Apache Spark
하둡의 YARN이 등장하게 되면서 YARN과 Spark의 조합으로 대규모 분산 데이터 처리를 빠르고 효율적으로 할 수 있게 되면서 빅데이터 분산 처리 모든 분야에서 쓰이게 된 엔진
- spark는 기본적으로 데이터 센터나 클라우드에서 대규모 분산 데이터 처리를 하기 위해 설계된 통합형 엔진
- 주요 설계 철학은 속도
일단 컴퓨터 내에서 데이터 처리되는 장치들에 대한 속도를 단적으로 비교해보면 다음과 같다
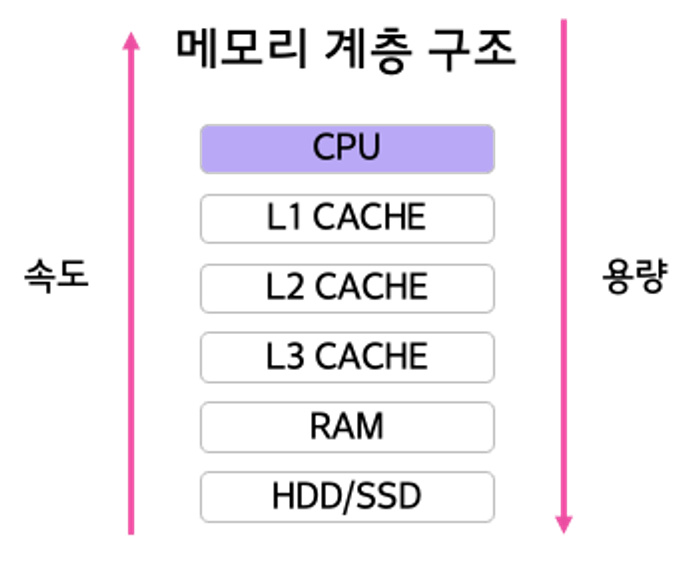
- 먼저 데이터는 HDD/SDD와 같은 보조 기억장치에 저장
- 이 데이터를 처리하기 위해 프로그램은 RAM에 데이터를 적재
- RAM에 적재된 데이터들을 자주 사용하면 CACHE에 적재 되어 CPU에 빠른 접근 가능
- 문제는 아래에 있을 수록 용량은 커지지만 속도는 느려짐
정리하자면, 자주 사용할수록 용량은 작지만 속도는 빠른 기억장치에, 자주 사용되지 않는 데이터 일수록 용량은 크지만 처리 속도가 느린 기억장치에 데이터가 적재되게 됨
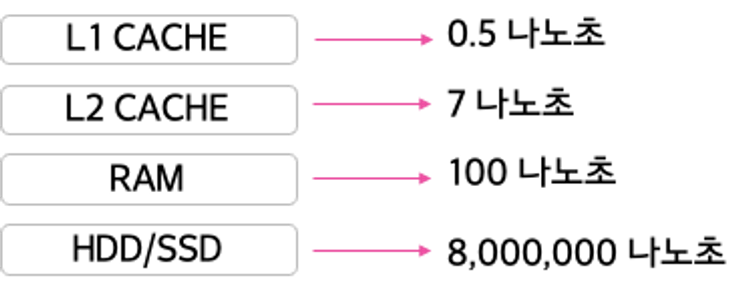
- 데이터를 빠르게 처리하기 위해 L1,L2 캐시 등을 사용하는 것을 좋아보임
- 그러나 캐시 메모리는 기본적으로 용량이 너무 작음
- 가격도 적당하고, 용량도 적당하고 속도도 적당히 빠른 RAM 을 Spark에서 활용
Spark Cluster
RAM을 사용하는 스파크도 문제는 있다. 거대한 용량의 데이터는 처리가 힘들다는 점이다. 일반적으로 RAM의 용량은 8~64GB 라는 것을 생각하면 페타바이트나 제타바이트 같은 거대 용량을 가진 데이터는 RAM에서 단독으로 처리하기 힘들다. 그래서 DISK 및 분산 처리 시스템과의 협업을 할 수 있다.
따라서 스파크도 클러스터를 이루며 대략적인 구조는 다음과 같다.
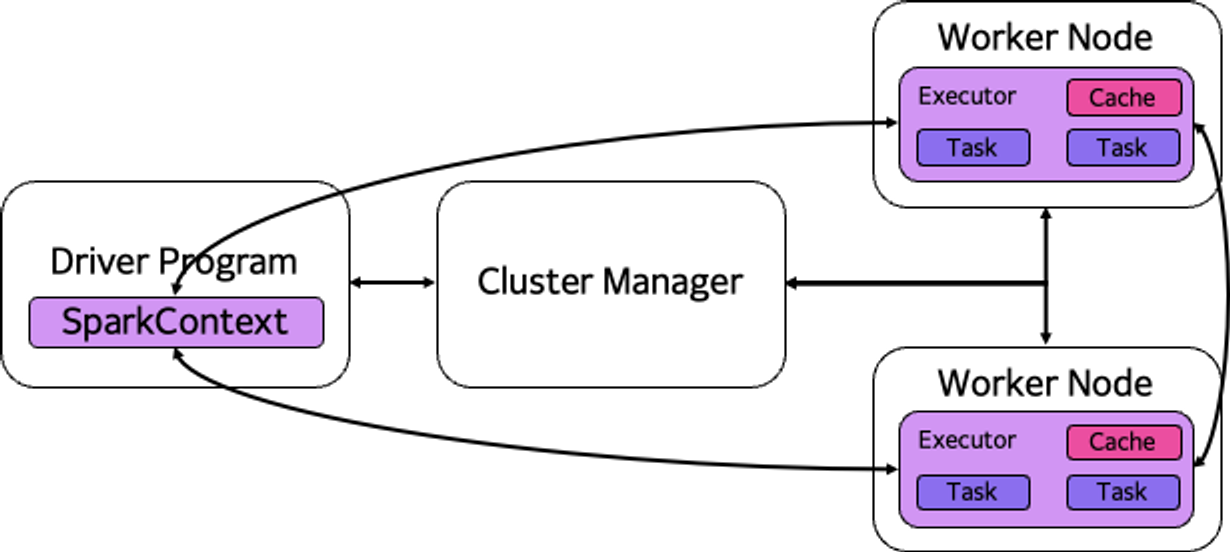
마찬가지로 Master/Worker 구조를 가진다. SparkContext가 Master의 역할을 수행
- Driver Program
- 분산 시스템에서 처리할 작업을 의미.
- 즉, 작업프로그램(Task Progarm)을 작성해서 실행을 의뢰하는 주체로 Python, Scalar, Java등을 사용해서 프로그램을 작성.
- 실행은 각 Worker Node에서 실행
- Cluster Manager
- Worker Node의 상태를 관리하는 주체로 스케쥴링을 담당
- 작성된 Task를 Worker에 분배하는 역할
- HADOOP을 사용할 때는 YARN, AWS와 같은 클라우드를 사용할 때는 EMR(Elastic Map Reduce) 등을 사용하기도 함
- Worker Node
- 실제 작업을 하는 노드
- Cluster Manager에 의해 Driver Program을 다운로드 받고 실행하게 됨
- 노드의 개수는 필요에 따라 얼마든지 늘릴 수 있음
- 이상적인 구조는 하나의 CPU 당 하나의 노드를 배치하는 것
Pandas vs Spark
일반 로컬 컴퓨터에서는 스파크를 사용하면 판다스보다 느림. 판다스는 기본적으로 넘파이를 기반으로 만들어진 라이브러리이기 때문에 CPU 분산 병렬 처리가 가능한 반면, 스파크는 분산 컴퓨팅에 특화되어 있기 때문
- 판다스 데이터 프레임은 일정 크기가 넘어가면 처리가 불가능
- 스파크는 용량이 커져도 연산을 잘 수행
- 스파크는 대용량 데이터에 대한 수펴저 확장을 고려
하지만 스파크는 하둡이나 하이브의 맵리듀스 작업보다 훨씬 빠름. 메모리 상에서는 100배, 디스크 상에서는 10배 정도가 빠르다고 알려져 있다.
- Lazy Evaluation 연산을 지원
- 데이터를 바로 처리하는 것이 아니라, 데이터를 불러오는 것부터 시작하여 필요한 시점에서 연산을 수행
- 불필요한 데이터 로딩과 중복 연산을 방지하고, 연산 처리 속도를 빠르게 함

이상억