Introduction
일반적으로 파드는 시작되면 지속적으로 실행되는 것을 기대한다.
(ex. 웹 애플리케이션)
하지만 몇분, 몇 시간 동안 또는 몇 번만 실행 되도록 하고 종료되었으면 좋겠는 그런 작업들이 있다.
(ex. 배치 작업, 데이터 베이스 백업 등)
이를 가능케 하는 방법이 바로 Job과 Cron Job이다.
1. 잡(JOB)
JOB이란 하나 이상의 파드를 지정하고, 지정된 수의 파드가 성공적으로 종료될 때까지 계속해서 파드의 실행을 재시도하는 배포법이다.
❗이해 하기 전 주의!
하나 이상의 파드 == 한 번 이상의 동일 작업
서로 다른 컨테이너 서비스를 운영하는 파드가 아님을 주의한다. (동일 작업이다.)
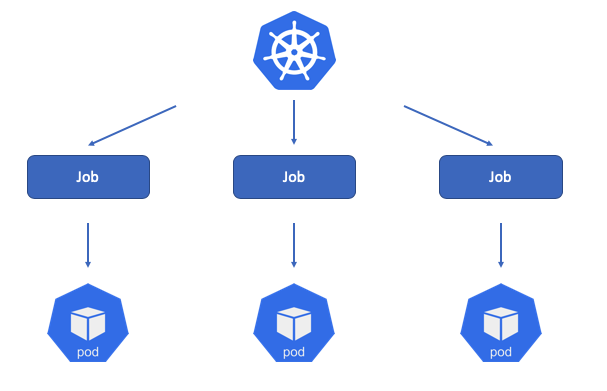
이러한 Job은 일회성 또는 정기적인 작업을 실행할 때 사용한다.
ex. (배치 작업, 일회성 작업)
Job이 성공적으로 작업을 완료한 경우에는 해당 파드는 삭제된다.
간단한 배치 작업의 예를 보자.
배치 작업의 예
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world-job
spec:
template:
spec:
containers:
- name: hello-world
image: busybox
command: ["echo", "Hello World"]
restartPolicy: Never
backoffLimit: 3각 파라미터의 의미
- metadata.name
Job의 이름을 지정.
- spec.template.spec.containers
파드가 실행할 컨테이너를 설정한다.
여기서는 busybox 이미지를 사용하여 "Hello World"를 출력하도록 함.
- (If End) restartPolicy
"Job에서 파드 내 컨테이너가 수행이 완료(종료)된 경우, 어떻게 할 것인가?"를 결정
즉, 이 속성은 파드 수준에서 설정되며, 해당 JOB에 대해서 포함된 파드 내 컨테이너가 종료되었을 경우 어떻게 할 것인지를 결정한다.
OnFailure: 컨테이너가 실패한 경우 다시 시작을 시도한다.Never: 컨테이너가 종료되면 완전히 종료된다.(기본값)
주의 사항
🚨 restartPolicy는 Always로 설정할 수 없다.
이는 Job의 목적과 Always 재시작 정책이 서로 충돌되기 때문이다.
Job은 일회성 작업의 실행 및 완료를 보장하는 반면, restartPolicy: Always는 지속적으로 실행되도록 하기에 Job의 실행 목적에 부합하지 않는다.
- backoffLimit
"Job리소스 자체에 대해서, Job이 실패한 경우 얼만큼 반복할 것인가?"를 결정
즉, 이 속성은 잡 수준에서 설정되며, 잡이 생성하는 모든 파드에 적용된다.
따라서, 잡이 생성한 파드 중 하나가 실패하면(잡이 실패하면), 쿠버네티스는 backoffLimit에 지정된 횟수만큼 잡을 재시도한다.
⭐ 기본적으로
6이 설정되어 있다.
현재는3으로 최대3번까지 재시도할 수 있다.
restartPolicy와 backoffLimit 모두 지수 백오프 (exponential back-off) 지연 시간을 가진다.
🧐지수 백오프 지연시간이란?
초기에는 짧은 시간 간격 (예: 10초, 20초, 40초 등)으로 재시작을 시도하지만, 재시작이 계속 실패하면 이 시간 간격이 점차 늘어난다. 만약 프로세스가 10분 동안 정상적으로 실행되면, 이 지연 시간은 초기화된다.
예시
1. 배포
다음과 같은 JOB을 apply를 통해 배포해 보자.
1~9의 숫자를 쉘에서 출력하는 스크립트가 작성되어 있다.
apiVersion: batch/v1
kind: Job
metadata:
name: test-job
spec:
template:
metadata:
name: test-job
spec:
containers:
- name: test
image: alpine:latest
command:
- "bin/sh"
- "-c"
- "for i in 1 2 3 4 5 6 7 8 9 ; do echo $i ; done"
restartPolicy: Neverkubectl apply -f [filename].yaml
2. Job 상태 확인
배포가 완료된 Job의 상태를 확인해보자.
kubectl get job
Job은 설정한 성공횟수(COMPLETIONS)에 도달할때까지 실행된다. 현재 디폴트로 1이 설정되어 있고, 작업이 성공적으로 끝나면 COMPLETIONS이 증가한다.
만약 작업이 실패로 끝나면 설정한 backoffLimit정책에 따라 실패한 작업을 재실행한다.
현재 1/1로 Job이 성공적으로 수행되었다는 것을 확인할 수 있다.
추가적으로 총 Job이 실행되기까지 걸리는 시간은 4초이고, 생성된 지 29초가 흘렀다는 것을 알 수 있다.
3. Pod 상태 확인
이제 파드의 상태를 확인해보자.
kubectl get podJob이 성공적으로 수행을 마쳤으므로, Job에의해 생성된 파드가 더 이상 동작하지 않는 "완료" 상태로 진입한 것을 확인할 수 있다.

로그를 출력해보면, 1~9까지의 로그를 확인할 수 있다.
kubectl logs <파드 이름>잡에 의해서 생성되고, 완료된 파드의 상세 정보를 descirbe해 보면 다음과 같다.
먼저 파드의 상태가 완료되었다는 것을 확인할 수 있다.
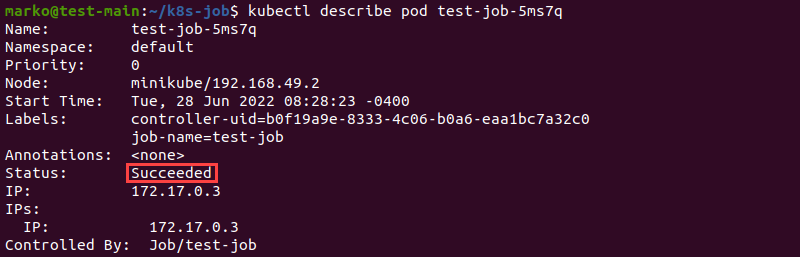
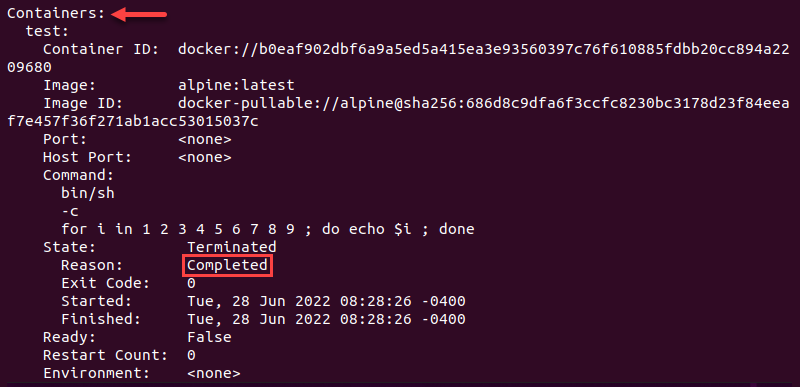
이후 파드 내 컨테이너 또한 "종료"되었고, 종료 사유는 완료라는 것을 확인할 수 있다.
이러한 컨테이너 종료의 이후 방향은 restartPolicy에 의해서 결정된다.
Job의 관리
job의 관리는 쿠버네티스 controller 중 하나인 job controller가 관리한다.

kubectl describe job으로 상세내용을 확인하면 job-controller이 관리하는 것을 알 수 있다.
생성된 파드는 언제 사라질까?

Job에 의해 생성된 Pod는 Completed상태로 남아 기본적으로 삭제 되지 않는다.
왜 삭제되지 않을까?
이는 완료된 Pod의 로그를 확인하여 오류, 경고 또는 기타 진단 출력을 확인할 수 있도록 하기 위함이다.
그럼 삭제하는 방법은?
-
Job 삭제: Job을 삭제하면 해당 Job이 생성한 모든 Pod도 함께 삭제된다.
-
TTL-after-finished 컨트롤러 사용: 이 컨트롤러는 완료된 Job 객체의 수명을 제한하는 TTL (time to live)를 사용하여 Job를 삭제하며 Pods를 삭제할 수 있다.
-
kube-cleanup-operator 사용 : 선택한 네임스페이스를 모니터링하고, 오류/재시작 없이 완료된 job/pod를 삭제한다.
Job의 시간 제한
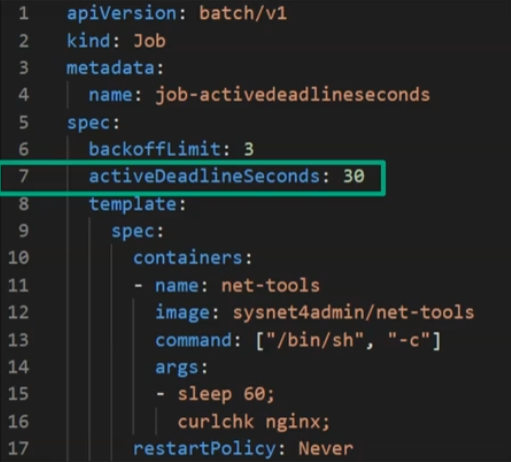
Job이 무한정 실행되는 것을 막을 수 있는 방법은 없을까?
spec의 activeDeadlineSeconds를 추가하여 Job의 실행에 대해서 시간을 제한할 수 있다.
apiVersion: batch/v1
kind: Job
metadata:
name: test-job
spec:
completions: 10
activeDeadlineSeconds: 10
template:
metadata:
name: test-job
spec:
containers:
- name: test
image: alpine:latest
command:
- "bin/sh"
- "-c"
- "for i in 1 2 3 4 5 6 7 8 9 ; do echo $i ; done"
restartPolicy: Never위와 같이 activeDeadlineSeconds 값을 10으로 설정하고
Job의 상황을 --watch 명령어를 통해서 실시간으로 확인해보자.
10초까지만 실행이 되고 멈춘 것을 확인할 수 있다.

이제 pods를 확인해보자.
분명 completions 의 값이 10인데, 3개까지만 파드가 생성된 것을 확인할 수 있다.

Job의 상세 정보를 확인해보면?
kubectl describe job [job-name]
다음과 같이 데드라인값인 10초에 도착하여 종료된 것을 확인할 수 있다.
activeDeadlineSeconds 와 ttlSecondsAfterFinished의 차이
❌ ❌ ❌ ❌
위쪽의 생성된 파드는 언제 사라질까에서 다뤘던, TTL-after-finished 컨트롤러ttlSecondsAfterFinished와 JOB의 실행 시간을 제한하는activeDeadlineSeconds는 차이가 있다.
activeDeadlineSeconds
activeDeadlineSeconds는 단지 JOB의 동작시간을 제한하는 명령어이다.
💡 즉, 동작시간이 끝난 뒤, JOB을 포함하여 완료된 POD가 삭제되지 않는다.
(단, 실행 중이던 POD는 Terminating 되어 삭제된다.)
JOB 및 완료된 파드(있는 경우)가 여전히 남아있음.

ttlSecondsAfterFinished
반면 ttlSecondsAfterFinished JOB이 끝난 다음에 TTL 시간 이후, JOB을 삭제하는 명령어이다.
🔥 따라서 JOB을 포함하여 완료된 POD가 삭제된다.
(실행 중이던 POD 또한 Terminating 되어 삭제된다.)
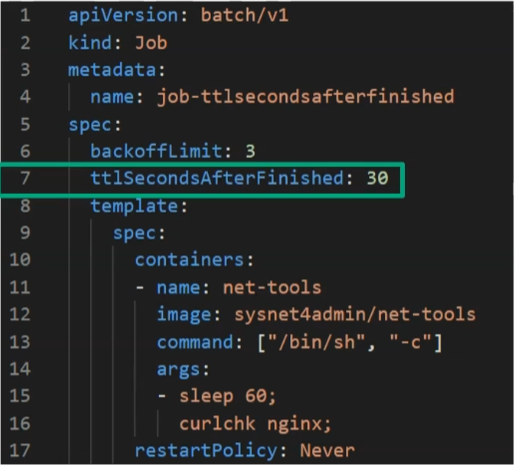
30초 뒤에 종료되는 모습
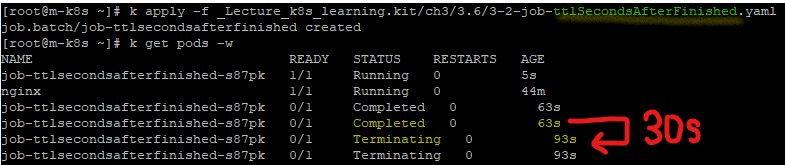
JOB 및 파드가 전부 삭제됨

병렬 Job
parallelism파라미터를 통해서 잡이 동시에 실행할 수 있는 파드의 수를 지정할 수 있다.
기존 completions 횟수 만큼 완료할 때까지 파드를 반복적으로 실행시키는 건 동일하나, 이를 parallelism를 통해 병렬적으로 파드를 실행하는 것이다.
-
completions: 3 → 파드가 3번 이상 정상 종료 될 경우 잡을 성공(완료) 처리한다.
-
parallelism: 3 → 한번에 3개의 파드를 실행한다.
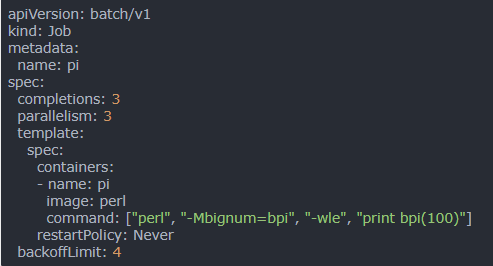
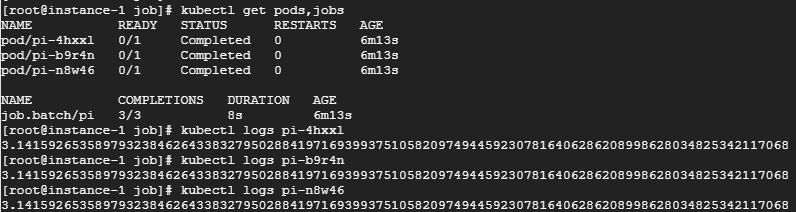
파드 3개가 한번에 생성되고 완료된 것을 확인할 수 있다.
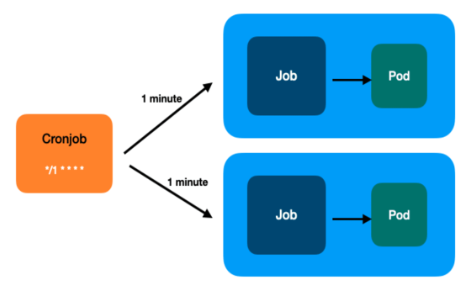
2. 크론 잡(Cron Job)
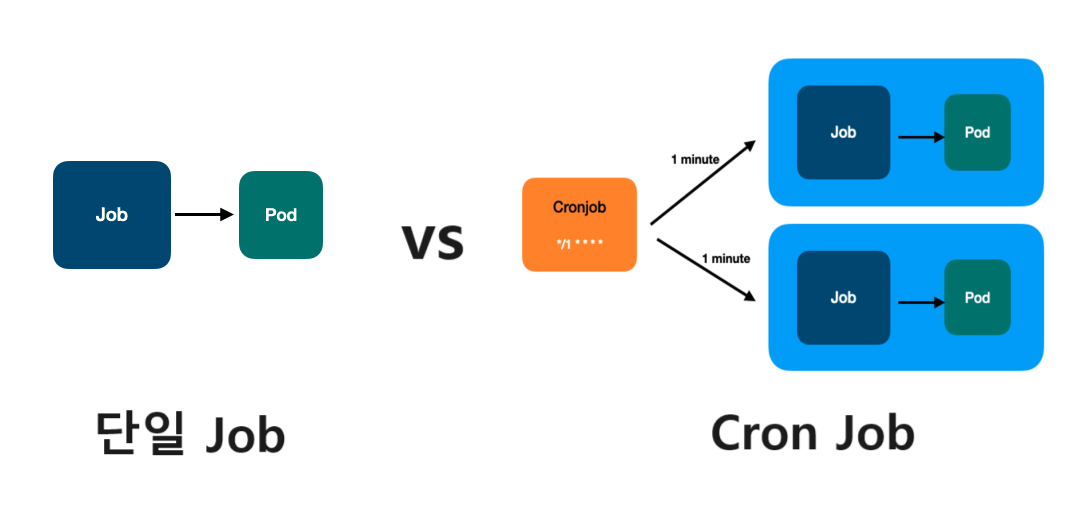
기존의 Job 리소스는 생성될 때, 즉시 파드를 실행하게 된다.
하지만 시간 단위로 반복되어야 하는 배치 작업이나, 정기적으로 반복되어야 하는 작업이 필요한 경우 Cron Job을 사용한다.
여기서 Cron Job이 내부적으로 Job을 생성하는 것을 유의하자!
예시
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: test-cron-job
spec:
schedule: "*/1 * * * *" # 매 1분마다 실행
jobTemplate:
metadata:
name: test-job
spec:
template:
spec:
containers:
- name: test
image: alpine:latest
command:
- "bin/sh"
- "-c"
- "for i in 1 2 3 4 5 6 7 8 9 ; do echo $i ; done"
restartPolicy: Never기본 Job과 유사하나 kind가 CronJob으로 사용하고 schedule 부분이 추가된 것을 확인할 수 있다.
"*/1 * * * *" 는 매 1분마다 실행하는 것을 의미하는데, 이에 대해서는 아래와 같은 특정한 문법을 따른다.
크론 스케줄 문법

| 스케줄러 | 설명 | 크론 표현식 |
|---|---|---|
| @yearly | 매년 1월 1일 자정에 1번 실행 | 0 0 1 1 * |
| @monthly | 매월 1일 자정에 1번 실행 | 0 0 1 * * |
| @weekly | 매주 일요일 자정에 1번 실행 | 0 0 * * 0 |
| @daily | 매일 자정에 1번 실행 | 0 0 * * * |
| @hourly | 매시 정각에 1번 실행 | 0 * * * * |
일정한 간격으로 실행하고 싶다면?
중간에 슬래시(/)를 사용하는 경우, 크론 표현식에서 일정한 간격으로 작업을 실행할 수 있다.
/ 앞에 시작-종료 시간을 /뒤에 반복할 시간 간격을 넣어서 사용한다.
ex.) 1월1일 자정부터 AM 1시까지 6분간격으로 실행
➡️ 0/6 0-1 1 1 *
ex.) 매일 오전 5시 10분부터 50분까지 5분간격으로 실행
➡️ 10-50/5 5 * * *
ex.) 토요일 오전 5시 30분부터 6시까지 10분간격으로 실행
➡️ 30/10 5-6 * * 6
실행 확인
1. 크론잡 생성
kubectl apply -f [filename].yaml다음과 같이 크론잡을 생성하여 주자.

2. 크론잡 확인
--watch 명령어를 통해서 작업이 실행되는 과정을 실시간으로 확인해보도록 하자.
kubectl get cronjob --watch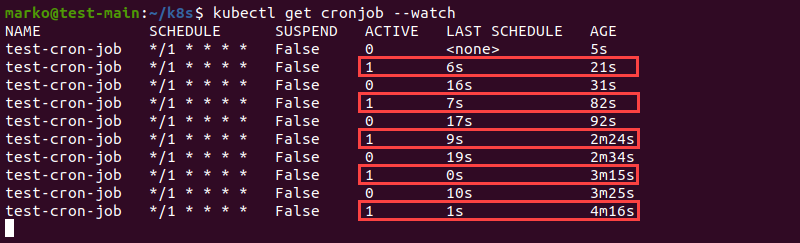
크론잡이 매 1분마다 껏다 켜졌다를 반복하며 Job을 생성하여 동작하는 것을 확인할 수 있다.
- SUSPEND : 크론잡이 정지되었는지 나타낸다.
- ACTIVE : 현재 실행중인 잡이 있는지를 나타낸다.
- LAST SCHEDULE : 마지막으로 잡을 실행한 후 어느정도 시간이 지났는지 나타낸다.
3. Cron Job 리소스 삭제
kubectl delete cronjobs 크론잡이름크론잡이 생성했던 잡과 파드까지 한꺼번에 삭제된다.
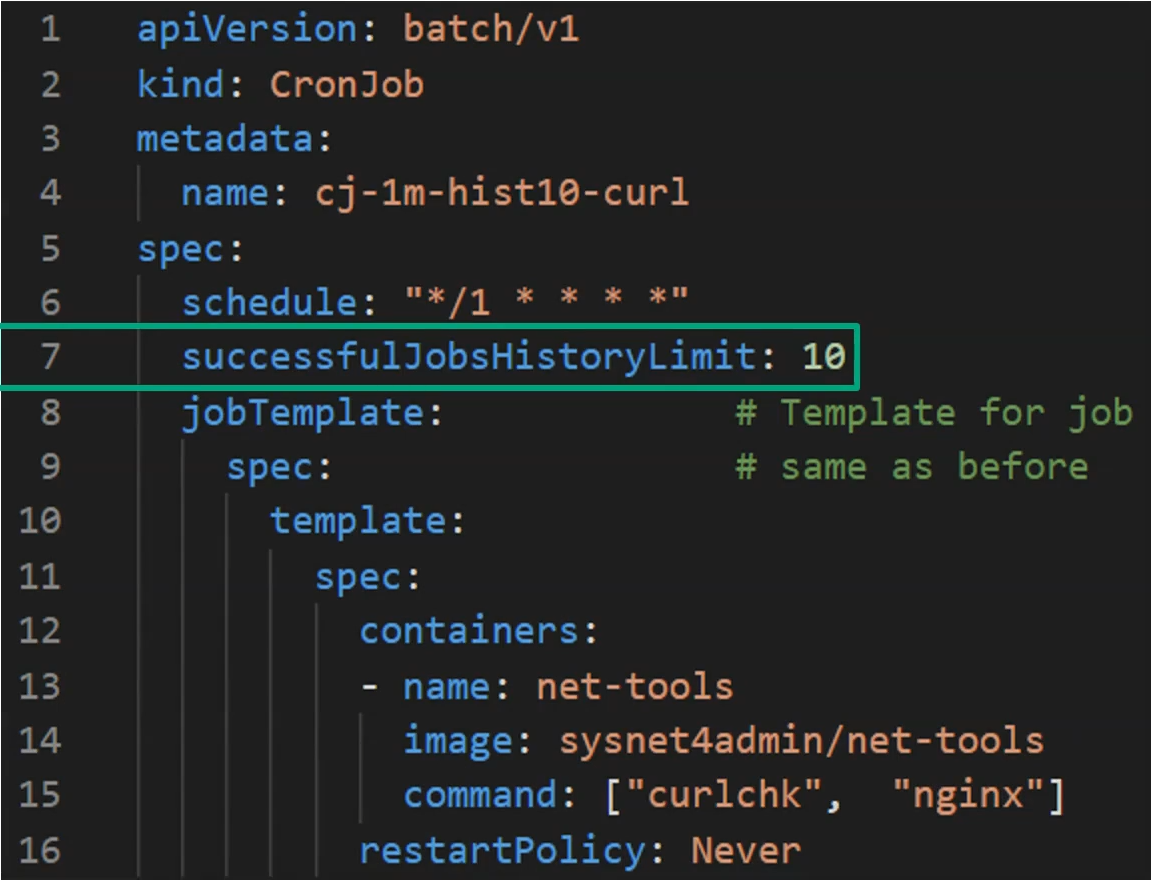
CronJob으로 저장되는 History수
kind: CronJob
metadata:
name: cj-1m-hist10-curl
spec:
schedule: "*/1 * * * *" # 1분마다 Job실행
jobTemplate: # Template for job
spec:
template:
spec:
containers:
- name: net-tools
image: sysnet4admin/net-tools
command: ["curlchk", "nginx"]
restartPolicy: Never
크론잡을 1분으로 설정해 놓으면 크론잡이 종료되기 전까지 1분마다 무한정 ( CronJob - Job 생성 - Pod 생성-실행 )이 반복되며 파드가 쌓여 나갈까?
그렇지 않다.
아무리 완료된 파드가 CPU 및 리소스를 먹지 않는다고 해도 이는 잠재적으로 구성된 파드의 상황에 따라서 메모리의 소모가 있을 수 있다.
따라서 이는 기본적으로 History가 맨 마지막 Job 3회로 고정되어있다.
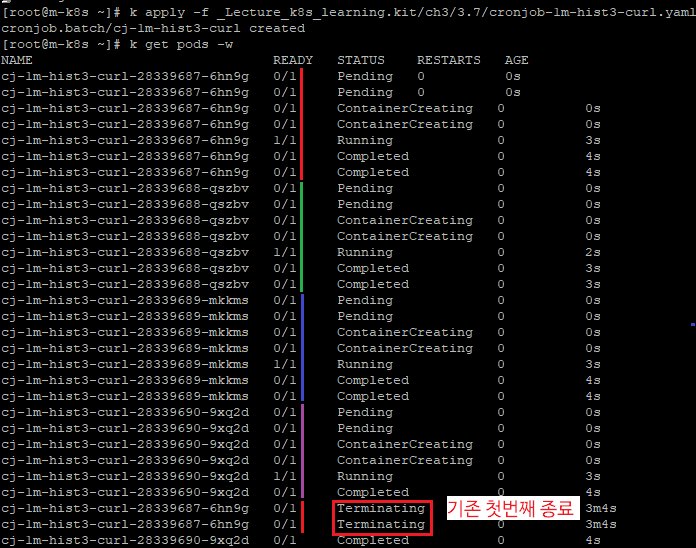
Histroy(Complted Pod)수 늘리기
successfulJobsHistoryLimit 파라미터를 추가하여 기본값 3으로 설정된 것을 10으로 변경해주면 된다.
참고자료
- phoenixnap
https://phoenixnap.com/kb/kubernetes-job - Job & cronJob
https://velog.io/@niyu/k8s-job-and-cronjob
