
파드를 실수로 지웠다면
-
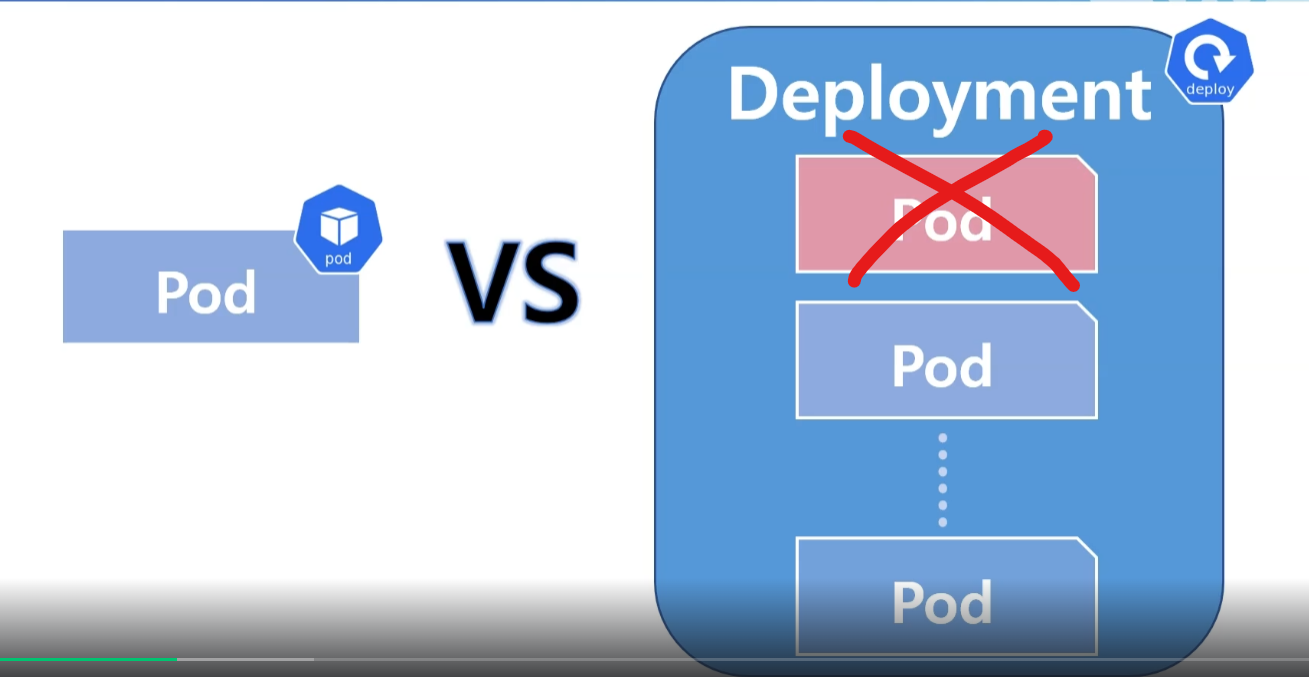
파드만 배포된 경우
-> 큰일났다..GG -
디플로이먼트 형태로 배포된 파드라면?
-> 괜찮아! 디플로이먼트는 파드를 감싸고 있는 객체니까, 하나쯤 지워져도 다시 만들면 돼!
쿠버네티스가 키우는 파드는?
- 죽으면 죽는거지
- 집에 있는 일회용 우산같은 느낌
(잃어버리거나 부서지거나 하면 그냥 하나 사면되지 뭐)
왜 그럴까?
- 파드는 재 생성되는 경우가 상당히 많다.
(ex. 노드가 문제가 생겨 다른 노드로 파드를 옮겨야하거나, 뭔가 파드 내부적으로 문제가 생겼거나 등) - 이러한 파드는 존재할 뿐, 이동할 수 있는 존재가 아니다!
(삭제 후 재 생성만 가능)
실제로 지우면서 알아보자.
- 첫째로 두 yaml 파일을 해당 디렉토리 경로만을 이용해서 한번에 전체 실행시킨다. (deploy와 pod를 동시에 생성)
kubectl apply -f ~/_Lecture_k8s_starter.kit/ch4/4.1

- 단일 배포된 파드를 지워보자.
kubectl delete pod del-pod
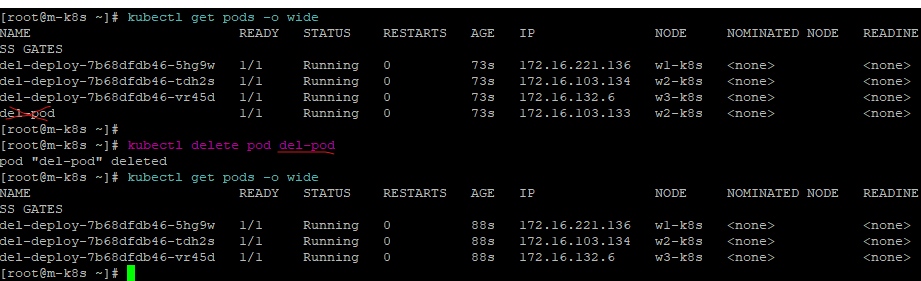
저런,, 실제로 지워져버린 것을 확인할 수 있다.😥
- 디플로이먼트로 배포된 파드를 지워보자.
kubectl delete pod del-deploy-7b68dfdb46-5hg9w
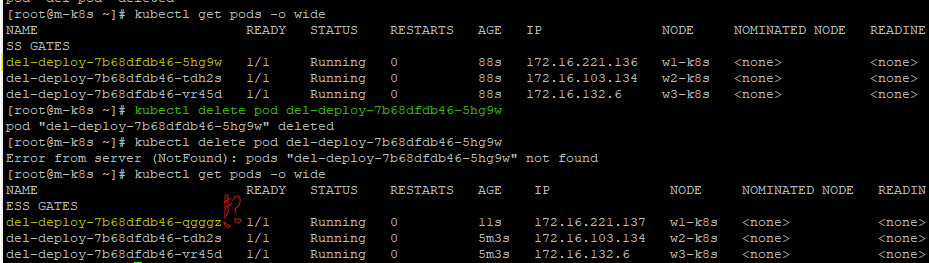
엇? 지웠더니 새로운 파드가 생겼다!?
이는 디플로이먼트 내부적으로 3개의 파드를 유지하라는 규칙이 적용되어 있기 때문이다.
- 디플로이먼트를 지워보자.
kubectl delete deployments.apps del-deploy
kubectl delete deployment del-deploy
( 둘 다 동일한 명령어이다)

default 네임스페이스에서 완전히 사라진 것을 확인할 수 있다!
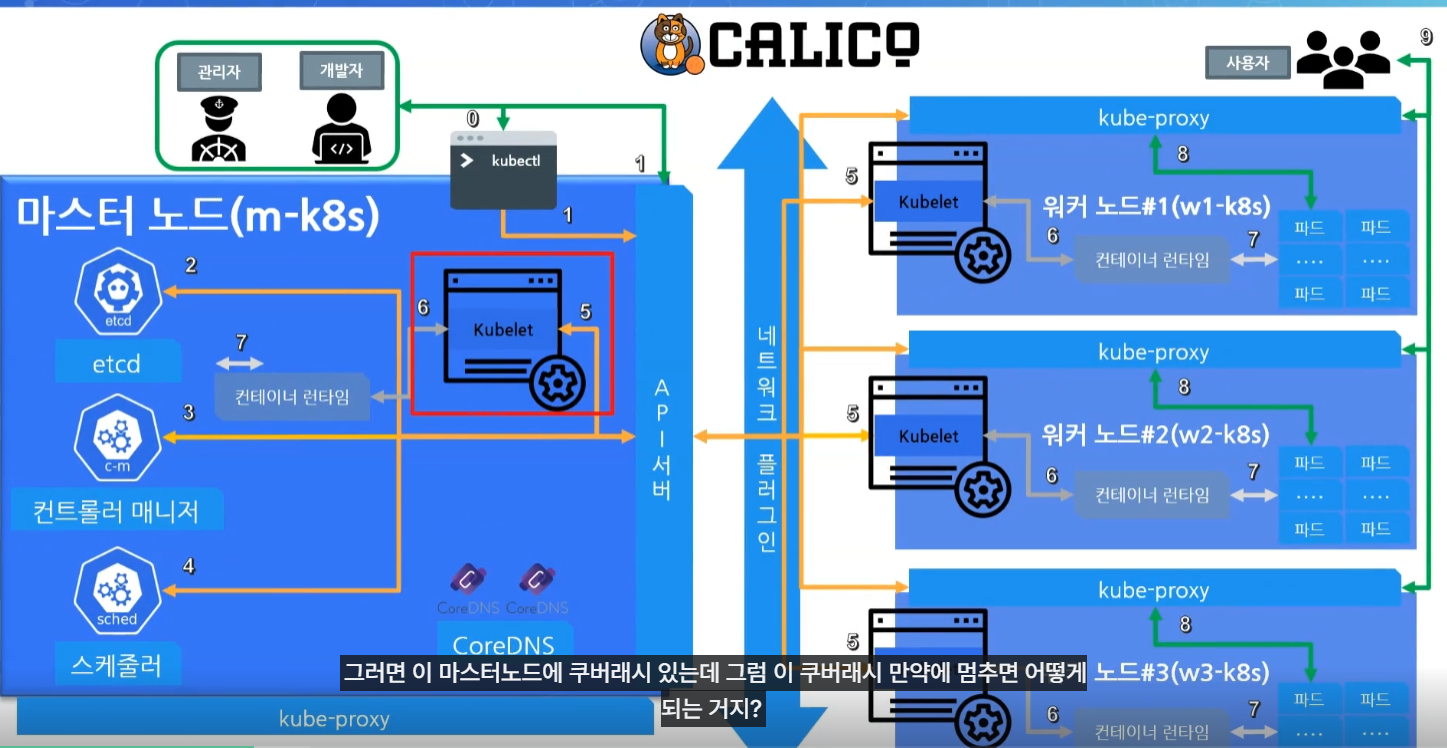
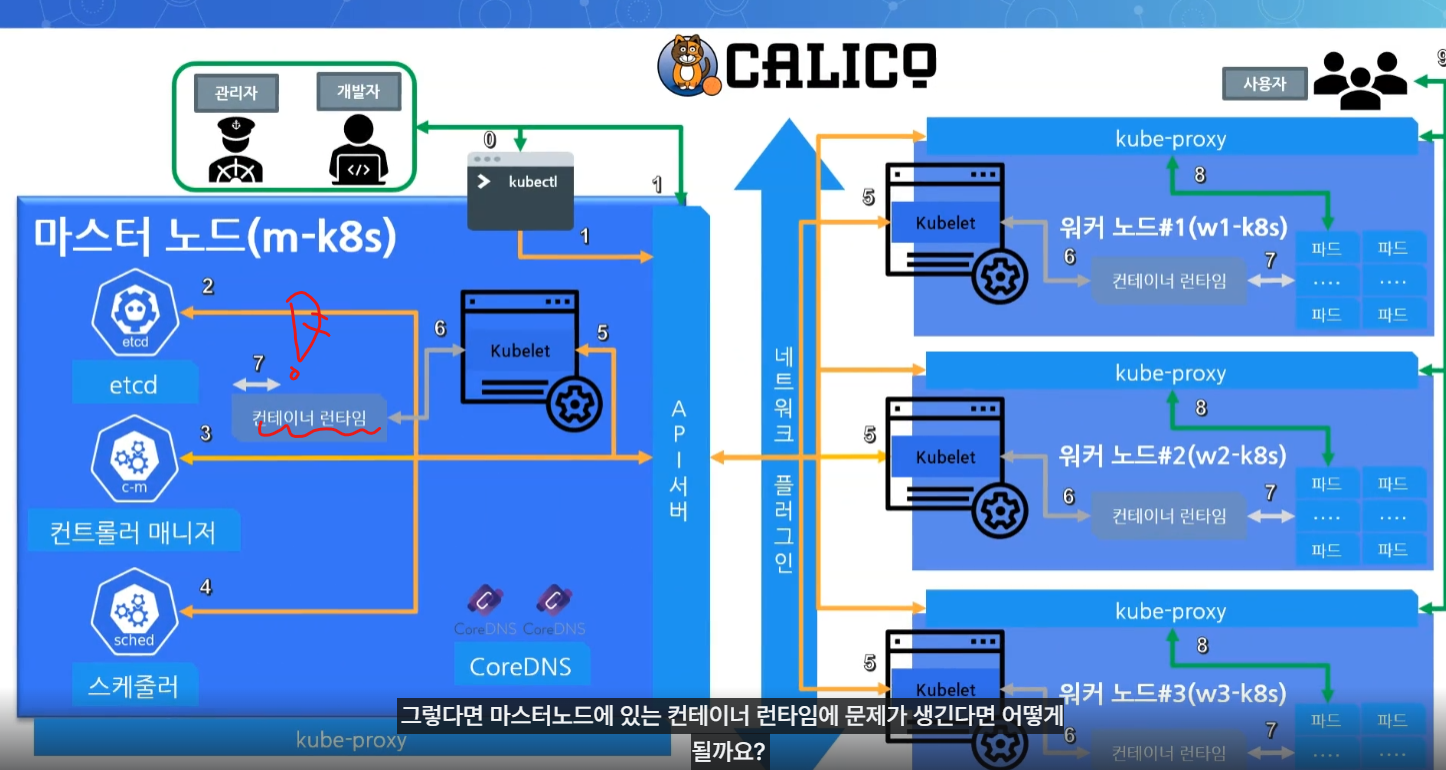
구성요소에 문제가 생겼다면?
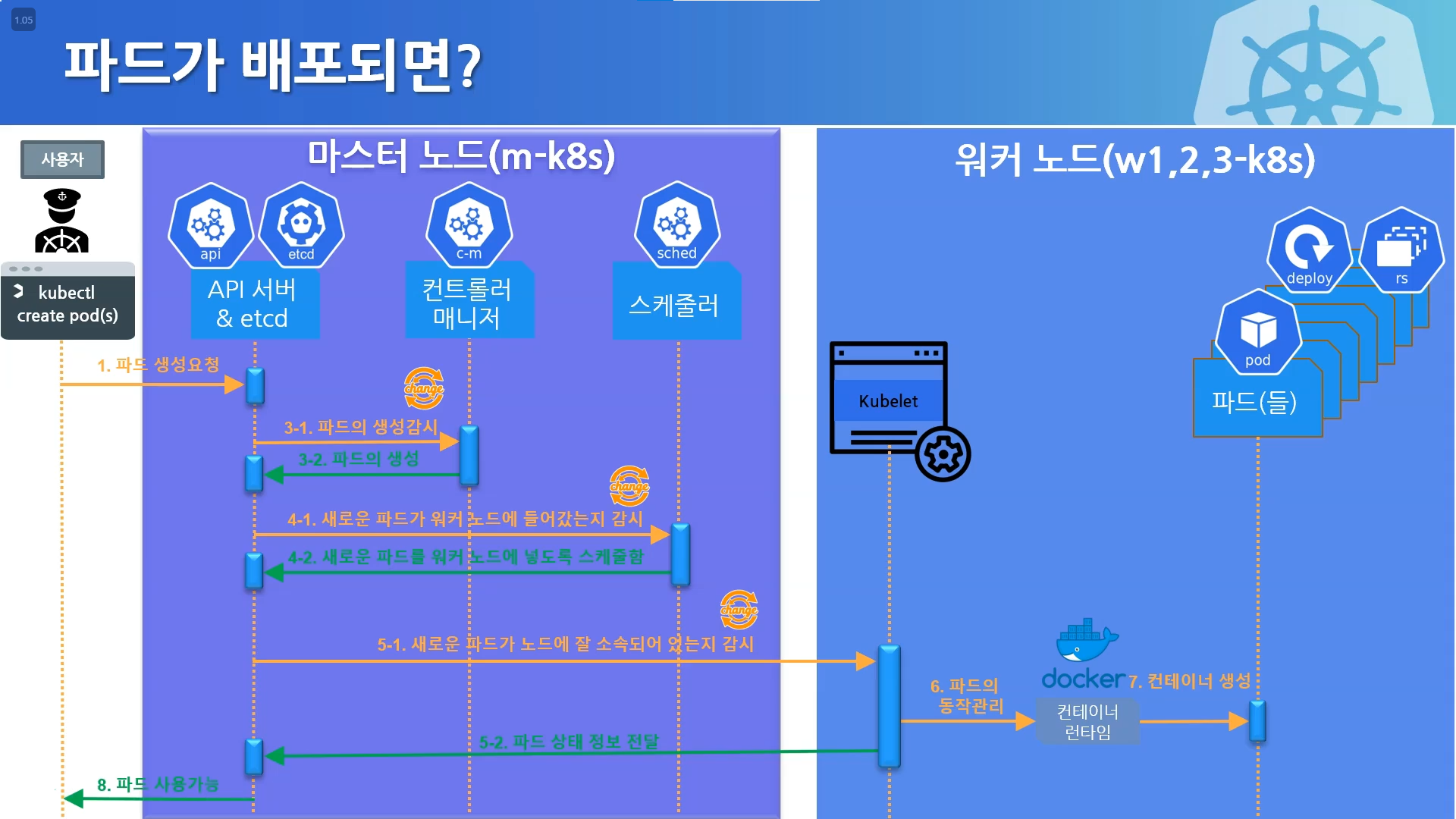
대부분의 구성요소 파드들은 API 서버의 상태를 확인하고 빠르게 복구가 가능하다. 하지만 Kubelet의 경우 복구가 힘들다.
API서버와 Kubelet은 각 위치가 마스터노드와 워커노드로 마치 바다와 강을 두고 그 사이에 서로 존재하기 때문이다.
마스터 노드의 쿠버네티스 구성 요소는 복제되어 있으며 더 높은 가용성과 내결함성을 갖추도록 설계되어있다. 따라서 하나의 마스터 노드 구성 요소가 실패하면 다른 인스턴스로 대체되어 클러스터가 계속 작동한다.
하지만 클러스터 내의 워커노드에서 파드를 관리하는 Kubelet은 API 서버 상태를 통해 빠르게 복구하기 힘들다.
API 서버가 다루는 자식이긴 하지만 워커노드의 kubelet은 다른 집(워커노드)에 살고있는 서자와 같이 취급되기 때문이다.
(마스터노드에도 물론 kubelet이 존재한다)
kubelet 문제를 발생시켜보자.
kubelet에 문제가 생긴 상황을 연출해보자.
현재 그림에서의 kubelet에서 문제가 생긴 상황을 발생시키기 위해 자식노드로 접속하여 다음 명령어를 입력한다.
systemctl stop kubelet
systemctl status kubelet
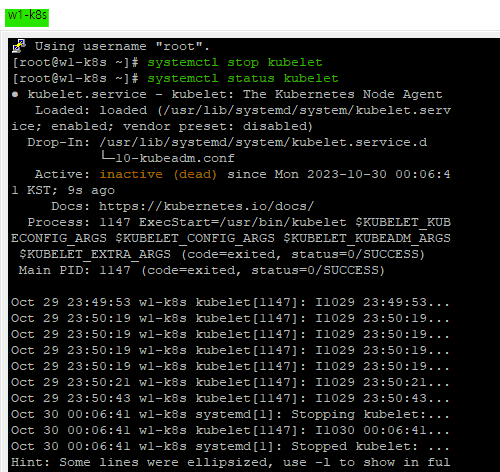
자식노드 쪽 kubelet이 멈춰진 것을 확인할 수 있다.
이제 작성해둔 yaml 파일을 통해서 마스터 노드에서 deployment로 파드들을 생성해보자.
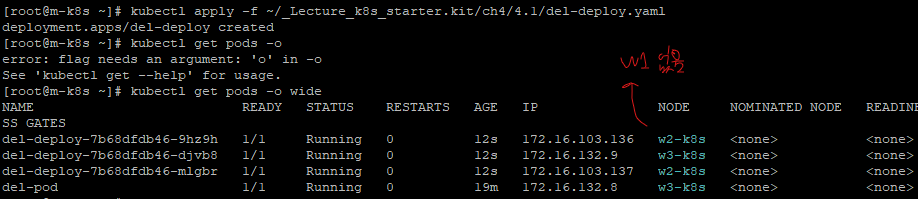
사실 원했던 결과는 w1에도 생성이되고, STATUS가 Pending 상태인 것을 원했는데..스케쥴러가 알아서 kubelet이 죽은 w1을 알아서 제외하고 w2, w3에만 자동으로 생성해줘버렸다. (버전이 올라가면서 더욱 문제 상황에 대한 대처가 좋아진 샘)
아무튼 kubelet이 문제가 생기면 정상적인 배포가 되지 않을 수 있다.
마무리
이제 실습이 종료되었으니, kubelet을 다시 켜주도록 하자.
systemctl start kubelet
컨테이너 런타임에 문제를 발생시켜 보자.

워커 노드 1번쪽에 다음 명령어를 입력해서 컨테이너 런타임 즉, 컨테이너를 생성해주고 관리해주는 친구를 정지시켜보자.
systemctl stop containerd
systemctl status containerd
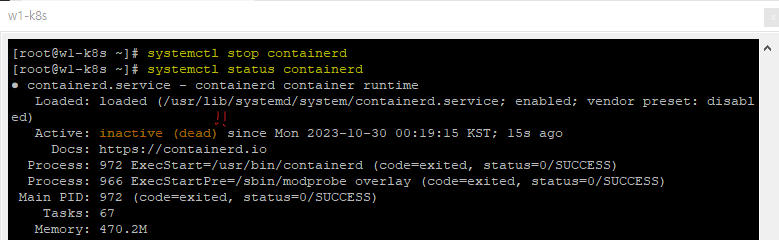
그리고 나서 replicas명령어를 통해 deployment 스케일을 키워보도록 한다.
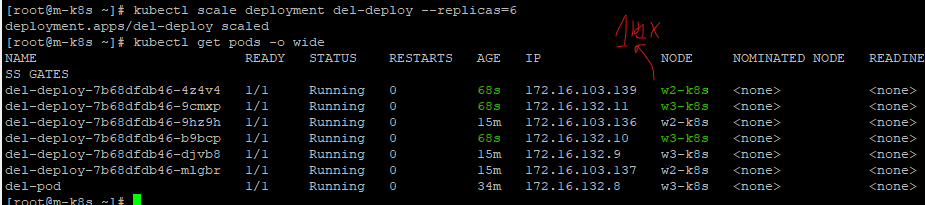
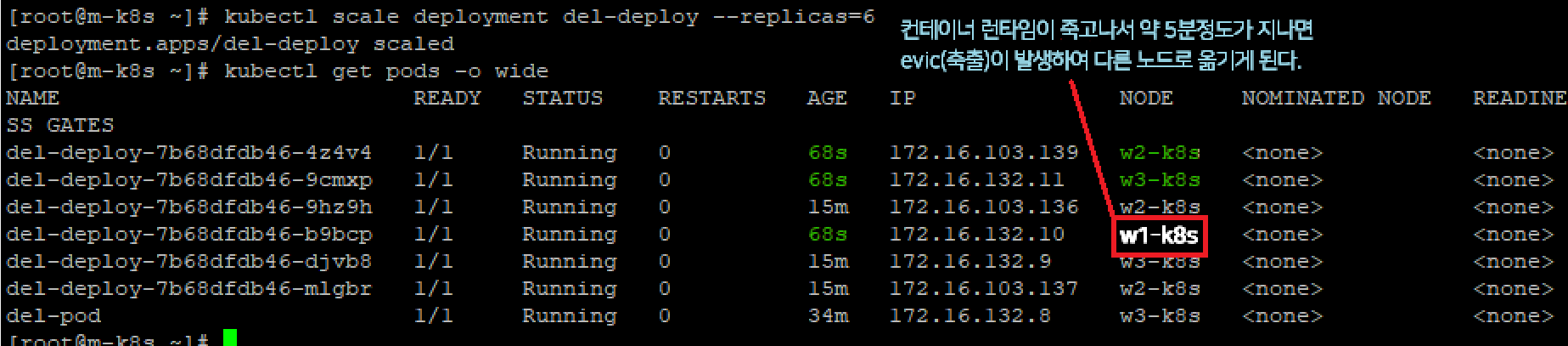
보이는가? 1번 워커노드의 컨테이너 런타임이 현재 동작하지 않으므로 스케쥴러에서 자동으로 다른 2, 3번 노드에 파드들을 생성해주었다.
evict (축출)
만약 이 때, 컨테이너 런타임이 죽었지만 해당 컨테이너를 사용하는 노드에 이미 파드가 배포되어있다면 어떻게 될까?
evict(축출) time인 5분이 지나고 난 뒤, 다른 노드(노드2 또는 노드3)로 이동된다.
스케쥴러의 재배포 전략
이제 스케쥴러가 어떻게 문제가된 상태를 감지하고, 균등하게 배포하고, 또 동작하는지를 알아보자.
systemctl start containerd
다시 워커 노드 1번의 컨테이너 런타임을 실행시켜주고

마스터노드에서 디플로이먼트로 배포된 노드들의 개수를 늘리면?
kubectl scale deployment del-deploy --replicas=9

6개에서 9개로 3개 늘어날 때, 워커노드 1번에만 3개가 전부 생성된 것을 확인할 수 있다.
이는 기본 스케쥴러의 전략인, best effort(가능한 균등하게)가 적용되어 아무것도 없이 텅 빈 워커노드 1번에 새롭게 3개의 노드가 추가된 것이다.
마스터노드에 문제가 생긴다면?
지금까지는 사실 워커노드의 kubelet(노드 내 파드관리)에 문제가 생기거나, 워커노드의 컨테이너 런타임(컨테이너 생성 및 관리)에 문제가 생기는 경우만 확인했다.
즉, 워커 노드 쪽 문제가 생기는 경우만 실습했다는 것인데 마스터노드에서도 충분히 문제가 발생할 수 있지 않을까?
바로 실습을 통해 확인해보자.
우리는 마스터 노드쪽에서 스케줄러를 삭제하여 마스터 노드쪽 문제를 발생시켜보자.
kubectl get pods -n kube-system -o wide
위 명령어를 통해서 마스터 노드의 kube-system 네임스페이스에 있는 파드들을 살펴보자.
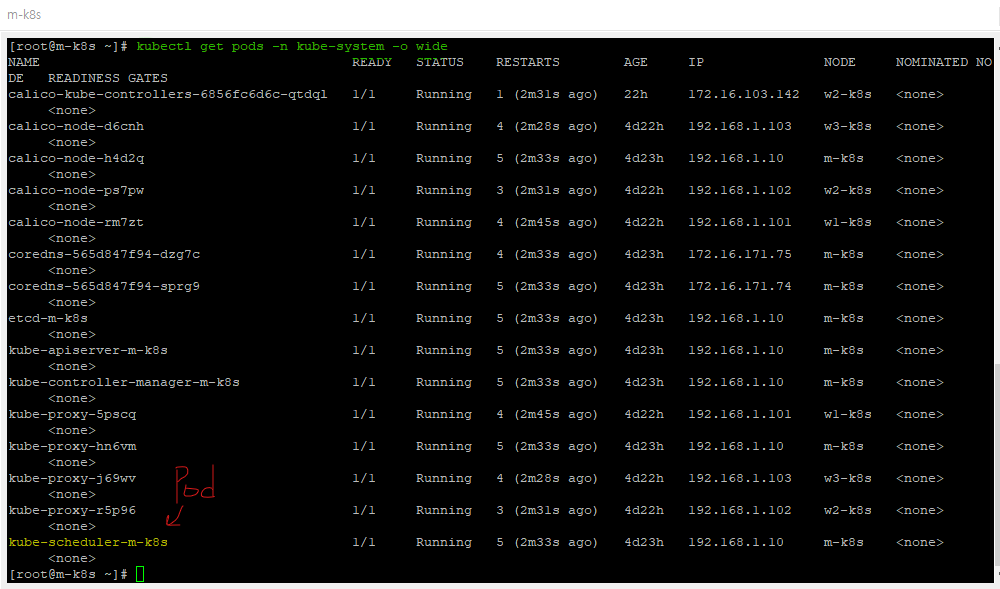
다음과 같이 파드들이 있는 것을 확인할 수 있다.
이 때, kube-scheduler-m-k8s가 바로 스케쥴러이다.
이러한 스케쥴러를 삭제하면 어떻게 될까?
kubectl delete pod kube-scheduler-m-k8 -n kube-system
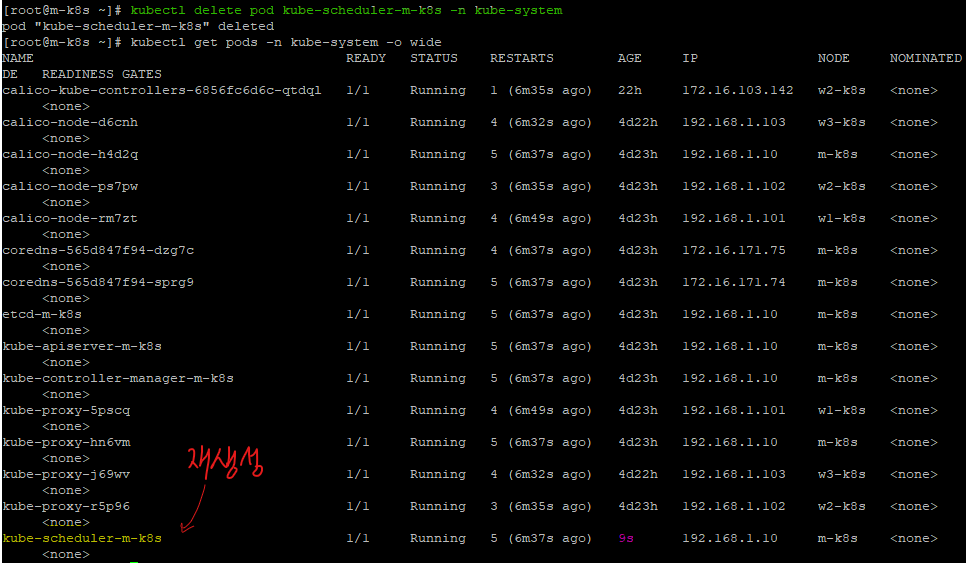
엇 삭제를 분명 했지만, 여전히 남아있는 것을 확인할 수 있다!
그렇다. 쿠버네티스에서는 마스터 노드에 있는 중요 요소들이 삭제되는 경우 자동으로 다시 만들어준다.
스케쥴러 말고, 다른 kube-system에 있는 pod들 또한 동일하다.
마스터 노드의 kubelet 정지 상황
그럼 마스터 노드에있는 kubelet이 멈추게 되면 어떻게 될까?
바로 해보도록 하자.
일단 kubelet을 멈춰 준 후,
systemctl stop kubelet
다시 스케쥴러를 지워준다.
kubectl delete pod kube-scheduler-m-k8s -n kube-system
스케쥴러를 지우는 명령어를 쳐도, 다음 줄로 넘어가지 않고 시스템이 멈춘듯이 무한정 기다리게 되는 상황이 발생한다.
- 무한정 시스템이 멈춰, 강제종료함

왜 이렇게 될까?
kubelet으로 명령이 전달되고 이를 통해서 삭제가 이루어져야 하는데, kubelet이 현재 정지(stop)된 상태이므로 해당 스케쥴러 파드를 지우는 명령이 수행되지 않아 수행되기 까지 멈추는 것이다.
스케쥴러의 상태를 보면 다음과 같이 Terminating 즉, 종료가 진행중인 상태로 멈춰있는 것을 확인할 수 있다.
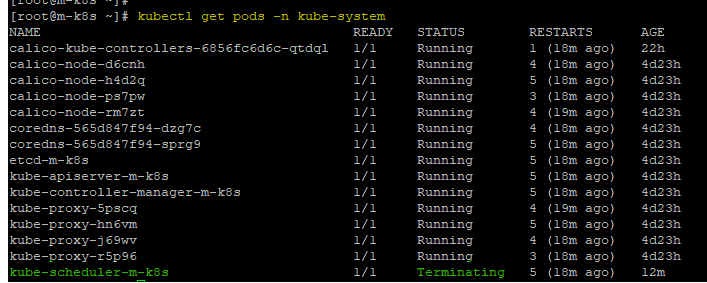
그럼 스케쥴러가 멈춰있으니, 파드의 생성도 안될까?
다음 명령어를 입력해보록 하자.
kubectl create deployment nginx --image=nginx
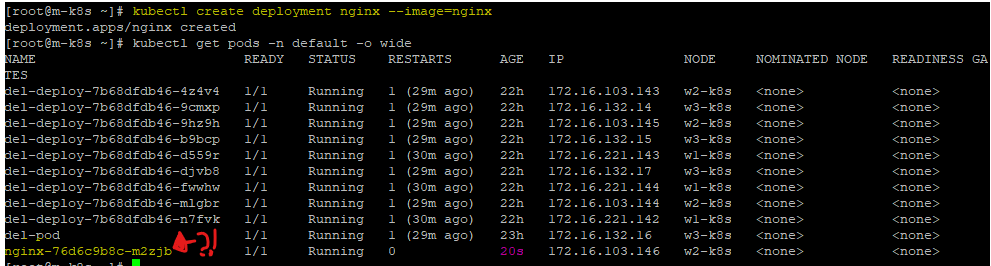
아니? 잘 생성되어있다?
그럼 replicas를 통한 scale을 변경은 동작할까?
kubectl scale deployment nginx --replicas=3
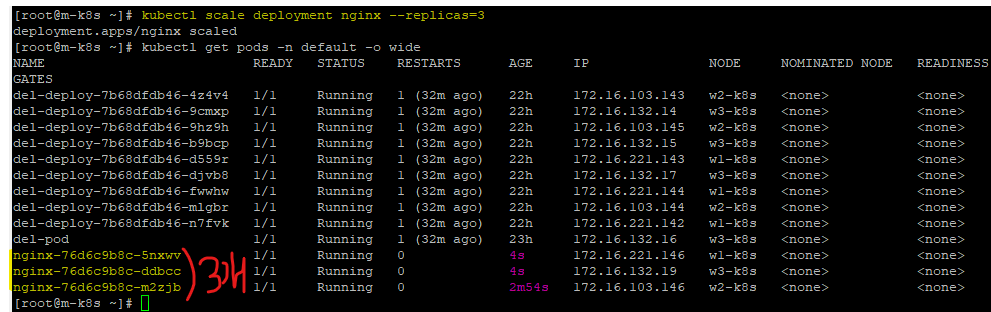
아니 이것 또한 잘 증가(동작)한다!
즉, 스케쥴러가 Termianting 상태이고, 마스터노드의 kubelet이 멈춰있는 상태이지만 정상적으로 스케쥴러가 동작한다는 것을 알 수 있다.
왜 그럴까?
이는 kubelet이 (InActive)상태 즉, 멈춰있기 때문에 스케쥴러를 삭제하는 명령어를 입력했더라도, 스케쥴러가 Terminating의 상태로 표시될 뿐. 실제 삭제는 일어나지 않는 것이다.
반대로 kubelet이 정상적으로 Active상태일 때는 실제 삭제가 되긴하나, 즉시 다시 스케쥴러가 생성된다.
결론
kubelet이 멈추든, 멈추지 않든 모든 동작(노드 배포, 스케일 변경, curl 접속 등)들이 정상적으로 작동한다.
그 이유는?
kubelet이 멈춰있기 때문에 스케쥴러 삭제를 시도해도, 삭제가 안되는 것이다.
노드를 배포하고, 스케일을 변경하고, 삭제하는 작업은 스케쥴러 + 컨트롤러 매니저가 하는 것이기 때문.
🎯 핵심 ➡ kubelet이 죽어도, 스케쥴러를 삭제한 적은 없기에 스케쥴러는 정상적으로 동작한다.
2. 마스터 노드의 컨테이너 런타임에 문제가 생긴 경우
마스터 노드의 컨테이너 런타임을 종료해보자.
systemctl stop containerd
systemctl status containerd
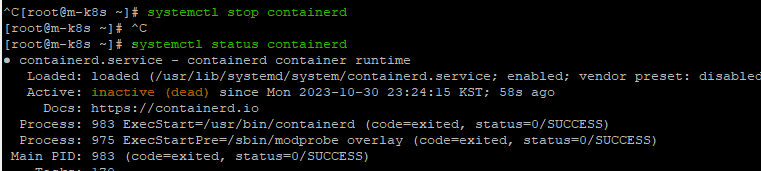
결과는? 정상작동!
사실 컨테이너 런타임에 문제가 생기면 안 되는게 맞다.
하지만, containerd 런타임이 죽더라도 마스터 노드의 중요한 kube-system의 pod들이 살아있기에 정상적으로 동작하게 된다. (조회 및 생성, 삭제 등)
pod 삭제
컨테이너 런타임(containerd)가 중지된 상태에서도, deployment나 pod를 정상적으로 지울 수 있다.
pod 생성
생성도 잘 된다.
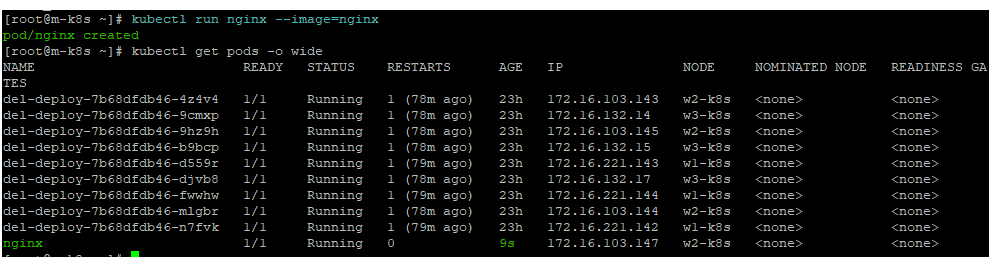
kubectl run nginx --image=nginx
- kubectl run 명령을 사용하면 YAML 매니페스트 파일을 직접 작성하지 않고도 빠르게 파드를 생성할 수 있다.
(주로 테스트 용으로 사용)
마스터 노드의 컨테이너 런타임 정지 상황에서 스케쥴러를 지우면?
그럼 다시 돌아가서 하나만 더 보자.
이전에 우리는 마스터 노드의 kubelet 정지 상황일 때, 스케쥴러를 지우는 명령을 수행하라고 해도 수행이 되지않아, 삭제가 되지 않고 정상 작동하는 것을 확인했다.
그럼 마스터 노드의 "컨테이너 런타임이 정지된 상황"은 어떨까?
정답은?
🎆 결국 컨테이너 런타임이 정지되어 있을 때도 동일하다.
마스터 노드의 컨테이너 런타임 정지 상황일 때도 스케쥴러를 지우는 명령을 수행하려고 해도, 수행되지 않기에, 결국 정상작동 한다.
이를 실제로 확인해보자.
컨테이너디를 멈춘 뒤, 스케쥴러를 지우는 명령어를 입력해보자.
systemctl stop containerd
kubectl delete pod kube-scheduler-m-k8s -n kube-system

Terminating 상황인 스케쥴러의 모습이 나타난다. (but, 정상 작동할 것임)
실제로 정상 작동하는 지, 테스트해볼 겸 파드를 생성해보자.
kubectl run nginx2 --image=nginx
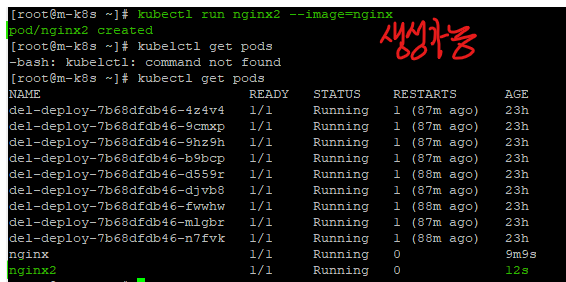
그렇다. 정상적으로 파드를 생성하는 것을 확인할 수 있다.
마무리
다시 이제 컨테이너 런타임을 실행시켜주도록 하자.
systemctl start containerd
systemctl status containerd
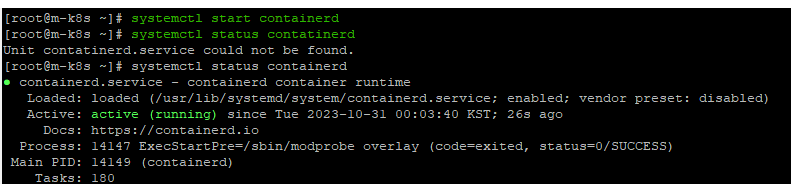
이제 컨테이너 런타임이 실행되었으므로 Terminating 상태가 다시 진행되기 시작할 것이다.
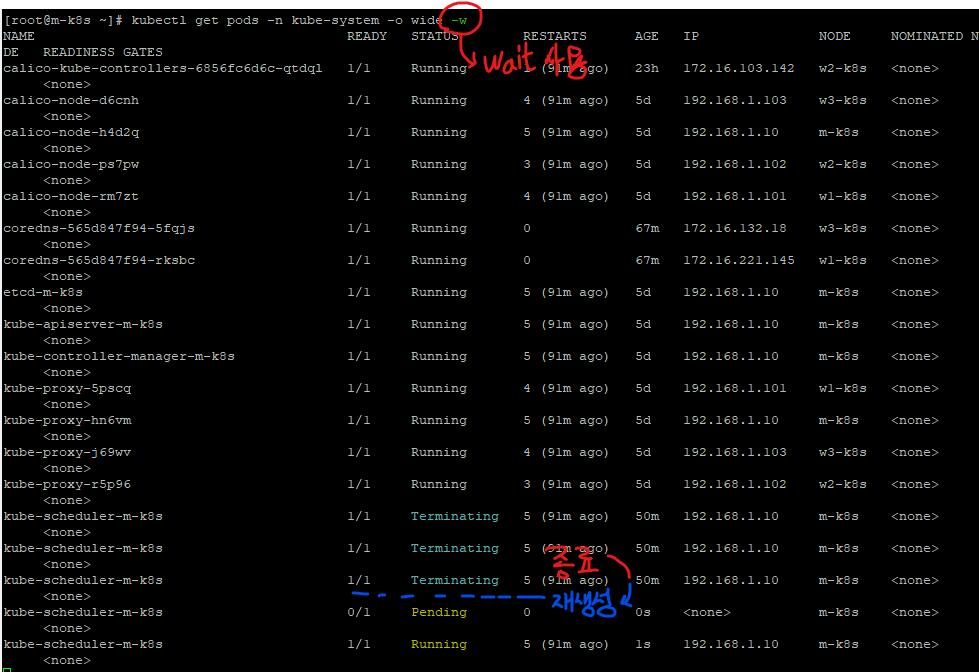
-w 명령어를 통해서 상태변화를 계속 관찰해보자.
kubectl get pods -n kube-system -o wide -w
정지 상태의 스케쥴러가 완전히 종료(삭제)되고, 다시 생성되는 것을 확인할 수 있다.
이러한 도커와 컨테이너 런타임(Containerd)에 관해서는 도커와 Containerd 런타임을 참고하라.
