간 동안만 기다리게 하면 된다. join() 메서드는 대기 시간도 파라미터로 넘길 수 있도록 오버로딩 되어 있다.
package thread.control.join;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class JoinMainV4 {
public static void main(String[] args) throws InterruptedException {
log("Start");
SumTask task1 = new SumTask(1, 50);
Thread thread1 = new Thread(task1, "thread-1");
thread1.start(); // main 스레드: thread1 일 시작해!
// 스레드가 종료될 때까지 대기한다.
log("join(1000) - main 스레드가 thread1 종료까지 1초 대기...");
thread1.join(1000); // 1초만 대기
log("main 스레드 대기 완료!");
log("task1.result = " + task1.result);
log("End");
}
static class SumTask implements Runnable {
int startValue;
int endValue;
int result;
public SumTask(int startValue, int endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
public void run() {
log("작업 시작");
sleep(2000);
int sum = 0;
for (int i = startValue; i <= endValue; i++) {
sum += i;
}
result = sum;
log("작업 완료 result = " + result);
}
}
}
/*
22:42:16.325 [ main] Start
22:42:16.327 [ main] join(1000) - main 스레드가 thread1 종료까지 1초 대기...
22:42:16.327 [ thread-1] 작업 시작
22:42:17.332 [ main] main 스레드 대기 완료!
22:42:17.339 [ main] task1.result = 0
22:42:17.340 [ main] End
22:42:18.334 [ thread-1] 작업 완료 result = 1275
*/main 스레드는 join(1000)을 사용해서 thread-1 스레드를 1초간 기다린다. 이때 main 스레드의 상태는 TIMED_WAITING이 된다. 하지만 thread-1 스레드의 작업은 2초간 진행되므로, main 스레드가 1초 동안 기다렸다가 조회해도 여전히 task1.result = 0을 볼 수 밖에 없다. 따라서 기다리다 중간에 나오는 상황인데, 결과가 없다면 추가적인 오류 처리가 필요할 수 있다.
