🦶 발단
사이드 프로젝트 진행 중 투표 기능을 구현하려는데 팀원이 Vote 테이블을 역정규화 해보자는 얘기가 나왔다. 내가 제대로 팀원의 의견을 이해한건지는 모르겠지만 팀원의 의견은 다음과 같았다.
- 데이터 자체가 줄어들기 때문에 DB의 부하가 줄 수 있다.
- 예를 들어서 투표 항목 10개를 불러오는데 모든 항목에 100명의 유저가 투표를 했다면 불러와야 할 Row 수는 1010개의 Row가 되는데 JSON으로 하게되면 게시물 항목만 10개 불러오면 되어서 Row가 확 준다.
나 역시 저기에 덧대서 다음과 같은 장점이 있을거라고 생각했다.
- JOIN 횟수가 줄기때문에 쿼리의 복잡도가 감소한다.
- 투표 컬럼만 사용해서 어떤 조회를 한다거나 하는 작업도 없기 때문에 정규화를 통해서 가져올 수 있는 이점이 적다.
그렇게 결정을 하고 각 투표 옵션에 대한 비율 VoteRatio를 구하는 로직을 작성하던 중 JSON 데이터를 (Spring Application에서는 HashMap<Long, Long>) Stream으로 처리하는 과정에서 어려움을 겪고 있는데 같이 공부하고 있던 형님께서 왜 이걸 JSON으로 넣었냐고 하면서 다시 문제가 되었다.
형의 주장은 다음과 같았다.
- 어차피 Index를 걸어둘 경우 조회성능에서 크게 차이가 나지 않는다.
- 테이블을 분리하는게 정석이다.
- 테이블을 분리해서 처리할 경우 쿼리를 통해서 Ratio를 처리하는 로직을 좀 더 간단하게 개발할 수 있다.
- JSON으로 처리할 경우 하나의 Column을 처리하는거기 때문에 동시성 문제를 신경써줘야 하지만 테이블을 분리하게 되면 Row를 그냥 추가하는거기 때문에 동시성 문제에서 상대적으로 자유롭다.
나는 위 주장에 대해서 다음과 같이 반박했다.
- JPA는 Proxy 객체를 갖고 있기 때문에 이 객체 생성 비용 때문에 오히려 연관관계 맵핑이 성능이 더 안좋게 나올 수 있다.
하지만 저 Proxy 객체의 생성 비용이라는 것 자체가 내 추측에 불과해서 실제로 성능 테스트를 해보고 두 방식의 장단점을 고려해볼려고 한다.
테스트 세팅
Post Vote 연관관계 맵핑 방식 ERD
create table jpa_post
(
id bigint not null auto_increment primary key,
content varchar(255),
title varchar(255)
);
create table vote
(
id bigint not null auto_increment primary key,
member_id bigint,
vote boolean,
post_id bigint,
unique (member_id, post_id) # 하나의 회원이 하나의 게시글에 여러번 투표할 수 없도록 유니크 제약조건 추가
);JSON으로 투표 항목을 한 테이블에 몰아 넣는 방식 ERD
CREATE TABLE json_post
(
id BIGINT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255),
content TEXT,
votes JSON
);성능 테스트 스크립트
import http from 'k6/http';
import { check } from 'k6';
import { SharedArray } from 'k6/data';
export let options = {
vus: 10000, // 동시에 실행할 가상 사용자 수
iterations: 10000, // 반복 횟수 (총 요청 수 : 반복 횟수 / 동시 사용자 수)
duration: '1m', // 최대 테스트 지속 시간
};
export default function() {
// __VU : Virtual User의 고유 ID
// __ITER : 현재 시나리오에서의 반복 횟수
const memberId = (__VU - 1) * 10000 + __ITER + 1;
const vote = Math.random() < 0.5; // Math.random()은 0.0 ~ 1.0 사이의 난수를 반환
// const url = 'http://192.168.1.12:8080/json/7';
const url = 'http://192.168.1.12:8080/jpa/10';
const payload = JSON.stringify({
memberId: memberId,
vote: vote
});
const params = {
headers: {
'accept': '*/*',
'Content-Type': 'application/json'
},
};
const res = http.post(url, payload, params);
check(res, {
'is status 200': (r) => r.status === 200,
});
}✨ 쓰기 성능 테스트 결과
투표 성능 테스트(테스트 실패)
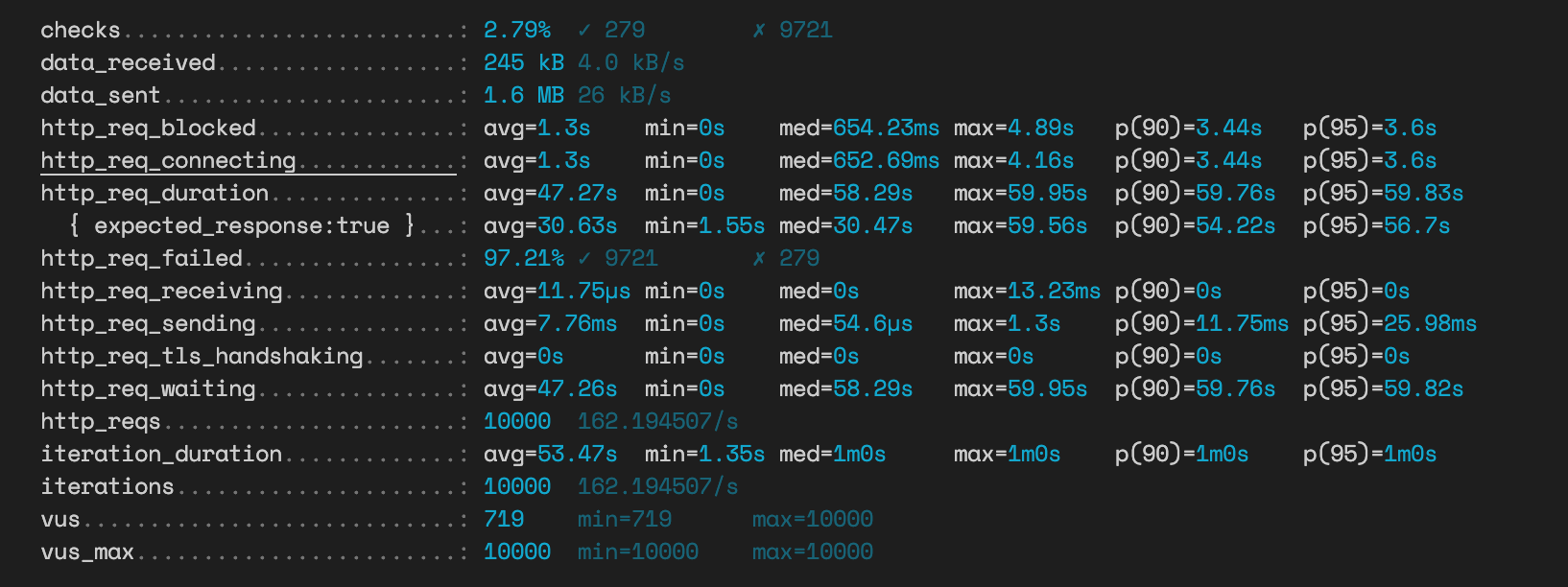
JSON 방식 투표 API
실패율이 97%나 된다.
timeout 변경
위 방식으로 했더니 timeout으로 인한 실패율이 굉장히 많았고 실패율이 너무 높아서 제대로 된 성능측정이 아닌 것 같아서 (TPS를 제대로 구할 수 없어서) timeout을 조정한 뒤 다시 테스트 했다.
export default function() {
...
const params = {
headers: {
'accept': '*/*',
'Content-Type': 'application/json'
},
timeout: '600s', // 600초 (10분) 이내에 응답이 없으면 타임아웃으로 처리
};
...
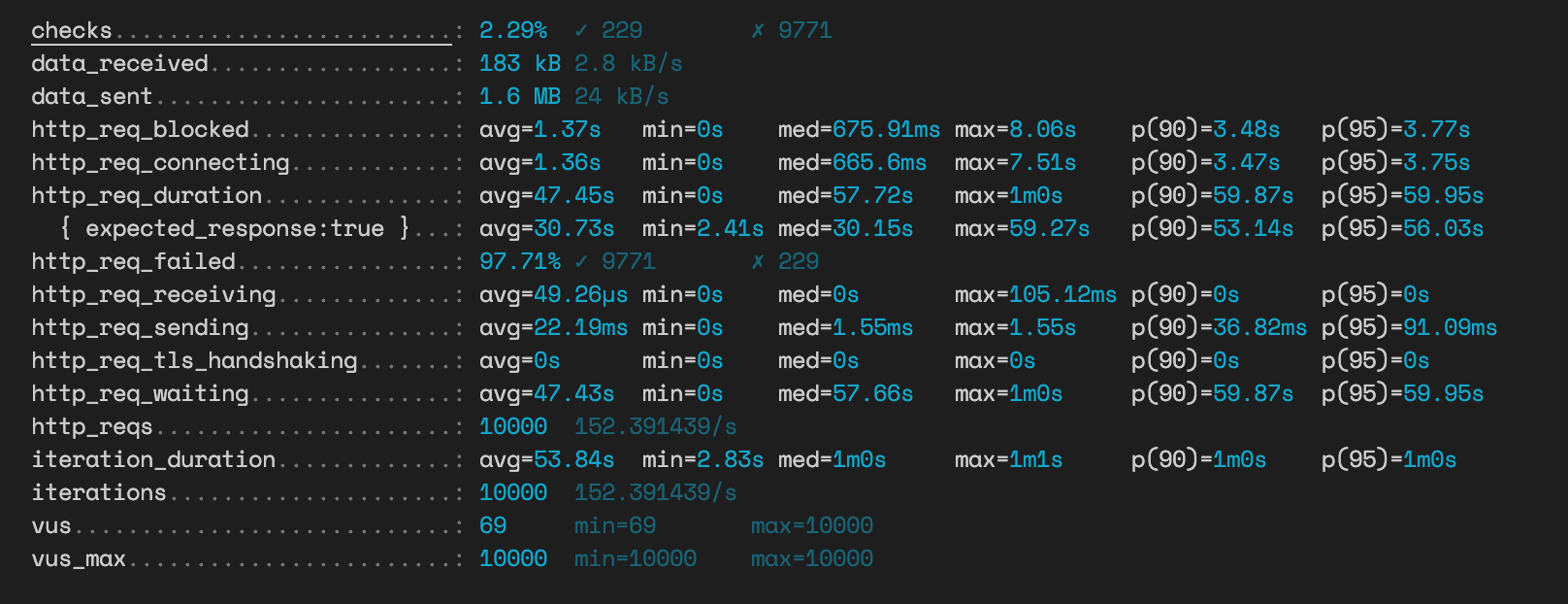
}
JSON 맵핑 방식의 투표 API는 1분간 10000명의 사용자가 몰렸을 때 평균 11.44초의 응답 시간을 갖고 그마저도 실패율이 84.42%나 된다는 것을 알 수 있다.
파일 디스크립터 설정 변경
Network IO나 DB Connect 후 파일을 작성하는 것도 모두 IO이기 때문에 파일 디스크립터 설정의 영향을 받는다.
현재 파일 디스크립터의 개수는 1024개 였고 이를 임시로 65000까지 늘리고 API 성능을 한 번 체크해보기로 한다.
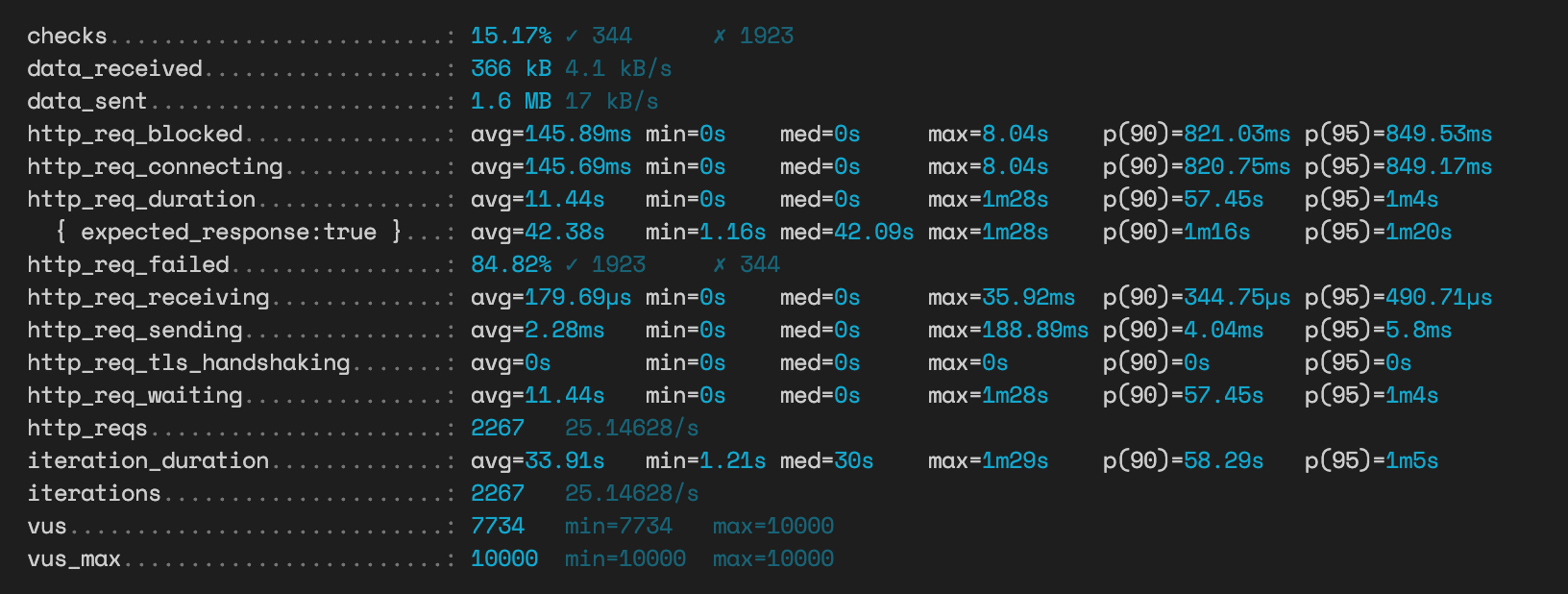
ulimit -n 65000 # 65000으로 설정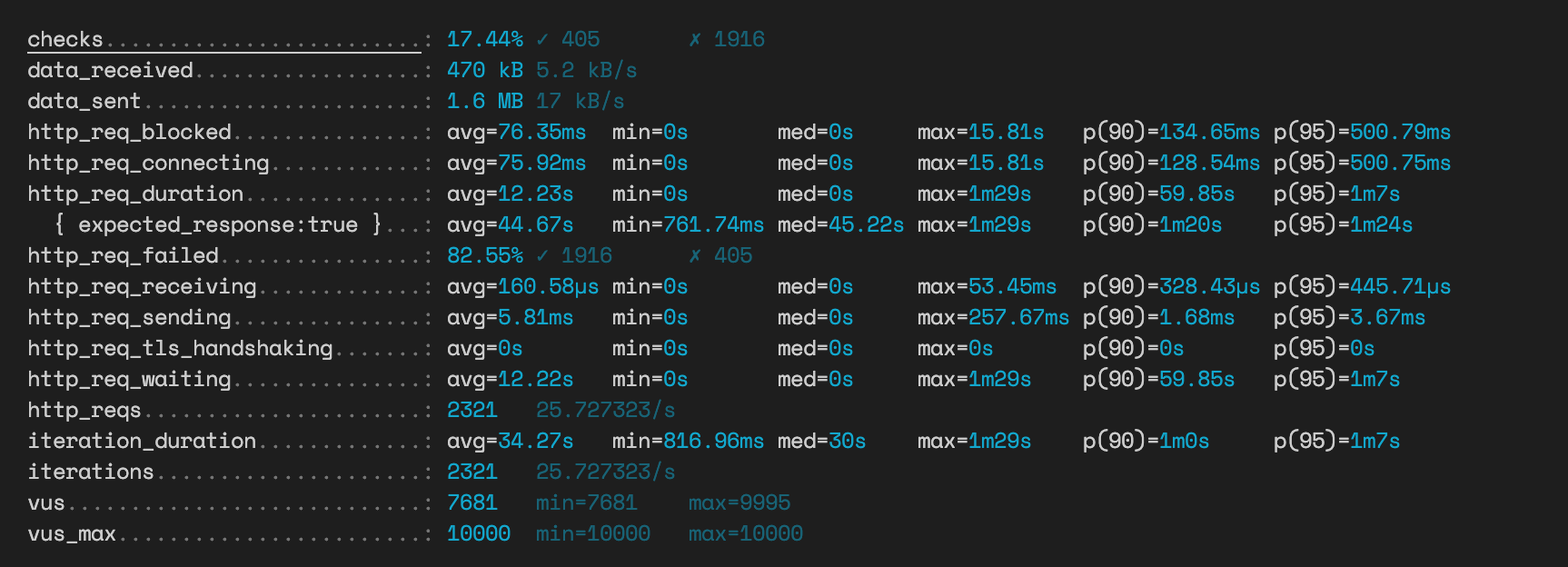
이게 문제가 아닌가?
연관관계 맵핑 방식 투표 API
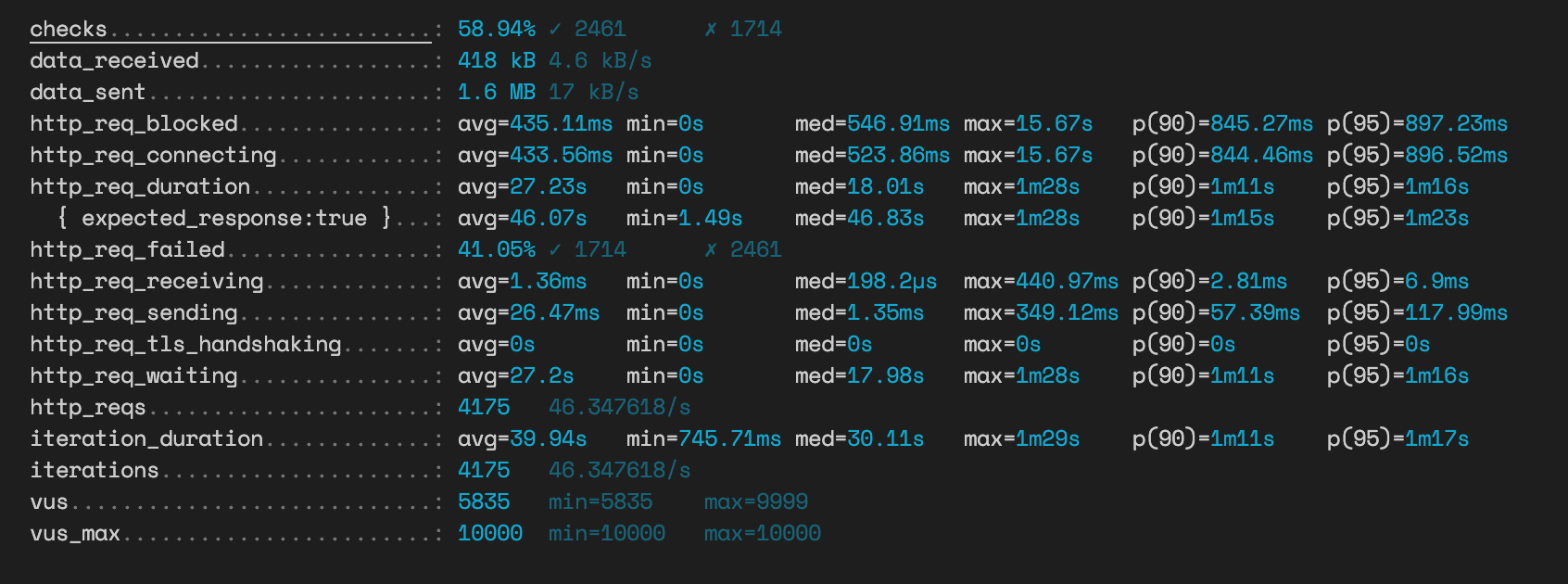
성공률이 높아지고 응답시간이 굉장히 올라간 것을 알 수 있는데 이건 성공률이 올라갈수록 어쩔 수 없는 부분이라는 생각이 들었다. 그래서 이 방식으로는 정확한 비교가 힘들거란 생각이 들었다.
500명의 사용자가 4번의 투표를 하는 경우 (테스트 성공사례! 주목!)
현실적인 상황을 고려해보기 위해서 options를 다음과 같이 수정했다.
export let options = {
vus: 500, // 동시에 실행할 가상 사용자 수
iterations: 2000, // 반복 횟수 (총 요청 수 : 반복 횟수 / 동시 사용자 수)
duration: '20m', // 최대 테스트 지속 시간
};JSON 방식 투표
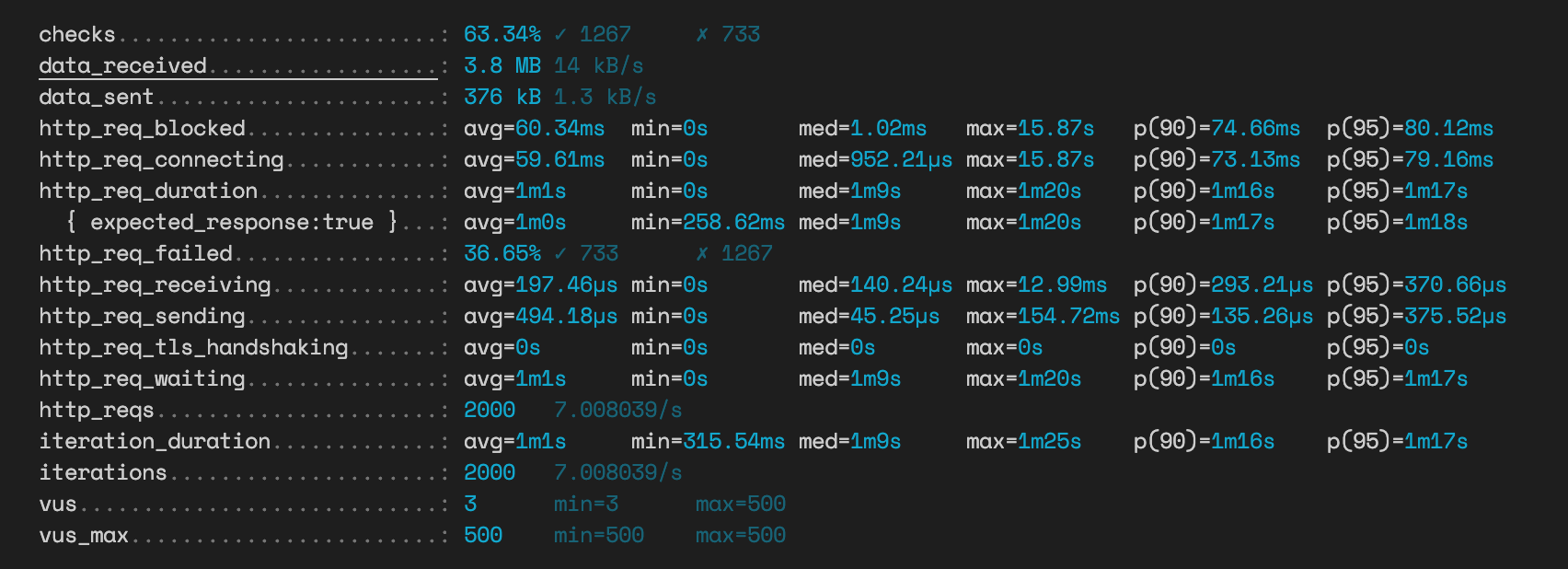
2000건의 투표 중 733건이 실패하고도 1분 1초라는 평균 응답 시간이 소요됐다.
연관관계 맵핑 방식 투표
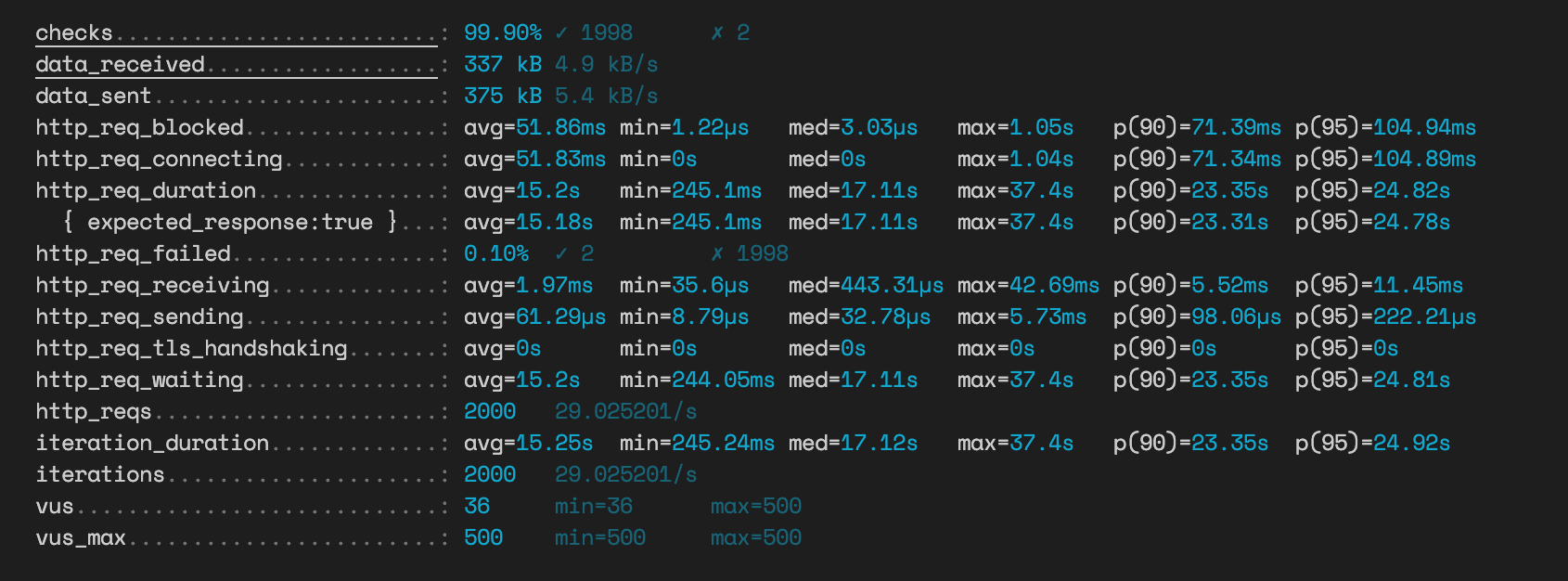
2000건의 request 중 2건이 실패하고 평균 응답 시간은 15.2초이다.
단순 조회 API
여기서는 Post와 모든 Vote를 Response로 보내주는 API를 테스트 해볼려고 한다. 가정은 100명의 사용자가 각각 10개의 게시물을 읽어본다는 가정을 하고 테스트를 진행한다. 데이터는 10개의 Post에 각각의 방식으로 10000개씩 투표 데이터를 넣어둔 방식이다.
👇 테스트 스크립트
import http from 'k6/http';
import { check } from 'k6';
import { SharedArray } from 'k6/data';
export let options = {
vus: 100, // 동시에 실행할 가상 사용자 수
iterations: 1000, // 반복 횟수 (총 요청 수 : 반복 횟수 / 동시 사용자 수)
duration: '10m', // 최대 테스트 지속 시간
};
export default function() {
const url = 'http://192.168.1.12:8080/jpa/all';
// const url = 'http://192.168.1.12:8080/jpa/12';
const params = {
headers: {
'accept': '*/*',
'Content-Type': 'application/json'
},
timeout: '600s', // 600초 (10분) 이내에 응답이 없으면 타임아웃으로 처리
};
const res = http.get(url, params);
check(res, {
'is status 200': (r) => r.status === 200,
});
}👇 테스트할 DTO
public class PostResponse {
private Long id;
private String title;
private String content;
private List<VoteResponse> vote;
}
public class VoteResponse {
private Long id;
private Long memberId;
private Boolean vote;
}JSON 역정규화 방식 조회 테스트
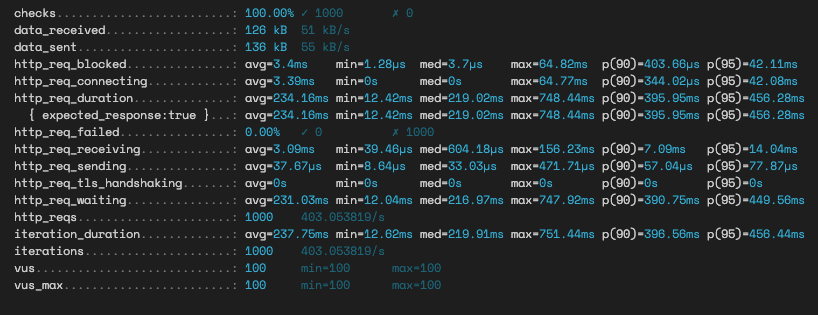
연관관계 맵핑 방식 조회 테스트
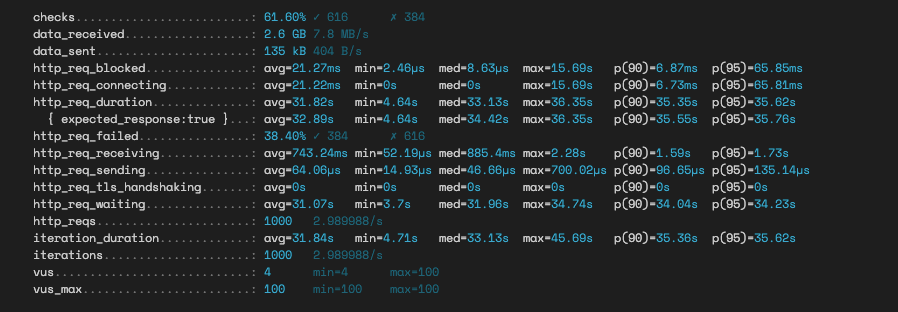
페이지네이션을 적용하지 않은채 모든 데이터를 연관해서 가져오는 방식은 당연(?)하게도 압도적으로 JPA가 더 오래 걸렸다. 어디서 발생하는 병목인지는 굳이 추적해보지 않아도 로그만 보고 파악할 수 있는게 N+1 문제가 발생한다는 것을 알 수 있다.
투표율 조회 API
그런데 위와 같은 방식으로 Post를 조회할 일은 없다. 보통 투표 데이터를 가지고 투표율을 집계해서 사용하는 방식으로 많이 사용할테니 이에 맞는 상황을 가정해서 다시 로직을 수정해보려고 한다.
👇 테스트할 DTO
public class PostRatioResponse {
private Long id;
private String title;
private String content;
private List<VoteRatio> votes;
@Getter
@Builder
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public static class VoteRatio {
private Boolean voteOption;
private Double ratio;
}
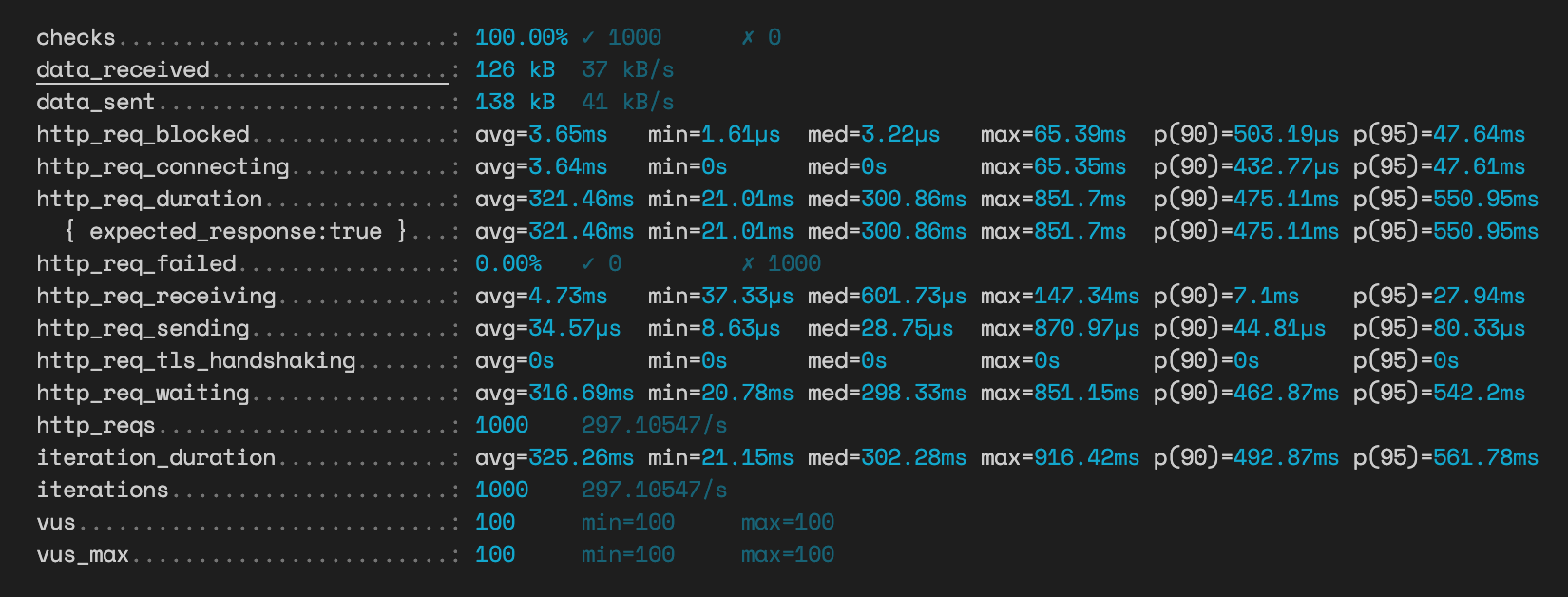
}JSON 역정규화 방식 조회 테스트
연관관계 맵핑 방식 조회 테스트
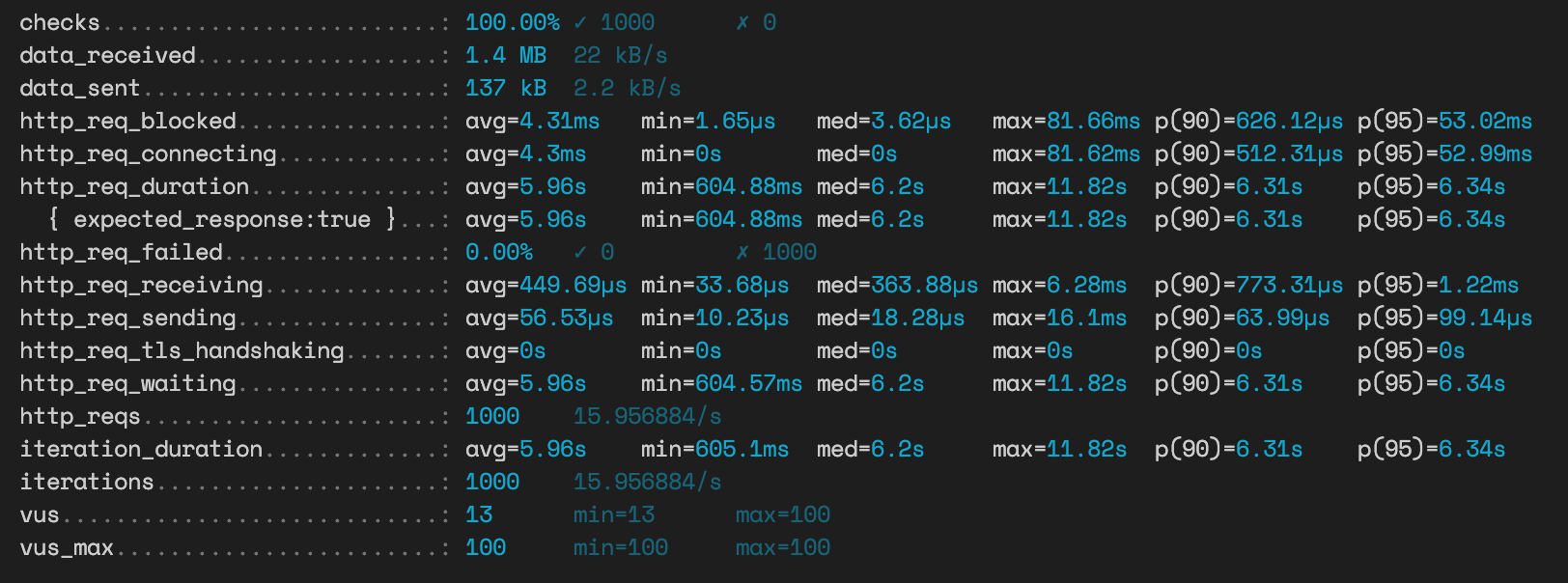
대략 연관관계 맵핑 방식으로 조회하는 쿼리가 18배정도 느리다.
Index 설정
현재 각각의 PostId에 대해서 투표율을 구하기 위해서 true일 경우(voteOption1)의 개수와 false일 경우(voteOption2)의 개수를 구하는 쿼리를 사용 중이다.
즉, Post 1개당 날아가는 쿼리가 3개인 것이다. 이걸 개선하기 위해서 한 번의 쿼리로 하는 방법도 여러가지 시도를 해봤지만 생각보다 쿼리가 많이 복잡해지거나 투표 옵션이 반드시 2개일 경우 동작한다는 단점 등이 있어서 그 부분은 포기하고 Index를 설정해보려고 한다.
👇 인덱스 쿼리
CREATE INDEX idx_post_id_vote ON vote (post_id, vote);Index 설정 후 연관관계 맵핑 방식 성능
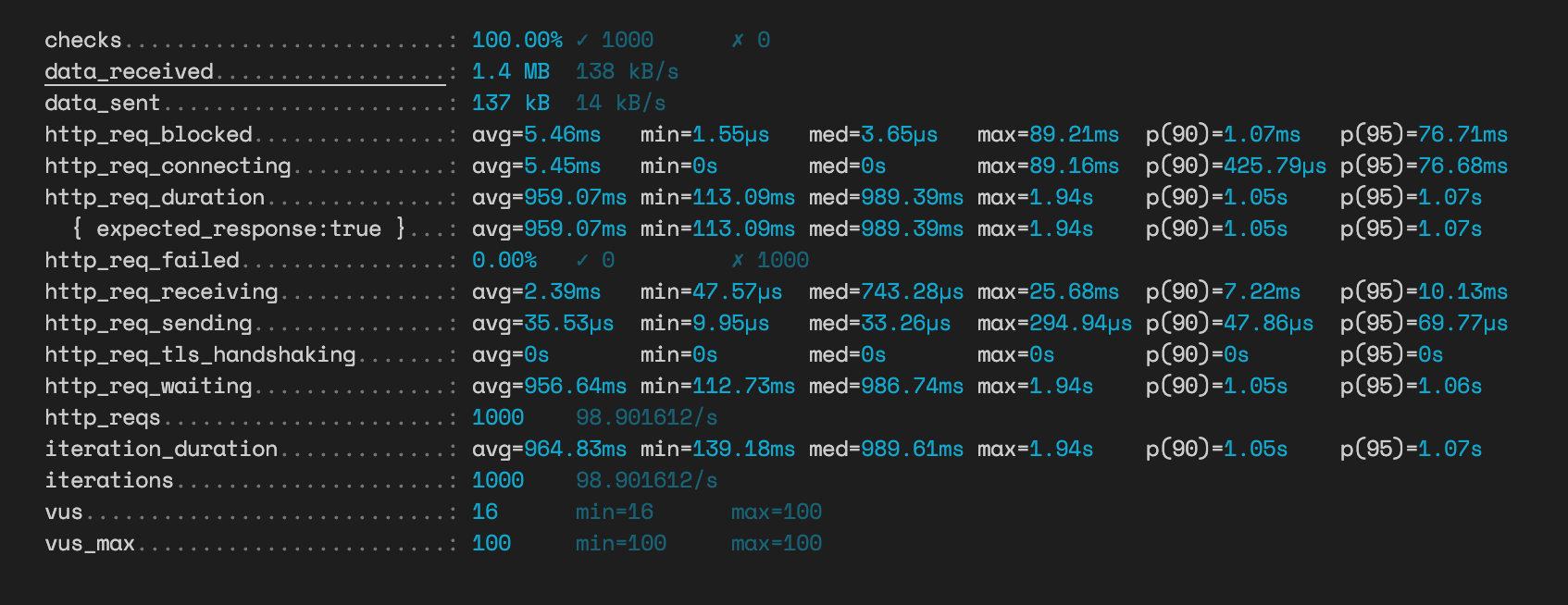
대략 6배의 성능 개선이 있었다. 물론 캐싱을 더 활용하면 당연히 성능 격차는 더 벌어질 수 있겠지만 그건 애초에 이 글을 작성한 목적과 다르므로 패스하기로 한다.
🥅 결론
해당 투표에서는 쓰기 성능이 중요하다고 느꼈고 읽기 성능은 캐싱이나 다른 방식으로 성능을 개선할 수 있기 때문에 현재 프로젝트에서는 연관관계 맵핑 방식을 사용하기로 했다.
역정규화는 아래와 같은 경우에 사용한다.
- 읽기 성능이 중요한 경우
- 데이터의 변경이 잦지 않은 경우
☣️ Error
DB Connection Pool 에러
java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30007ms (total=10, active=10, idle=0, waiting=5)
DB Connection Pool에 연결하는 시간이 초과되었을 때 발생하는 에러이다. 아래에서 참고한 자료조사에 따르면 적절한 Pool 개수를 구하는 공식은 다음과 같다.
최적의 풀 크기=CPU 코어 수×2+효율성 계수그래서 위 공식을 토대로 m1 Pro를 기준으로 다음과 같이 Connection Pool을 세팅했다.
spring:
datasource:
hikari:
minimum-idle: 20 # 최소 유휴 세션 개수
maximum-pool-size: 20 # 최대 풀 크기