Introduction
노드의 스케쥴링을 차단하고, 또 파드를 축출하는 방법인 경계선(cordon)과 드레인(drain)이라는 것은 무엇일까?
경계선(cordon)

특정 오류가 자주 생기는 노드에 대해서, 파드가 할당 되지 않도록 경계선을 치는 것이다.
이렇게 cordon을 사용하면 해당 노드는 더이상 스케쥴링이 되지 않는다.
드레인(drain)

드레인은 영어 뜻 그대로 축출이다.
따라서 노드를 껐다 켜야하는 상황(업데이트)에서 해당 노드에 잇는 파드들을 다른 곳(노드)으로 이전시키는 것을 의미한다.
이렇게 드레인이 수행되고난 뒤의 파드는 자동으로 cordon 상태로 빠지게 된다.
실습
cordon
cordon 설정을 워커노드에 직접 지정해 보도록 하자.
# 스케쥴링 정지(제외)
k cordon w3-k8s
# 스케쥴링 재시작
k uncordon w3-k8s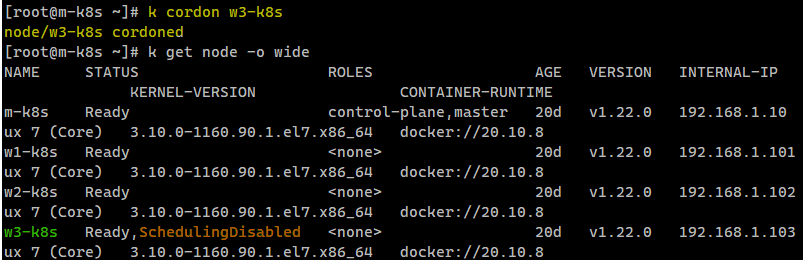
SchedulingDisabled 상태에 3번 워커노드가 빠진 것을 알 수 있다.
파드 배포
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-drain
spec:
replicas: 3
selector:
matchLabels:
app: deploy-drain
template:
metadata:
labels:
app: deploy-drain
spec:
containers:
- name: nginx
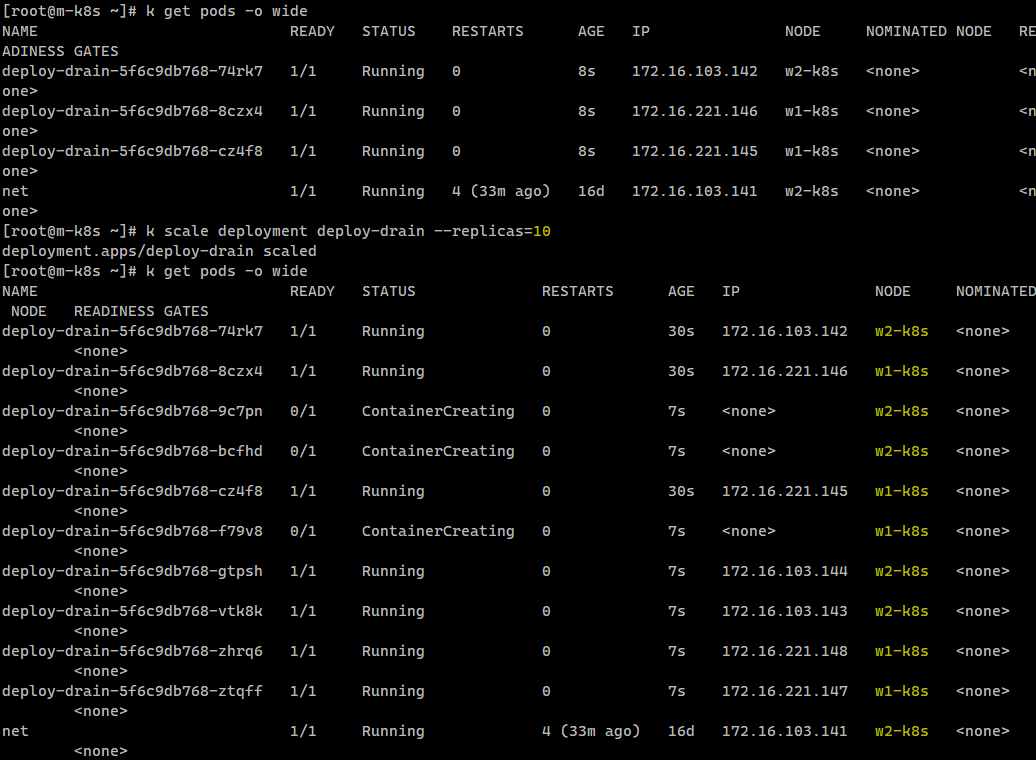
image: nginx실제로 파드를 배포해 보면 cordon 상태에 빠진 워커노드에는 스케쥴링이 발생하지 않는 것을 확인할 수 있다.
replicas 증가
replicas=10 으로 증가시켜보도록 하자.
k scale deployment deploy-drain --replicas=10여전히 워커노드 3번에는 배포되지 않는 것을 확인할 수 있다.
drain
drain을 수행하게 되면 해당 노드는 자동으로 cordon 상태에 빠지고, 해당 노드에 있는 파드들은 다른노드로 이동 한다고 했다.
실제로 그런지 확인해보자.
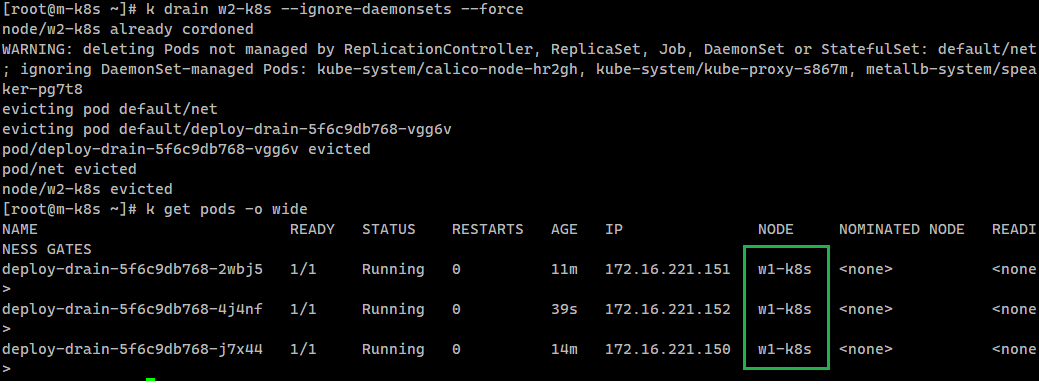
k drain w2-k8s워커노드 2번에 drain을 수행 하였는데, 다음과 같이 수행할 수 없다는 문구가 출력되었다.
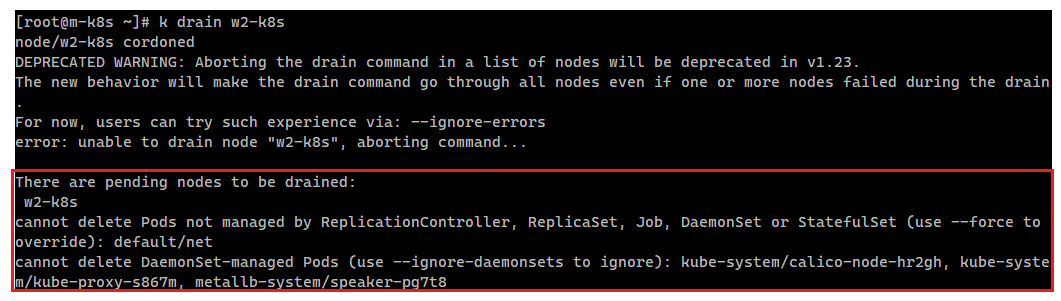
에러 메세지의 중요한 부분만 읽어보자.
"레플리카 셋이나, Job, 데몬셋 등에 의해서 관리되지 않는 기본 파드(net)은 삭제할 수 없어. 그리고 데몬셋으로 관리되는 파드 또한 삭제할 수 없어."
이 말을 정리해보면 다음과 같다.
사용하는 방법
-
아무것도 아닌 단지
kind:Pod로 배포한 단순 파드의 경우,evict(축출) 되어도 다른 노드로 다시 생성되지 않는다. 관리되지 않는 파드를 삭제하기 위해서는
✅--force를 써라 -
데몬셋은 데몬셋의 목적 자체가 각 노드마다 고유의 파드를 한개씩 배포하는 것이므로, drain이 적합하지 않다.
✅--ignore-daemonsets를 써라
k drain w2-k8s --ignore-daemonsets --force기본 파드는 삭제되었고, 워커노드2번(drain한 노드)과 워커노드3번(이전 cordon 실습)이 cordon 상태로 존재하므로 워커노드 1번에만 파드들이 배포된 것을 확인할 수 있다.