
Introduction
본 딥러닝 글은 "금오공과대학교 컴퓨터공학과 김성영 교수님"의 강의자료를 통해 학습한 내용을 기반으로 작성하였습니다.
딥러닝 활용 분야
여러 활용분야가 있지만, 몇가지 예시만 살펴보도록 하자.
1. - 이미지 분류 (Image Classification)

학습된 모델을 기반으로 입력 영상에대해서 영상에 포함된 객체의 종류를 구분할 수 있습니다.
이미지 분류의 경우 주로 CNN방식을 기반으로 학습하게 된다.
2. - 객체 검출 obect(Class) Detection
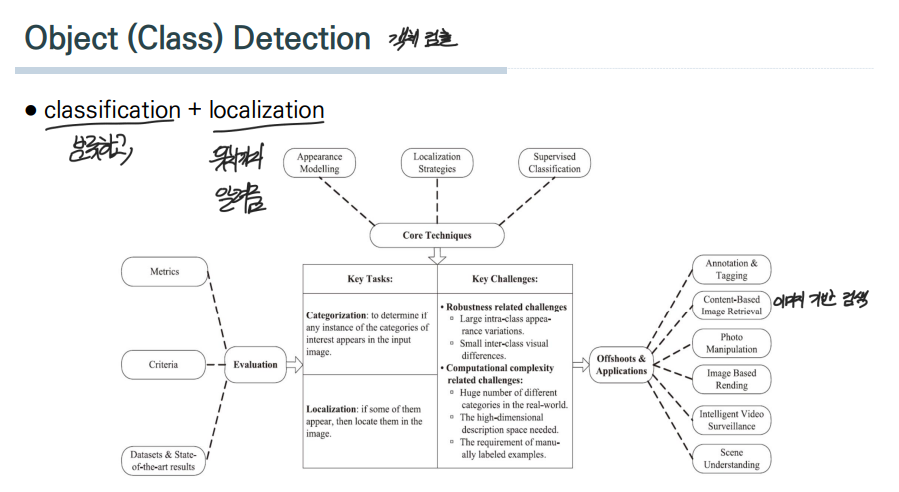
1번의 Image Classification과 같이 어떠한 Input(입력) 데이터에 대해서 이를 분류하는 작업에 localization을 추가하여 해당 객체를 단순히 분류만 하는 것이 아닌 "위치"까지 찾아 알려줄 수 있게 되었다. 이것이 바로 "객체 검출"이다.
여기서 class라는 표현을 썼는데, 이는 객체의 종류(class)를 구분하는 것이므로 class라는 표현을 사용한다.
자 그럼, 아래 새 사진의 Input 예시를 통해 둘의 차이에 대하여 좀 더 직관적으로 알아보자.
Classifcation <-> Object Detection 의 차이
Classification(이미지 분류)

Classification에서는 단순하게 해당 사진을 "분류"만을 한다. 새인지, 강아지, 고양이인지..etc Input데이터에 대해서 학습된 모델을 통해 새 or 개 or 고양이등 분류된 결과를 나타낸다.
Object detection(객체 검출)
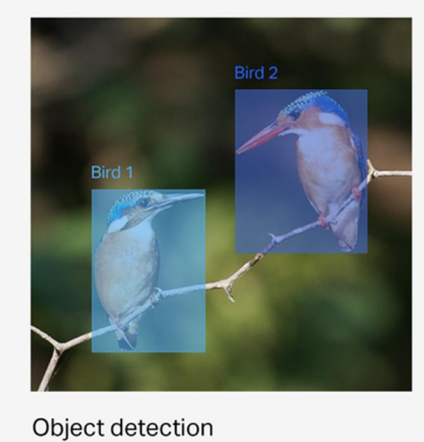
반면 Object detection(객체 검출)은 Bounding box라는 사각형을 통해 대략적인 object의 위치까지 찾아낸다, Classification과 다르게 새의 위치까지 찾아 낼 수 있게 되었다.
다만, 새의 종류가 만약 다르더라도 똑같은 "Bird"로 분류된다. (새 처럼 생긴 객체를 2개 찾은 것이라고 생각하면 된다.)
자 이렇게 앞서 공부한 2가지 방법의 차이까지 살펴보았다.🎉
이왕 분류에 대해서 알아보는 김에 조금만 더 알아보자!
바로 Image Segmentation 과정이다.
Image Segmentation은 위의 object detection(객체 검출)을 확장한 방법이라고 생각하면 된다. 더 upgrade 된 느낌..
3. Image Segmetation
Image Segmentation
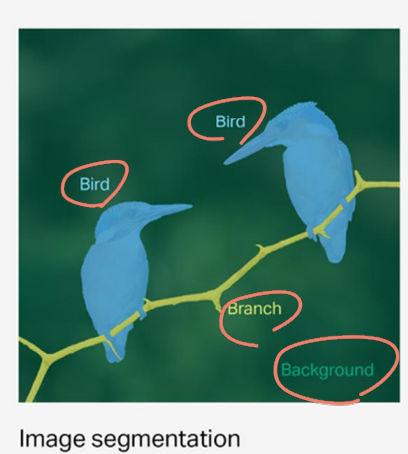
영상처리를 배웠다면 들어봤을 단어.
쉽게말해 Image에서 영상을 구성하는 객체들을 각 영역별로 나눠 처라하는 방법이다.
배경은 backgroud, 새 객체는 Bird, 나뭇가지는 Branch로 이미지를 분리한다. 이렇게 영역을 나누게 되면 위의 Bounding Box가 아닌 Object의 형상대로 영역을 구하기에 Object의 실제에 가까운 더 정확한 영역을 찾을 수 있다.
이러한 Image Segmentation방법을 Semantic Segmentation이라고 한다.
Semantic segmentation: the process of linking each pixel in an image to a class label
(이미지의 각 픽셀을 클래스 레이블에 연결)
🧨하지만 새가 2마리임에도 같은 Bird라는 영역으로 취급되므로 마치 1마리의 새처럼 취급된다. 이를 해결하는 방법은? 바로 아래 있다.
Image Segmentation w.instances
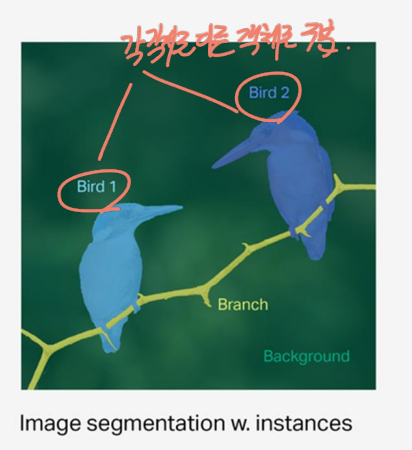
위의 Image Segmetation을 좀더 upgrade(?)한 방법이다. 영역을 분리하는 건 똑같으나 동일한 객체라도 다른 Mask(영역)으로 처리한다. 기존 Segmentation은 두 마리의 새 모두 같은 Bird라는 이름을 부여받았으나, Segmentation instances의 경우 서로 다른 이름(ID 값)을 부여받음으로써 각각 다른 객체로 구분된다.
- 2가지 Segmentation에 대한 차이는 아래 사진과 같다.
영상에 소가 2마리이나 전체적으로 1개의 영역으로 segmentation되었기에 Instance Segmentation이 아닌, semantic segementation이다.

