역주: 이 포스트는 Julia Evans의 포스트 https://jvns.ca/blog/confusing-explanations/ 를 허락받아 번역하였음.
또한 원문의 뉘앙스를 살리려고 최대한 노력하였음. 한글 번역이 애매할 땐 그냥 영어를 쓰거나, 한글 옆에 괄호를 치고 영단어를 적어서 이해를 도우려고 하였음. 그 외의 괄호는 원문에 있는 것임.
원제목인 Patterns in confusing explanations을 어떻게 번역할까 한참 고민하다가 지금과 같은 제목이 되었음.
모두들 안녕! 저는 최근에 제가 뭔가를 설명하는 방법에 대해 고찰해 보았어요. 보통 저는 이런 식으로 글을 씁니다:
- 해당 주제(topic)를 공부한다
- 이해하기 힘든 온갖 설명들을 찾아 읽는다.
- 마침내 그 주제를 이해한다.
- 다른 사람에게 도움이 되길 바라며, 내가 이해할 수 있는 설명을 적는다.
대체 왜 저는 수많은 설명들을 난해하다고 생각하는 걸까요? 저는 그 이유를 찾아보기로 했어요! 그리고 마침내 이해하기 힘든 설명의 12가지 패턴 목록을 추려냈습니다. 각각의 패턴에 대해서 그 패턴을 피하기 위한 저의 요령도 같이 남겼습니다.
이 패턴들은 정말로 흔합니다
이 목록은 당신의 글을 저격하기 위해 만든게 아닙니다. 저도 이런 패턴대로 글을 써 왔어요! 그리고 또 그런 실수를 반복할거고요! 심지어 이 글을 적는 중에도 적어도 하나의 패턴을 사용해버렸어요.
하지만 제가 그런 실수를 할 지 모른다는 것을 인지하는 것만으로도 그런 상황을 피하기가 쉬워졌습니다. 또 덕분에 다른 사람들의 비판도 훨씬 잘 받아들일 수 있게 되었어요(이를테면 "줄리아, 이 글엔 내가 알거라고 전제하는 정보가 너무 많아요!").
이 패턴들을 잘 인지하고 있는건 난해한 글을 읽을 때에도 도움을 주었습니다: "음, 내가 지금 이 글을 이해 못하는 건 내가 멍청해서가 아니라 여기 나온 여섯 가지 새로운 개념이 전혀 설명되어있지 않기 때문이야!".
왜 이렇게 부정적인 프레임으로 글을 쓰는가
저는 거의 항상, 부정적인 프레임("X는 나쁩니다!") 대신 긍정적인 프레임("Y는 좋아요!")으로 글을 써 왔습니다. 그럼 제가 이번엔 긍정적인 패턴 대신 부정적인 패턴에 대한 글을 쓰는 이유는 뭘까요?
명료하게 글을 쓰는 건 정.말.로 중요한 작업입니다. 그리고 기술에 대한 난해한 설명 때문에 좌절할 때 저는 명료한 글을 써야겠다는 생각이 강하게 들고요("으, 리눅스 컨테이너에 대해 내가 읽은 것들은 모두 너무 난해해. X Y Z 차근차근 또박또박 설명해줄 사람 어디 없나...").
하지만 제가 주의를 기울이지 않는다면 기존처럼 난해한 패턴을 사용해 글을 쓸 가능성이 매우 높습니다! 그리고 긍정적인 패턴(예를 들면 "불필요한 용어를 소개하지 마라")에 대한 문제가 또 있는데, 그것들이 너무 당연한 것이어서 저 스스로가 마치 그것들을 잘 지키고 있는 것 같다는 착각을 들게 한다는 점이죠. 실제로는 아닌데도요! 그래서 저는 지금 저 스스로에게 정직해지기 위해서 이 리스트를 남기는 것이고, 바라건대 여러분도 이런 패턴들을 피할 수 있으면 좋겠습니다.
이제 패턴들을 봅시다!
이 글의 동기에 대해서 설명했으니, 이제 패턴을 설명할 차례군요! 여기 간단하게 인덱스를 준비했습니다*. 순서는 중요하지 않아요.
*역주: Velog에서는 우측에 index가 자동으로 생성되니 여기 목록은 생략합니다.
패턴 1: 독자가 올드한 지식을 갖고 있다는 가정
특히 시스템(systems) 관련해서, 독자가 올드한 지식을 갖고 있다는 가정하는 글을 정말 많이 봤습니다. 예를 들어, Git book이 Git과 다른 버전 관리 툴들 간 브랜칭(branching) 구현 차이에 대해 설명하는 부분을 봅시다.
❌ 거의 대부분의 VCS(Version Control System)는 어느 정도 브랜칭을 지원한다. [...] 대부분의 VCS 툴들에서 이것은 상당히 비싼 연산이고, 대부분의 경우엔 당신이 당신 소스 코드 디렉토리의 새 복사본을 만들도록 요구한다. 이런 작업은 큰 프로젝트에서 시간을 상당히 소요한다.
여기 나타난 가정은, 당신(독자)이 다른 VCS들의 브랜칭 구현에 대해 알고 있고 이것들과 Git의 구현 간 차이를 이해하는게 브랜칭 이해에 도움이 될거라는 것이죠.
하지만 당신이 이걸 읽는 사람인데 Git 외의 버전 관리 시스템을 써본 적도 없고, 쓸 계획도 없다면 이 설명은 쓸모없습니다! 대체 누가 다른 VCS들의 브랜칭 구현을 신경씁니까? 그냥 Git이 어떻게 작동하는지만 알고 싶다고요!
이 설명이 이런 식으로 쓰여진 것은 아마도 첫 번째 판이 2009년에 출시되었기 때문일 것입니다. 그리고 2009년엔 아마 그 가정이 옳았을 겁니다! Git이 릴리즈된 직후에 배운 사람들은 대부분 Subversion이나 CVS(Concurrent Versioning System)이나 다른 것으로부터 교체를 했을 거고, 위와 같은 비교가 도움이 많이 되었을 겁니다.
하지만 2021년에서 본 Git은 아주 오랜 기간동안 독보적인 지위를 차지하고 있는 VSC이고 Git을 처음으로 배우는 대부분의 사람들은 Git 외의 버전 관리에 대해 어떠한 경험도 없을겁니다.
저는 가끔 이 "독자가 올드한 지식을 갖고 있다는 가정" 문제를 요즘 글에서도 발견합니다. 보통은 글쓴이가 해당 개념을 수 년 전에 배웠다가 요즘 잘 쓰지 않을 때 발생해요. 즉 독자들도 2005년의 글쓴이와 엇비슷한 수준의 지식을 갖고 있을 거라고 가정하고 설명하며, 오늘날 그 개념을 공부하는 대부분의 사람들은 전혀 다른 지식을 보유하고 있다는 것을 깨닫지 못하는 것입니다.
대안: 자신의 설명을 테스트하세요!
일반적으로 제가 어떤 개념을 오래전에 배웠다면, 그걸 지금 처음 봤을 때의 감각을 모른다는 소리입니다. 그러므로 그 개념을 전혀 모르는 사람에게 시험삼아 설명해보세요. 그리고 잘못된 가정을 찾아내세요.
(제가 "그 개념을 전혀 모르는"에 볼드체를 적용한 것은 이미 해당 개념을 아는 사람에게 설명하려는 유혹이 정말 강렬하기 때문입니다. 하지만 그런 사람들은 이미 당신과 똑같은 가정을 하고 있을지도 몰라요!)
패턴 2: 독자의 지식에 대해 일관되지 않은 가정
예를 들면, 프로그래밍 언어 튜토리얼에서 거의 모든 프로그래머가 알 만한 개념을 설명한 후 (예를 들면, for loop가 interation에 어떻게 사용되는지) 많은 사람들이 모를 만한 내용을 설명 없이 진행하는 경우입니다(예를 들면, stack이나 malloc의 원리). (Dan Luu, 사례 고마워요!)
이 패턴의 문제는 malloc을 알면서 for loop을 모르는 사람이 거의 0에 수렴한다는 겁니다! 그리고 좀 바보같은 점인데, 설명하는 대상에 대한 명료한 생각이 자리잡지 않았을 때 이런 실수가 일어나기 쉽습니다.
대안: 특정한 한 사람을 골라 그 사람을 위한 글을 쓰세요!
친구나, 동료나, 과거의 자신도 좋습니다. 딱 한 사람만을 위한 글이라는 말을 들으면 너무 대중적이지 않다는 느낌이 들 수도 있지만 ("다른 모든 사람들은 어쩌고??"), 그런 글은 높은 확률로 다른 사람들도 이해하기 쉬울 겁니다.
패턴 3: 억지스런 비유
때때로 복잡한 기술 개념을 설명하려고 할때, 글쓴이는 독자가 반드시 알 만한 현실세계 개념을 가져와 비유와 비교로 개념을 풀어내려고 합니다.
제가 만든 예시를 보시죠:
❌ 이벤트 시스템을 미시시피 강이라고 해봅니다. 이 강은 다양한 생태계를 거치고 어떤 물방울들은 강물에서 떨어져 나가겠죠. 때때로 강은 주변 상황에 따라 속도가 다를 것입니다. 그리고 이 강은 여러 지류로 갈라질 거예요.
그리고 다양한 종류의 물고기들이 이벤트 시스템 안에 존재합니다. 각각의 물고기들은 각기 다른 목적지가 있죠. 인간들은 강과 함께 살기로 결정했고 여러 목적으로 강을 사용하기 시작했습니다. 또 유량을 통제하기 위해 댐을 설치했습니다.
이 예시는 패러디입니다만, 이런 타입의 비유들은 항상 난해하게 느껴집니다. 왜냐하면 결국엔 제가 이벤트 시스템과 미시시피 강 사이의 공통점과 차이점을 분석하는 데 시간을 소모하니까요. 그냥 이벤트 시스템에 대한 기술적(technical) 사실만 공부할 수도 있는데 말입니다.
제 생각에 글쓴이들이 이런 비유를 사용하는 건... 크고, 이상한, 비유를 쓰는게 꽤 재밌거든요! 이런거죠, "댐과 스트림 프로세싱 시스템 간에 공통점이 있나? 그럴지도!" 그런 생각은 정말 재밌죠! 하지만 쓸 때는 재밌을지 몰라도 읽을 땐 아닙니다. 사람들은 알고 싶은 사실을 추출하는 데에 많은 노력을 기울여야 해요.
대안: 딱 하나의 아이디어에 대해서만 비유하세요!
제가 이벤트 프로세싱 시스템이 어떻게 강과 똑닮아있는지 심도있게 비유한 것 같의 "큰" 비유를 사용하지 마세요. 저는 한 두 문장 안에서 아주 특정한 부분만 비유로 설명하고, 더는 그 예시를 언급하지 않습니다.
두 가지 방법을 알려드리겠습니다.
옵션 1: 은유(implicit metaphor) 사용하기
예를 들어, 제가 스트림(streams)에 대해서 얘기한다면 이런 식으로 쓰겠죠:
✅ 단일 스트림의 모든 이벤트는 프로듀서에서 컨슈머로 흐릅니다(flow).
저는 여기에서 "flow"라는 단어를 썼고 이건 명백하게 물을 이용한 은유입니다. 제가 볼 땐 아주 좋은 예시입니다. 아주 효과적으로 방향성에 대한 아이디어와 대량의 이벤트가 존재할 수 있다는 아이디어를 효과적으로 환기시켰거든요.
제가 전에 이런 종류의 메타포를 모아 글(Metaphors in man pages)을 썼었죠.
옵션 2: 매우 제한된 비유 사용하기
예를 들어, Jessica Kerr는 When costs are nonlinear, keep it small라는 글에서 빨래를 이용한 비유로 배칭(batching)을 나이스하게 설명했습니다.
✅ 우리는 배칭(몰아서 하기)을 좋아합니다. 배칭이 훨씬 효과적이니까요: 열 개를 한 번에 하는게 한 개, 한 개, 두 개, 한 개, 한 개, 이런식으로 하는 것보다 훨씬 빠릅니다. 저는 양말을 벗을 때마다 빨지 않아요. 그 양말을 계속해서 쌓아두는 건 전혀 힘들지 않으니까요.
이 비유는 아주 깔끔합니다! 제 생각엔 빨래를 배칭으로 하는 이유와 컴퓨터가 배칭을 하는 이유가 완벽하게 똑같기 때문인 것 같아요. 즉 양말을 쌓는 코스트가 매우 낮다는 거죠. 그리고 딱 하나의 아이디어에 대해서만 비유를 사용했죠. 새 아이템을 추가하는 비용이 낮을 때엔 배칭이 효과적이다는 아이디어.
패턴 4: 딱딱한 설명에 웃긴 일러스트 넣기
어떤 글쓴이들은 매력적이고 이해하기 쉬우라고 매우 딱딱한 설명에 웃긴 일러스트를 추가하더군요.
독자로 하여금 설명이 쉽게 느끼도록 속이는 것은 대개 좋은 목표가 아닙니다. 제 생각에 보통 이런 논리가 있는것 같아요. "사람들은 웃긴 일러스트를 좋아해! 그러니까 넣자!". 하지만 실제 의도에 관계없이 독자는 항상 끝에 가서 속았다는 기분이 들겁니다.
대안: 설명하는 방식에 따라 전체적인 모양새(design)를 잡으세요!
일러스트를 곁들인 설명 중 훌륭한 예시는 얼마든지 있습니다. 그런 글들은 명료하고 친근한 말투로 쓰여있죠.
하지만 딱딱한 설명도 역시 유용하긴 마찬가지입니다! Intel instruction-set reference가 읽기 쉬울거라고 기대하는 사람도 없지요! 이 레퍼런스는 딱딱하고, 기술적(technical)이고, 전체적으로 매우 실용적인 모양새를 채택했습니다. 글 내용과 딱 맞아떨어지죠.
패턴 5: 비현실적인 예제
파이썬 lambda에 대한 비현실적인 예제를 보여드리겠습니다:
# ❌
numbers = [1, 2, 3, 4]
squares = map(lambda x: x * x, numbers)대부분의 사람들은 파이썬에서 map을 쓰지 않기 때문에 이 예제는 비현실적입니다. 대신 list comprehensions을 쓰죠.
Oracle docs에 나온 인터페이스에 대한 또다른 예시를 봅시다.
# ❌
interface Bicycle {
// wheel revolutions per minute
void changeCadence(int newValue);
void changeGear(int newValue);
void speedUp(int increment);
void applyBrakes(int decrement);
}이런 종류의 "현실 세계 예제"는 객체 지향 프로그래밍 예제에서 아주 흔하게 발견되는데 제가 볼 때는 그저 난해할 뿐입니다. 저는 단 한 번도 자전거나 차를 코드로 구현해본 적이 없어요! 그래서 이 설명은 인터페이스의 유용성에 대해 아무런 영감도 주지 못하고요!
대안: 현실적인 예제를 사용하라!
파이썬 lambda에 대한 현실적인 예제를 가져와 봤습니다. 리스트의 원소들을 나이 기준으로 정렬하는 람다식이죠. (저의 글 Write good examples by starting with real code에서 발췌) 실무에서 저는 람다를 이렇게 씁니다.
# ✅
children = [
{"name": "ashwin", "age": 12},
{"name": "radhika", "age": 3},
]
sorted_children = sorted(children, key=lambda x: x['age'])자바 인터페이스에 대한 예시도 볼까요.
// ✅
// Comparable* 인터페이스는 딱 하나의 메소드만 가지고 있습니다. 전체 코드는 다음과 같습니다.
public interface Comparable<T> {
int compareTo(T o);
}
// 이 인터페이스를 구현하기 위해선 단지 `compareTo` 메소드만 구현하면 됩니다.
// 그리고 만약 어떤 클래스가 이 인터페이스를 구현하고 있다면 (예를 들면 `Money` 클래스),
// 그 즉시 다양하고 유용한 것들을 사용할 수 잇습니다!
// `Arrays.sort`로 Money 객체 배열을 정렬할 수 있고, 그 배열을 `SortedSet`에 넣을 수도 있습니다!* JDK source에서 확인 가능
위 예시는, 자바 인터페이스를 설명하기엔 부족하죠. 실제로는 인터페이스를 직접 만드는 실질적인 예제도 필요할 겁니다. 하지만 이 글은 자바 인터페이스를 위한 건 아니니까 넘어가죠.
패턴 6: 아무 의미 없는 용어(jargon)
커밋 서명(Commit signing)의 한 챕터를 봅시다:
❌ Git은 암호학적으로 안전하지만(cryptographically secure), 완전하지는(foolproof) 않습니다.
여기서 "암호학적으로 안전"은 굉장히 모호한 표현인데, 마치 그게 무슨 특정한 기술적 의미처럼 들리기 때문입니다. 하지만 그게 대체 무엇인지 어디에도 설명이 없죠. 지금 이 문장이 Git은 SHA-1 암호화로 커밋을 해싱하고 이 경우 해싱 충돌이 거의 일어나지 않는다는 말일까요? 글쎄요!
대안: 필요하지 않으면 용어를 쓰지 마세요!
전 이상한 용어를 쓰지 않고도 제게 필요한 커뮤니케이션을 할 수 있다는 것을 아주 많이 확인했습니다. 예를 들어, 저라면 커밋 서명이 중요한 이유를 이렇게 설명하겠어요:
✅ Git 커밋을 만들 때, 당신은 당신 마음대로 이름과 이메일을 설정할 수 있습니다! 예를 들어, 지금 당장에라도 제가 리누즈 토발즈인척 이런 커밋을 만들 수 있다는 거죠:
git commit -m"Very Serious Kernel Update" --author='Linus Torvalds <torvalds@linux-foundation.org>'
패턴 7: 핵심 정보 누락하기
개념에 대한 설명에 핵심 아이디어가 빠지는 경우가 더러 있습니다. Git 객체 모델(Object model)에 대한 이 챕터을 봅시다:
❌ Git은 컨텐츠 참조가능(content-addressable) 파일시스템입니다. 좋아요. 그게 무슨 뜻일까요? 그 말인즉슨 Git의 코어엔 심플한 키-밸류 데이터 저장소가 있다는 얘기입니다. 따라서 당신은 어떤 종류의 컨텐츠라도 Git 레포지토리에 삽입할 수 있고 그 결과로 Git은 당신에게 그 컨텐츠를 참조할 우 있는 유니크한 키를 제공합니다.
이 단락은 컨텐츠 참조가능한 스토리지에 대한 핵심 아이디어가 누락된 것처럼 보입니다. 그 아이디어란, 컨텐츠 각각의 키 값이 해당 컨텐츠에 대한 결정적 함수(deterministic function)*라는 점이죠. 즉 해시 말입니다(위 글에서도 Git이 SHA-1 해시를 쓴다는 점을 뒤에 언급하긴 합니다). 키가 단순히 랜덤 유니크 값이 아니라 컨텐츠에 대한 함수라는 건 아주 중요한 부분인데, 컨텐츠가 그 컨텐츠 자체에 의해서 참조된다는 말은 컨텐츠가 바뀔 때 키도 같이 바뀐다는 뜻이기 때문입니다.
*역주: 결정적 함수는 이 글을 참고하세요.
독자 입장에서는 이 패턴을 인지하기가 굉장히 어렵습니다. 왜냐하면, 뭐가 핵심 요소인지 모르는 상태에서 어떻게 핵심 아이디어가 빠졌는지를 알 수 있겠어요? 그러므로 이 패턴은 특히나 해당 주제를 잘 알고있는 리뷰어가 필요한 항목입니다.
패턴 8: 한 번에 많은 개념 소개하기
여기 링커(linker)를 난해하게 설명하는 예제가 있습니다:
❌ 링킹 과정에서, 링커는 커맨드라인에 명시된 모든 오브젝트 모듈을 픽업하고, 앞부분에 시스템에 따라 달라지는 스타트업(startup) 코드를 추가하고, 다른 오브젝트 파일들(이는 커맨드라인에 언급되었을 수도 있고 라이브러리들에 의해 간접적으로 추가되었을 수도 있음)의 외부 정의(external definition)를 사용해 오브젝트 모듈 안의 외부 참조를 리졸브하려고 시도합니다. 그리고 나서 각 오브젝트 파일에 대해 로드 주소값(load address)을 할당하는데 그 말인즉슨 코드와 데이터가 최종 프로그램 어디에 위치할지 결정한다는 말입니다. 로드 어드레스가 확보되면, 오브젝트 파일은 해당 오브젝트 코드 속 모든 심볼릭 어드레스(symbolic address)를 타겟의 어드레스 공간 내 "실제(real)", 즉 숫자(numerical) 어드레스로 대체할 수 있습니다. 이제 프로그램은 실행될 준비가 완료되었습니다.
이 단락에 나타난 개념들을 봅시다:
- 오브젝트 모듈 (
.o파일) - 외부 참조
- 심볼릭 참조
- 로드 어드레스
- 시스템에 따라 달라지는 스타트업 코드(system-specific startup code)
너무 많아요!
대안: 각각의 개념에 숨 쉴 공간을 주세요!
예를 들어, 저라면 "외부 참조"를 이렇게 설명하겠어요:
✅ 예를 들어
objdump -d myfile.o를 실행한다면call함수 호출 라인에 타겟 어드레스가 없는 것을 볼 수 있습니다. 바로 이때 링커가 그 공간을 메꿔줍니다.33: e8 00 00 00 00 call 38 ^^^^^^^^^^^ 여기 주소가 전부 0입니다. 실제로 호출해야 하는 함수의 주소를 채워주는 역할이 바로 링커의 역할입니다! 38: 84 c0 test %al,%al 3a: 74 3b je 77 3c: 48 83 7d f8 00 cmpq $0x0,-0x8(%rbp)
아직 많은 정보가 더 필요해보입니다만 (그 주소값을 링커가 어떻게 알죠?), 이렇게 시작하는 것이 훨씬 명확하고 사람들에게 질문할 거리를 던져줍니다.
패턴 9: 추상적인 요소부터 설명하기
위키피디아의 정의를 사용해서 리눅스 시그널(Signal)을 당신에게 설명해볼까요.
❌ 시그널은 내부 프로세스 커뮤니테이션(inter-process communication, IPC)의 특정한 형태로서, 일반적으로 유닉스, 유사 유닉스(Unix-like), 그리고 그 외 POSIX-호환 운영체제에서 사용됩니다. 시그널은 프로세스나 동일 프로세스 내 쓰레드로 전송되는 비동기 알림(asynchronous notification)이며 이벤트를 알리는 역할을 합니다. 시그널은 1970년대 Bell labs Unix에서 유래되었으며, 이후 POSIX 스탠다드에 명시되었습니다.
당신이 시그널을 처음 들어본다면 이 내용 자체로는 아무런 도움도 되지 않겠죠! 매우 추상적이고, 전문 용어도 많고 ("비동기 알림", "내부 프로세스 커뮤니케이션"), 실제로 이게 어떻게 쓰이는지에 대한 정보는 전혀 없습니다.
당연히, 위키피디아 설명을 단순히 "나쁘다"라고 말하면 안되겠죠. 시그널을 전혀 모르는 사람에게 설명해주기 위해서 이 문서가 쓰여진 건 아닐테니까요.
대안: 구체적인 요소부터 설명하기
예를 들어, 몇 년전에 시그널에 대해 포스팅*한 적이 있습니다.
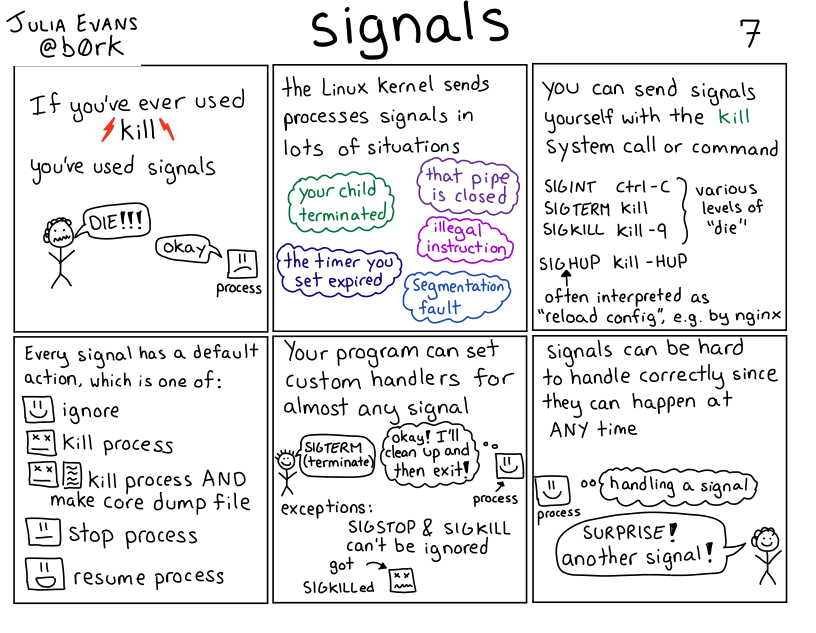
*역주:
(1) kill 커맨드를 써보셨다면 당신은 시그널을 사용해 본겁니다. ("죽어!", "그랭")
(2) 리눅스 커널은 다양한 상황에서 시그널을 보냅니다. (자식 프로세스가 죽음, 설정한 타이머가 만료됨, 해당 파이프가 닫힘, 잘못된 지시, 세그멘테이션 폴트)
(3) 당신은 스스로에게 시그널을 보낼 수 있어요. kill 시스템 콜이나 아래와 같은 커맨드들로요. (다양한 레벨의 die, 자주 "설정 리로드"로 쓰임, 예를 들면 nginx)
(4) 각 시그널은 디폴트 액션이 있습니다. 이것들 중 하나요: 무시, 프로세스 킬, 프로세스 킬 그리고 코어 덤프파일 생성, 프로세스 중지, 프로세스 재개)
(5) 당신의 프로그램은 대부분의 시그널에 대해 커스텀 핸들러를 만들수도 있어요. ("SIGTERM (종료)", "그래! clean up 후 exit 할게!") 예외: SIGSTOP, SIGKILL은 무시가 안됩니다. (SIGKILL 당함)
(6) 시그널은 아무때나 발생할 수 있기 때문에 정확하게 핸들링하기 어렵습니다. ("시그널 핸들링 중" "짜잔! 또 다른 시그널!")
저는 시그널의 작동방식을 설명하기 전에 독자의 경험과 관련있는 시그널을 먼저 언급했습니다("kill 커맨드 써본적있어요? 당신은 이미 시그널을 사용했어요!")
패턴 10: 근거 없이 주장하기
여기에 언급된 C 헤더 파일의 예시를 봅시다:
❌ 모던 C에서, 헤더 파일은 아주 중요한 도구이므로 반드시 정확하게 디자인되고 사용되어야 합니다. 헤더 파일은 컴파일러가 프로그램의 컴파일된 부분들 각각을 독립적으로 교차검사(cross-check) 하도록 돕습니다.
헤더는 일련의 facilities에 딸린 컨슈머들이 요구하는 타입, 함수, 매크로 등을 정의합니다. facilities가 사용하는 모든 코드는 헤더를 포함하고 있습니다. facilities를 정의하는 코드도 헤더를 포합하고 있습니다. 이로 인해 컴파일러는 실제 사용과 정의(the uses and definitions)가 일치하는지 확인할 수 있습니다.
여기선 "모던 C에서, 헤더 파일은 아주 중요한 도구..." (실제로 그렇습니다)라고 말하지만, 왜 헤더 파일이 그토록 중요한지는 설명하지 않고 있습니다. 당연히 독자가 잘 알고 있다면 전혀 문제가 아니겠죠(매우 기초적인 개념이죠!). 하지만 이 단락의 핵심은 헤더 파일을 설명하는 것이므로, 설명하는게 맞습니다.
대안: 그 말이 참임을 증명하세요!
예를 들어, 저라면 이렇게 쓰겠어요:
✅ 거의 모든 C 프로그램은 헤더 파일을 포함하고 있습니다. 예를 들어,
#include <stdio.h>를 C 코드 최상단에 적어보셨나요?stdio.h가 바로 해더 파일입니다.#include는 간단히 말하자면 C 전처리기에게stdio.h의 내용물을 이 코드 상단에 붙여넣기 하라는 뜻입니다.헤더 파일이 중요한 이유 중 하나는 헤더 파일이 당신 프로그램에 필요한 타입과 상수를 정의하기 때문입니다. 예를 들어, 아래 코드는
error: unknown type name 'FILE'에러가 나면서 컴파일에 실패할텐데,FILE이 정의되지 않았기(undefined) 때문입니다.int main() { FILE *fp; fp = fopen("data.txt", "w"); }
FILEstdio.h에 정의되어 있으므로 당신이#include <stdio.h>를 코드 상단에 입력하면 프로그램은 정상적으로 컴파일 될 것입니다.
이 예제 프로그램은 독자가 실제로 직접 돌려볼 수 있고, 컴파일 되지 않는 것도 확인할 수 있습니다. 제가 굳이 설명하지 않더라도 말이죠!
패턴 11: 예시 안쓰기
패턴 10의 헤더 파일 설명 예제에서 드러나는 또다른 문제점은, 예시가 하나도 없다는 것입니다! 예시를 없애면 독자가 새로운 개념과 이미 가지고 있던 경험을 연결하는 데 상당히 어려워집니다.
C 프로그램을 작성해 본 대다수의 사람들은 분명 헤더를 써보긴 했을 겁니다. 그러므로 간단한 예시(제가 언급한 stdio.h라던지)는 굉장히 도움이 됩니다.
헤더 파일 예제에서 저는
❌ 모던 C에서, 헤더 파일은 아주 중요한 도구...
를 간단한 예시가 포함된 설명으로 교체했습니다:
✅ 거의 모든 C 프로그램은 헤더 파일을 포함하고 있습니다. 예를 들어,
#include <stdio.h>를 C 코드 최상단에 적어보셨나요?
패턴 12: "잘못된" 방식을 경고 없이 설명하기
튜토리얼들에서 가끔 이런 패턴이 보입니다(아쉽게도 예제가 없네요):
- "잘못된" 방식이라고 미리 말하지 않은 채, 잘못된 방식을 설명해준다.
- 나중에 되서야, "잘못된" 방식으로 할 경우 생기는 부작용(consequences)을 보여준다.
- "옳은" 방법을 설명한다.
아마 현실세계에서의 잘못된 의사 결정을 흉내내려는 의도 같습니다. 보통 뭔가를 실수한다는 건, 그 순간에 그게 잘못되었다는 걸 모른다는 뜻이니까요!
하지만 대부분의 독자들은 속았다는 기분이 들거나 "옳은" 방법이 뭔지에 대해 혼란스러워 할 것입니다. 생각해보니 독자들은 애초에 그런 실수를 한 번도 안 저질렀을 수도 있잖아요!
대안: 실수를 보여주는 4가지 기법을 활용하세요!
독자를 속이지 않으면서 같은 효과를 보는 몇 가지 기법들이 있습니다:
- "잘못된" 행동을 일종의 실험으로 포장하세요. ("이걸 이런 식으로 처리하면 어떻게 될까요?")
- 독자가 생각할 법한 잘못된 생각을 언급하세요. ("당신은 아마 커맨드라인 도구가 root 권한으로 실행되어야만 한다고 생각할지도 모릅니다. 커널에 말하는 꼴이니까요. 하지만...")
- 흔히 저지르는 실수를 설명하세요. (예를 들어 Effective Python에 언급된 "Striding과 Slicing을 한 식에서 같이 쓰지 마시오"*)
- 당신이 실제로 저지른 실수에 대한 이야기를 한 뒤, 어떤 문제가 발생했는지를 말하세요. (제걸 참고하세요: Why Ruby’s Timeout is dangerous (and Thread.raise is terrifying))
*역주: 여기에서 내용을 확인할 수 있습니다. (예제를 보여주라는 말 같습니다)
실수에 대해 얘기하는 것은 매우 중요합니다만, 그게 실수라는 것을 사전에 미리 언급하세요!
패턴 13: "왜"를 빼놓고 말하기*
*역주: 패턴 10(근거없이 주장하기)와 달리, 여기선 '
저는 왜 사람들이 그 기술을 쓰냐를 말하는 대신 새 기술의 피쳐 리스트를 소개하는 사람을 정말 많이 봤습니다.
예를 들어, 쿠버네티스 홈페이지에는 쿠버네티스의 피쳐가 쫙 적혀있죠: 자동화된 롤아웃과 롤백, 서비스 디스커버리, 로드 밸런싱, 스토리지 오케스트레이션, 시크릿과 컨피그 관리, 자동화된 빈 패킹(bin packing), 기타 등등 말이죠. 프로젝트 홈페이지에는 더할 나위없이 적절합니다만, 그 자체로는 쿠버네티스가 지금 누군가의 팀에 적절한 도구인지 아닌지를 설명해주지 못합니다.
제 생각에 글쓴이들이 "왜"를 설명하지 않는 것은 하나의 단순하고 보편적인 이유를 찾기가 어렵기 때문인 것 같습니다. 말하자면 "왜 사람들이 쿠버네티스를쓰는가?" 같은거요. 당연히 수많은 이유들이 있습니다! 그리고 만약 "왜"를 잘못 설명하면 눈에 쉽게 띌 것이고 그건 꽤 부끄럽겠죠. 따라서 그냥 피쳐들만 보여주고 마무리하는게 안전하다고 느꼈을 겁니다.
하지만 독자의 입장에서 볼 때, 저는 아주 약한 근거의 "왜"라도 없는 것 보다는 낫다고 생각합니다. "흠, 세련된 기본 배포 시스템과 GKE를 지원한다는 말은 우리가 서버에 대해서 생각하지 않아도 된다는 소리니까 우리 팀에선 쿠버네티스트를 써야겠군"라고 생각하며 읽는게, 쿠버네티스를 쓰는 모든 회사들의 비즈니스적 근거를 확인하는 것보다 나아 보입니다.
대안: 그 기술을 사용해야 할 근거를 얘기하세요!
물론, 그 기술이 해결하는 명료하고 보편적인 문제점이 있다면 그걸로 충분하지요. 그렇지만 제 생각에 대부분의 경우 저자들은(저도 포함해서!!) 다른 사람들이 왜 그 기술을 쓰는지 깊게 생각하지 못하고 있는 것 같아요. 그것도 괜찮습니다!
만약 당신이 보편적인 "왜"를 내놓을 자신이 없다면, 솔직하게 얘기하고 당신만의 개인적인 경험을 예시로 언급하세요.
예를 들어, 저라면 쿠버네티스를 이렇게 설명하겠죠:
✅ 제가 쿠버네티스로 해결한 문제는 단 하나입니다: 우리는 분산 크론잡 시스템(Chronos)을 쓰고 있는데 기존에는 신뢰성이 좋지 못했습니다(크론잡들은 때때로 그냥 작동을 안해요). 그래서 저희는 쿠버네티스로 시스템을 교체했습니다. 쿠버네티스의 분산 크론은 훨씬 신뢰성이 높았거든요.
이건 일반적으로 사람들이 쿠버네티스를 쓰는 대표적인 예시가 명백하게 아닙니다. 그렇지만 저는 그간 이러한 개인적인 이야기들을 읽는게 한 두 문단 안에 쿠버네티스 사용사례를 우겨넣은 문서들보다 훨씬 더 도움이 되었습니다.
분명히 해두자면, 여러분의 개인적인 사례를 설명하는 것도 결코 쉬운 일이 아닙니다. 기술 프로젝트들은 금방 지저분해지고, 때때로는 목표 자체가 중간에 바뀌어버리기도 합니다. 저는 전에 Envoy를 쓰는 이유를 예시로 설명해보려고 노력했었는데, 제가 그 설명을 일관되게 하려면 수 시간의 고찰 및 시니어들과의 대화가 필요하다는 사실을 깨달았습니다*. 그래서 결국 다른 예시를 쓰기로 했죠.
*역주: 설명하려는 개인적인 비지니스 로직이 매우 복잡하다는 것을 깨달았다는 말 같습니다.
일단은 여기까지입니다!
처음에 저는 이 패턴들을 요약하는게 쉬울 것 같았어요("난해한 설명들이 참 많더군요!" 정도로 말이죠). 하지만 정확하게 어떤 점이 저에게 어렵게 다가왔는지를 설득력있는 예시와 함께 설명하는 것은 놀라울만큼 어려웠네요.
분명 이게 끝은 아닐겁니다만, 이미 2주의 시간과 3000 단어를 썼으니 일단 여기서 멈추고, 제가 놓친 부분을 귀담아 듣도록 해보겠습니다 :)
thanks to Laura, Dan, Kamal, Alyssa, Lindsey, Paul, Ivan, Edith, Hazem, Anton, and John for helping improve this post
