Multiprocessor Scheduling
-
멀티코어 프로세서의 등장은 멀티프로세서 스캐줄링의 확장의 요인이다.
- 멀티코어 : 다중 CPU코어들은 단일 칩에 패키징 되어있다.
-
CPU(코어)를 더 추가하는 것은 단일 응용프로그램을 더 빠르게 만들지는 않는다. -> thread들을 이용하여 응용프로그램이 병렬로 수행될 수 있도록 다시 적어야 한다.
-
그럼 멀티코어 CPU에서 어떻게 작업을 스캐줄 할 수 있을까?
Single CPU with cache
- Cache(CPU칩 안에 존재)
- 작고 빠른 메모리
- 메인 메모리에서 발견된 유용한 데이터들의 복사본을 가지고 있다.
- 시간적, 공간적 locality를 가지고 있다.
- 예를 들어 메인 메모리에서 1번 수행이 실행되었을때 리스트 옆의 2번/3번....16번까지 캐시로 가져온다.
- Main Menory
- 모든 데이터를 가지고 있다.
- 메인메모리로의 접근이 캐시로의 접근보다 느리다.
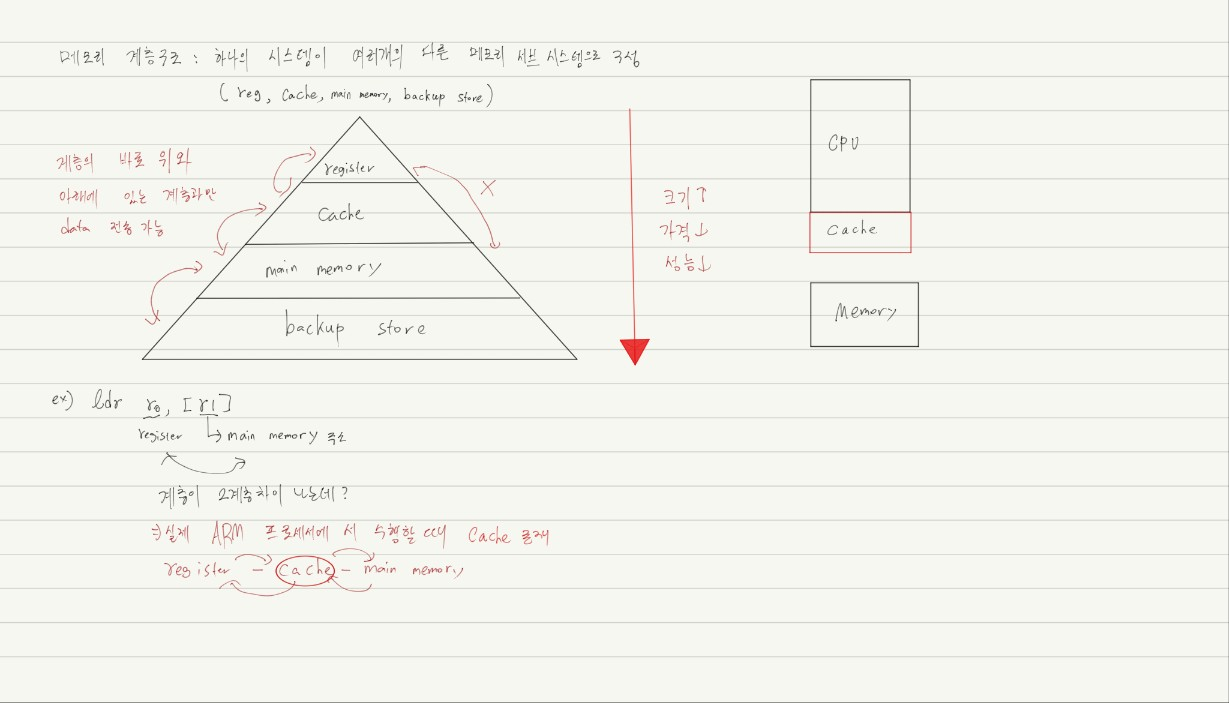
- 캐시가 데이터를 가지고 있음으로써 시스템은 느린 메모리가 빠르게 작동한다고 느끼게 한다.
Cache coherence(캐시 일관성)
- 여러 캐시에 저장된 공유 리소스 데이터의의 일관성이다.
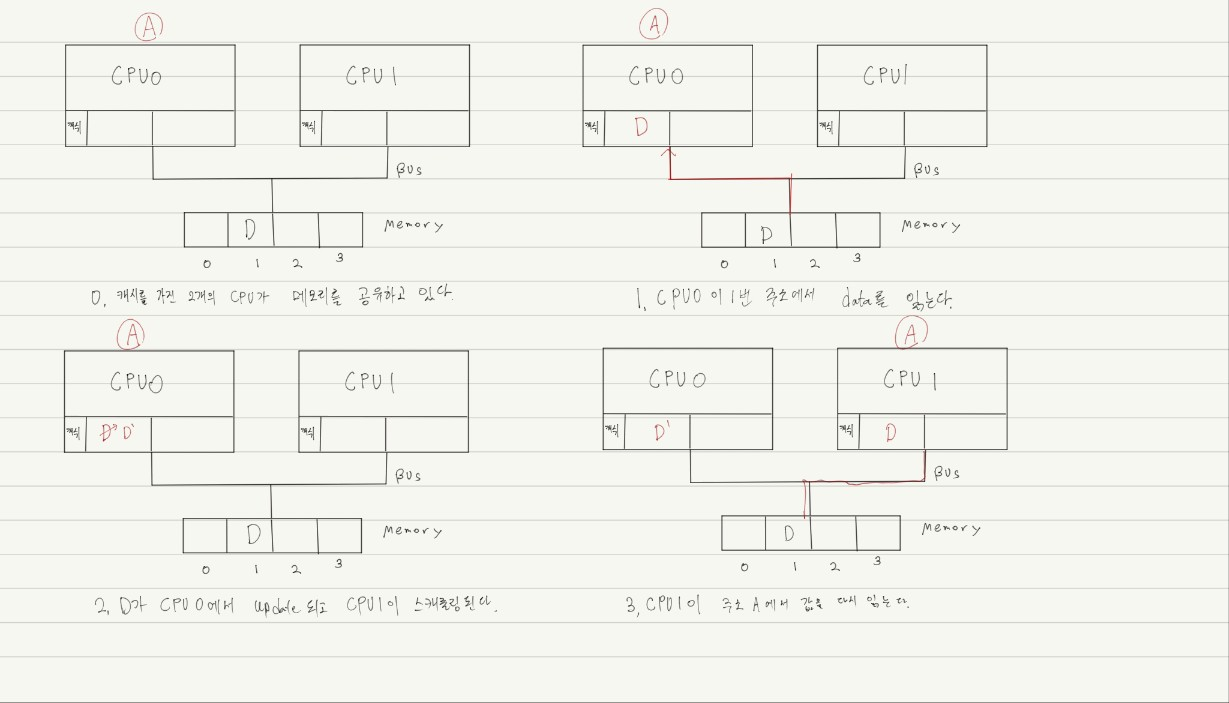
-
위 그림을 보았을 때 2번 과정에서 CPU0에서 D가 D'으로 업데이트 되었음에도 캐시에서 메모리로의 업데이트가 느려서 메모리에 업데이트를 하지 않게된다. ->이를 write back방식 이라고 한다.
-
CPU1은 바뀐값 D'이 아닌 옛날 값 D를 가지게 된다. 이를 캐쉬 일관성 문제라고 한다.
-
write back : 캐시의 수정이 메모리에 바로 업데이트되지 않는 방식
-
write through : 캐시의 수정이 메모리에 바로 반영이 되는 방식
Cache coherence 해결책
- Bus snooping(write-through)
- 각 캐시는 버스를 관찰하여 메모리 업데이트에 집중한다.
- CPU가 캐시에서의 데이터 요소들의 업데이트를 포착한다면, 해당 복사본을 무효화하거나 업데이트한다.
동기화에 유의
- CPU들의 공유된 데이터들을 접근할 때, 초기의 상호배제는 정확도를 보장하기 위해 사용된다.
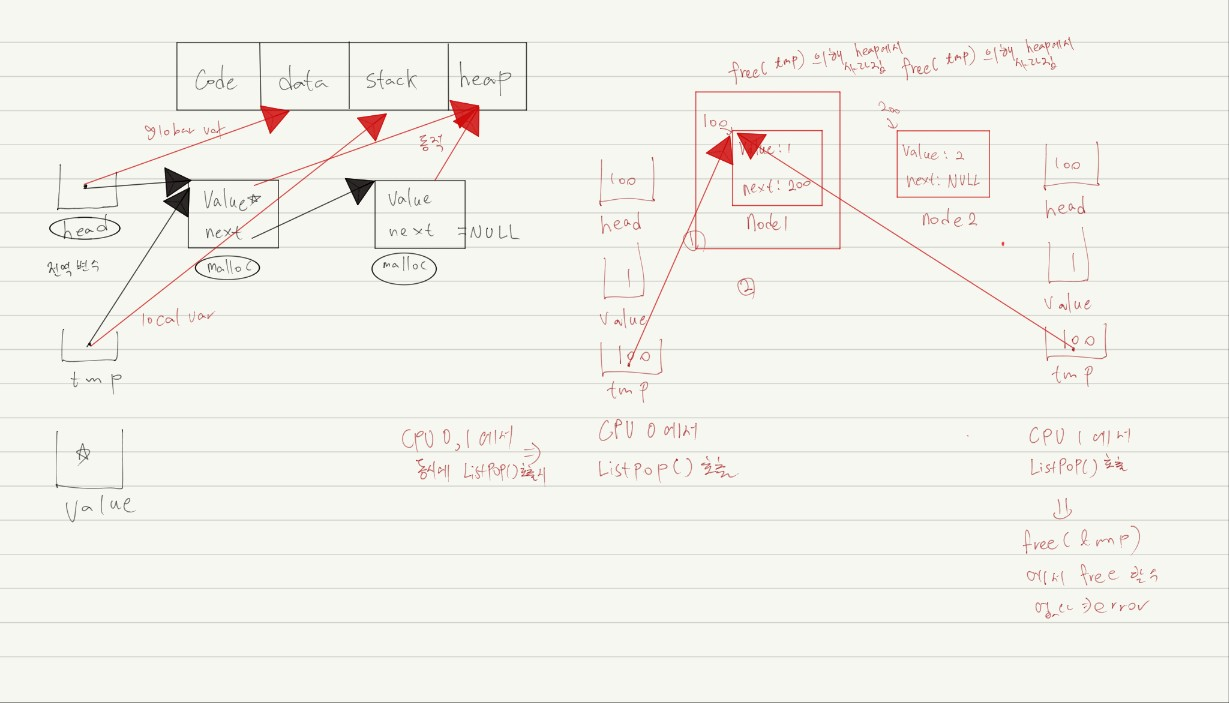
// Simple list Delete Code
typedef struct __Node_t{
int value;
struct __Node_t *next;
} Node_t;
int List_Pop(){
Node_t *tmp = head;
int value = head -> value;
head = head -> next;
free(tmp);
return value;
}
- 해결책
- lock을 이용한 Simple List Delete code
pthread_mtuex_t m;
typedef struct __Node_t {
int value;
struct __Node_t;
} Node_t;
int List_Pop(){
lock(&m) // key가 필요 1개만 실행된다.
Node_t *tmp = head;
int value = head->value;
free(tmp);
unlock(&m) // mutual exclusive primitive
return value;
}- lock은 thread에서 동시에 실행되면 안되는 부분을 의미한다.
- 따라서 critical section을 하나의 thread에서만 접근이 가능하게 lock을 걸어준다.
- lock은 기본적으로 lock을 획득한 thread만 critical section을 실행하며, 사용하고 난 뒤에 lock을 반환한다.(unlock)
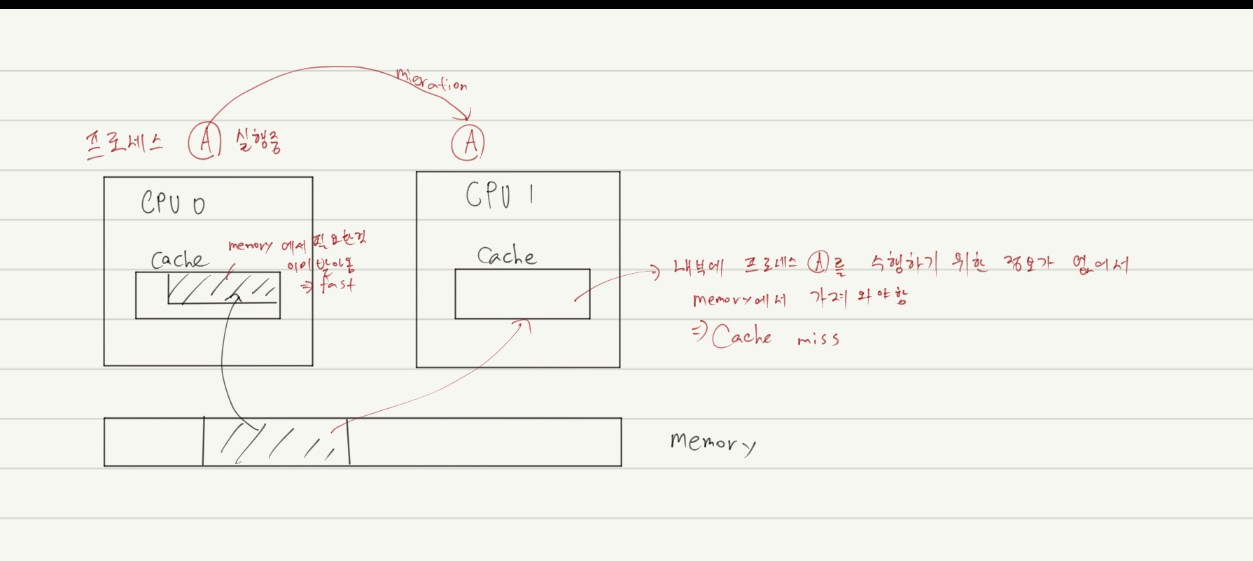
Cache Affinity(캐시 친화도)
- 프로세스를 가능하면 같은 CPU에서 실행시키기
- 프로세스는 CPU의 캐시에 충분한 양의 상태를 넣는다.
- 다음번에 프로세스가 작동할때 이미 CPU의 캐시에 상태가 이미 존재한다면 더 빠르게 작동할 것이다.
- 멀티프로세서 스캐줄러는 스캐줄링 결정을 할 때 캐시 친화도를 고려해야한다.
Single queue Multiprocessor Scheduling(SQMS)
-
단일 큐에 스캐줄링되어야 할 모든 작업들을 넣어 놓는다.(shared resource)
- 각 CPU는 단순히 전체로 공유된 큐들 중에서 다음 작업을 선택한다.
- 단점
- 몇몇 locking 형태가 삽입되어야 한다. -> 확장성의 부족
- 캐시 친화도
- CPU들에서 가능한 작업 스케줄러
-
예시
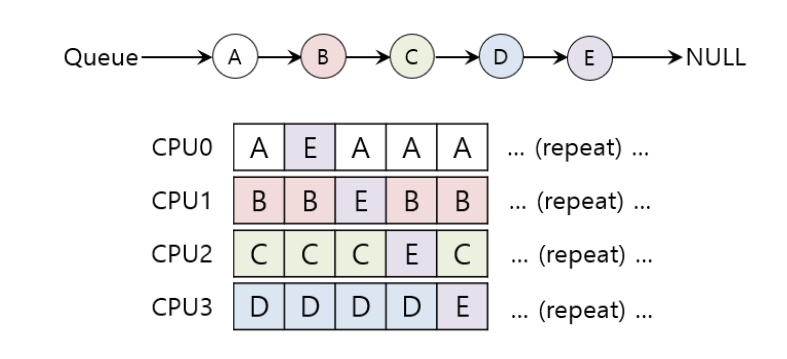

Cache affinity를 좋게 유지하는 스케줄링
-
affinity를 가장 중요하게 고려
- A~D작업은 같은 프로세서에서 이루어진다.
- E작업만 CPU에서 CPU사이에 이동한다.
-
다음과 같은 계획을 가지는 것은 어려울 수도 있다.
Multi-queue Multiprocessor Scheduling(MQMS)
- MQMS는 다양한 스케줄링 큐들로 이루어져 있다.
- 각 큐들은 특정한 스케줄링 정책을 따른다.
- 작업이 시스템에 들어오면 이것은 정확히 하나의 스케줄링 큐에 위치하게 된다(코어마다 자신만의 스케줄링 큐를 가진다).
- 정보 교환 또는 동기화 문제를 피할 수 있다.
MQMS 예시
-
round robin을 이용하여 시스템은 스케줄을 만들 수 있다.
-
MQMS는 더 좋은 확장성과 캐시 친화도를 제공한다.
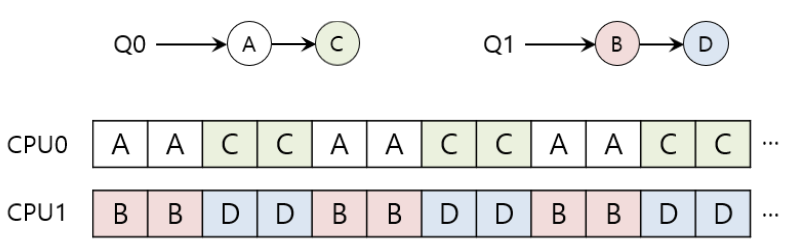
MQMS에서의 Load imbalance 문제
- Q0에서 C작업이 끝났을 때
- A는 B와 D보다 두배더 많은 CPU를 할당받는다
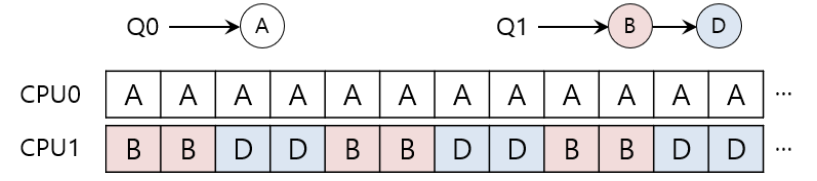
- Q0에서 A마저 끝나버릴때
- CPU0는 쉬게된다.
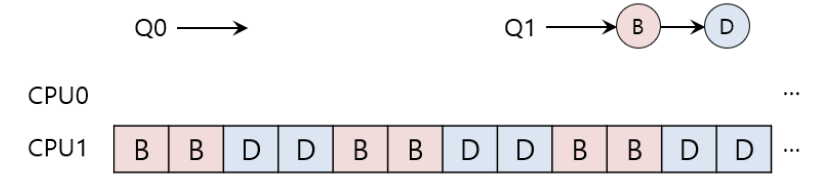
load imbalance문제를 어떻게 해결할까?
-
작업을 옮겨 버린다.(migration)
-
예시
-
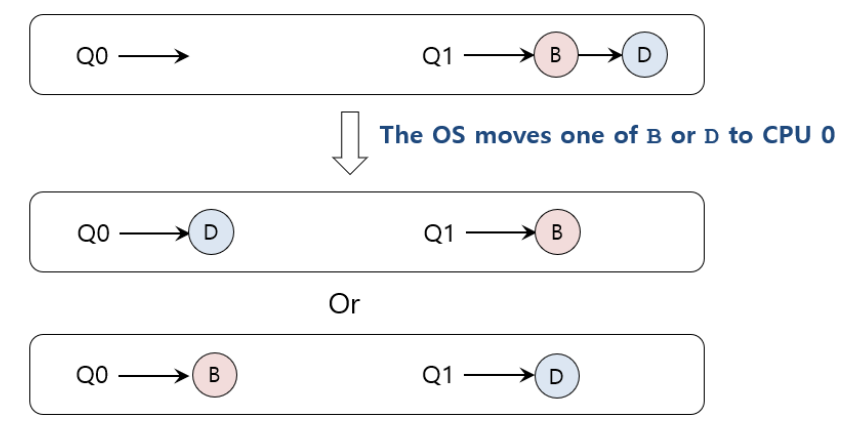
더 어려운 경우(Q0 스텍에는 A가 Q1스텍에는 B,D가 존재)
-
가능한 migration 패턴
- switching 작업을 계속한다.
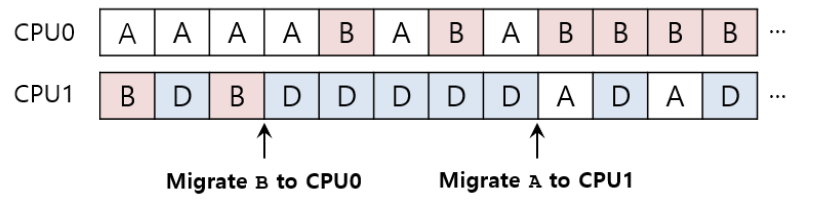
Work Stealing
- 작업을 큐들 사이에서 옮긴다.
- 구현
- 작업량이 작은 소스 큐가 선택된다.
- 소스 큐는 한번씩 다른 타겟 큐를 쳐다본다.
- 타겟 큐가 소스 큐보다 훨씬 차있다면 소스 큐는 타겟 큐로부터 하나 또는 더 많은 작업을 "훔칠 것"이다.
- 단점
- SQMS의 scalability를 해결하기 위해 적용했는데 다시 scalability 문제가 발생 할 수 있다. 이를 통한 lock에 대한 경쟁이 커져 overhead가 높아진다.
- 구현
