
Spring Framework
Spring Framework는 여러 서비스를 제공하며, 드넓은 생태계로 이루어진 프레임워크이다. 여기서 프레임워크는 개발자가 작성한 코드를 제어할 수 있는 권한을 가지고 있으면서 여러 기능을 제공하는 도구라고 보면 된다. 이름 그대로 뼈대 또는 골조라고 생각하자.
Bean
Spring이 생명주기를 관리해주는 객체인데, 기본적으로 싱글톤으로 생성이 되며 원하는 경우에는 프로토타입 스코프나 웹 스코프로도 생성할 수 있다. 의존성을 주입할 때 사용되는 게 바로 이 Bean 객체이다. 어렵게 생각할 필요는 없다.
ApplicationContext
스프링 컨테이너라고 부르는 이 Application Context는 Bean들을 생명주기를 관리해주는 컨테이너이다. Bean 저장소라고 생각하면 더 이해가 쉬울 것이다. Application Context은 Bean과 관련된 다양한 메서드를 제공한다.(등록된 Bean 반환 등)
Configuration
Bean으로 등록하기 위한 설정 파일이라고 보면 된다. Configuration 클래스를 사용함으로써 작성된 코드 사용 영역과 객체를 생성하고 구성하는 영역으로 분리할 수 있게 되는 것이다.
아래처럼 @Configuration 애너테이션을 클래스 단계에 적용시켜서 사용할 수 있고, 만들고자 하는 Bean객체들을 @Bean 애너테이션을 붙여서 생성할 수 있다.
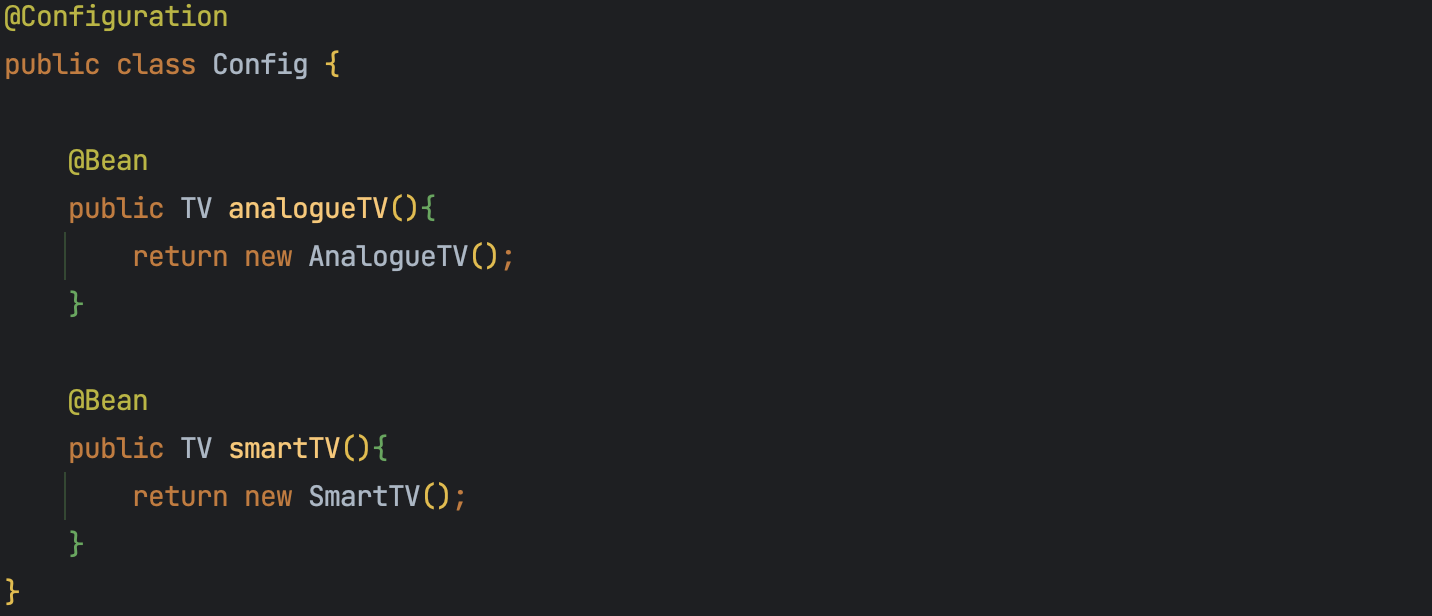
일반적인 경우에는 메서드 이름(analogueTV, smartTV)으로 Bean이 생성된다. 다만, 아래의 경우 같은 타입을 반환하기 때문에 메서드 이름이 다르더라도 Bean 이름을 설정해줘야 한다.
@Bean(name = "analogueTV"), @Bean(name = "smartTV")그렇다면 왜 동일한 타입을 반환하는 경우 Bean 이름을 설정해야 되는 걸까? 아래의 코드를 보면 이해가 될 것이다.
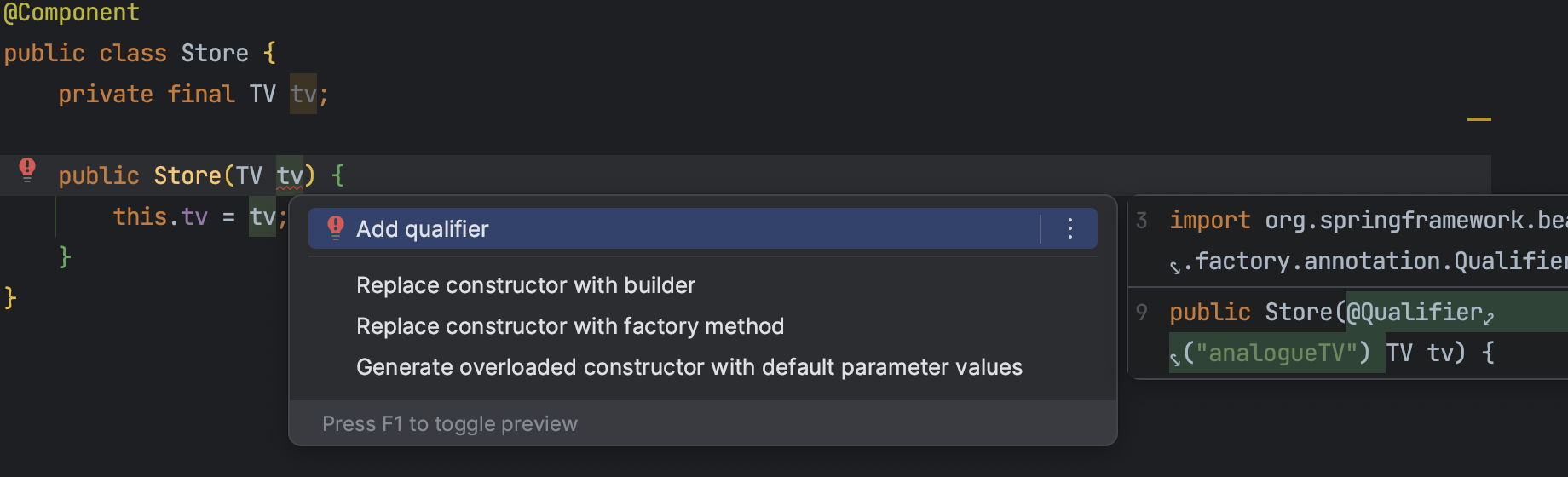
TV 타입을 반환하는 Bean이 한 개가 아니기 때문에 컴파일 에러가 나고 있고, Intellij에서는 Qualifer 키워드를 사용하여 Bean 이름을 설정해서 주입할 것을 추천하고 있다.
같은 타입의 Bean을 생성할 수는 있지만, 주입하는 시점에서 주입하려는 타입으로 등록된 Bean이 두 개 이상이기 때문에 어떤 Bean을 주입할 것인지 명시를 해줘야 한다는 것이다.
즉, 같은 타입을 반환하는 Bean이 여러 개인 경우 꼭 @Bean(name="")을 설정해주자
 @Qualifier를 설정하니 컴파일 에러가 사라진 걸 볼 수 있다.
@Qualifier를 설정하니 컴파일 에러가 사라진 걸 볼 수 있다.
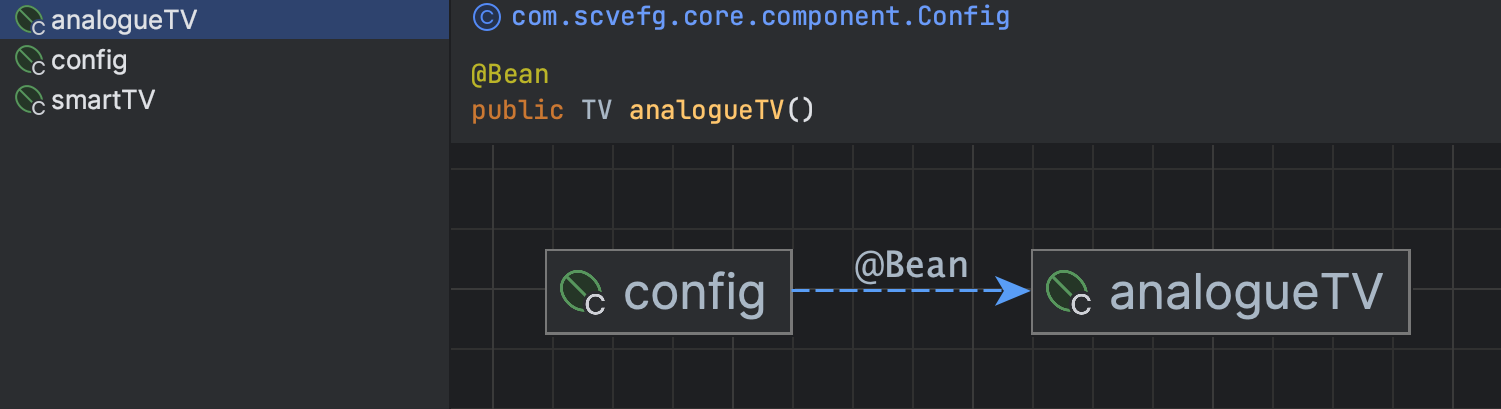
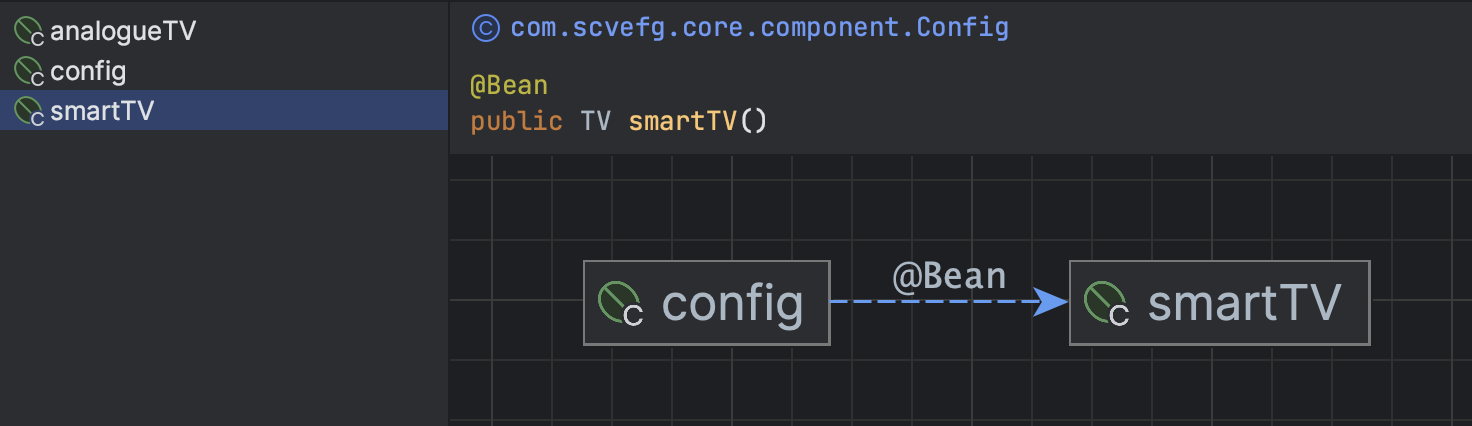
위에서 확인할 수 있듯이, 같은 타입의 Bean이 여러 개를 등록할 수는 있다.
Bean은 매우 중요한 개념이다. 처음에는 그렇게 중요하다고 느끼지 못할 수도 있지만, 나중에 모듈 간 의존성을 추가해야 하는 상황에서는 이렇게 기본적인 Bean 관리 조차도 어렵게 느껴지기 때문에 결국엔 다시 돌고 돌아 기초를 다시 배우러 가게 되기 때문이다. Bean에 대한 개념이 부족하면 나중에 정말 정말 힘들어진다. 꼭 숙지하고 가자 !
Component
@Component를 클래스 단계에 적용시켜 Bean으로 등록할 수 있다. 어떤 경우에 @Bean을 사용하고, 어떤 경우에 @Component를 사용하면 될까?
직접 작성한 클래스의 경우
@Configuration + @Bean or @Component 둘 다 가능(다만, Config.class를 통해 ApplicationContext에서 가져오려는 경우 @Bean으로 등록해서 사용)
외부 라이브러리에서 가져오는 경우
의존성을 추가하여 외부의 라이브러리에서 가져오는 경우에는 우리가 코드를 수정할 수 없다. 즉, 클래스 단계에서 @Component를 적용할 수 없게 된다는 것이고, 이 경우에는 @Configuration을 적용한 설정 파일에서 @Bean으로 등록해서 사용하면 된다.
DI
DI(Dependency Injection)는 이름 그대로 의존성 주입을 뜻하는 키워드이다. 우리가 @Bean 또는 @Component로 등록한 Bean 객체를 사용하고 싶은 곳이 있을 것이다. Layered Architecture를 예로 들면, Controller에서는 Service를 의존하고, Service에서는 Repository를 의존하는 게 일반적인 경우인데,
이 때 의존성을 주입하기 위해서 어떻게 해야 할까?
Spring 이전까지는 인스턴스를 직접 생성해서 생성자를 통하거나 setter방식으로 값을 설정했을 것이고, Spring에 넘어 오고 나서는 ApplicationContext라는 객체를 통해 Bean으로 등록할 수 있게 되고, 이것을 어떻게 주입하는지에 대한 고민을 해보게 될 때가 온 것이다. 먼저, 이 문제를 Spring에서 권장하는 생성자 주입 방식으로 해결하기 위해서 코드를 다시 가져와보겠다.
생성자 주입(권장)

생성자에 필요한 객체가 Bean객체로 등록되어 있는 경우 생성자 주입을 사용하면 자동으로 주입을 해준다. 다만, 생성자가 하나인 경우는 상관 없지만 아래처럼 생성자가 두 개 이상인 경우에는 @Autowired를 붙여 줘야 한다.
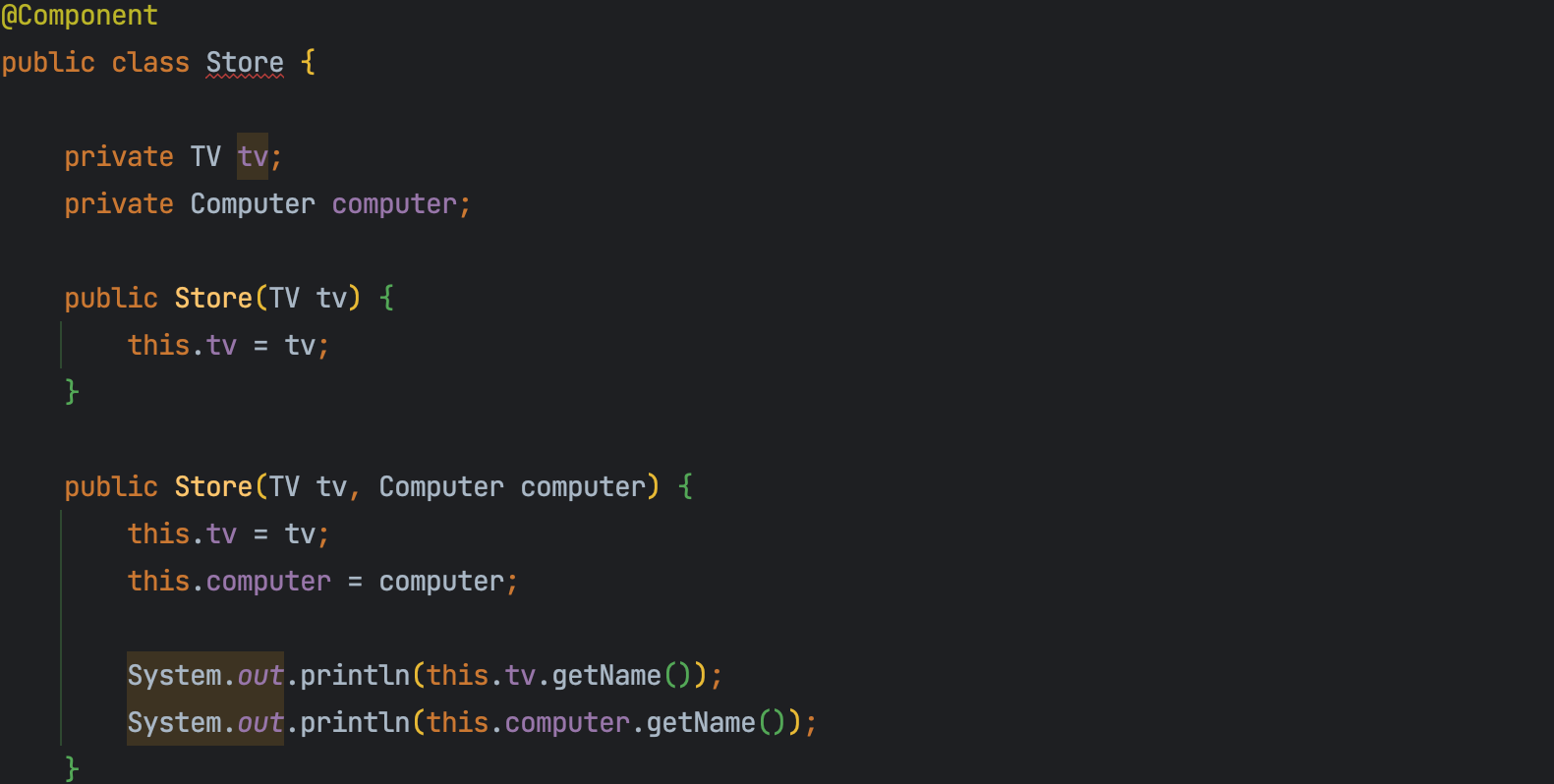
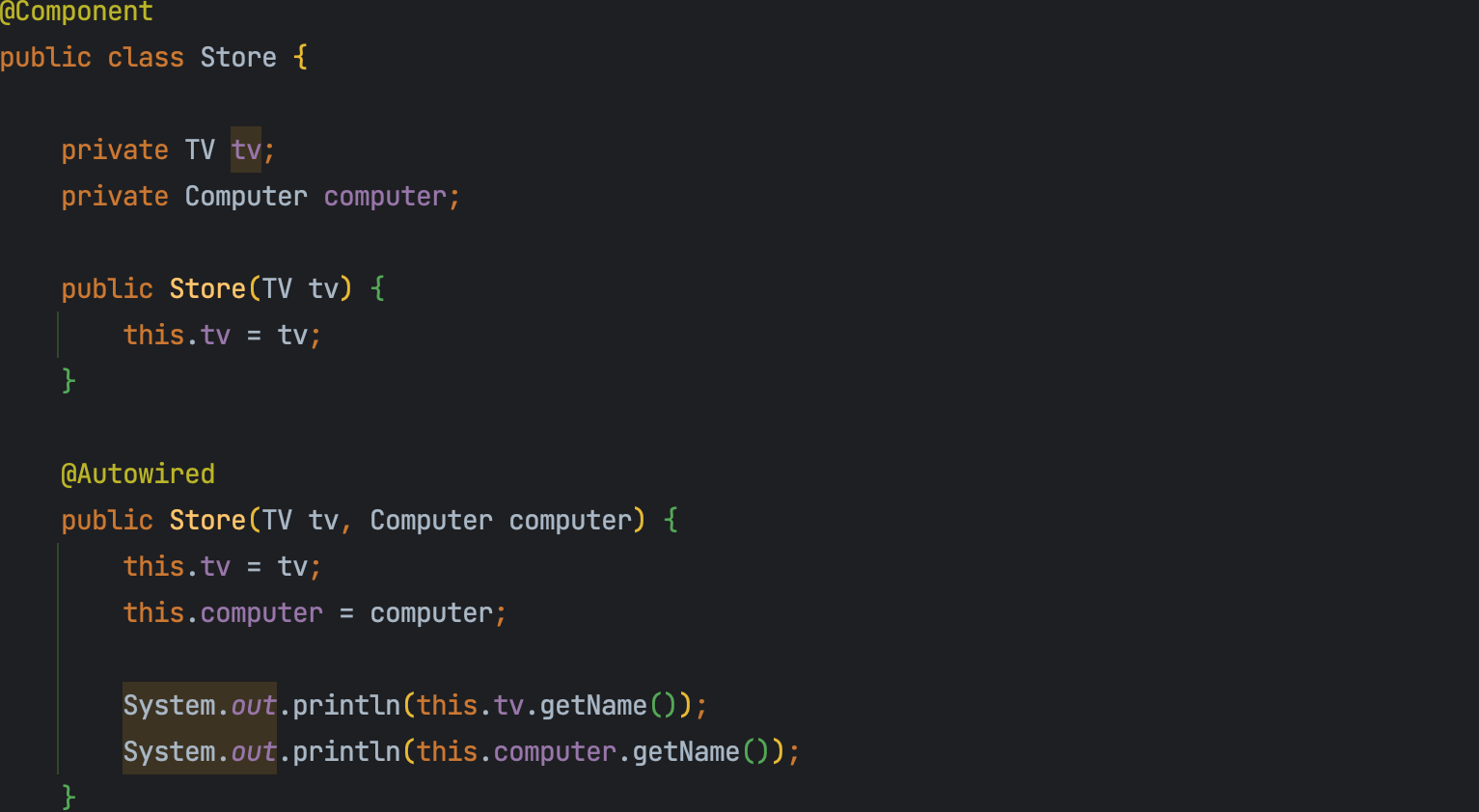

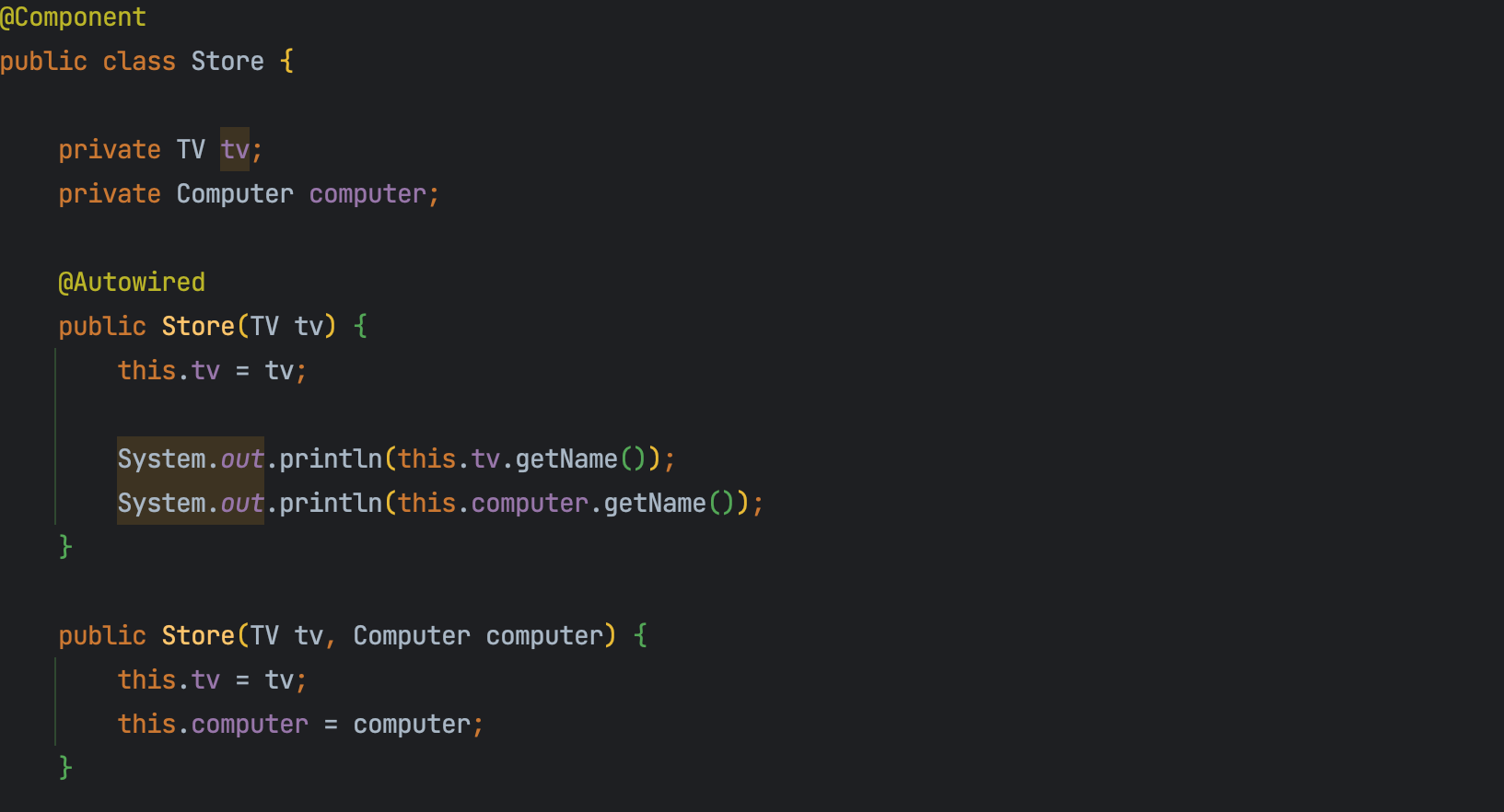
생성자가 2개 이상인 경우 @Autowired를 붙이지 않으면 Store클래스에 컴파일 에러가 나는데, @Autowired를 추가하고 나니 컴파일 에러가 사라졌다는 걸 확인할 수 있다.
실행을 해보면 두 Bean 객체 모두 잘 담기고, Store 객체가 Bean 객체로 생성되면서 의존하고 있던 tv와 computer의 메서드를 잘 호출해주는 걸 볼 수 있다.
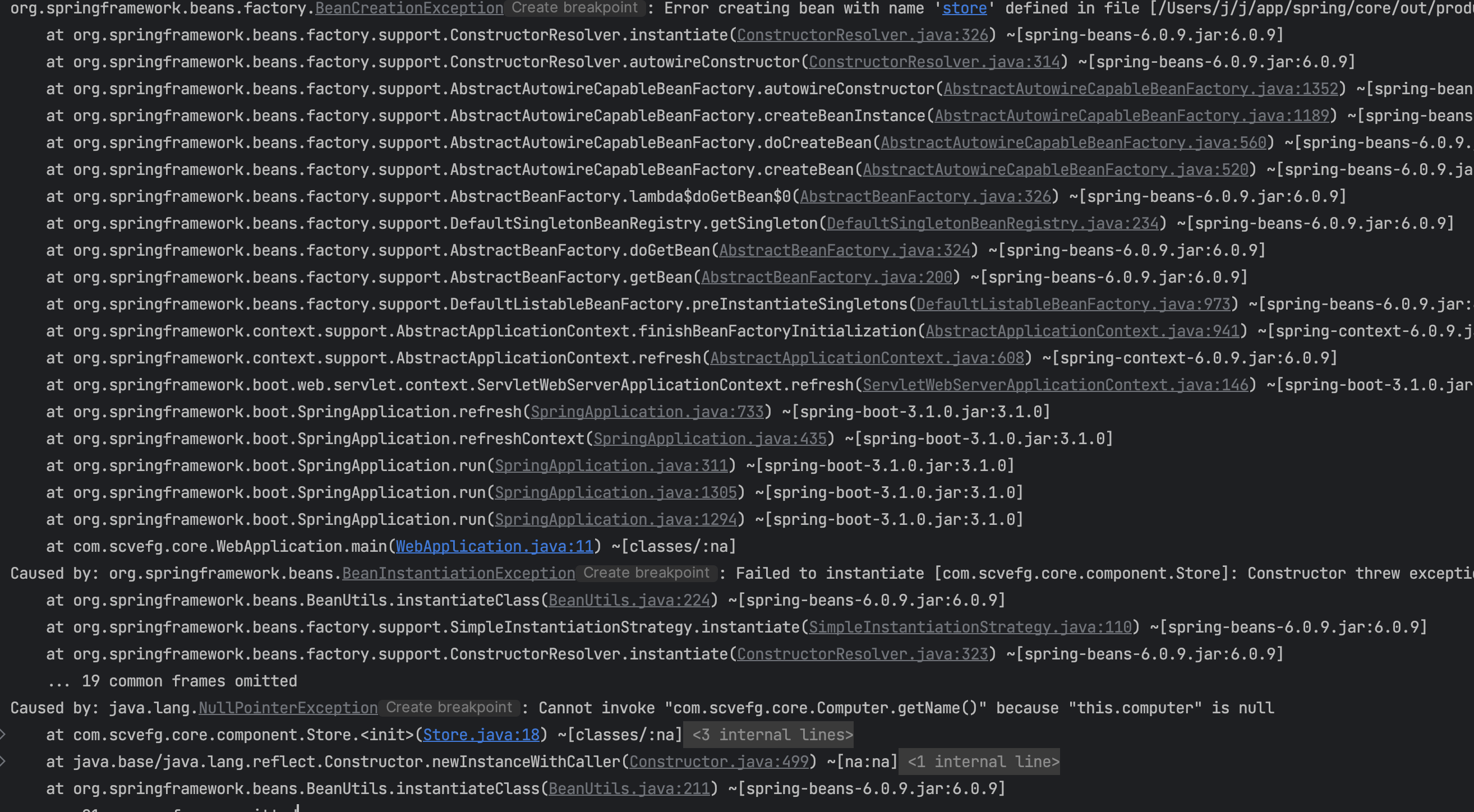
하나의 객체만 받는 생성자에 @Autowired를 붙이면 어떻게 될까?
너무 당연하게도 에러가 발생한다. 주입이 제대로 되지 않았는데 메서드를 호출했기 때문에 NPE 예외가 발생한다.
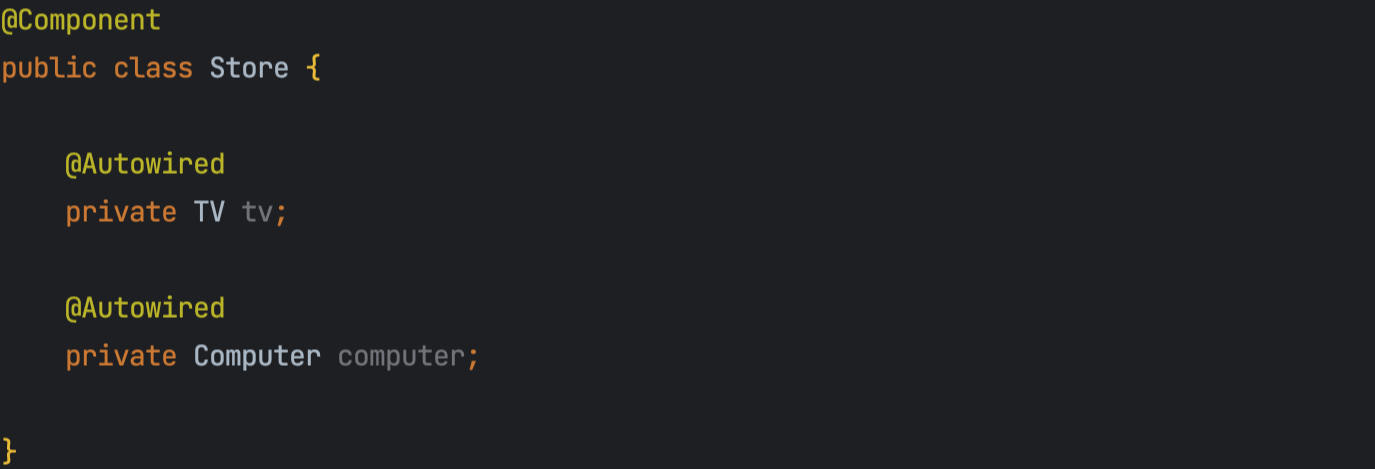
필드 주입
생성자 주입을 제외한 나머지 필드는 권장되지 않기 때문에 가볍게 보면 될 것 같다. 필드 주입은 이름 그대로 필드에 @Autowired를 사용하여 주입을 한다. 주입을 기대하는 필드에서 final키워드를 사용할 수 없다는 특징이 있다. final을 사용하게 되면 생성자에서 초기화를 하거나 필드를 작성할 때 바로 값을 입력해줘야 하기 때문인데, 생성자 주입이 아니기에 생성자에서 초기화는 하지 않을 것이고, 주입 자체를 필드로 받기 때문에 필드를 바로 초기화할 수 없지 않을까 생각이 든다.
출력이 잘 되는 걸 볼 수 있다.
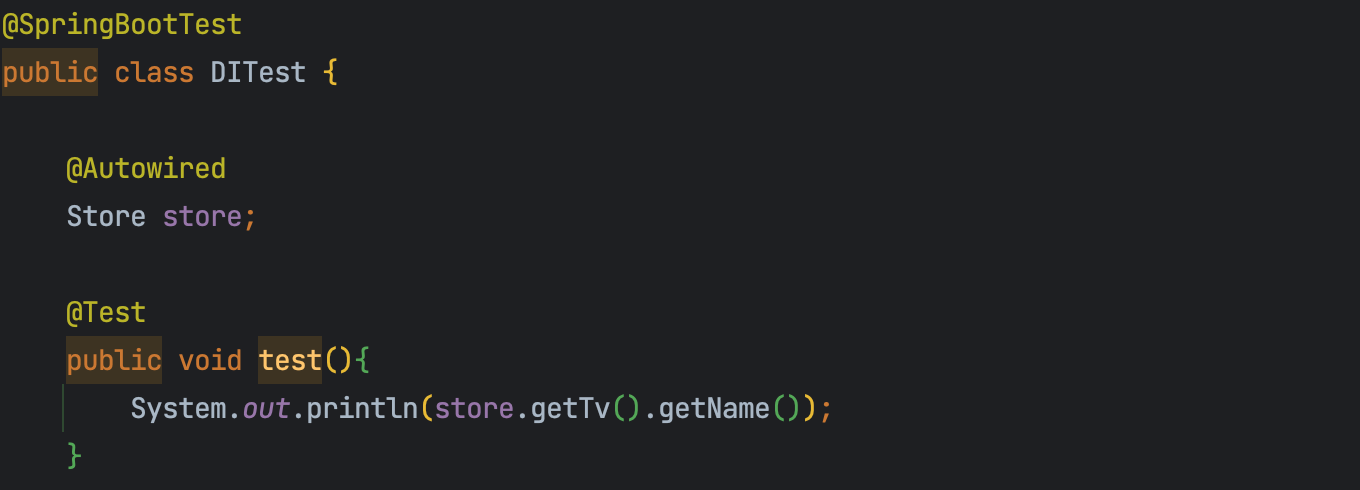
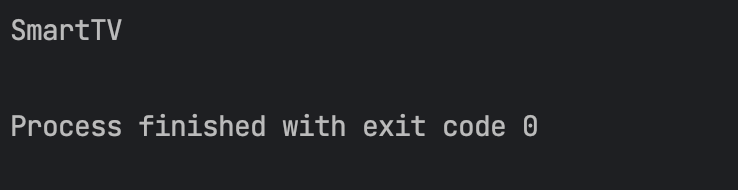
setter 주입
자바빈 프로퍼티에 따라 setXXX처럼 set으로 시작되는 메서드에 @Autowired를 추가하면 의존성을 주입할 수 있다. 생성자 주입과의 큰 차이점이라고 한다면, 생성자 주입은 Bean 객체가 생성이 될 때 한 번만 주입을 하고 그 이후에는 주입하지 않는다. 반면에, setter 주입은 계속해서 호출이 될 수도 있는 구조이기도 하고 생성자 함수가 호출되고 난 후에 주입이 된다는 점이다.

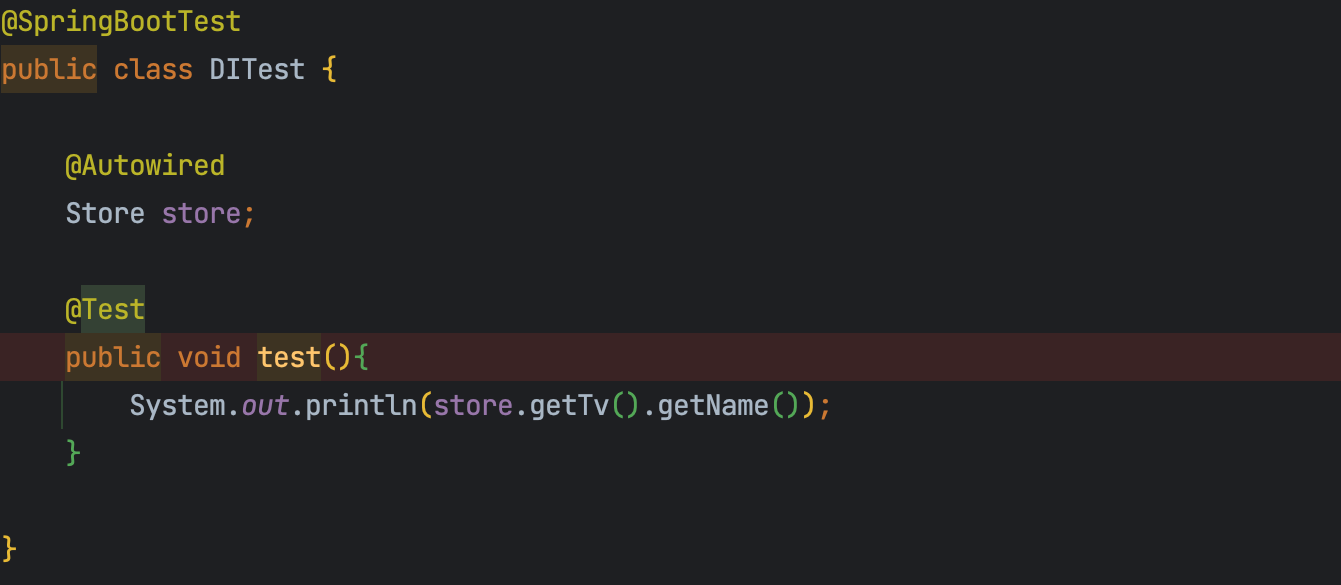


잘 출력되는 걸 볼 수 있다.
Spring에서는 데이터의 불변성을 고려하여 생성자 주입을 사용하길 권장하고 있는데, setter 주입을 사용하는 경우에는 계속해서 public으로 열어둬야 하는데 누군가에 의해 값이 수정될 수 있기 때문에 권장하지 않는다. 필드 주입은 DI가 없으면 아무것도 할 수 없고, 테스트 코드를 작성할 때도 쉽지 않다.
특히나 순수 자바 코드로는 테스트 코드를 작성하기가 힘들기 때문에 마찬가지로 권장하지 않는다. 생성자 주입의 경우 순수 자바로도 테스트 코드를 작성할 수 있다는 장점이 있기에 그냥 생성자 주입을 쓰면 되겠구나 하면 된다.
주입 시기 비교
필드 주입은 생성자 함수가 호출되기 전에 주입이 된다. 생성자 주입은 필드에 실제 값이 있는 경우 값이 할당되고 나서 주입이 된다. Setter 주입은 생성자 함수가 호출되고 나서 주입이 된다.
ComponentScan
@ComponentScan을 사용하여, @Component 애너테이션이 설정된 클래스들을 찾아서 Bean으로 등록할 수 있다. basePackage라는 설정을 할 수 있는데, 상위 디렉토리를 설정하면 그 하위에 있는 디렉토리까지 모두 스캔해준다. 그렇기 때문에 관례상 Application class에 놔두는 경우가 많다.
@SpringBootApplication이 내부적으로 @ComponentScan을 가지고 있기 때문에 Application을 실행할 때 등록된 모든 Component를 스캔하고 등록해주는 것이다. 알아 두면 좋은 옵션으로는 includeFilters와 excludeFilters 두 가지의 옵션이 있으며, ComponentScan에서 제외하고 싶은 경우 설정할 수 있다.
Life Cycle Callback
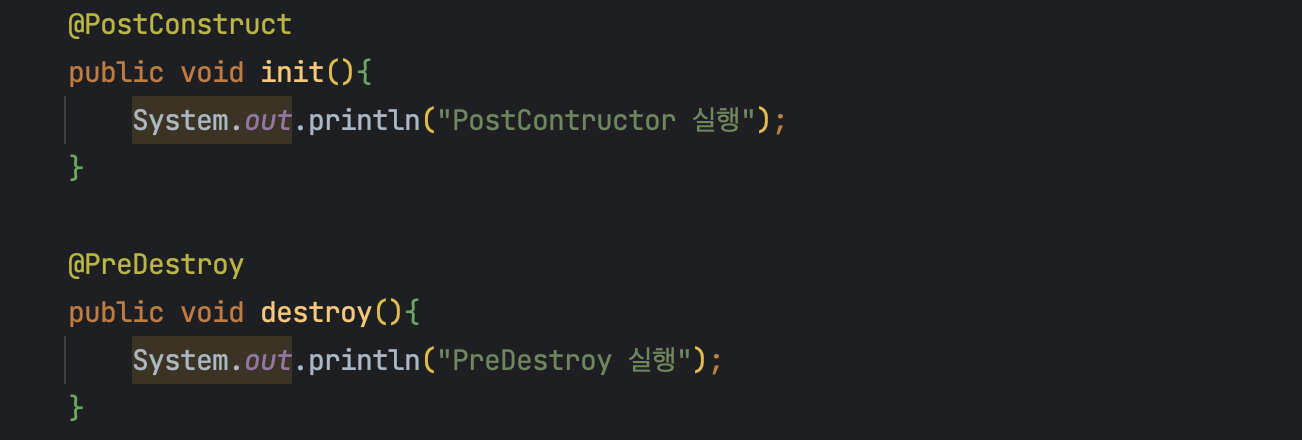
@PostConstruct를 일반 메서드 단계에 적용시키면, Bean이 생성되고 나서 생성자 함수가 호출되고 나서 바로 실행을 하게 해주고, @PreDestroy를 일반 메서드 단계에 적용시키면, Bean이 소멸되기 전에 해당 메서드를 실행을 하게 해준다.

Scope
스프링에서 지원하는 스코프들은 아래와 같다.
일반 스코프
싱글톤
기본 스코프, 스프링 컨테이너의 시작과 종료까지 유지되는 가장 넓은 범위의 스코프이다. 즉, @PostContructor와 @PreDestory 모두 실행된다.
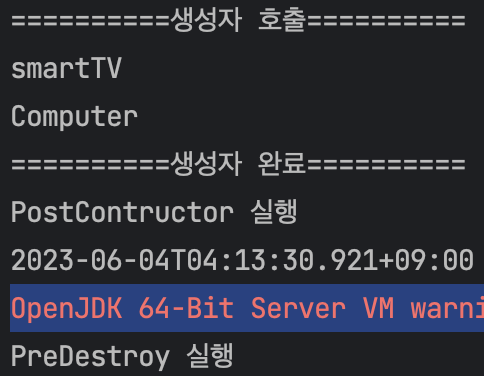
프로토타입
스프링 컨테이너는 프로토타입 빈의 생성과 의존관계 주입까지만 관여하고 더는 관리하지 않는 매우 짧은 범위의 스코프이다. 즉, @PreDestory는 실행되지 않는다. 만약 싱글톤 Bean이 프로토타입 Bean에 의존하는 경우 주입 시점에 프로토타입이 생성되는 거지 사용할 때마다 생성이 되는 게 아니라는 것 주의하자.

웹 관련 스코프
request
웹 요청이 들어오고 나갈 때까지 유지되는 스코프이다.
session
웹 세션이 생성되고 종료될 때까지 유지되는 스코프이다.
application
웹의 서블릿 컨텍스트와 같은 범위로 유지되는 스코프이다.
웹 관련 스코프를 @Controller 계층에서 의존하여 사용하는 경우에는 에러가 발생할 수 있다. 그 이유는, Controller는 일반적으로 싱글톤 객체로 관리가 되는데 웹 관련 스코프를 메서드 내부에서 사용하려고 하면, 당연히 웹 요청이 있기 전까지는 Null로 유지되는 객체이기 때문에 사용을 할 수가 없게 되는 것이다.
이렇게 생성 시기가 다른 Bean들이 가지고 있는 문제점들을 해결하기 위해서는 ObjectProvider를 사용하거나 Proxy객체를 만들어서 위임하고 싱글톤처럼 애플리케이션이 생성될 때 Bean이 생성되게 한 후 실제로 요청이 들어올 때 실제 Bean을 호출하는 방식을 사용할 수 있다.
결론
- @Bean은 메서드 이름으로, @Component는 클래스 이름으로 Bean을 생성한다.
- 같은 타입을 반환하는 Bean을 @Bean 여러 개를 사용해서 만들 수 있다. 다만, 이름을 꼭 지정해줘야 한다. 그래야 주입할 때 동일한 타입 중 @Qualifier에 해당하는 이름으로 주입을 해준다.
- 생성자가 두 개 이상인 경우 꼭 주입 받으려는 쪽에 @Autowired를 붙여줘야 된다.A라는 객체가 B라는 객체에 의존하는 경우 B의 Bean 인스턴스가 먼저 생성이 되고 나서, A가 생성이 된다.
- 생성자 주입을 사용해라.
- 애플리케이션 실행 - Bean 생성 - 생성자 함수 호출 - @PostConstruct 실행 - 비즈니스 로직 실행 - @Predestroy 실행 - 애플리케이션 종료
- Scope는 웬만하면 기본 기능을 사용하자. 건드리면 더 복잡해질 수도 있음
잘못된 정보는 지적해주시면 감사하겠습니다.
