🎞Introduction
딥러닝과 머신러닝의 차이는 무엇일까?
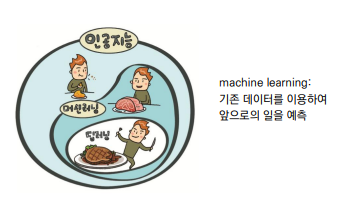
⚙ 머신 러닝
머신러닝의 뜻부터 생각을 해보자
"기계를 학습 시킨다" = "AI를 만들기 위해 기계를 학습시킨다" 라고 할 수 있다.
📈 딥러닝
그럼 딥러닝은 뭘까?
딥러닝 또한 기계를 학습시켜 AI를 만드는 것은 동일하다. 다만, 머신러닝보다 세부적인 "심층학습 깊은 학습" 이 이루어지기에 딥러닝이라 불린다.
이러한 깊은 학습(딥러닝)은 신경망(Neural Network)을 Deep하게 쌓아서 인공지능(인공신경망)을 만드는 것이다.
자 그럼 본격적으로 딥러닝을 탐구해보자!
📚 지도학습 (Supervised learning)
지도학습이란 쉽게말해 데이터 셋에 label이 존재한다는 뜻이다.
label은 정답데이터라고 할 수 있는데, 아래 그램을 보며 이해해보자
📚 학습은 어떻게 이루어 질까?
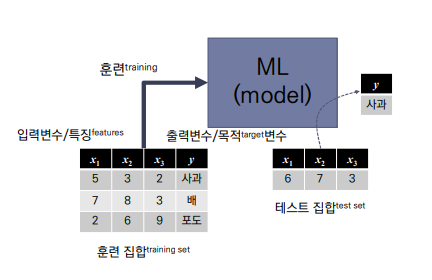
음식..아니 과일을 분류하는 하나의 AI 모델을 만든다고 생각해보자.
우리는 이러한 AI가 학습에 필요한 data 집합을 마련해야한다. (그래야 어떤 과일이 어떤 특징을 가지고 있는지 학습을할 수 있을테니)

x1, x2, x3는 각각 과일의 특징이다. 간단하게 x1은 과일의 모양, x2는 과즙의 양, x3는 과일의 크기라고 생각하자.
이를 feature 즉, 과일의 특징이라고 한다. 이러한 특징은 예를 든 것일 뿐 다양한 특징이 있을것이다. ex.)학생으로 치면 키..무게..성적..등등
특징을 보며 사과는 모양이 5를 가지고, 과즙이 3, 크기가 2정도 된다. 그리고 이러한 데이터에 대한 정답(y)는 사과라는 것을 포함해 AI(model)에게 알려준다. 이러한 과정을 training 즉, 훈련과정이다.
나머지 배와 포도또한 이렇게 학습을 진행한다.
👓 새로운 데이터(샘플)가 오면 분류는 어떻게 이루어 질까?
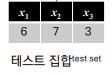
자 그리고 정답(y)가 없는 채 과일의 모양/과즙/크기 만을 AI에게 제시하고 이러한 특징을 가진 과일은 무엇일까? 하고 AI에게 질문을 던진다.
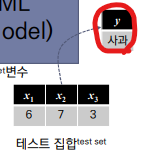
x1, x2, x3 = (6,7,3)을 통해 y는 사과라는 값을 예측하였다.
정확히 입력데이터와 같지 않더라도 학습된 class(과일 종류)중에 입력된 feautre와 가장 유사한 과일을 판명해 내는 것이다.
이렇게 feature와 feature에 대응되는 정답(사과, 배, 포도)를 함께 학습시키는 것을 Supervised learning이라고 한다.
📚 비지도 학습 (Unsupervised learning)
지도학습은 위에서 본 바와 같이 정답(y)가 있는 데이터에 대해서 학습을 시킨것을 말합니다.
그럼 비 지도학습이라함은 뭘까?
바로 정답이 없는 데이터를 통해 학습시키는 방법이다.
정답이 없는데 학습을 어떻게 시키는가?
아래 그림을 보자.
너무 대충 그렸나..?
아무튼, 정답이 없는 입력데이터에 대해 학습을 진행하게 되면 위 그림과 같이 나온다.
포도는 포도끼리 뭉쳐있고, 사과는 사과끼리, 배는 배 끼리 뭉쳐있다.

📚 학습은 어떻게 이루어지는가?
정답이 없기에 x1(모양), x2(크기)의 feature만으로 학습을 진행하게 되고, 유사한 feautre를 가지고있는 데이터들이(같은 과일끼리) 서로 뭉쳐지는 것이다.
(그림에서는 이해를 위해 모양, 크기 2개의 feature만을 생각하여 2차원 좌표평면을 그렸다. 물론 더 다양한 특징을 통하면 더욱 세밀하게 분류가 가능할 것이다)
뭉치지 않으려해도 해당 데이터를 특징에 따라 좌표평면상에 놓게되면 같은 종류의 과일은 각도나, 크기, 모양이 조금씩 다르더라도 유사하므로 뭉쳐진 결과로 학습이 진행된다.
이를 군집화(Clusturing)이라고한다.
👓 새로운 데이터(샘플)가 오면 분류는 어떻게 이루어 질까?
새로운 샘플이 x1, x2의 feature를 가지고 우리가 학습시킨 모델(AI Model)에 들어왔을 때, 이러한 feature x1, x2를 통해 가장 유사한 군집으로 샘플을 분류할 수 있게 된다.
강화학습 (Reinforcement learning)
강화학습이란..?

아! 알파고!
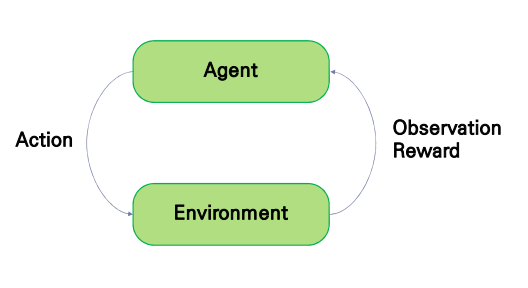
한창 뉴스에 떠들석한 시절, 알파고가 스스로 최적의 수를 학습한다는 것은 들어봤을 것이다.
이를 기반으로 이해해 보자. 자, 그림의 Agent부터 화살표를 따라가자.
-
Agent(알파고)가 Evironment(바둑 게임)에 대해서 어떠한 Action(수를 놓는다)을 취한다.
그럼 이를 통해 이러한 Action이 최적의 수 였을 경우, 혹은 나쁜 수 였을 경우를 Observation(관찰)하여 이에 따른 Reward(보상)을 받으며 학습하게 된다. -
따라서 Agent(알파고)는 높은 Reward(보상)이 따르는 Action(최적의 수)의 방향으로 지속적으로 학습하게 된다.
-
(요약) 정답이 따로 정해져 있지 않으며 자신이 한 행동에 대해 보상(reward)을 받으며 학습하는 것
📜 지도학습 (Supervised learning)
지도학습이 무엇인지는 위에 상세히 서술했으니..패스..
이러한 지도학습에 대해 상세한 종류에 대해 알아보도록 하자!
1. 회귀 분석(Regression)
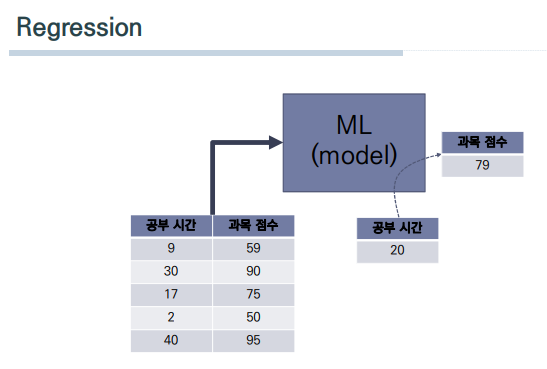
-
회귀 분석이란
입력 데이터(X)에 따라서결과 데이터(Y)를 예측하는 것을 말한다.
선형의 예제로 생각해본다면 쉽다. 공부시간(X)에 대해서 결과(Y)가 있는 여러 학생들의 샘플들이 있을 때
이러한 샘플들로 이를 반영하는(최대한~반영) 최적의 선(Linear)을 긋는다고 생각해보자. -
이렇게 최적의 선을 긋는(찾는)과정이 바로 Model(AI)을 학습시키는 것이다.
자, 학습이 완료되고 최적의 직선을 찾았다! (임의로 그린것이기에 정확하지는 않을 것이다.)
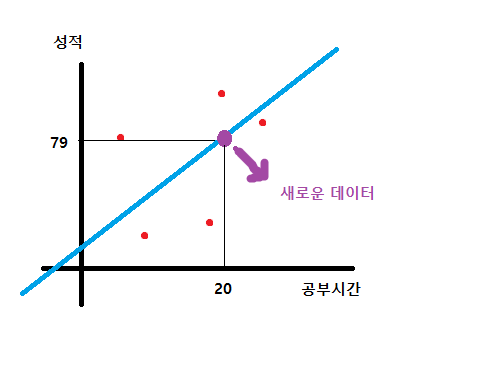
-
빨간색이 기존 학생들의 데이터, 파란색 선이 이를 반영하는 최적의 직선이다. 여기에 새로운 학생의 공부시간 데이터가 입력 되었을때 공부시간 X(20)만으로 과목점수 Y(79)점이 나올 것이다. 라고 예상할 수 있게 된다.
-
몰라도 된다! 이러한 부분은 이후 Linear Regression 파트에서 자세히 서술한다.
2. 이진 분류(Binary classification)
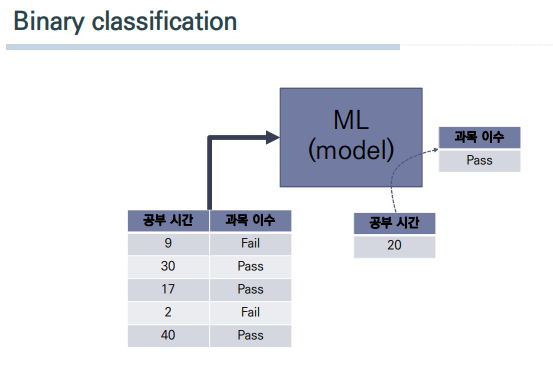
-
이진 분류는 공부시간을 바탕으로 과목이수 여부를 True/False(합/불) 2가지로 분류한다.
이진 분류와 같은 경우, 선형으로 예측하기 어려운 점이 있으므로 sigmoid function을 사용한 logistic regression 과정을 거친다. -
왜 선형으로는 어렵고, 왜 logstic regression을 사용하는지 대해서는 Logistic Regression 파트에서 자세히 서술한다.
3. 다중 클래스 분류(Multi-label classification)
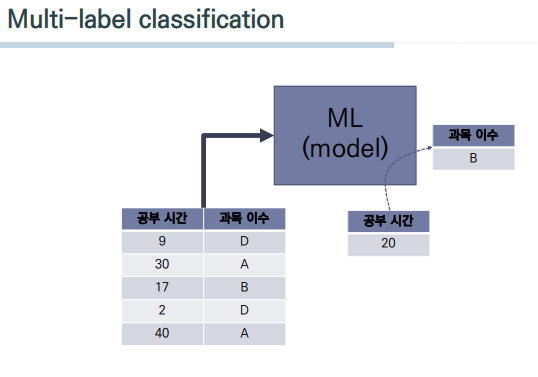
주어진 데이터에 대해서 클래스(카테고리)에 따라 데이터를 분류하는 것이다.
분류에서 2가지를 Yes/No 로 분류하는 것이 위에서 보았던 이진 분류이고, 이 이상의 클래스(카테고리)를 나눠 분류하는 것은 다중 분류라고한다.
part01에서 보았던 Classification(분류)를 다시보는 시간을 가지며 마친다.
part01 - Classification
