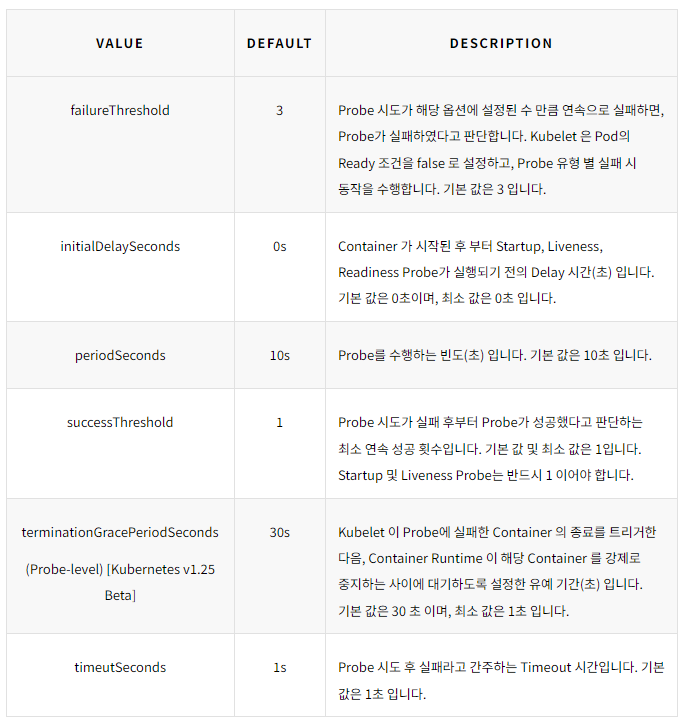
Probe란?
Kubernetes Probe는 컨테이너의 상태를 지속적으로 모니터링하고,
문제가 발생하면 자동으로 조치를 취하는 Kubernetes 기능이다.
Probe의 종류
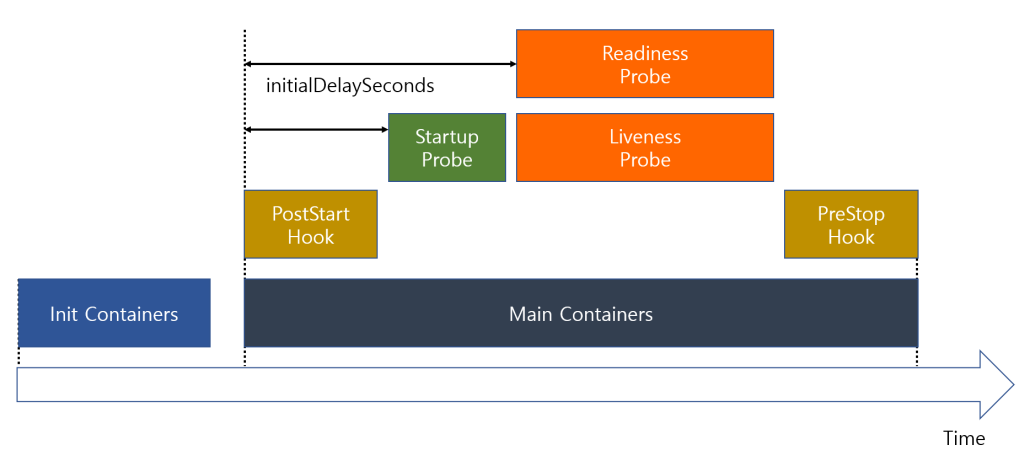
Startup Probe
컨테이너가 제대로 시작되었는지 확인한다.
컨테이너가 제대로 준비되었다는 응답을 받지 못하면 restartPoilcy에 의거하여 자동으로 재시작하며
이는 컨테이너의 초기화 시간이 길 때 주로 사용한다.
✨ Tip!
이러한 Startup Probe가 성공으로 확인되면 바로 Liveness Probe 및 Readiness Probe로 넘어가게 된다.
즉, 애플리케이션을 조금이라도 더 빨리 킬 수 있으므로 Liveness Probe의 initalDelaySeconds 값을 길게 설정하는 것 보다 Startup Probe를 함께 사용하는 것이 좋다.
link
Liveness Probe
컨테이너가 제대로 작동하고 있는지 확인한다.
주기적인 헬스 체크를 통해, 컨테이너가 응답하지 않으면 restartPoilcy에 의거하여 자동으로 재시작한다.
Readiness Probe
컨테이너가 트래픽을 받을 준비가 되었는지 확인한다.
쉽게 말해서 잠깐만 "서비스"를 못하도록 하는 것이다.
즉, 엔드포인트만 제거하여 문제가 있는 컨테이너에 접근하지 못하도록 하고, 문제가 해결되면 엔드포인트를 다시 살린다.
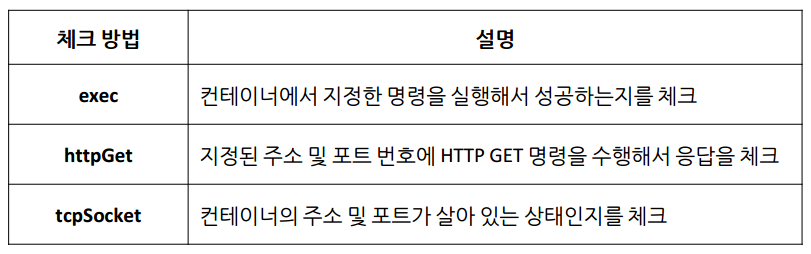
Probe의 체크 방법
Probe가 상태를 체크하는 방법은 다음과 같은 3가지 방법이 있다.
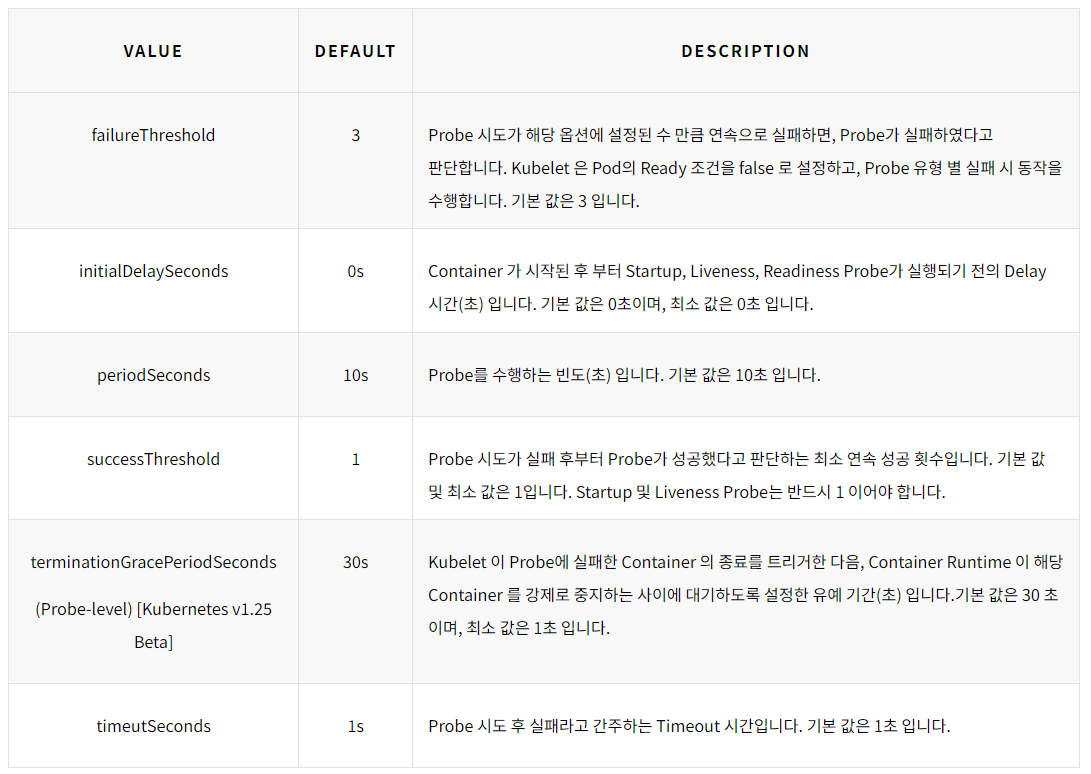
Probe의 설정 옵션
Probe를 등록할 때 지정할 수 있는 옵션은 다음과 같다.
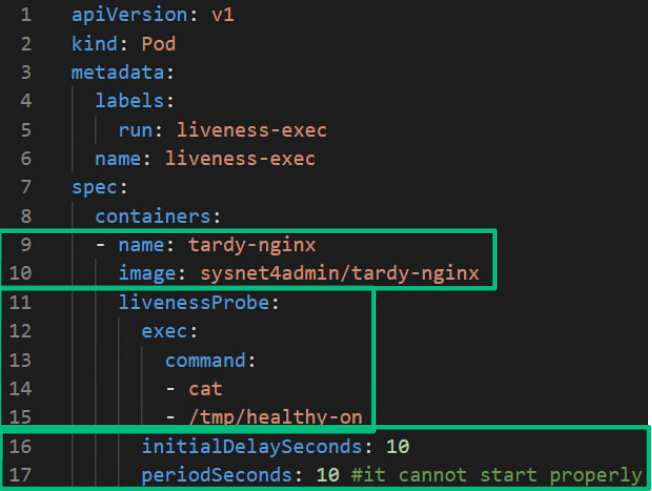
Liveness Probe 예제
현재 initialDelaySeconds를 10초로 둠으로써 livenessProbe가 10초 뒤에 최초 실행이 되고, 매 periodSeconds인 10초 마다 livenessProbe가 실행되며 failureThreshold를 체크한다.
또한 값이 명시적으로 나오지는 않았지만, 현재 failureThreshold 기본 값은 3으로 3번 이상 fail이 되는 경우 컨테이너가 재시작 된다.
실행 확인
tardy-nginx는 컨테이너의 배포까지 오래 걸리도록(약 30초) 만들어진 이미지이므로, initialDelaySeconds인 10초 + periodSecond 10초로 총 20초 이후 livenessProbe로 exec: cat /tmp/healty-on 를 체크 하였을 때 배포가 되지 않았으므로 Fail이 체크된다.
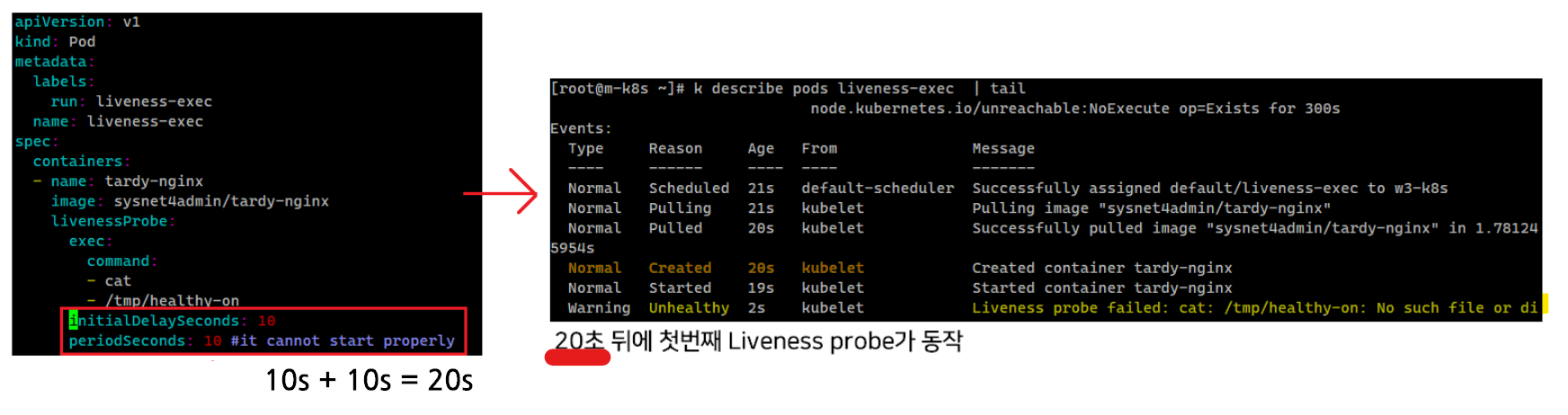
- 0초 : 컨테이너 생성
- 20초 : 1 fail(unhealty)
- 30초 : 2 fail(unhealty)
- 40초 : 3 fail(unhealty)
이후 killing이 수행되고, 다시 재시작을 수행하는 모습을 확인할 수 있다.
initialDelaySeconds 이후 바로 probe가 동작하는 게 아니라고?
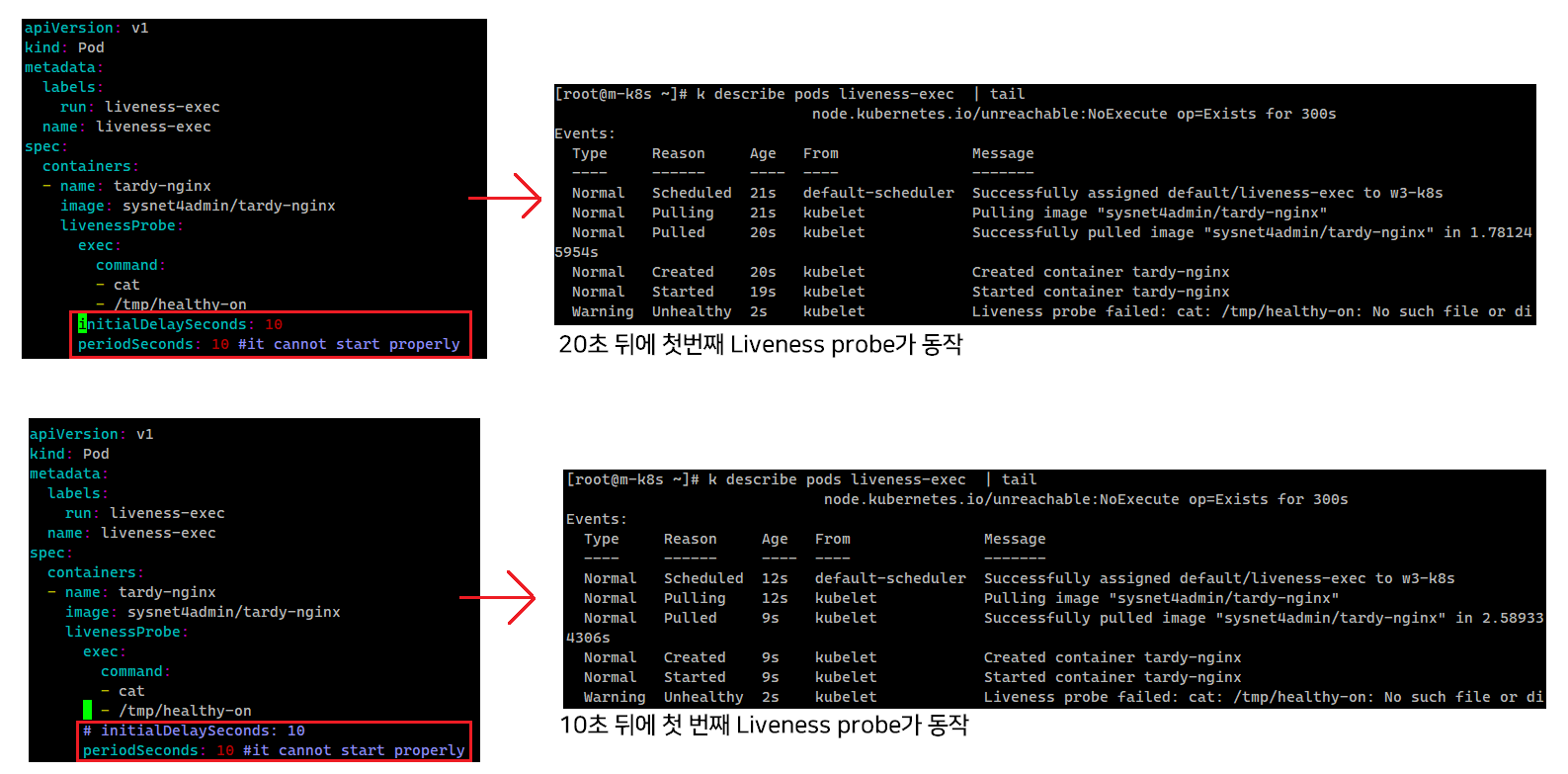
쿠버네티스의 Liveness Probe 설정에서 initialDelaySeconds가 10초이고 periodSeconds도 10초로 설정된 경우, 첫 번째 🩺Liveness Probe가 실행되는 시점은 파드 시작 후 20초가 된다.
이는 initialDelaySeconds 동안의 단순 지연이 먼저 적용되고, 이 지연 시간이 끝난 후 🩺Liveness probe가 아닌periodSeconds가 시작한다.
결과적으로, initialDelaySeconds와 periodSeconds가 함께 있을 때 첫 번째 🩺Liveness Probe 실행시간은 두 시간의 합인 20초가 된다.
즉,
initialDelaySeconds는 그 무엇보다 우선시 되는 대기(초기화) 시간으로 생각하면 된다.
이와 관련해서는 여기를 참고하라.
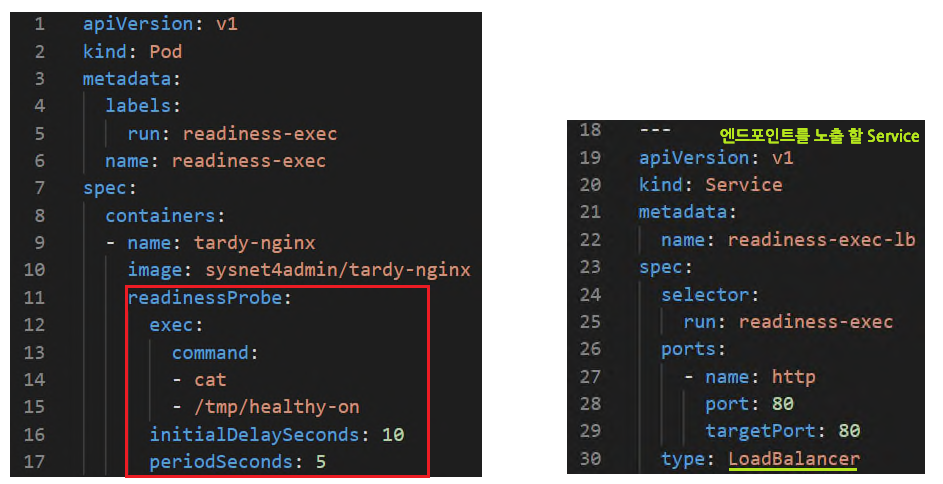
ReadinessProbe 예제
readinessProbe의 경우, 이전 Liveness Probe와 달리 파드(컨테이너)를 재시작 하지 않는다. 단순하게 파드의 엔드포인트를 제거하는 형태로 동작하게 된다.
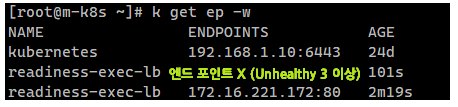
실행 확인

readinessProbe 답게 3번의 실패를 했지만, Unhealthy 상태로 있을 뿐 이전 Killing 상태로는 바뀌지 않는 것을 확인할 수 있다.
단지,파드의 엔드포인트만 제거될 뿐이다.
(만약, deployment로 여러 개의 파드가 동작중이라면, Unhealthy로 판명된 파드의 endpoint만 제거된다)
시간이 지나고, 배포가 완료되어 엔드포인트가 2m19s 경에 생성된 것을 확인할 수 있다.
이제 Probe에 실패하도록 Probe가 cat 명령을 통해서 체크 중인 /tmp/healthy-on 디렉토리를 제거해 보자.
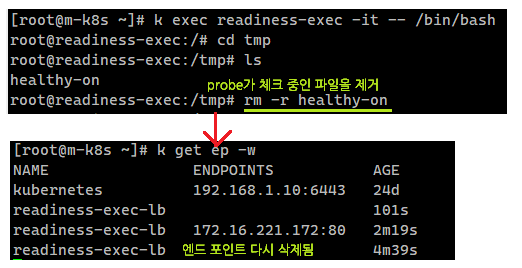
/tmp/healthy-on 디렉토리를 제거하니, 3번의 Unhealthy가 체크된 뒤 엔드포인트가 다시 제거되는 것을 확인할 수 있다.
StartupProbe

애플레케이션의 초기화 과정에 대한 동작 수행이 잘 되는지 체크할 정도의 중요한 애플리케이션이라면, LivenessProbe및 ReadinessProbe를 안 넣을 이유가 없다.
따라서 StartupProbe는 대부분 다른 Probe들과 함께 사용된다.
현재 StartupProbe의 periodSeconds 시간을 상당히 길게(60초) 가져감으로써 나머지 Probe의 initialDelaySeconds 시간을 짧게(5초,10초) 줄 수 있다.
이는 긴 StartupProbe의 periodSeconds를 통해 애플리케이션에 충분한 시간을 제공하여 안정적으로 시작을 보장할 수 있기 때문이다.
Reference
