서론
UUID를 사용할 때와 Bigint Primary Key를 사용할 때의 조회 성능이 어느정도 차이가 나는가에 대해서 테스트를 진행했다.
해당 테스트를 진행한 결과와 진행 과정을 기록해놓은 Repository는 아래와 같다.
위의 README에서 적어놓았듯이 테스트 결과는 UUID v1, v4, Auto Increment 방식에 따라서 조회 성능이 얼마 차이나지 않는다는 결과가 도출되었다.
때마침 눈 앞에 Vector DB를 개발하고 계시는 개발자님이 계셔서 실험을 어떻게 진행했는지 과정과 실행한 결과를 공유를 해드렸고 실험에 대해서 JOIN을 걸어보면 그 차이가 좀 더 명확하게 드러날거라고 조언을 해주셨다.
BIGINT를 비교하는 방식과 UUID로 문자열을 비교하는 방식은 CMP 연산 방식이 다르고 UUID가 64BYTE라고 말씀을 드렸더니 그럼 64번 만큼의 LOOP를 더 돌 것이라고 말씀하셨다.
실험 진행
- 아래와 같이 100만건의 데이터를 조인을 Recursive Join을 거는 방식으로 데이터를 생성한다.
-- Create table with INTEGER primary key
CREATE TABLE bigint_table (
id INT PRIMARY KEY AUTO_INCREMENT,
data BINARY(16)
);
-- Insert 1,000,000 records into bigint_table
INSERT INTO bigint_table (data)
SELECT UNHEX(REPLACE(UUID(), '-', ''))
FROM (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) a
JOIN (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) b
JOIN (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) c
JOIN (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) d
JOIN (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) e;
-- Create table with TEXT primary key to store UUID
CREATE TABLE uuid_table (
id VARCHAR(36) PRIMARY KEY,
data BINARY(16)
);
-- Insert 1,000,000 records into uuid_table with generated UUIDs
INSERT INTO uuid_table (id, data)
SELECT UUID(), UNHEX(REPLACE(UUID(), '-', ''))
FROM (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) a
JOIN (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) b
JOIN (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) c
JOIN (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) d
JOIN (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) e;- 조회 쿼리를 날려서 속도 차이를 본다.
SELECT count(a.data)
FROM bigint_table a
JOIN bigint_table b ON a.id = b.id
JOIN bigint_table c ON b.id = c.id
join bigint_table d on c.id = d.id; -- 302 ms
SELECT count(a.data)
FROM uuid_table a
JOIN uuid_table b ON a.id = b.id
JOIN uuid_table c ON b.id = c.id
join uuid_table d on c.id = d.id; -- 818 ms이유 분석
select 쿼리가 실행되는 방식을 어셈블리 언어로 생각해보면 알 수 있는데 Bigint 방식은 Bigint끼리 한 번 비교를 수행하고 만약에 결과가 다르다면 어디론가 JMP를 하는 코드가 나올 것이다.
하지만 문자열 비교는 64개의 단어에 대해서 CMP 연산을 하면서 LOOP를 돌고 만약 모두 동일하다면 어디론가 JMP를 하는 로직이 나올 것이다.
- BIGINT 비교 어셈블리 코드 예상
CMP RAX, RBX ; RAX와 RBX 레지스터에 각각 BIGINT 값이 저장된 경우 비교
JLE label ; 만약 RAX <= RBX이면 label로 점프- UUID 비교 어셈블리 코드 예상
mov RAX, [str1] ; 첫 번째 문자열의 포인터
mov RBX, [str2] ; 두 번째 문자열의 포인터
loop_compare:
mov AL, [RAX] ; str1에서 한 글자 가져오기
mov BL, [RBX] ; str2에서 한 글자 가져오기
cmp AL, BL ; 두 문자를 비교
jne not_equal ; 다르면 종료
inc RAX ; 다음 문자로 이동
inc RBX ; 다음 문자로 이동
test AL, AL ; NULL 문자(종료 문자)인지 확인
jne loop_compare ; 종료 문자 아니면 반복즉, 4개의 JOIN을 걸었다는 가정하에 단순히 계산해봐도 Cycle이 64배가 차이가 난다.
Sqlite 분석
위와 같이 추측을 말씀드렸더니 앞에 계시던 DB 개발자님께서 맞는 추측이라고 하시면서 Sqlite로 진짜 그렇게 동작하는지 알아볼까요???를 외치시며 1시간동안 Sqlite를 디버깅 했다.
- UUID 비교시 memcmp를 사용해서 문자열을 비교하는 부분
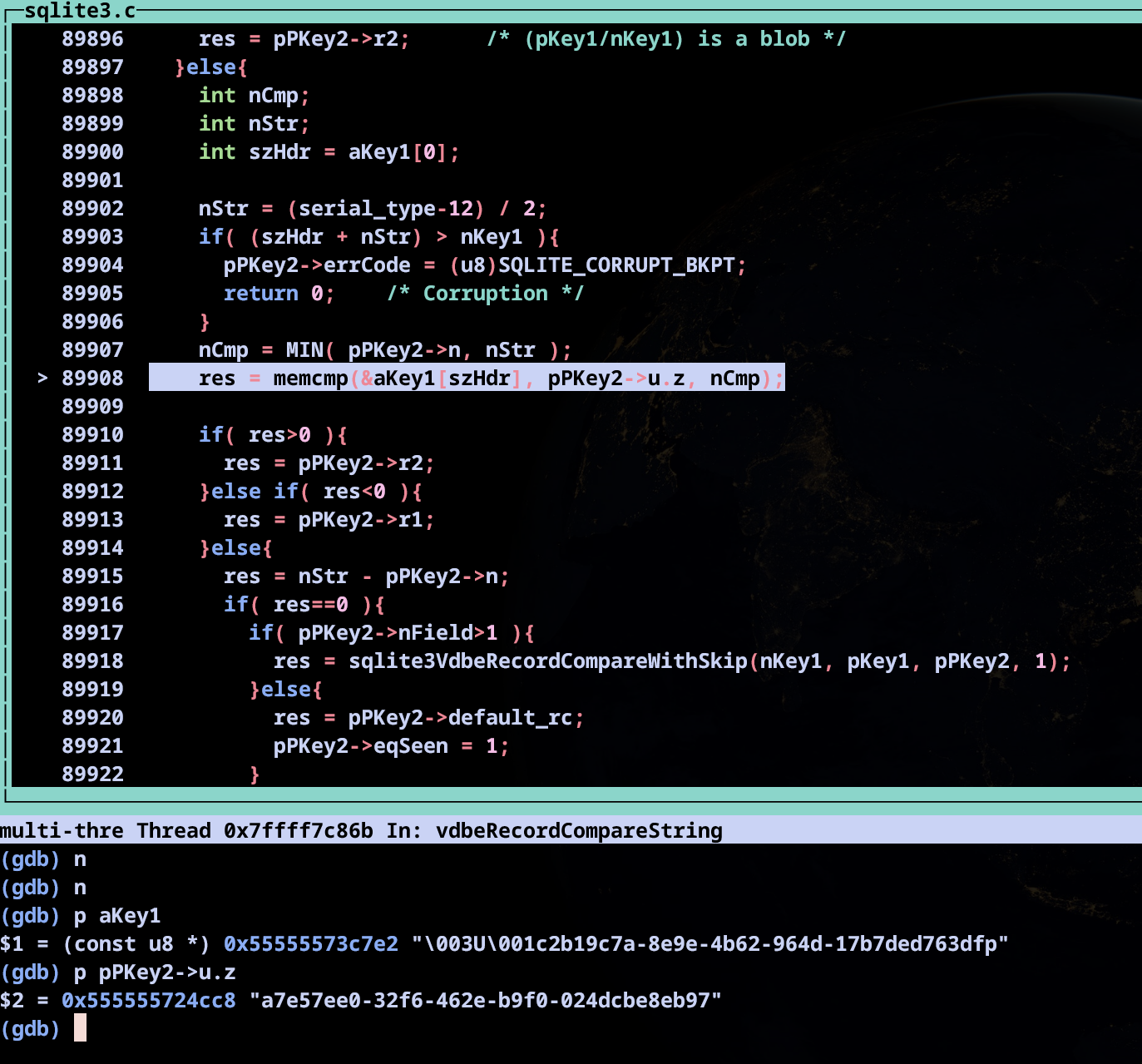
사실 이 memcmp를 사용하는 코드도 디버깅을 하면서 어떤 동작을 하는지 보고 위에서 추측했던
mov RAX, [str1] ; 첫 번째 문자열의 포인터
mov RBX, [str2] ; 두 번째 문자열의 포인터
loop_compare:
mov AL, [RAX] ; str1에서 한 글자 가져오기
mov BL, [RBX] ; str2에서 한 글자 가져오기
cmp AL, BL ; 두 문자를 비교
jne not_equal ; 다르면 종료
inc RAX ; 다음 문자로 이동
inc RBX ; 다음 문자로 이동
test AL, AL ; NULL 문자(종료 문자)인지 확인
jne loop_compare ; 종료 문자 아니면 반복코드와 유사한 동작을 하는 것을 확인했지만, 아쉽게 캡쳐를 하지 못했다.
결론
UUID를 사용해서 조회를 하는 경우 시간복잡도가 N^n 만큼 기하급수적으로 늘어날 것 같다는 생각이 들었고 DB Sequential ID와 UUID를 따로 두는 이유를 납득하게 되었다.
