Introduction
배포만큼 중요한 것이 바로 운영 중인 애플리케이션의 성능을 모니터링하고 필요에 따라 자동으로 규모를 조정하는 것이다.
이번에는 이를 실현할 수 있는 도구인 Metrics-server와 (HPA)Horizontal Pod Autoscaler에대해서 알아보자.
Metrics-server
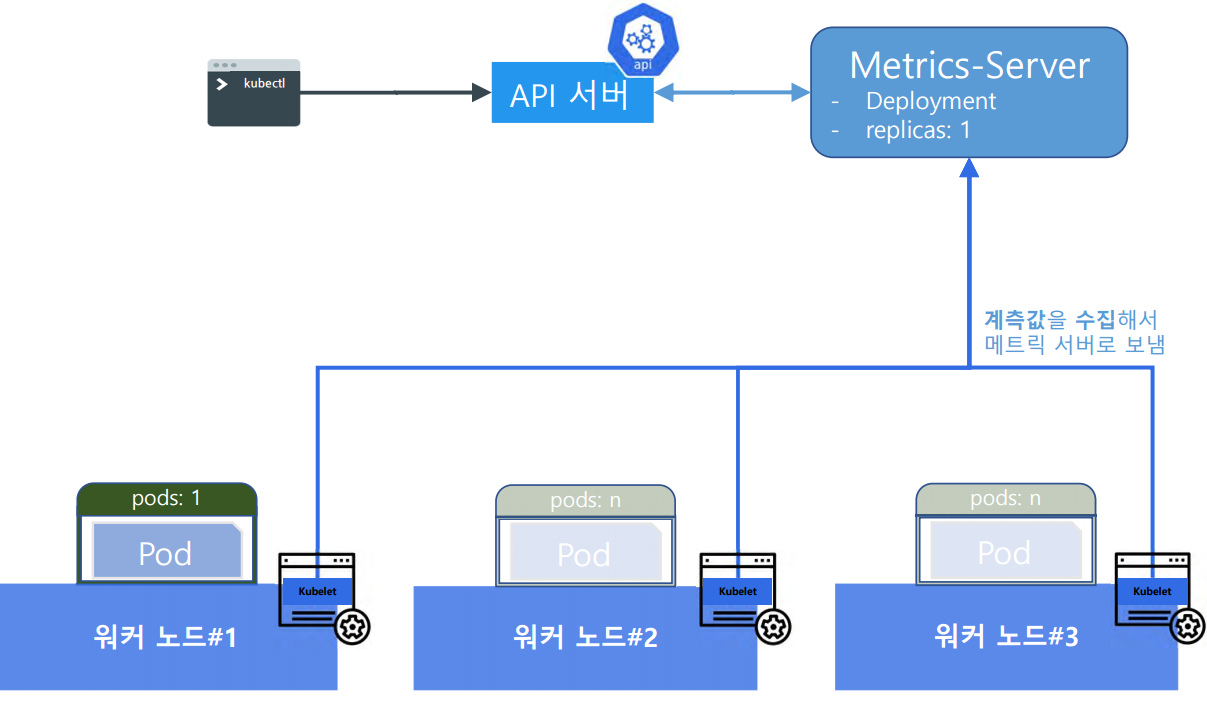
각 노드의 Kubelet은 실행 중인 파드(Pods)의 메트릭을 주기적으로 수집하고, Metrics Server에 저장한다.
Metrics Server는 이러한 데이터를 Kubernetes API 서버와 공유하는데, 사용자는 kubectl 명령을 통해서 이러한 Metris 정보에 접근할 수 있고, API 서버는 이 Metris 정보를 활용하여 클러스터 리소스 할당을 조정할 수 있다.
실습
metrics-server 설치
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
commonLabels:
k8s-app: metrics-server
resources:
- apiservice.yaml
- deployment-notls.yaml
- rbac.yaml
- service.yamlKubernetes 버전 1.14부터 kubectl 내에 kustomize 기능이 통합되어 kubectl apply -k를 사용하여 kustomize를 별도로 설치하지 않고도 kustomize의 기능을 사용할 수 있다.
# metrics-server 설치
kubectl apply -k .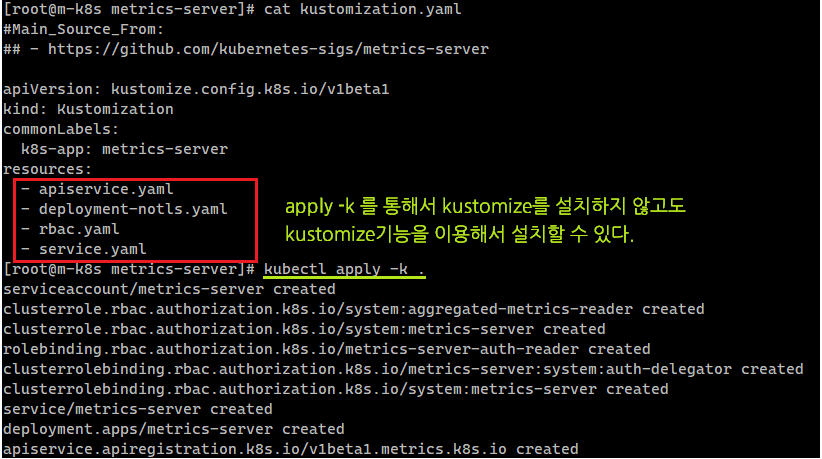
이러한 metrics-server는 kube-system 네임스페이스에 설치된다.
# metrics-server 확인
k get po -n kube-system | grep -i metrics
metrics-server 확인
metrics-server를 통해서 현재 파드 및 노드의 시스템 사용량을 확인할 수 있다.
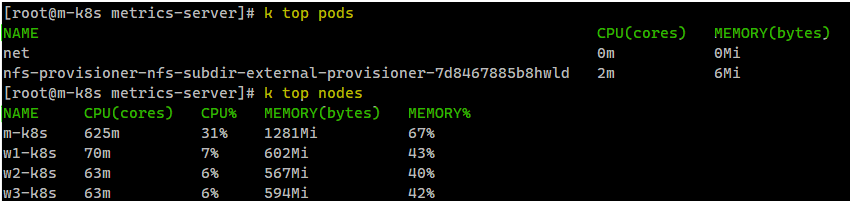
이제 이러한 metrics-server를 이용하여 파드에 부하가 발생하면 파드의 수를 늘리는 HPA Autoscaling을 진행해 보자.
HPA(Horizontal Pod Autoscaler)
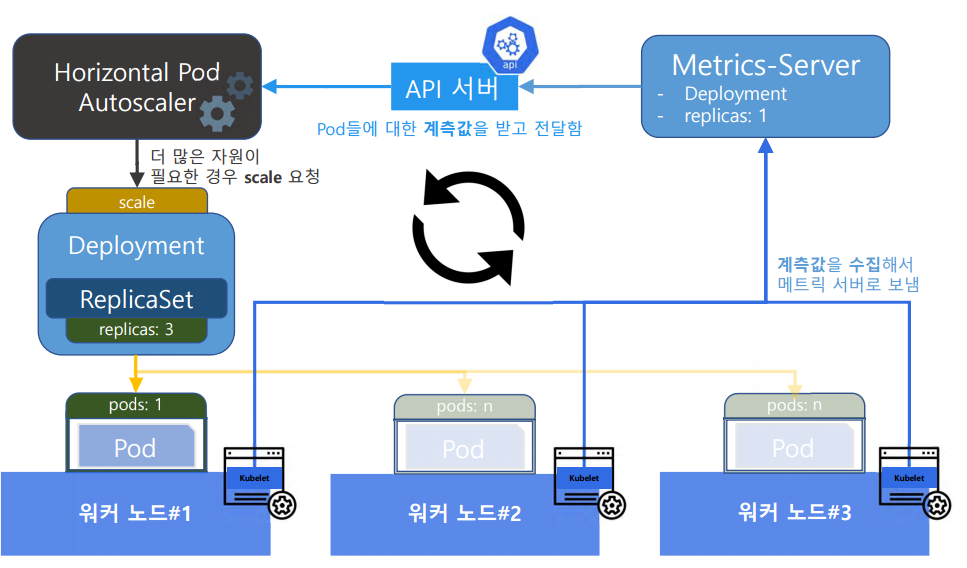
HPA의 동작과정은 아래와 같다.
- Kubelet은 각 노드의 파드 메트릭을 주기적으로 수집하여 Metrics Server에 보고한다.
- Metrics Server는 이 메트릭을 저장하고, Kubernetes API 서버에 제공한다.
- HPA는 API 서버로부터 메트릭을 조회하여, 설정된 목표 메트릭 값에 도달하기 위한 필요한 파드의 수를 결정한다.
3.1 만약 추가 파드가 필요하다면, HPA는 Deployment에 새로운 파드를 생성하라는 명령을 내리고, Deployment는 ReplicaSet을 통해 새로운 파드 인스턴스를 생성한다. - 부하가 줄어들면, HPA는 Deployment에 파드의 수를 줄이라는 명령을 내려 다시 파드의 수를 줄인다.
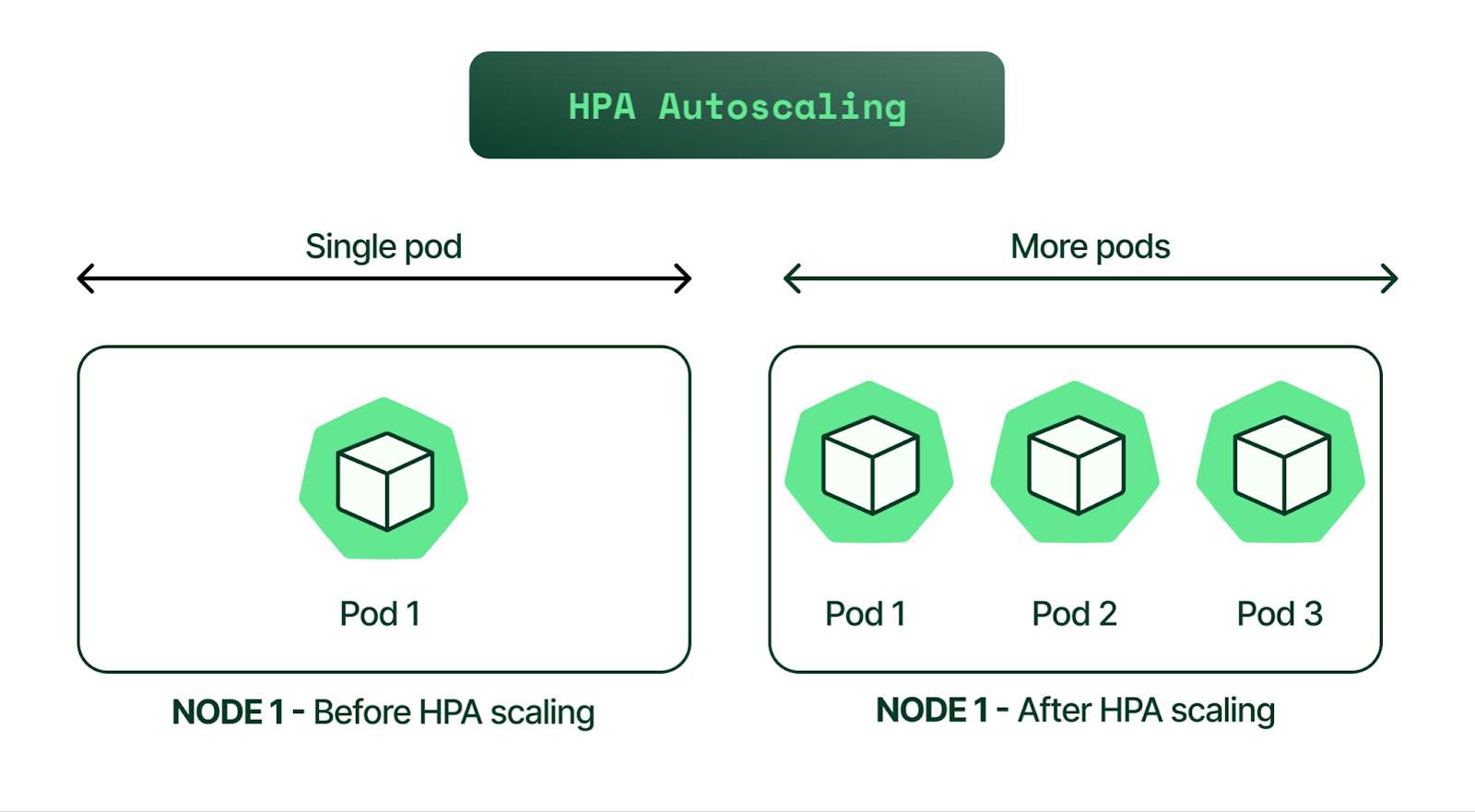
HPA(Horizontal Pod Autoscaler)는 부하가 발생하면 부하에 맞춰 scale-up 되는 것으로, 파드가 늘어나는 수평 확장이다.
실습
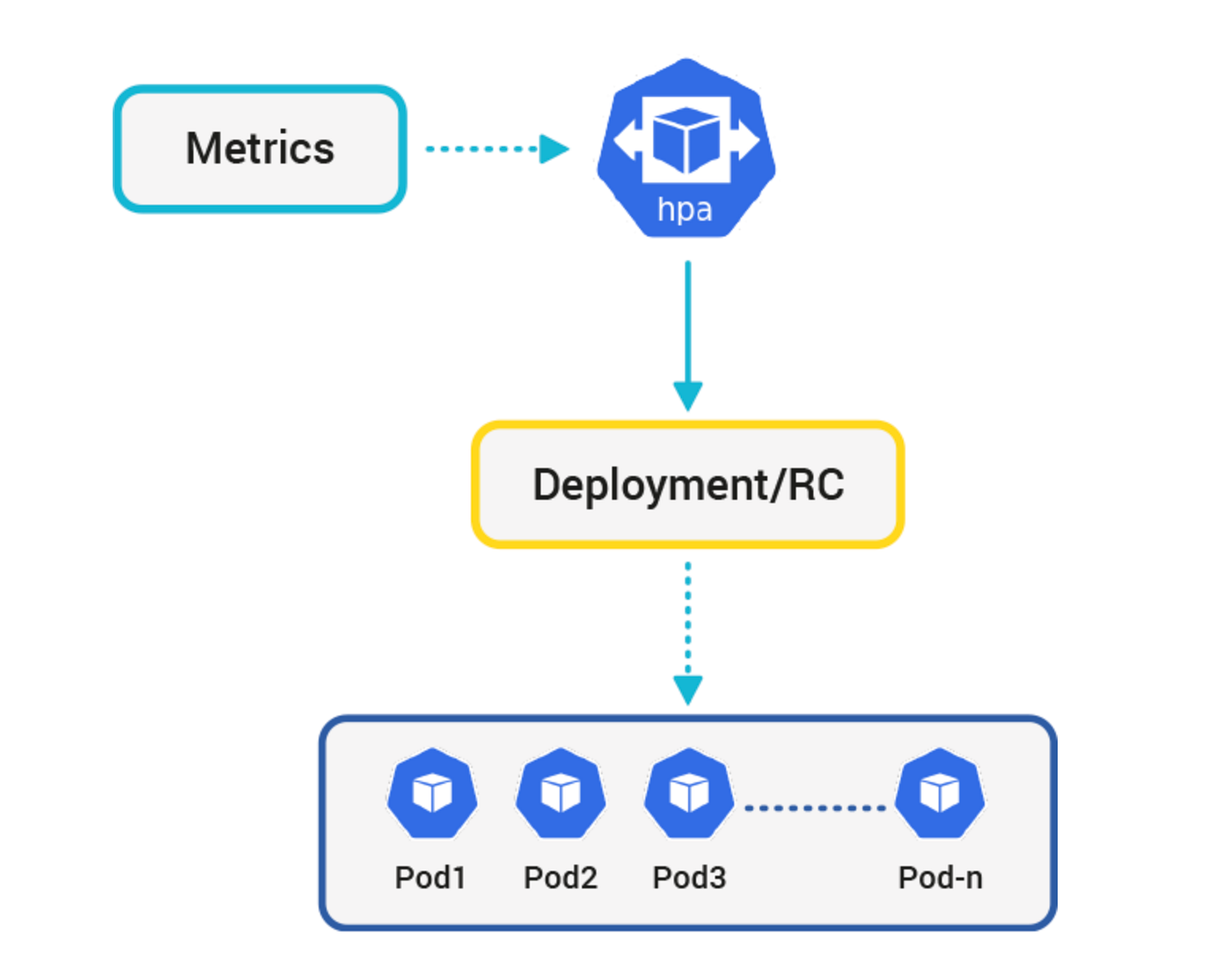
이전 Metrics-server와 연계하여 실습해 보자.
클러스터에서 실행 중인 Pod의 CPU 및 메모리 사용량을 Metrics-server를 통해 감시하고, 이 정보를 기반으로 Horizontal Pod Autoscaler (HPA)를 통해 Pod들의 개수를 동적으로 스케일할 것이다.
파드 배포
파드를 배포할 때 컨테이너에서 리소스에 대한 requests(이 정도 쓸 거야) 및 limits(최대 값)를 줘서 배포할 것이다.
이는 실무적으로는 거의 100% 사용하는 옵션이다.
컨테이너는 제한을 두지 않으면 기본적으로 노드의 자원을 끝없이 소모하기 때문이다.
또한 본 실습에서 HPA를 실현하기 위해 파드를 늘리는 기준(limit)을 줘야 만이, 파드가 한계치를 초과하기 전에 파드가 늘어나는 HPA가 가능하다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-4-hpa
labels:
app: deploy-4-hpa
spec:
replicas: 1
selector:
matchLabels:
app: deploy-4-hpa
template:
metadata:
labels:
app: deploy-4-hpa
spec:
containers:
- name: chk-hn
image: sysnet4admin/chk-hn
resources:
# requests 및 limits 설정
requests:
cpu: "10m"
limits:
cpu: "20m"
---
apiVersion: v1
kind: Service
metadata:
name: lb-deploy-4-hpa
spec:
selector:
app: deploy-4-hpa
ports:
- name: http
port: 80
targetPort: 80
type: LoadBalancerHPA 실행
HPA를 실행하는 것은 yaml파일 및 명령어 둘 다 가능하다.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: deploy-4-hpa
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deploy-4-hpa
targetCPUUtilizationPercentage: 50-
maxReplicas: 10 / minReplicas: 1
최대 최소 파드의 수 -
targetCPUUtilizationPercentage: 50
50%로 설정되었으므로 limits로 설정된 cpu가 10이 넘어가는 경우 pod가 추가 생성된다.
명령어를 통해서 HPA를 실행해 주도록 하자.
k autoscale deployment deploy-4-hpa --min=1 --max=10 --cpu-percent=50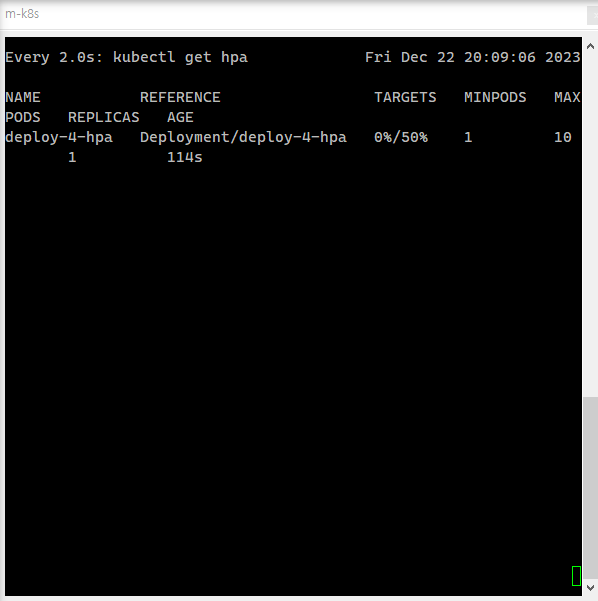
파드에 부하 주기
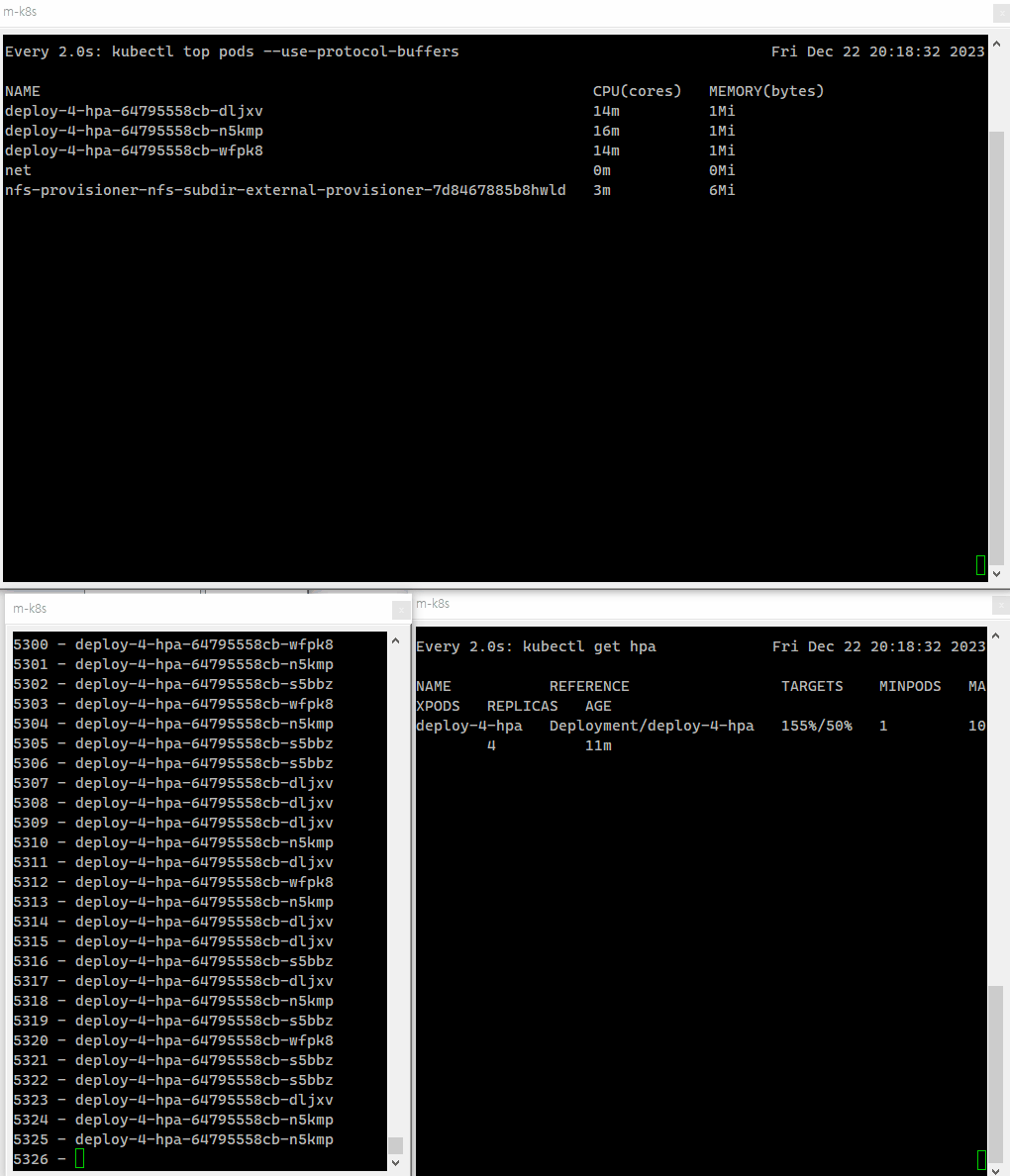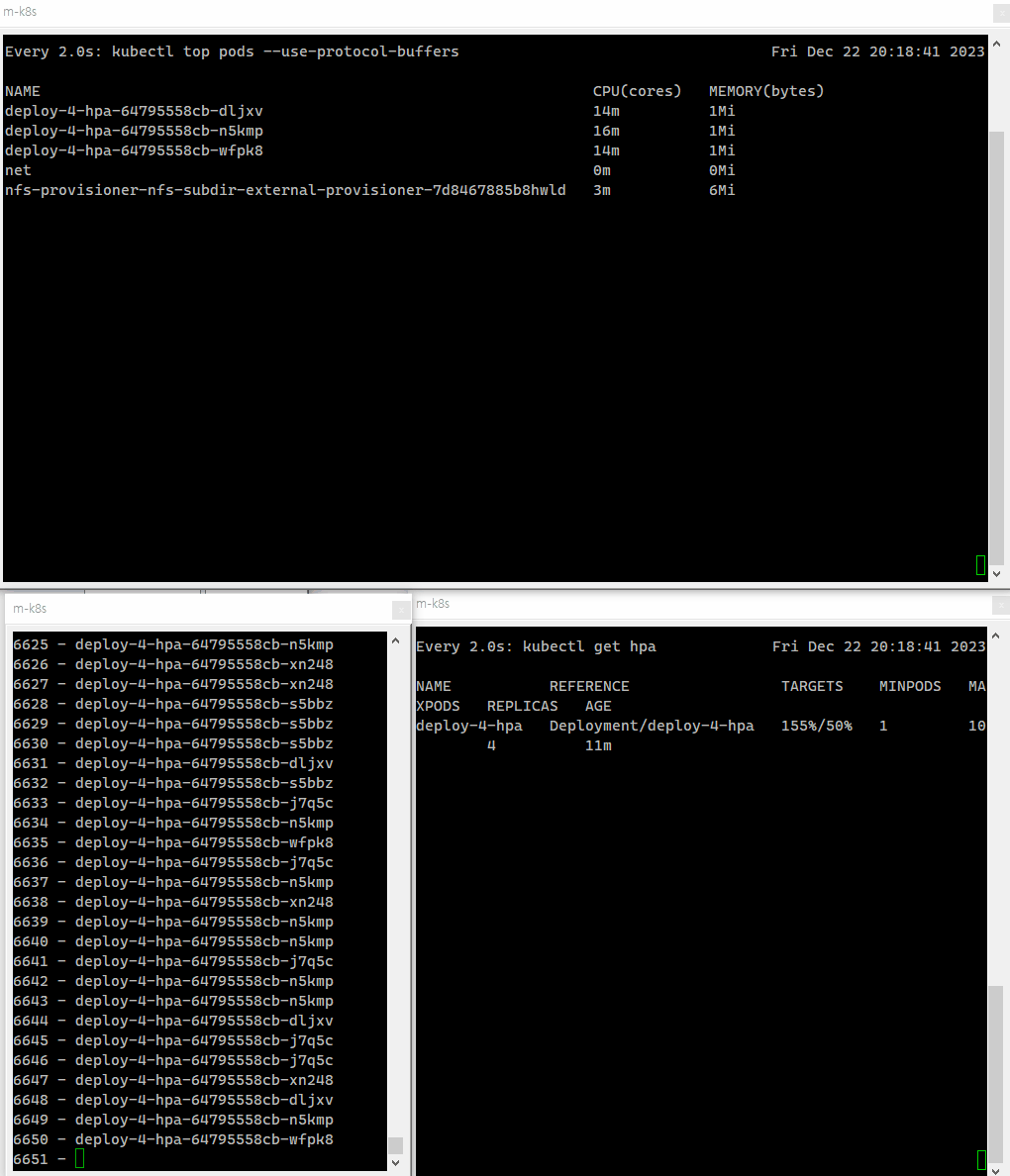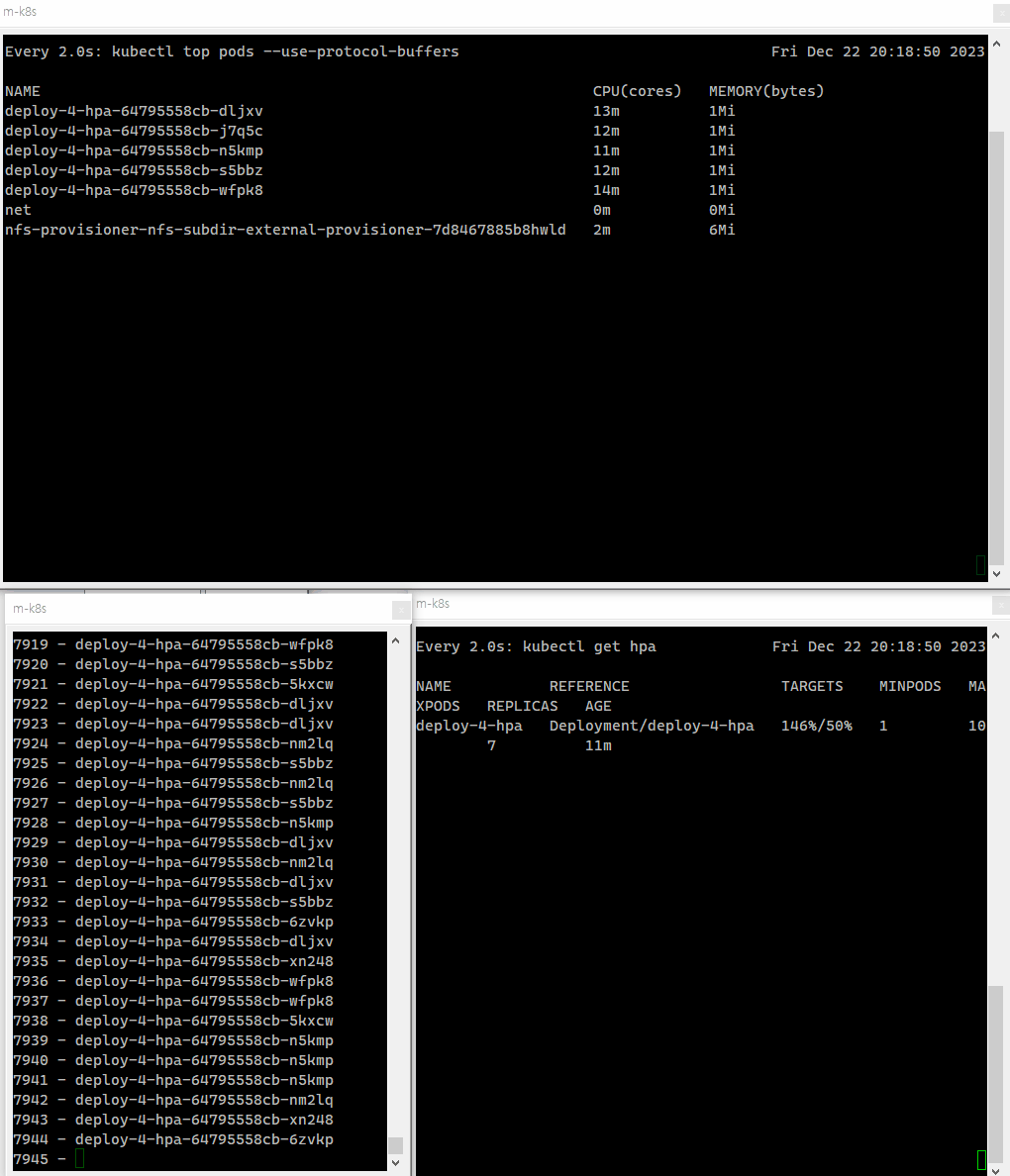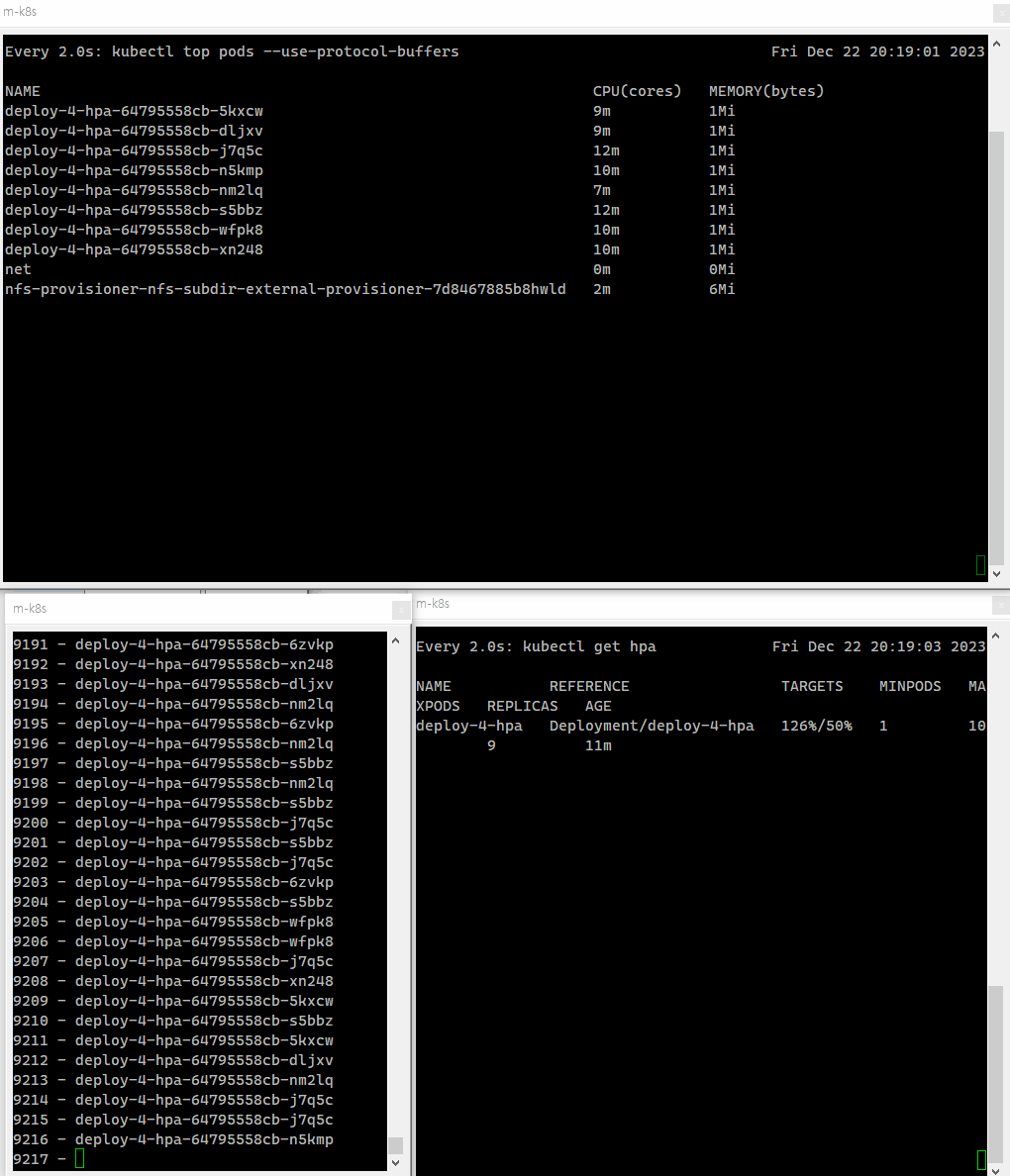
부하를 주기 전에 파드의 수를 체크하기 위해 watch kubectl top 명령어를 통해서 어떻게 파드가 변화하고 있는지 실시간으로 확인할 수 있게 한다.
# 제대로 refresh 되는 것을 보기 위해서
# `-use-protocol-buffers`를 추가했다.
watch kubectl top pods --use-protocol-buffers이제 파드에 부하를 주도록 하자.
무한루프를 통해서 curl 192.168.1.11 로 계속해서 pod에게 요청을 보내게 된다.
(192.168.1.11은 파드를 노출한 로드밸런서의 IP)
현재는 1개의 파드만 있지만, 얼마나 늘어나는 지 확인해 보도록 하자.
#!/usr/bin/env bash
while true
do
COUNTER=$((COUNTER + 1))
echo -ne "$COUNTER - " ; curl $1
done# 실행
./curl-get.sh 192.168.1.11결과
파드에 부하를 줌에 따라 점차 파드의 전체 수가 증가하는 것을 확인할 수 있다.
Reference
그림으로 배우는 쿠버네티스
