💡 Introduction
쿠버네티스에는 상태를 저장할 수 있는 배포법(또는 컨트롤러)인 스테이트풀셋(Statefulset)이 있다.
이에 대해서 알아보기 위해 먼저 Stateful과 Non-Stateful의 차이를 알고 가도록 하자.
🥊 Stateful vs Non-Stateful
1. 스테이트풀(Stateful)
상태를 지속적으로 유지하는 애플리케이션
각각의 인스턴스가 고유한 상태 및 역할을 가지고, 인스턴스는 이러한 상태를 유지한다.
예를 들어 데이터베이스나 캐싱 시스템과 같이 데이터를 영구적으로 저장하고 관리해야 하는 애플리케이션이 있다.
데이터베이스의 관점
일반적으로 많은 데이터베이스는 스테이트풀의 특성을 가지고 있는데, 그 이유는 데이터베이스는 클라이언트와 서버 간의 상태를 유지하고 정보를 지속적으로 저장하는 역할을 수행하기 때문이다.
데이터베이스에 상태 정보를 기억(저장)하고 필요할 때마다 클라이언트나 서버가 이를 조회하거나 업데이트하게 된다.
이러한 스테이트풀 애플리케이션은 각각의 인스턴스가 고유한 식별자를 가지고 있다.
🎭 고유한 식별자?!
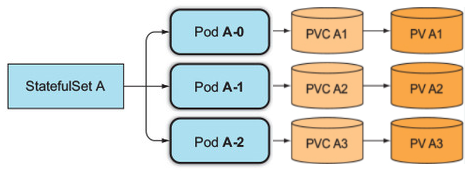
여기서 고유한 식별자를 가진다는 의미로 이후 나올 스테이풀셋의 각각의 파드가 각각의 볼륨(PV)을 가지는 것을 설명할 수 있다.
2. 논스테이트풀(Non-stateful)
상태를 지속적으로 유지하지 않는 애플리케이션
각각의 인스턴스는 동일한 작업을 수행하며, 요청에 따라서 상태가 변경되는 것이 아닌 일관되게 유지된다.
예를 들어 웹 서버, 로드밸런서와 같은 애플리케이션에 이에 해당된다.
각각의 인스턴스는 동일한 작업을 수행
논 스테이트풀 애플리케이션은 상태를 공유하거나, 따로 저장하지 않으므로 인스턴스간에 교체가 가능하며, 스케일링이 쉽다.
웹의 관점
웹은 주로 논스테이트풀이다. 웹이 논 스테이트풀로 작동하는 이유는 다음과 같다.
-
웹 HTTP 프로토콜의 Stateless 특성
첫째로 웹의 통신 프로토콜인 HTTP 프로토콜은 상태를 유지하지 않는 stateless 프로토콜로, 각각의 HTTP 요청은 이전 요청과 별개로 처리된다.
-
웹 서버는 상태 유지 X
둘째로 웹 서버는 클라이언트로부터 받은 요청에 대한 필요한 정보로 응답을 제공할 때, 해당 응답에 대한 상태를 저장하지 않는다. (즉, 유지하지 않는다. 응답을 제공과 동시에 자체로 끝)
이제 본격적으로 Kubernetes의 스테이트 풀셋에 대해서 알아보자.
스테이트풀셋(Statefulset)
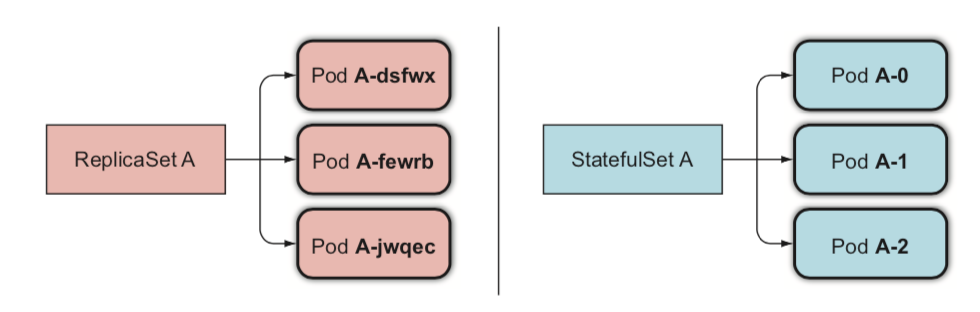
스테이트 풀셋은 "Stateful" 즉, 상태가 있는 애플리케이션 배포 방법이다.
스테이트 풀셋은 디플로이먼트와 동일하게 파드를 배포하고 복제본을 제공한다.
차이점은 파드의 순서 및 파드의 고유성을 보장하며, 각 파드마다 고유한 볼륨을 가지게 된다는 것이다.
쿠버네티스에서 MSA로 동작하는 대부분의 애플리케이션은 상태를 갖지 않는 경우(Stateless)가 많다.
웹서버만 해도 응답에 대한 요청 데이터만 그 순간 처리할 뿐 상태를 저장하지 않는다.
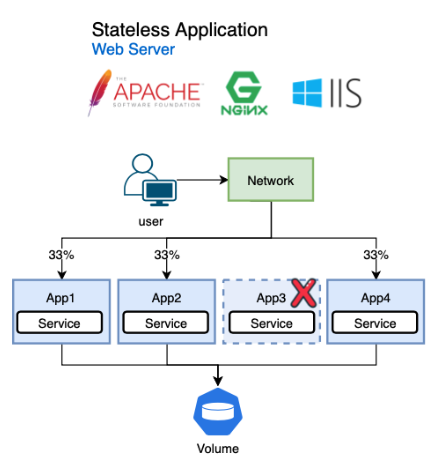
이처럼 상태를 가지지 않는 웹서버와 같은 경우는 단순하게 레플리카셋이나, 디플로이먼트를 통해서 단순 복제 형식으로 대체가 가능하다.
하지만..
데이터 베이스와 같이 영구적인 데이터 저장 및 상태를 저장해야하는 경우가 있다.
이 때, 데이터 베이스는 상태를 저장할 수 있는 배포 방법인 StatefulSet을 사용한다.
왜 그런지 바로 알아보자.
데이터베이스를 StatefulSet으로 사용하는 이유
🧐 만일 데이터 베이스를 Stateless한 디플로이먼트 및 레플리카셋등으로 배포할 경우 어떻게 될지 생각해보자.
➡️ 첫째, 상태가 저장되지 않으므로 파드가 재시작되거나 다시 배포될 때 데이터 손실이 발생할 수 있다.
스테이트 풀셋을 사용하면 각 파드의 고유 식별자를 부여하여 해당 파드에 장애가 생겨 다시 시작 되더라도 파드에 할당된 PV를 기억하고 유지할 수 있다.
➡️ 둘째, Stateful Application의 특징인 "각각의 역할"을 수행할 수 없다.
데이터 베이스의 경우 성능 최적화, 부하 분산을 위해 그림과 같이 각각의 인스턴스의 역할이 다르게 부여되어 사용될 수 있다.
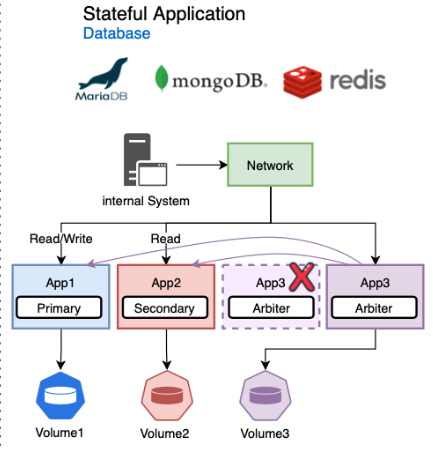
App1메인 DB로서 Read/Write가 가능한 PV1을 사용하며, CRUD 작업을 처리App2Read 권한만 필요하므로 조회를 위해 읽기 전용 PV2를 사용App3Primary와 Secondary를 감시하고 있어야 하므로, App1과 App2의 PV에 접근하여 이를 감시
각 파드는 하나의 데이터베이스의 각 일부를 가지고, 이는 각 파드가 독립적인 데이터베이스 인스턴스를 실행한다.
사용자는 여러 파드가 있는 것을 알지 못하고, 단일 데이터베이스 인스턴스로 작동하는 것 처럼 보인다.
소스코드
헤드리스 서비스이므로, ClusterIP를 통해서 랜덤한 파드로 접속되는 것이 아닌, 포드 번호를 통해서 특정한 파드로 접속한다.
헤드리스 서비스를 생성한다.
//myapp-svc-headless.yaml
---
apiVersion: v1
kind: Service
metadata:
name: myapp-svc-headless
labels:
app: myapp-svc-headless
spec:
ports:
- name: http
port: 80
# 헤드리스 서비스이므로 ClusterIP로 접근하지 않을 것이므로, ClusterIP가 없다.
clusterIP: None
selector:
app: myapp-sts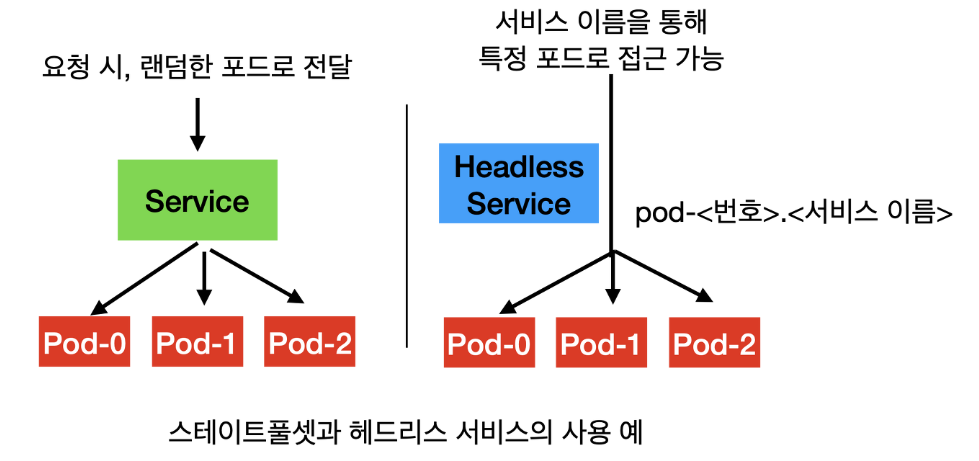
스테이트 풀셋은 디플로이먼트와 동일하게 파드를 배포하고 복제본을 제공한다.
차이점은 파드의 순서 및 파드의 고유성을 보장하며, 각 파드마다 고유한 볼륨을 가지게 된다는 것이다.
//myapp-sts.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: myapp-sts
spec:
selector:
matchLabels:
app: myapp-sts
serviceName: myapp-svc-headless
replicas: 2
template:
metadata:
labels:
app: myapp-sts
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb
ports:
- containerPort: 8080Reference
https://nearhome.tistory.com/107
https://yozm.wishket.com/magazine/detail/1909/
https://loft.sh/blog/kubernetes-statefulset-examples-and-best-practices/
