Introduction
kubernetes 환경의 Node에는 IP의 제한이나, 용량에 제한이 있으므로 더 이상 생성될 수 없는 파드는 Pending 상태에 빠지게 된다.
이를 해결하기 위한 방법이 Node의 수량 자체를 늘리는 것으로 CA(Cluster AutoScaling)라 한다.
이러한 CA는 AWS의 Auto Scaling을 통해서 수행되게 된다.

CA 동작 방식
-
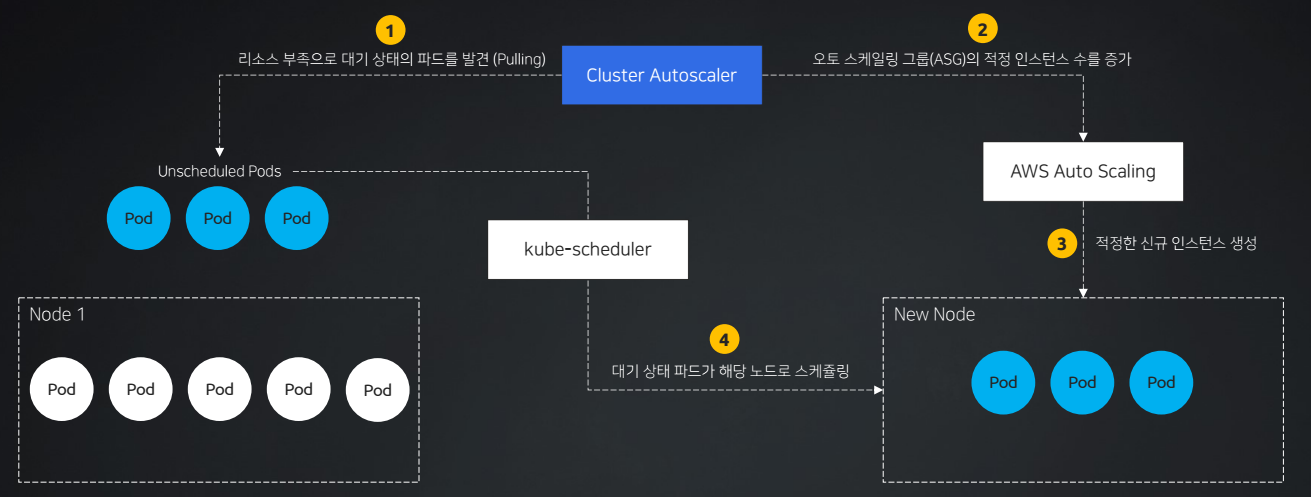
CA(Cluster AutoScaling)가 리소스 부족으로 대기상태로 빠진 파드를 발견한다. Pulling 방식
-
오토 스케일링 그룹(ASG)의 적정 인스턴스 수를 계산하여 증가하도록 전달한다.
-
오토 스케일링 그룹(ASG)은 신규 노드(인스턴스)를 생성한다.
-
kube-scheduler를 통해서 신규 노드로 Pending 상태의 파드들이 스케쥴링된다.
CA의 문제점
1. ASG과 EKS의 관리 주체가 다르다. (동기화 문제)
즉, ASG는 "EC2 인스턴스"를 조절하는 것이고, EKS는 EC2 인스턴스로 구성된 "노드"를 다루기에 관리 주체가 다른 문제가 발생한다.
그렇기에 동기화 문제가 발생할 수 있다. 즉, EKS에서 특정 노드를 삭제했지만 여전히 EC2 인스턴스 자체는 남아있는 상황..😲
2. ASG에 의존적이다.
ASG(Auto Scaling Group) 자체에 의존적이다.
EKS의 "노드"를 생성하는 것이지만, ASG의 "EC2 인스턴스 Auto Scaling"에 의존해야만 한다.
이렇다보니, 관리자 입장에서 ASG 그룹을 따로 관리해줘야 하는 관리 오버헤드 또한 증가한다.
3. 스케일링 속도가 느리다.

가장 큰 문제는 ASG의 스케일링되는 속도 자체가 느리다는 것이다. 🐌
현 IT 세상에서 대용량의 트래픽이 들어오고, 빠르게 고가용성을 확보해야하는 상황에서 "스케일링 속도"가 느리다는 것은 큰 단점으로 작용한다.
Karpenter

karpenter는 오픈소스 노드 생명 주기 관리 솔루션으로 굉장히 빠르게 리소스를 제공할 수 있다.
Why karpenter?
kubernetes 사용자 모임 오픈채팅톡방에서 NaverCloud에 CA의 프로비저닝이 10분넘게 걸린다는 소식을 접했다.
내가 진행하고 있는 프로젝트에서도 CA를 사용하고 있었고, 추가 노드 증설에서 느림을 경험하고 있었기에 karpenter는 상당히 매력적이였다.
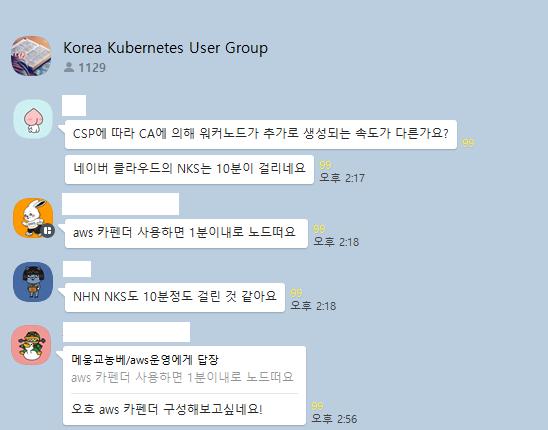
그리고 karpenter가 굉장히 빠르다는 것을 접하게 되었다.
Why fast? ✈️
1. Pub/Sub 방식으로 파악

karpenter에서 Pending 상태의 파드를 모니터링 하는 방식은 Pub/Sub 방식을 따른다.
앞서 CA의 Pulling 방식은 주기적으로 Pod의 상태정보를 가져오는 반면, Pub/Sub 방식은 변화가 생기면 즉시 상태를 파악할 수 있다.
2. Provisioner를 통해 노드를 생성 🛞
느리고 관리하기 불편한 ASG가 아닌 Custom Resource Definitions(CRD)로 정의된 Provisioner를 통해서 노드를 생성한다.
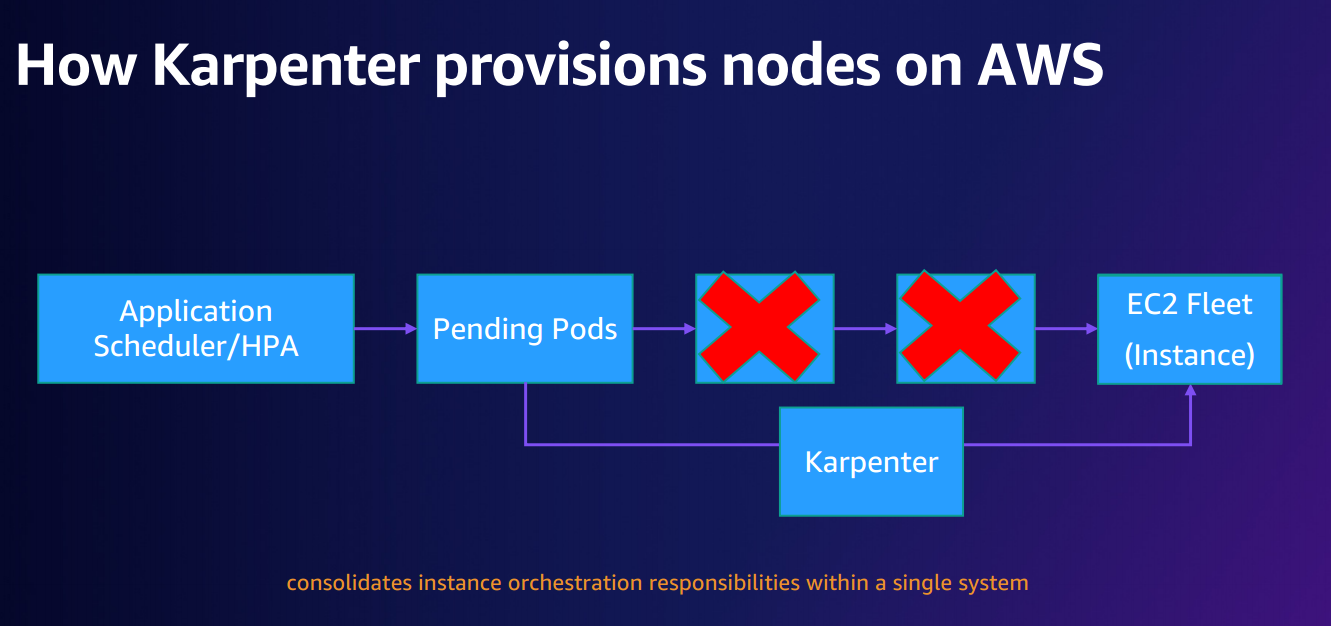
이 때, Provisioner는 AWS의 리소스인 EC2를 생성하기 위해서 EC2 fleet API를 사용하며 이를 통해 인스턴스를 빠르게 생성한다.
즉, 클러스터 확장 단계에서 ASG 플로우 대신에 fleet API를 사용하여 EC2를 요청하고 프로비저닝함에 있어, 노드가 조인되고 완료되는데 까지의 시간이 매우 빠르다.
Provisioner 예시
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: my-karpenter-provisioner
spec:
# 클러스터 내의 모든 미배치된 파드에 대해 실행
requirements:
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
labels:
department: engineering
# 생성될 노드의 제한 사항
limits:
resources:
cpu: "1000"
memory: 1000Gi
# 생성될 노드에 대한 기본 리소스 요구 사항
provider:
instanceProfile: KarpenterNodeInstanceProfile
subnetSelector:
environment: dev
securityGroupSelector:
karpenter.sh/discovery: dev-clusterKarpenter 동작 방식
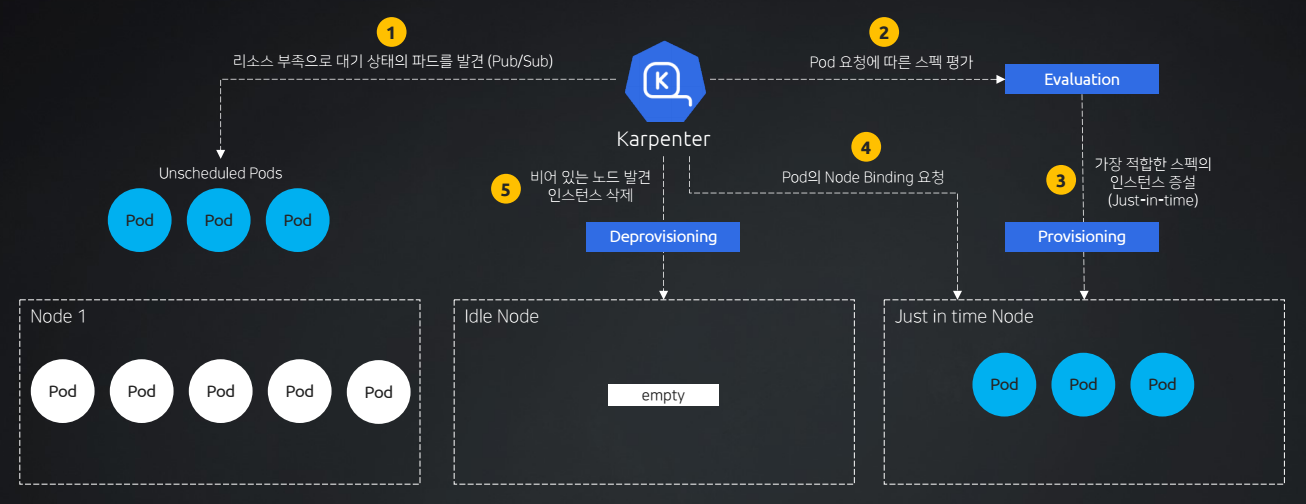
-
리소스 부족으로 대기 상태의 파드를 Pub/Sub 방식을 통해 파악한다.
-
Pod 요청에 따른 생성할 노드의 스펙을 평가(Evaluation)한다.
-
평가된 스펙에 따른 가장 적합한 스펙(Just-In-Time)의 인스턴스를 Provisioner가 생성한다.
특히, 적합한 인스턴스 유형들 중 가장 저렴한 인스턴스를 골라서 증설한다는 특징 또한 있다.💰
🪄 Provisioning & Provisioner
이처럼 kapenter가 직접 노드를 생성하는 작업을 Provisioning이라고 하는데, 이러한 작업은 Provisioner CRD를 통해 수행되며, 이 과정에서 EC2 fleet API를 사용한다.
- karpenter에서 직접 새로운 노드에 파드가 생성되도록 Node Binding을 요청한다.
즉,kube-scheduler를 통한 흐름을 거치지 않기에 빠르게 파드를 배치할 수 있다.
- 만약 파드가 배치되지 않고, 빈 노드가 생성되어 돌고 있다면 이러한 노드를 삭제하는
Deprovisioning작업 또한 수행할 수 있다.
CA 예제
CA는 기본적으로 ASG의 동작방식을 따라가므로, EKS 환경에서 "노드"와 "EC2"에서의 차이에서 발생하는 동기화 문제와 ASG의 느린 스케일링 속도가 문제가 되었다. 😲
ASG 확인 및 조정
ASG부터 살펴보도록 하자.
// 현재 ASG 정보 확인
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
// ASG 이름 변수 선언
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text); echo $ASG_NAME
// ASG MaxSize를 6으로 변경
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 3 \
--max-size 6 \
--desired-capacity 3다음과 같이 요구수량 3대, 현재 수량 및 최대 수량 또한 3대로 설정된 것을 확인할 수 있다.

이제 이러한 최대 수량을 6으로 변경해 보자.
최대 생성할 수 있는 최대 EC2 개수가 6으로 변경되었다.
// ASG 이름 변수 선언
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text); echo $ASG_NAME
// ASG MaxSize를 6으로 변경
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 3 \
--max-size 6 \
--desired-capacity 3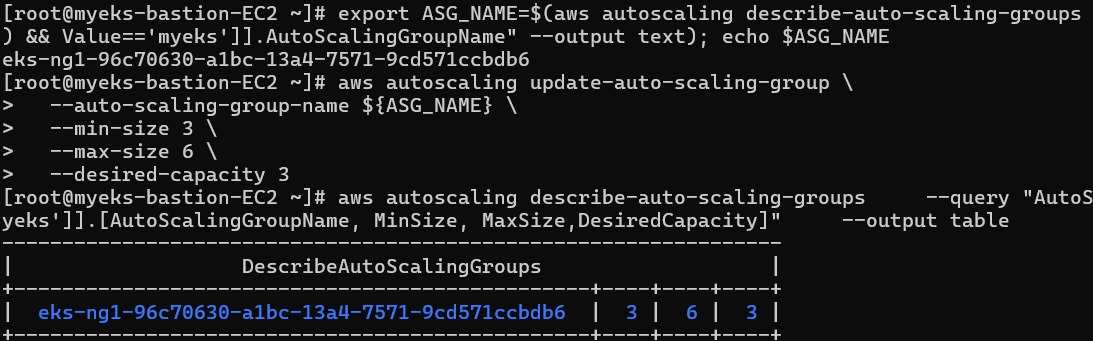
CA 설치 및 확인
// CA 설치 파일 다운로드 및 변수 치환
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
// CA 배포
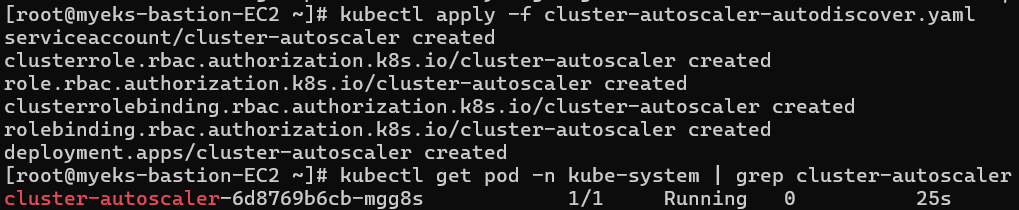
kubectl apply -f cluster-autoscaler-autodiscover.yaml
// CA 확인
kubectl get pod -n kube-system | grep cluster-autoscalerCA관련해서 다양한 kubernetes 리소스들이 생성된다.
CA 동작 확인
- 테스트용 자원 설치
// 테스트용 디플로이먼트 생성
cat <<EoF> nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
# ⚠️ 요구 리소스자체가 높은 편이다.
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EoF
// 테스트용 디플로이먼트 설치
kubectl apply -f nginx.yaml
// 테스트용 디플로이먼트 정보 확인
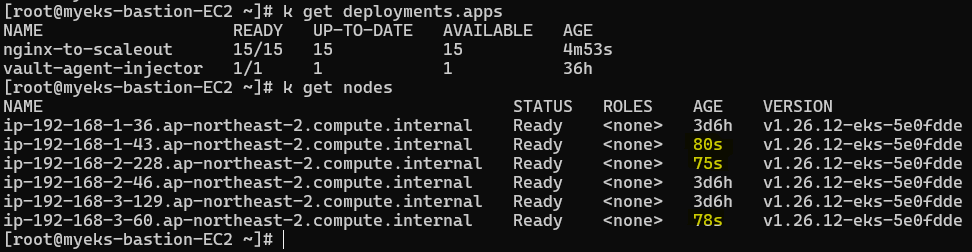
kubectl get deployment/nginx-to-scaleout다음과 같이 디플로이먼트로 파드 한대를 배포해주고, 이후 이러한 파드의 수량을 늘려서 실제로 CA가 동작하는 지를 테스트해 보자. 🧑🏻🔬

노드 scale-out 확인
과연 레플리카 개수를 조절하였을 때, Pending 되는 파드들을 CA가 감지하고, 새로운 워커 노드가 ASG를 통해서 생성될까?
즉, CA가 수행될까? 😮
// replica를 15로 조정 (scale-out 확인)
kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
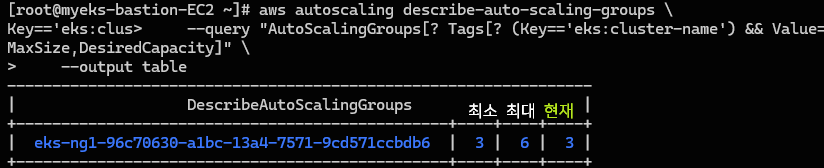
// 현재 ASG 정보 확인
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table현재 노드의 수량이 6개로 증가했다.🆙

부여가능 한 파드 자체의 IP는 널널하지만, 파드가 요구하는 최소 CPU, Memory의 값이 높아 t3.medium 인스턴스로 버티지 못하기에 새로운 EC2 노드가 생성된다.
파드가 15개로 증가함에 따라서, 3개의 노드가 추가로 생성된 것을 확인할 수 있다.
노드 scale-in 확인
반대로 이제 노드 개수가 감소되는 것을 확인해 보자.
// 테스트용 디플로이먼트 삭제 (scale-in 확인 - 10분 이상 소요)
kubectl delete -f nginx.yaml && date
// 현재 ASG 정보 확인
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table- 결과

실습 자원 삭제
// CA 삭제
kubectl delete -f cluster-autoscaler-autodiscover.yaml
Fiddlebops feels like a love letter to Incredibox. It captures the magic of the original while creating something exciting and fresh.