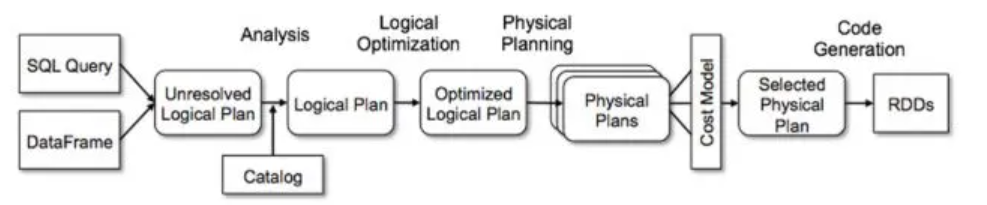
Apache Spark SQL 엔진의 쿼리 처리 과정
Unresolved Logical Plan
- Schema Information, table name 등이 확정 되지 않았기 때문에 참조하는 Data Structure, Column name 등이 제대로 확인 되지 않은 상태
Catalog
- Spark는 Catalog를 사용하여 Database, Table, View, function 등 Meta Data 확인
- Unresolved Logical Plan 의 각 부분이 실제 테이블과 컬럼 정보와 매칭되며, 이 과정 오류 발생 시 query 실행 되지 않음
Logical Plan
- Meta Data 확인되면, Logical Plan 생성
- Query나 DataFrame의 구조가 명확
- Query의 순서와 수행해야 할 작업들이 논리적으로 배치
- But, 아직 최적화되지 않은 상태
Optimized Logical Plan
Query의 성능을 크게 개선할 수 있는 여러 최적화 작업이 수행
Projection Pushdown
- Query에서 실제 필요한 컬럼만 최대한 빨리 선택하는 최적화
- 예를 들어, 특정 컬럼만 필요한데도 쿼리에서 전체 테이블을 읽고 있다면, Spark는 프로젝션 푸시다운을 통해 불필요한 컬럼들을 제외하고 처리
Filter Pushdown
- WHERE, HAVING 과 같은 필터 조건을 가능한 한 빨리 적용하여, Query 실행 중 불필요한 데이터를 미리 걸러내는 최적화
- 필터가 데이터 소스 가까이에서 실행되면 Spark는 그 이후의 연산에서 처리할 데이터 양을 줄일 수 있다. 큰 데이터셋을 처리할 때 중요한 최적화
Stage Optimization
- Spark는 작업을 stage 로 나누어 실행. 각 stage는 cluster 에서 병렬로 실행 될 수 있는 최소 단위의 작업 세트를 의미
- Spark는 여러 작업이 하나의 stage에서 처리 될 수 있는지, 아니면 데이터를 suffle 해야 하므로 stage를 나눠야 하는지를 분석
- 데이터가 이미 같은 파티션으로 나누어져 있으면 추가적인 suffle 없이 같은 stage에서 처리 할 수 있음
- 반면, 데이터가 suffle 되어야 한다면 Spark는 새로운 stage를 만들고, suffle 작업을 최적화 함
Predicate Pushdown
- 필터링 조건을 데이터 소스에서 최대한 빨리 적용하는 또 다른 최적화 전략
- Spark는 물리적 데이터 소스가 지원하는 경우, 데이터베이스 수준에서 조건을 푸시다운하여 데이터를 더 적게 읽어옴
Elimination of Redundant Operations & Cache Optimization
- Spark 는 Query Plan 에서 중복된 연산을 찾아 제거
- 데이터가 반복적으로 사용된다면 Cache를 이용해 재사용할 수 있도록 최적화 함
Predicate and Expression Simplification
- Spark는 논리적 최적화 단계에서 수식을 단순화하거나 논리적으로 일관되지 않는 조건을 제거합
Physical Plans
- Logical Plan을 Cluster 가 알아 들을 수 있게 바꿔 줌
- 여러 개의 물리 계획이 생성 될 수 있는데, Cost Model을 사용하여 각 물리 계획의 비용을 계산
- 비용이란 CPU 사용량, 네트워크 셔플, 메모리 사용량 등 실행 시 소모될 자원에 대한 평가
- Spark는 여러 물리 계획 중에서 가장 효율적인 계획을 선택
Selected Physical Plan
- 비용 모델을 기반으로 최종적으로 선택된 물리 계획이 결정
- 이 계획에 따라 실행이 이루어지며, 최종적으로 코드를 생성
Code Generation
- 선택된 물리 계획이 완료되면, Spark는 실행할 코드를 생성
- 주로 Tungsten 엔진을 통해 JIT(Just-In-Time) 컴파일을 수행하여 효율적인 바이트코드로 변환
- 실제로 RDD로 변환되어 클러스터 상에서 작업이 실행

이상억