
zookeeper란?
ZooKeeper의 개발 배경
개발 배경
- 분산 시스템에서는 클러스터간의 통신이나 데이터를 처리하는데 있어 고민
- 분산된 시스템 같이 정보를 어떻게 공유할 것인가
- 클러스터에 있는 서버들의 상태를 어떻게 체크할 것인가
- 분산된 서버들 간의 동기화를 위해 잠금을 어떻게 처리할 것인가
- 이러한 분산 시스템을 처리해주고 관리의 필요성이 생겼다.
분산된 서버들끼리 통신할 때 리소스를 공유하려다 보면 자원 점유 문제가 발생하는데, 이를 처리하기 위한 대표적인 해결책으로 리소스 락을 볼 수 있다. 이 리소스는 Lock,Unlock하는데도 관리해주는 시스템이 필요하다.
코디네이션 서비스는 분산 시스템 내에서 중요한 상태 정보나 설정 정보 등을 유지하기 때문에 코디네이션 시스템의 장애는 전체 시스템 장애로 이어지는 장애 전파 특성이 있다.
따라서 고가용성을 제공하는 것이 필수이다.
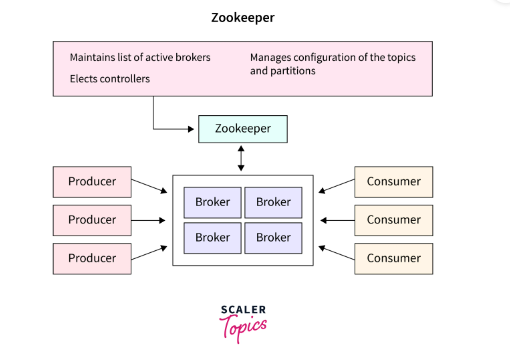
ZooKeeper는 분산 시스템을 위한 중앙화된 설정, 네이밍, 동기화, 상태 관리를 지원하는 오픈소스 코디네이션 서비스
- 즉, 여러 서버들이 “누가 리더인지?”, “누가 살아있는지”, “설정을 공유할지?”를 조율해주는 분산 시스템 관리자 역할을 한다.
- 어플리케이션의 정보를 중앙 집중화하고 구성관리, 그룹 관리 네이밍, 동기화 등의 서비스를 제공한다. 주키퍼의 데이터는 메모리에 저장되고, 영구 저장소에 스냅샷을 저장한다.
분산 코디네이션 서비스
분산 시스템에서 시스템 간의 정보 공유, 상태 체크, 서버들 간의 동기화를 위한 락 등을 처리해주는 서비스
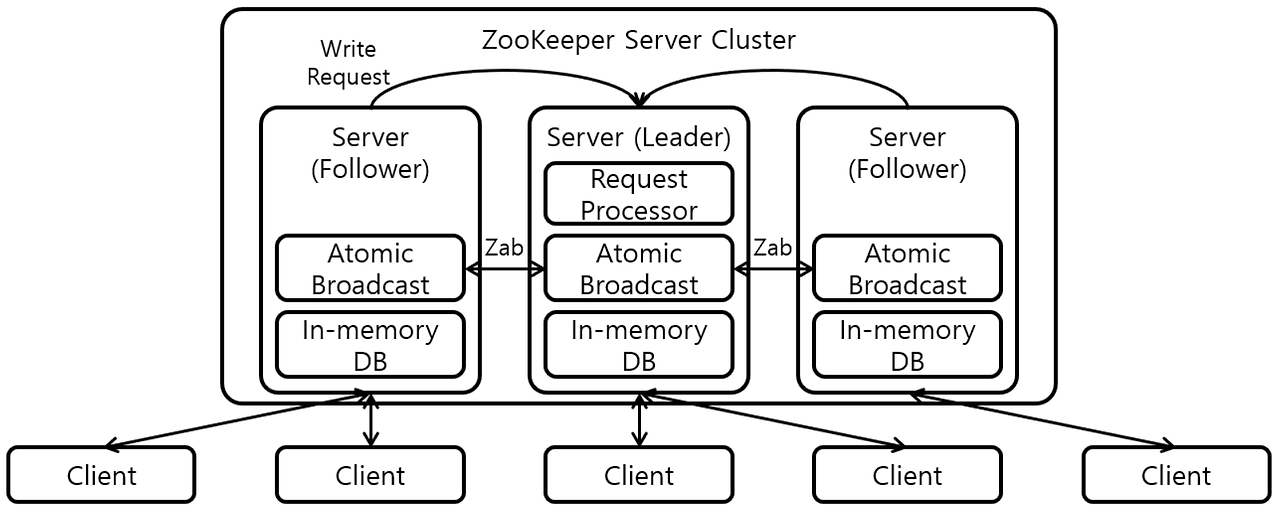
⇒ 그림에서 Server는 주키퍼, Client는 카프카
구성
-
Request Processor : Write 요청 처리
-
Zab (Zookeeper Atomic Broadcast Protocol) : Request Processor에서 처리한 요청을 트랜잭션을 생성하여 모든 서버에게 전파한다. [Leader-Propose] -> [Follower-Accept] -> [Leader-Commit] 단계로 구성
-
In-memory DB: Znode 정보 저장, 로컬 fs에 Replication을 구성
주키퍼 역시 분산 시스템의 일부분이기 때문에 동작을 멈춘다면 분산 시스템이 멈출수도 있다. 그래서 안정성을 확보하기 위해 클러스터(Cluster)로 구축한다.
- 클러스터는 홀수로 구축
- 어떤 서버에 문제가 생겼을 경우 과반수 이상의 데이터를 기준으로 일관성을 맞추기 때문
- 살아남은 노드가 과반수 이상이라면 지속적인 서비스를 제공
- 서버 여러 대를 클러스터로 구축하고, 분산 어플리케이션들의 각각 클라이언트가 되어 주키퍼 서버들과 커넥션을 맺은 후 상태 정보 등을 주고 받음.
-
상태 정보들은 주키퍼에 Znode 라고 불리는 곳에 Key - Value 형태로 저장
-
저장된 형태로 분산 어플리케이션들은 서로 데이터를 주고받음
-
Znode란?
주키퍼의 인터페이스
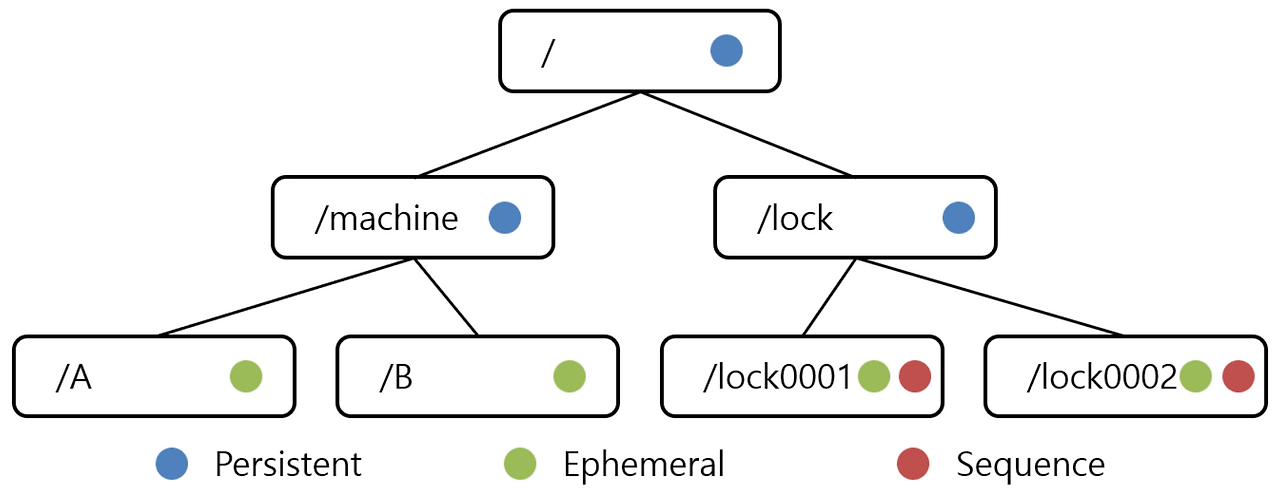
주키퍼가 상태 정보를 저장하는곳
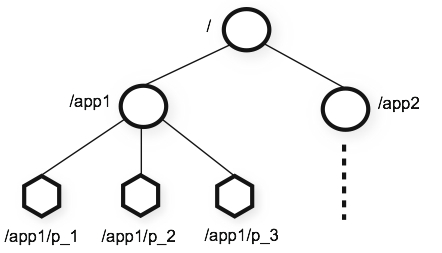
→ 파일 시스템과 유사하게 노드간 계층구조(트리구조)를 가지며 각 노드를 ‘/’로 구분하나 file과 directory 구분이 없음
- 모든 znode는 메모리에 저장됨.빠른 접근을 위해 메모리에 올려둠)
- 따라서 jvm의 모든 heap memory를 모든 znode를 올릴 수 있는 충분한 크기로 만들어야함
- 목적은 데이터 저장이 아니라 분산 처리되는 시스템 간의 조정. 하는 역할 자체가 read와 write 밖에 없다.
- 따라서 1 Znode당 데이터 크기 제한 있음.
- znode는 디렉토리와 파일의 구분이 없기 때문에, 경로를 가지면서 데이터를 가질 수 있다.
- 분류
- Persistent Node: 영구 저장소
- Ephermeral Node: Client가 종료되면 사라짐
- Sequence Node: 생성 시 뒤에 숫자가 붙음
Quorum
Leader가 새로운 트랜잭션을 수행하기 위해서는 자신을 포함하여 과반수 이상의 서버의 합의를 얻어야하는데, 과반수 합의를 위해 필요한 서버들
Ensemble을 구성하는 서버의 수가 5개라면, Quorum은 3개의 서버로 구성이 된다.
왜 쿼럼은 과반수로 이루어져야 하느냐?
첫번째, 리더 선출
- 각 서버는 자신의 현재 zxid(트랜잭션 ID)와 자신을 후보자로 지명해 모든 서버로 전송 (zxid가 높은 놈일수록 더 많은 데이터가 있는것)
- 각 서버는 zxid를 받은 뒤, 자신의 zxid와 비교해 더 높은 쪽을 후보자로 지명해 모든 서버에 전송
- 과반수 이상의 서버로부터 지명된 서버가 leader로 선출
두번째, 데이터의 일관성
- 데이터가 죽었을때, 반드시 과반수 이상의 데이터를 가져와서 브로드캐스팅을 진행
과반수 이상의 데이터가 죽어버리면, 주키퍼는 동작을 멈춘다! 더이상 데이터를 쓸수가 없다.
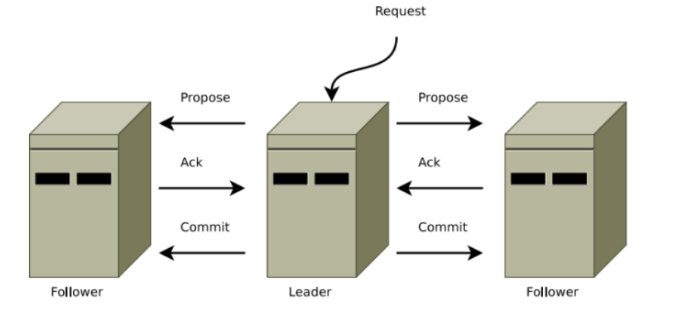
- Leader에게 Request 전달
새로운 트랜잭션 요청이 Follower에게 도착하였을 경우, Follower는 Leader에게 요청을 전달한다.
- Propose
Propose는 Leader가 Quorum을 구성하는 서버들에게 트랙잭션을 수행해도 되는지 여부를 요청하는 과정을 의미한다.
- Ack
Quorum을 구성하는 서버들은 Leader로 부터 Propose 요청을 받으면, 트랙잭션을 수행해도 된다는 Ack 응답을 Leader에게 전송한다.
- Commit
모든 Quorum으로 부터 Ack를 받으면, Leader는 트랙잭션을 처리하라는 Commit 명령을 broadcast 형태로 모든 Follower에 전파한다. ZooKeeper에서는 Commit 명령을 전달할 때, ZAB(ZooKeeper Atomic Broadcast) 알고리즘을 사용한다. Atomic Broadcast는 broacast 방식 중 하나로, 멀티 프로세스 시스템에서 모든 프로세스에게 동일한 순서로 메시지가 전달된다는 것을 의미한다.
-
Watcher
ZooKeeper는 znode에 변화를 감지할 수 있는 Watcher를 클라이언트가 설정할 수 있도록 한다. Watcher는 자신이 감시하고 있는 znode에 수정이 발생하였을 때, 클라이언트로 callback 호출을 전송하는 알림 기능을 제공한다.
주키퍼를 사용하는 클라이언트 A가 ZooKeeper에게 Watcher 등록을 요청한다.
주키퍼를 사용하는 클라이언트 B가 ZooKeeper에게 Znode를 수정한다고 말한다.
클라이언트 A에게 변경 이벤트를 전달한다.
Zookeeper의 목적과 Kafka와의 관계
주키퍼의 목적
Zookeeper는 DB처럼 데이터 저장하려는 목적이 아니다.
진짜 목적은 분산 시스템끼리 서로 "상태를 동기화"하고 "조정"하는 것.
- 누가 리더(Leader)가 될지 선출하기 (Leader Election)
- 분산 락(Distributed Lock) 걸기
- 설정 파일(Configuration)을 중앙 집중화해서 관리
- 서버들이 클러스터에 살아 있는지 확인(Heartbeat)
즉, Zookeeper는 다음 같은 걸 해주는 조정자(Coordinator) 역할.
- 서버 A, B, C가 있다고 할 때
- A, B, C가 서로 직접 통신하지 않고
- Zookeeper의 Znode를 통해 간접적으로 상태 공유함
Kafka와의 관계
- 주키퍼는 별도의 독립된 서버(클러스터)로 운영하는 경우가 많음
- 카프카는 일시적으로 브로커 하나가 죽어도 클러스터 전체가 바로 멈추진 않음
- 살아있는 브로커들이 계속 서비스 유지 가능
- 그러나 주키퍼는 다름
- 주키퍼는 다수결(Quorum) 구조 사용함
- 노드 과반수 이상 살아있어야 정상 동작 가능
- 과반수 무너지면 주키퍼 전체가 동작 중단함 (읽기/쓰기 모두 불가)
- 만약 주키퍼가 동작 멈추면?
- 카프카 브로커는 당장은 정상적으로 메시지 생산/소비할 수 있음
(이미 리더 선출된 상태에서는 주키퍼 필요 없음) - 그러나 이후에
- 새로운 브로커가 클러스터에 합류하려 하거나
- 리더 브로커가 죽어서 리더 재선출해야 할 때
- 파티션 리더 변경 같은 메타데이터 변경 작업이 필요할 때
- 카프카가 주키퍼에게 요청해야 하는 상황이 생김
- 카프카 브로커는 당장은 정상적으로 메시지 생산/소비할 수 있음
주키퍼는 "중앙 심판" 역할. 카프카는 "선수들". 평소에는 선수들끼리 알아서 경기함. 심판이 없어도 당장은 진행됨. 근데 문제가 생기거나 판정이 필요한 순간 → 심판 없으면 경기 진행 불가.
- 이때 주키퍼가 죽어있으면 카프카가 요청을 처리 못 함
→ 결국 카프카 클러스터 장애로 연결될 수 있음
