
프로젝트를 기획하는 단계를 거쳐 ERD라는 것을 설계해야 한다. ERD란 데이터베이스의 개체, 속성, 관계를 시각적으로 나타내는 방법인데, 데이터베이스를 설계하기 전에 ERD를 작성하는 것이 일반적이다.
데이터베이스 설계
사실 어딜 가나, 가장 중요한 건 설계가 아닐까 싶다. 애석하게도 난 설계에 너무나도 재능이 없다. 항상 좌절을 맛보는 곳이 설계 쪽이 아닌가 싶다. 그래도 제대로 정리해서 익숙해져야 한다.
요구사항 파악
데이터베이스를 설계하기 전에 요구사항을 가지고 어떤 데이터가 필요한지, 어떤 관계가 필요한지 등 파악해야 하는 단계를 거쳐야 한다.
개체 식별
요구사항을 파악한 후에는 데이터베이스에 들어갈 개체를 식별한다. 개체는 데이터베이스에서 중요한 역할을 담당하며, 테이블로 표현된다. 여기서 개체는 쉽게 말하면 Entity라고 생각하면 된다.
속성 식별
개체를 식별한 후에는 개체에 포함될 속성을 식별한다. 속성은 테이블에서 열 또는 Column으로 표현된다.
관계 식별
개체와 개체 사이의 관계를 식별합니다. 관계는 테이블 간에 외래키(Foreign Key)로 표현된다. 즉, 각 로우가 가지고 있는 FK를 가지고 참조되는 테이블에서 맵핑되는 값을 찾아갈 수 있다. 이렇게 연관 관계가 맺어지는 것
ERD 작성
개체, 속성, 관계 등을 시각적으로 나타내는 ERD를 작성한다. ERD는 테이블 간의 관계, 필드 등을 보여준다. ERD Cloud를 통해 작성할 수 있다.
데이터베이스 생성
ERD를 기반으로 데이터베이스를 생성하고, 데이터베이스 생성 시 ERD의 구조를 따라 데이터베이스 테이블을 생성하고 필요한 인덱스, 제약 조건 등을 설정한다.
데이터 입력
데이터베이스를 생성한 후에는 데이터를 입력한다. 이때 ERD의 구조를 따라 데이터를 입력해야 한다.
정규화
처음에 DB를 설계할 때 정규화를 고려해서 테이블을 설계하는 게 좋다. 다만, 정규화도 수준이 있고 난이도가 조금 어렵기 때문에 제대로 알고 쓰는 게 좋다.
정규화는 중복을 제거하고 데이터 일관성을 보장하기 위해 관계형 데이터베이스에서 데이터를 구성하는 프로세스다. 정규화된 데이터베이스에서 각 테이블은 단일 Entity를 나타내며 테이블의 각 특성에는 원자성 또는 분할할 수 없는 값만 포함된다.
원자성과 분할할 수 없는 불가분의 개념은 동일하다고 보면 된다. 정규화는 데이터 불일치를 방지하고, 데이터베이스에 필요한 저장 공간을 줄이고, 데이터 유지 및 업데이트를 쉽게 하기 때문에 중요하다.
1NF(제1 정규형)
1NF에서 각 속성에는 원자 값만 포함된다. 즉, 속성에 여러 값이나 반복 그룹이 포함되어서는 안 되며, 하나의 값만 들어가야 한다.
Before
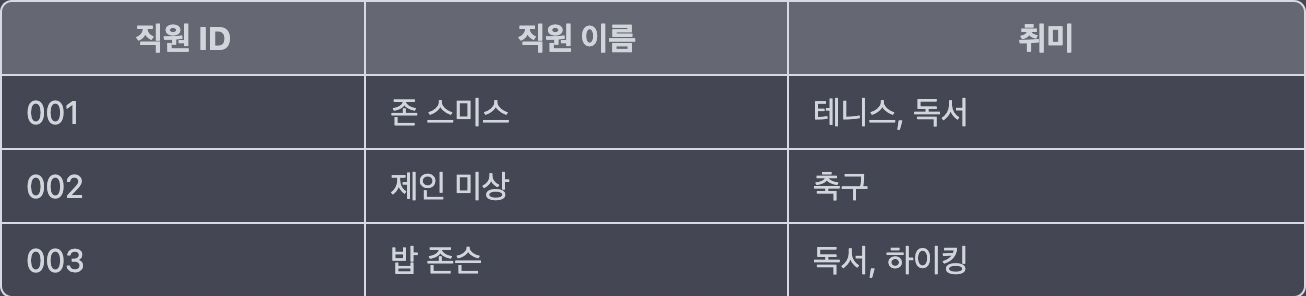
해당 테이블의 문제는 취미의 속성에서 하나의 속성에 2개의 값이 들어있는 게 보인다. 제1 정규형에 따르면 하나의 속성에는 원자성과 불가분의 성질을 띠는 값이 들어와야 한다. 즉, 여러 값이 들어오는 것보다, 더 이상 나눠지지 않을 때까지 쪼개는 단계를 거쳐야 한다는 것이다. 이렇게 쪼개는 이유는 SELECT * FROM 직원 WHERE 취미 = '테니스' ;를 해보면 알 수 있다. 이렇게 했을 때 1번 로우가 출력이 될 것 같지만, 그렇지 않다. 왜냐하면 취미가 '테니스'가 아닌 '테니스, 독서'이기 때문이다. 그렇기 때문에, 취미를 별도의 테이블로 만들던지 중복을 제거해서 작성을 해줘야 한다. 하나의 컬럼에는 하나의 값만 올 수 있도록 하자.
After

각각의 속성이 단일 값만을 가지고 있는 것을 볼 수 있다. 데이터를 정규화하기 위해 각 취미에 대한 고유 식별자를 사용하여 제품에 대한 새 테이블을 만들 수 있다. 그리고 나서 위에서는 테니스, 읽기, 축구, 하이킹 등으로 나오지만 취미가 저장된 테이블을 만든 후에 취미 에서 취미 테이블을 참조할 수 있게 하면 데이터의 중복을 제거하고 검색이 빨라진다. 추가적으로 데이터모델링을 설계할 때 유연하게 설계 할 수 있다. 스키마의 수정과 확장이 쉬워진다.
2NF(제2 정규형)
제2 정규형에서는 키가 아닌 각 속성은 PK에 기능적으로 종속된다. 이는 테이블의 각 속성이 중복 데이터(아래의 조지 오웰과 orwell@gmail.com)를 도입하지 않는 방식으로 PK와 관련되어야 함을 의미한다. 쉽게 말해서, 특정 필드에 부분적으로 종속적인 데이터들을 분리하여 해결하고자 하는 것이다.
Before

위와 같이 작성자 이메일은 작성자 이름에 의존하게 되고 새로운 로우가 생길 때마다 계속해서 중복이 발생할 수도 있게 되는 것이다. 위의 테이블에서 사실 중요한 건 책 제목과 작성자이다. 작성자 이메일은 그저 작성자 이름에 종속되고 있을 뿐 작성자가 조지 오웰이라서 orwell@gmail.com이 계속 따라 붙는 것이다. 추가로 작성자 이름 또한 중복되고 있는데 이것 또한 없애는 게 좋다.
이러한 중복을 왜 없애야 될까?
만약 조지 오웰이라는 사람의 이름이 사실 조지 오웬이었다면?
해당 저자의 이메일이 바뀌었다면?
뭐 일일이 바꿔주면 되는 거 아니야? 라고 하실 수도 있겠지만, 실제로 데이터베이스에는 어마어마한 데이터를 보관하고 있기 때문에 일일이 바꿔주는 것 자체는 불가능하다고 볼 수 있다.이 때는, 종속하고 있는 값을 Key로 놔두고, 나머지는 속성으로 놔둔 후에 참조하게 하면 된다. 즉, Author의 기본키만 해당 테이블에 놔두면 된다.
After
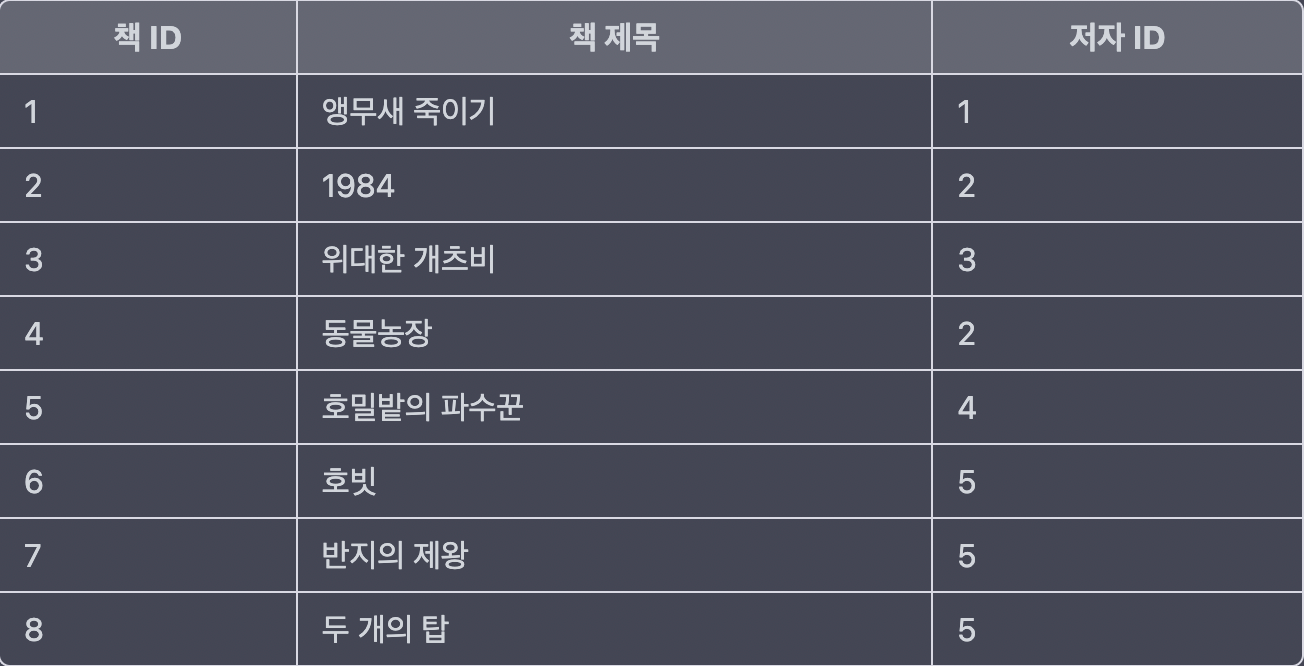
저자의 기본키(PK), 책 테이블에서는 FK인 저자의 ID를 가지고 참조할 수 있게 했다.

이렇게 저자의 이름을 정리하였고, 이름의 변경이 생기게 되면 해당 테이블만 수정해주면 저자를 참조하는 곳에서는 데이터를 수정할 필요가 없게 된다. 이메일은 여기서 빠져있는데 컬럼만 추가하면 된다. 다시 한 번 개념을 정리하자면, 제2 정규형에서 키가 아닌 각 속성(저자의 이름과 이메일)은 전체 기본 키(책ID)에 기능적으로 종속되는데, 이는 테이블의 각 속성이 중복 데이터를 도입하지 않는 방식으로 기본 키(저자ID)와 관련되어야 한다는 것이다.
요약하면, 키가 아닌 각 속성들 즉, 종속되고 있는 속성들만 따로 떼내서 별개의 테이블로 정리하면 된다. 그리고 참조하게 하면 된다.
3NF(제3 정규형)
제3 정규형에서 키가 아닌 각 속성은 기본 키에 비전이적으로 종속된다. 이는 테이블의 각 속성이 다른 속성을 통해서가 아니라 기본 키와 직접적으로 관련되어야 함을 의미한다. 굉장히 이해하기 어려울 것이다. 예시를 보면서 얘기해보자.
Before

After

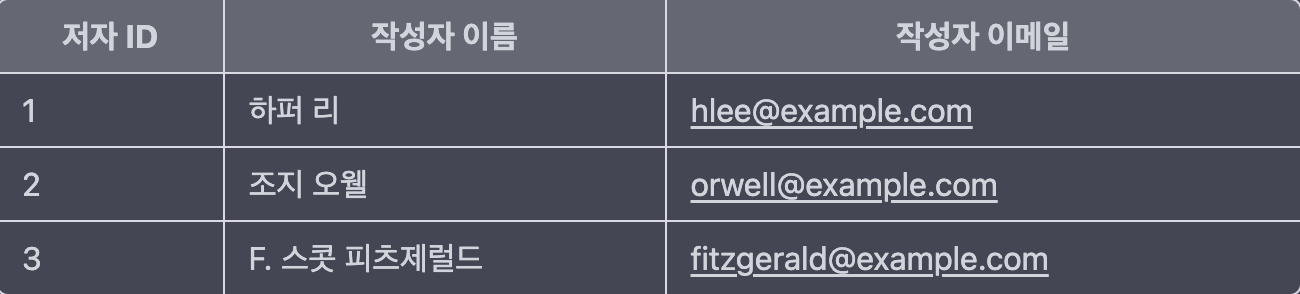
위의 항목에서 기본키가 아닌 속성(고객 전화, 항목 설명)이 키가 아닌 속성(고객명, 항목 번호)에 종속하고 있다. X(책ID)가 결정되어 Y(저자 ID)이 결정되고, Y(저자 ID)가 결정되어 Z(작성자 이름 또는 이메일)가 결정된다. 즉, X가 결정되어 Z가 결정되는 꼴이 되는 것이다. 이렇게 Z가 Y에 의존하는데, Y도 X에 의존하게 되는 걸 이행 함수의 종속성이라고 표현한다. 이러한 경우에는 고객과 항목을 별도의 테이블로 둬서 분리하는 게 좋다. 정규형을 적용하기 가장 쉬운 방법은 Prefix를 보고 무의식적으로 분리하는 것이다.
참고: https://mr-dan.tistory.com/10#recentEntries (추천 -> 정리가 매우 잘 되어 있다.)
잘못된 정보는 지적해주시면 감사하겠습니다.
