
벌러덩 콩순이
YOLO?
이미지를 한번 보는 것 만으로도 객체의 종류와 위치를 추측할 수 있는 모델.
single convolutional network를 통해 multiple bounding box에 대한 class probablity를 계산합니다.
마치 사람의 시각 인식 체계 처럼 한번 보면 객체와 객체의 위치를 파악할 수 있는 기능을 갖고 있습니다.
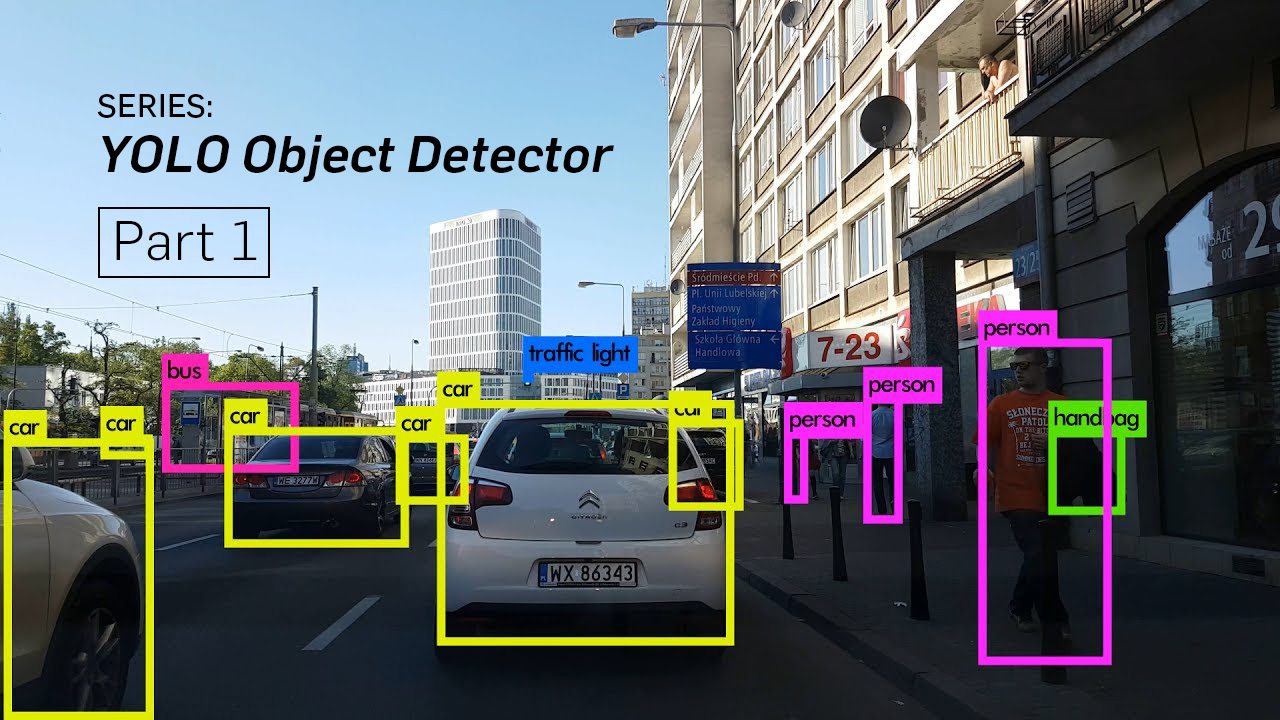
YOLO의 특징 : Unified Detection
위에서도 말씀 드렸듯이 YOLO는 이미지를 한번 보는 것 만으로
객체의 종류, 위치를 추측할 수 있습니다.
기존 R-CNN은 이미지 내의 2000개의 bounding box 후보를 선정하고 각 bounding box안 모든 영역에 대해 classification(분류)를 진행해는데요.
때문에 모델이 3개 이상이라 복잡했고 속도가 느렸습니다.

1) Input image를 S X S grid로 나눈다.
2) 각각의 grid cell은 B개의 bounding box와 각 bounding box에 대한 confidence score를 갖는다. (만약 cell에 object가 존재하지 않는다면 confidence score는 0이 된다.)
Confidence Score: Pr(Object)∗IOUtruthpred
3) 각각의 grid cell은 C개의 conditional class probability를 갖는다.
Conditional Class Probability: Pr(Classi|Object)
4) 각각의 bounding box는 x, y, w, h, confidence로 구성된다.
(x,y): Bounding box의 중심점을 의미하며, grid cell의 범위에 대한 상대값이 입력된다.
(w,h): 전체 이미지의 width, height에 대한 상대값이 입력된다.
- 예1: 만약 x가 grid cell의 가장 왼쪽에 있다면 x=0, y가 grid cell의 중간에 있다면 y=0.5
- 예2: bbox의 width가 이미지 width의 절반이라면 w=0.5
Test time에는 conditional class probability와 bounding box의 confidence score를 곱하여 class-specific confidence score를 얻는다.
용어 정리
- confidence : 박스에 객체가 있는지 없는지, 유무에 대한 확률.
x, y, w, h, confidence로 정의 됩니다.- x, y : 바운딩 박스의 중앙값
- w, h : 바운딩 박스의 넓이와 높이
- objectness : 박스에 객체가 있는지 없는지에 대한 정확도. 무슨 객체인지는 모르며, 박스 안에 객체가 있는지 없는지 유무만 확인. (= confidence threshold)
예를 들어 objectness를 0.3으로 설정 했는데 정확도가 30%가 안 나왔다, 그러면 해당 박스는 버려집니다.- probability : objectness에서 걸러진 박스를 대상으로 한번 더 필터링 하며, 객체가 무엇인지 탐지하는 과정입니다.
(고양이인지, 자전거인지, 새인지 등)- softmax 함수 : 분류하고 싶은 클래스의 수 만큼 출력으로 구성하는 함수입니다. 입력받은 값을 출력으로 0-1 사이 값으로 모두 정규화 하여 출력값으 총합이 항상 1입니다. 가장 큰 출력 값을 받은 클래스가 가장 확률이 높습니다.
- IOU : grid cell에 object가 존재할 확률과 예측된 bounding box가 실제 bounding box와 일치하는 정도
confidence score에서 필터링 되어 내려온
Bounding Box는 C(클래스 개수에 따라 다름)개의
Confidentional Class probability 값을 가집니다.
그 다음 Softmax로 들어가서 가장 높은 값을 찾습니다.
YOLO의 object detection 과정은 input image를 S X S grid로 나누는 것 부터 시작합니다.
grid cell은 B개의 bounding box와
각 bounding box에 대한 confidence score를 갖습니다.
Confidence Score는 해당 grid celldp object가 존재할 확률과 예측된 bounding box와 일치하는 정도인 IOU(Intersection Over Uninon)값을 곱해서 계산됩니다.
예를 들어 Grid Cell에 Object가 없으면 Confidence Score는 0이 됩니다.
YOLO의 장점
- 단일 신경망 (single convolutional network) 구조이기 때문에 구성이 단순하며 속도가 빠릅니다.
- 주변 정보까지 학습하며 이미지 전체를 처리하기 때문에 background error가 작습니다.
- 훈련단계에서 보지 못한 새로운 이미지에 대해서도 검출 정확도가 높습니다.
YOLO의 한계
- 각각의 grid cell은 하나의 클래스만 예측할 수 있습니다. 작은 object가 여러 개 다닥다닥 붙어 있을 시 정확하게 예측하지 못합니다.
- 바운딩 박스 형태가 일정해야 합니다. 왜냐하면 training data를 통해서만 학습되기 때문입니다. 따라서 새롭거나 독특한 형태의 바운딩박스를 사용할 경우 정확하게 예측하지 못합니다.
- 몇 단계의 레이어를 거쳐 나온 feature map을 대상으로 bounding box를 예측합니다. 따라서 Localization(객체가 있는 위치)가 부정확 할 수 있습니다.
