
Introduction
자연어 처리에 대해서 알아보고 MLP를 통하여 영화리뷰 문장에 대한 긍정/부정을 예측해본다.
자연어 처리란 무엇일까?
- Natural Languate Processing (NLP)
- 컴퓨터가 인간이 사용하는 언어(음성이나 텍스트)를 이해하고 분석하는 기술
자연어로 만들어진 모든 데이터에 대해서 이해하고 답한다.

시퀀스 데이터 이해
연관성이 있는 연속된 데이터
ex.) 텍스트, 시계열 데이터 등
시퀀스 데이터를 사용하는 응용 분야
- 문서 분류나 시계열 분류 : 글의 주제나 저자를 살펴 보는 기술
- 시계열 비교 : 두 문서나 주식 가격의 관련 정도 추정
- 시퀀스 to 시퀀스 학습 : 한글 문장을 영어로 번역
- 감성 분석 : 트윗터나 영화 리뷰가 긍정인지 부정인지 분류
- 시계열 예측 : 최근 날시 데이털르 기반으로 향후 날씨 예측
- 언어 모델 생성
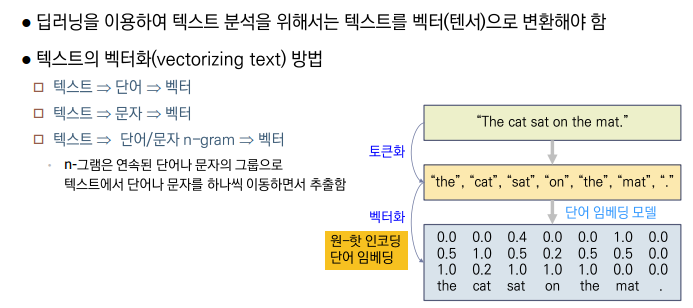
텍스트의 벡터화 방법
딥러닝을 이용하여 텍스트 분석을 위해서는 텍스트를 백터(텐서)로의 변환이 필요하다.
하나의 텍스트(문장)을 단어/문자로 변경하고 이를 다시 벡터화 하는 과정이 수행된다.
Bag of Words (BOW)
같은 단어끼리 가방에 담은 뒤 각 가방에 몇개의 단어가 들어있는지를 세는 ㄱ ㅣ법
각 단어가 몇번이나 중복해서 쓰였는지를 알 수 있음
단어의 빈도수를 알면 텍스트에서 중요한 역할을 하는 단어를 파악 가능
간단하고 효과적이라 널리 사용된다.
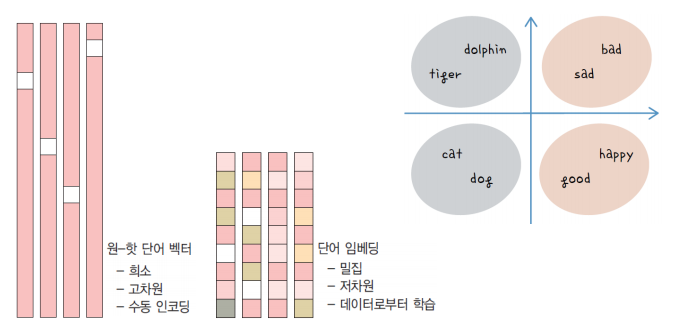
원-핫 인코딩
- N개의 단어를 포함하는 어휘 사전을 만드는 것.
- 모든 단어에 고유한 정수 인덱스를 부여하여 만든다.
- 각 단어마다 길이가 N인 벡터를 생성하는데, k번째 원소만 1이고 나머지는 모두 0인 희소 벡터 형태를 띈다.
원-핫 인코딩의 단점
-
원핫인코딩의 단점은 모두가 인덱싱 처리된 단순한 벡터 형태이므로 단어사이의 연관성을 파악할 수 없다. 의미/개념/유의어/반의어 등 연관관계가 있어도 이를 표현할 수 없다.
-
사용된 어휘가 많을수록 어휘사전의 크기가 커지는데, n개의 어휘를 사용한다고 하면 n차원의 어휘사전이 필요하게 된다. 즉 너무 많은 자원이 소모되는 것이다.
원-핫 인코딩의 해결 방안
1. 원-핫 해싱
- 토큰(단어)의 수가 너무 많아 다루기 어려울 때, 해당 단어를 해싱하여 고정된 크기의 벡터로 저장한다.
장점 : 이러한 방법을 사용하면 단어의 인덱싱이 필요없어 차원이 줄어드므로 효율적인 메모리의 사용이라고 할 수 있다.
단점 : 하지만 해싱기법에 따라 해시의 충돌이 발생할 수 있다. 따라서 해싱 공간의 차원이 증가하게 된다.
2. 단어 임베딩
- 저차원의 밀집된 벡터 형태로 사용된다.
- 데이터로부터 학습을 통해 생성한다.
- 학습을 통해 단어가 가지는 의미 자체를 다차원 공간에 '벡터화 '시킨다.
- 중심 단어의 주변 단어들을 이용하여 중심단어를 추론하는 방식으로 학습한다.
- 대표적인 예로 Word2Vec가 있다.
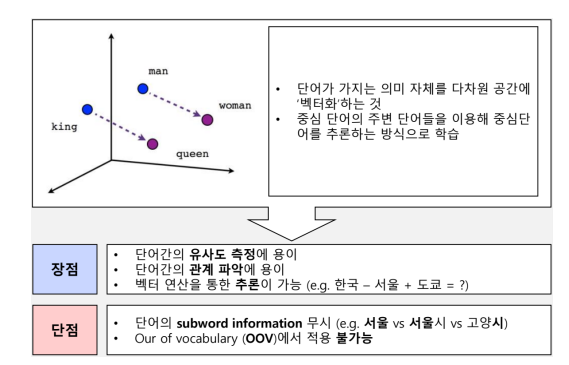
장점 :
- 단어간 유사도 측정이 용의하다.
- 단어간의 관계를 나타낼 수 있다.
- 벡터 연산을 통해 추론이 가능하다.
단점 :
- 동형어 다의어 등에 대해서 성능이 좋지 않다.
- 주변 단어를 통해 학습이 이루어지므로 '문맥'을 고려할 수 없기 때문이다.

영화리뷰 긍정/부정 예제
소스코드
import numpy
import tensorflow as tf
from numpy import array
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Flatten,Embedding
# 텍스트 리뷰자료를 지정
docs = ["너무 재밌네요","최고야","참 잘 만든영화다","추천하고 싶다","한번 더 보고싶다","글쎄요","별로였어","생각보다 지루해","연기가 어색해","재미없어"]
# 긍정 리뷰는 1, 부정 리뷰는 0으로 클래스를 지정.
classes = array([1,1,1,1,1,0,0,0,0,0])
# 토큰화
token = Tokenizer()
token.fit_on_texts(docs)
print(token.word_index)
x = token.texts_to_sequences(docs)
print("\n리뷰 텍스트, 토큰화 결과:\n", x)
# 패딩, 서로 다른 길이의 데이터를 4로 맞춰 준다.
padded_x = pad_sequences(x, 4)
print("\n :\n", padded_x)
# 딥러닝 모델
print("\n딥러닝 모델 시작:")
# 임베딩에 입력될 단어의 수를 지정
word_size = len(token.word_index) +1
# 단어 임베딩을 포함하여 딥러닝 모델을 만들고 결과 출력
model = Sequential()
model.add(Embedding(word_size, 8, input_length=4))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(padded_x, classes, epochs=20)
print("\n Accuracy: %.4f" % (model.evaluate(padded_x, classes)[1]))결과


붉은 배 오색 딱다구리 개발자 🦃Cloud & DevOps