배경
지난 시간에 istio를 도입과정에서 발생하는 다양한 에러들에 대해서 다루었다. 이번에는 istio 도입 이후 발생하는 HTTP 503 오류에 대한 원인 파악과 해결 과정에 대해서 소개하고자한다. 트러블슈팅 과정이 다소 험난?했는데 그만큼 다양한 사람들에게 도움이 되었으면 좋겠다.
또한 해당 이슈는 LG Uplus의 기술블로그, 그리고 다양한 github에서 제기되는만큼 전통적인 문제로 보인다

tl;dr
-
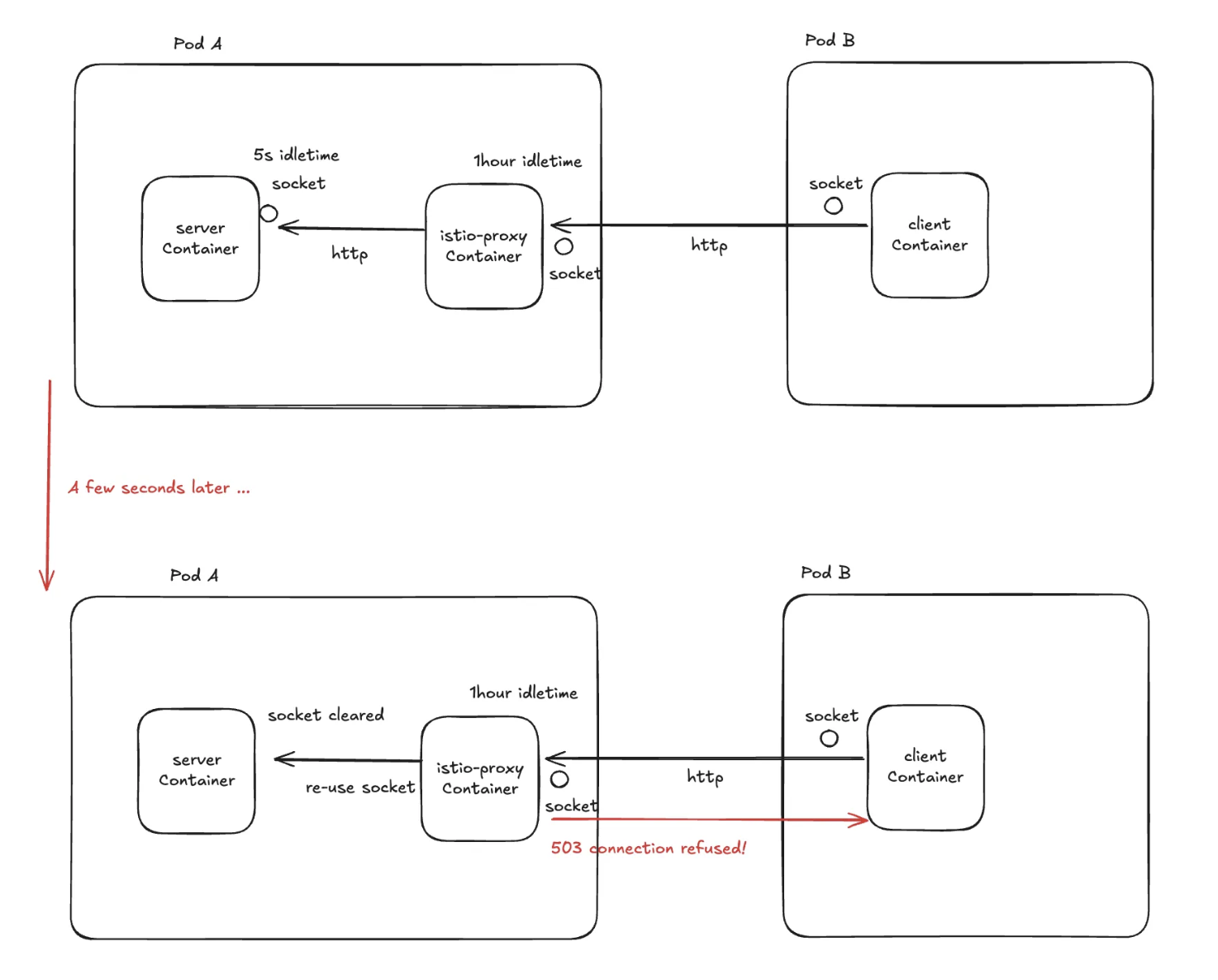
Node.js, FastAPI 등은 기본적으로 HTTP Keep-Alive가 활성화되어 있으며, 5초 이상의 유휴 시간이 지나면 커넥션을 종료하게 된다.
-
반면, istio proxy는 기본 idleTimeout이 1시간으로 설정되어 있어, 해당 커넥션이 여전히 유효하다고 간주하고 재사용을 시도한다.
-
이때 istio proxy는 서버가 이미 닫은 소켓에 요청을 보내게 되며, TCP 레벨에서 RST 또는 FIN 패킷을 받게 된다.
-
이로 인해 Envoy는 클라이언트에게 503 오류 (upstream_reset_before_response_started) 를 반환한다,
-
트래픽이 많을 경우 소켓 수가 급증하면서, 서버가 보낸 연결 종료 신호(RST/FIN)가 프록시에서 제때 처리되지 못하고, 그 사이에 프록시가 해당 죽은 커넥션을 재사용하려는 레이스 컨디션이 발생할 확률이 높아져 503 에러가 빈번하게 발생한다.
1. 현상 파악
가장 먼저 어떤 서비스에서, 어떤 경우에 503에러가 발생하는지 파악하기위해 프록시 서버의 datadog에서 집계되는 에러 로그와 기록된 api path를 추적해보았다.
그 결과 특정 api path로 프록시할 때만 503 에러가 과도하게 발생되는 것을 확인하였다.
2. 에러 가시성 확보
현상을 파악하였으니, 원인 파악을 시작한다. 원인 파악을 위해 반드시 필요한 정보는 에러 로그! 에러 가시성을 확보하기위해 아래 활동을 하였다.
-
Telemetry API를 사용하여 access log를 활성화하였다. 이를 통해 inbound, outbound 요청에 대한 로그를 남긴다.
-
매번 컨테이너에서 로그를 보기 번거로우니 istio-proxy에 annotation을 추가하여 데이터독으로 로그를 보낼 수 있도록 설정하였다. 이를 통해 데이터독에서 로그를 볼 수 있게 설정하였다.
(사진은 보안상 문제로 생략)
istio-proxy의 로그를 좀 더 살펴본 결과 A서버의 특정 api를 사용할 때 503에러가 급증하는 것을 볼 수 있었다. 해당 서버의 APM으로 확인하니 이는 rps 1000까지되는 대량 트래픽을 받는 path 였다.
3. 문제 재현
2번 단계에서 문제는 1000 rps 이상 대량 트래픽 상황에서 발생한다는 힌트를 얻었다. 트래픽이 많아지면 해당 문제가 발생한다는 사실을 확인하기위해 개발 환경에서 부하테스트를 진행한다.
같은 조건으로 문제를 재현하기위해 side-car container가 주입된 상태로, 대량 트래픽을 in-cluster로 발생시켜야했다. 그래서 k6를 ephemeral container로 주입하고 문제의 A 서버로 부하테스트를 진행했다. 그 결과 503 에러가 재현되었다.
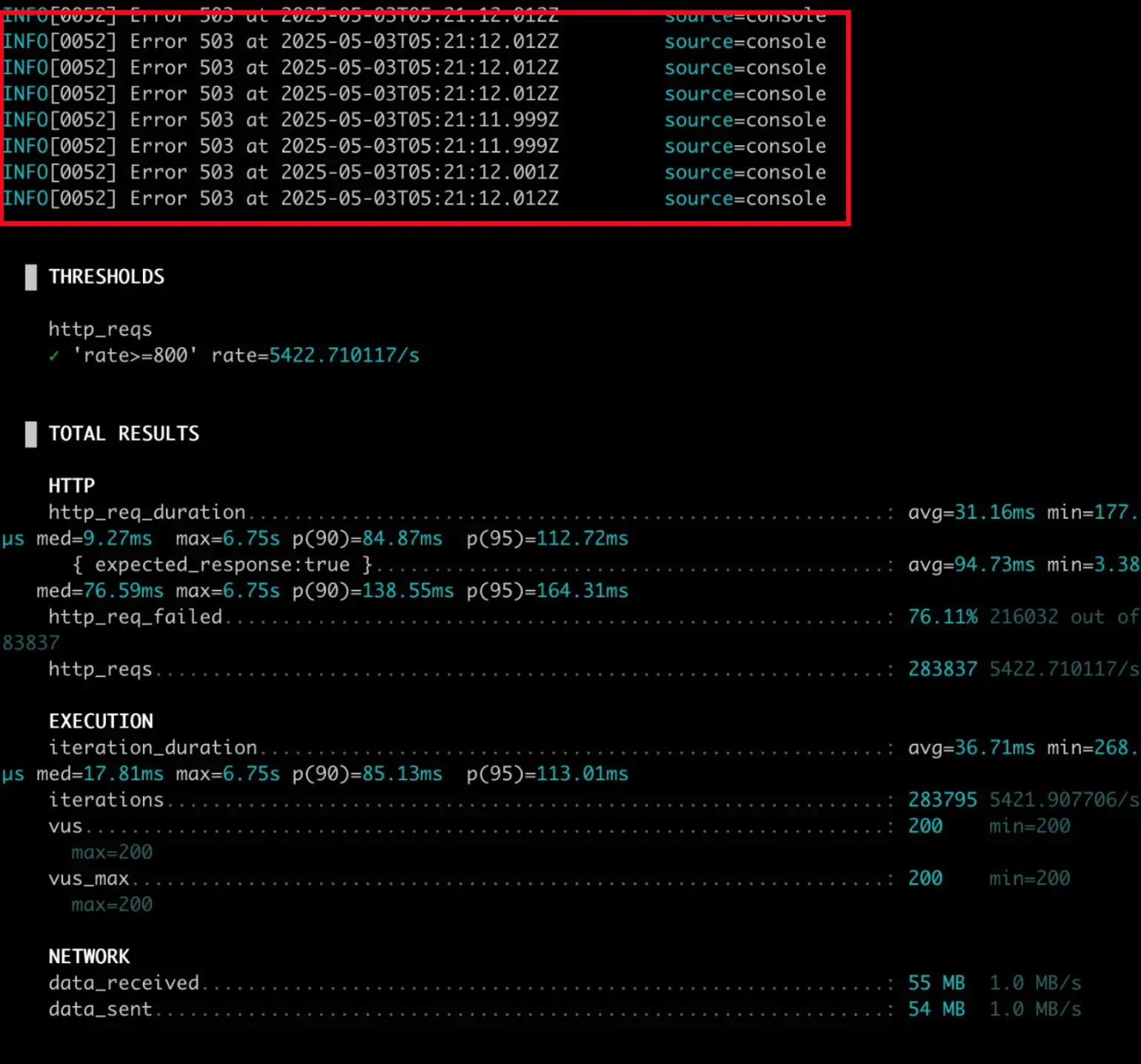
4. 원인 고찰
문제를 발생시키는 사항이 확인이되었으므로 원인을 파악해보자. 여러 조사를 통해 파악하고 내린 결론은 아래와 같다.
http keep alive 구조에서 기존에 tcp 연결에 사용된 소켓을 재사용 풀에 넣고 재사용한다. 원래대로라면 서버측에서 tcp 연결 종료하면 클라이언트단에서 해당 소켓을 http 요청에 재사용하지않고 정리해야하지만 대량 트래픽시 tcp 연결 종료 과정에서 클라이언트의 소켓을 재사용하게 되면서 503 에러가 발생한 것 이었다.
5. 해결 방법 시도
istio의 destinationRule을 통해서 쿠버네티스 내부 통신에서 특정 서비스로 향할 때 유휴 소켓 정리 시간을 조절하였다. (http idleTimeout) 그러자 부하테스트를 진행해도 503 에러가 발생하지않았다.

6. 운영 환경 적용
이후 운영 환경에 적용하여 해당 에러가 90% 이상 감소함을 확인하였다.
후기
원인의 파악과 해결 과정에서 정말 많은 것을 배웠던 트러블슈팅이다.
-
가장 기초적으로 모든 원인 파악의 시작은 반드시 에러로그를 확인해야한다는 원칙을 다시 일깨워주었다.
-
1번은 수행하기위해 사내 observability가 정말 잘 갖춰져야한다는 것을 배웠다. (잘 갖춰져있어서 정말 다행..)
-
os 레벨에서의 소켓에 대해서 다시 공부하게 해주었고, 역시나 cs 공부를 꾸준히 해야한다고 느꼈다..
-
ephemeral container를 사용한 디버깅 방법에 대해서 익혔다! 이후에도 netshoot 컨테이너를 주입하여 다양하게 트러블슈팅에 사용하고있다.

안녕하세요 ^^
혹시 'http idleTimeout' 몇으로 설정하셨을까요??
그리고 node server의 'keepAliveTimeout' 설정은 초기값인 5s로 놔두셨나요?
답변주시면 정말 감사하겠습니다!