
❓ Question
📖 Before Start
BFS, DFS 알고리즘을 활용하여 이차원 배열을 순회하는 문제다.
이번 문제는 BFS, DFS 를 활용하여 이차원 배열을 순회하는 문제였다.
그래프 탐색의 경우 가장 자신 있는 분야였기에, 골드 문제를 도전했다.
✒️ Design Algorithm
길을 지나오며 만난 알파벳 을 모두 체크해서, 중복인지를 검사해보자.
가로 C 칸, 세로 R 칸으로 이루어진 표 모양의 보드가 놓여져 있다.
이 보드에는 알파벳 (A ~ Z) 이 하나씩 모든 칸에 적혀져 있다고 한다.
사용자는 (1, 1) 좌표에서 상하좌우 방향으로 한 칸씩 이동이 가능하고,
각 칸에 적힌 알파벳은 오직 한 번만 만날 수 있다. 중복은 허용하지 않는다.
이때 사용자가 가장 멀리 갈 수 있는 거리, 즉 지나온 칸의 수량을 구해야 한다.
그러면 사용자가 지나오면서 만난 알파벳을 저장하면 되겠다는 생각이 들었다.
💻 Making Own Code
❌ Wrong Code
import sys
sys.setrecursionlimit(10 ** 6)
read = sys.stdin.readline
R, C = map(int, read().split())
matrix = [list(read().rstrip()) for _ in range(R)]
direction = [(1, 0), (-1, 0), (0, 1), (0, -1)]
max_move = 0
words = set(matrix[0][0])
def dfs(loc_y, loc_x, move):
global max_move
max_move = max(max_move, move)
for dir_y, dir_x in direction:
ny, nx = dir_y + loc_y, dir_x + loc_x
if 0 <= ny < R and 0 <= nx < C and matrix[ny][nx] not in words:
if matrix[ny][nx] not in words:
words.add(matrix[ny][nx])
dfs(ny, nx, move + 1)
words.remove(matrix[ny][nx])
dfs(0, 0, 1)
print(max_move)내가 코드를 설계한 방식은 아래와 같다.
- DFS 탐색을 통해 다음으로 이동 가능한 칸에 적힌 알파벳을 체크한다.
- 만약 중복이 아니라면 해당 칸으로 이동하고, 이동 횟수를
1늘린다. - 이동된 칸에 적힌 알파벳을 집합
words에 새롭게 추가한다. - 해당 칸의 재귀가 종료되었다면 이전에 추가했던 알파벳을 제거한다.
결국 DFS 알고리즘을 활용하여 탐색을 재귀적으로 진행하고, 만약 재귀가 끝났다면
탐색을 종료하고 돌아가기 위해 백트래킹 을 활용하여 추가했던 알파벳을 다시 지웠다.
처음 설계도 좋았고 결과도 전부 괜찮다고 생각했다. 하지만 메모리 초과가 문제였다.
따라서 알파벳이 아닌 아스키 코드 로 이를 치환하여 코드를 완전히 재수정 해야 했다.
✅ Correct Code (with DFS)
import sys
read = sys.stdin.readline
R, C = map(int, read().split())
# 입력 받은 대문자 알파벳을 0 ~ 26 사이의 숫자로 변환. (ord(A) = 65)
matrix = [list(map(lambda x: ord(x) - 65, read().rstrip())) for _ in range(R)]
direction = [(1, 0), (-1, 0), (0, 1), (0, -1)]
max_move = 1
words = [False] * 26 # A ~ Z 알파벳 갯수만큼 List 제작
def dfs(loc_y, loc_x, move):
global max_move
max_move = max(max_move, move)
for dir_y, dir_x in direction:
ny, nx = dir_y + loc_y, dir_x + loc_x
if 0 <= ny < R and 0 <= nx < C and not words[matrix[ny][nx]]:
words[matrix[ny][nx]] = True
dfs(ny, nx, move + 1)
words[matrix[ny][nx]] = False
# 가장 첫 지점의 경우 항상 경유하므로 True로 변환.
words[matrix[0][0]] = True
dfs(0, 0, max_move)
print(max_move)빡빡한 시간과 메모리 탓에, 문자를 아스키 코드 값으로 치환해야 했다.
여러번 시도를 해봤지만 결국 답은 ord 함수를 활용한 아스키 코드 활용 뿐이었다.
이쯤 되니 굳이 DFS 로 시도하지 않아도 BFS 로도 가능할 것 같아 코드를 작성했다.
문제의 핵심은 지금까지 탐색을 진행하며 거쳐온 알파벳의 목록 을 유지하는 것이니,
BFS 탐색으로도 이를 충분히 해결할 수 있다는 생각이 들어 내린 결론이었다.
✅ Correct Code (with BFS)
import sys
read = sys.stdin.readline
R, C = map(int, read().split())
matrix = [list(read().rstrip()) for _ in range(R)]
direction = [(1, 0), (-1, 0), (0, 1), (0, -1)]
max_move = 1
def bfs():
global max_move
# y, x, 이동하면서 지나친 알파벳을 합친 문자열을 하나의 요소로 묶음
# 시작은 (0, 0) 좌표부터 이므로 굳이 매개변수를 받지 않아도 됨.
queue = {(0, 0, matrix[0][0])}
while queue:
ny, nx, words = queue.pop()
# 지금까지 만나온 알파벳의 수량이 이동한 칸의 갯수와 같음.
# 따라서 이를 기존의 최대 이동 거리와 비교하여 계산해야 함.
max_move = max(max_move, len(words))
for dir_y, dir_x in direction:
my, mx = ny + dir_y, nx + dir_x
if 0 <= my < R and 0 <= mx < C and matrix[my][mx] not in words:
queue.add((my, mx, words + matrix[my][mx]))
bfs()
print(max_move)deque 에 들어가는 원소의 구조를 3개로 나누어 설계하였다.
덱에 들어갈 원소의 구조는 좌표값과 탐색을 거쳐 지나온 알파벳을 합친 문자열이다.
만약 새로운 좌표로 이동을 했다면, 기존의 문자열에 새로운 알파벳을 합치면 되었다.
그리고 탐색을 거치며 최대 이동 거리 값을 매 반복 시마다 갱신시키니 해결이 되었다.
아래의 표를 봐도 DFS 보다 BFS 의 성능이 훨씬 더 월등하게 나온 것을 알 수 있었다.
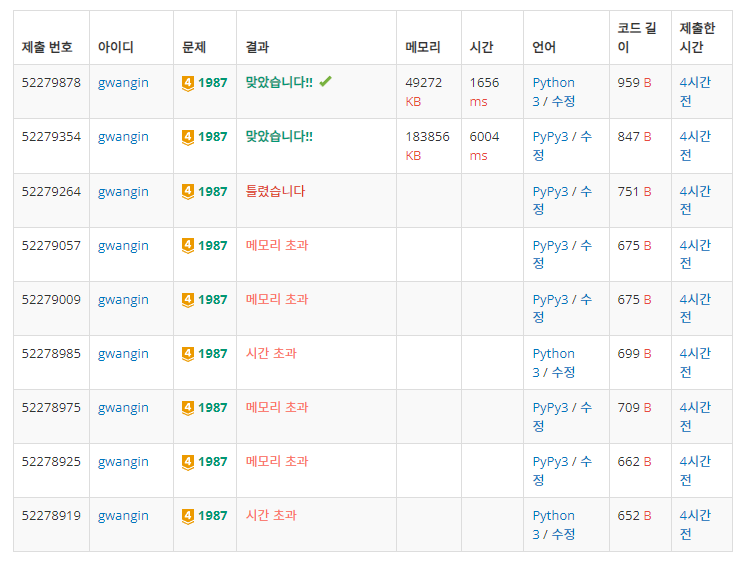
물론 PyPy3 이 메모리와 시간을 많이 먹긴 하지만, 그래도 BFS가 더 나았다
📖 Conclusion
📒 github Code link
https://github.com/RookieAND/BaekJoonCode
이번 문제는 정말 여러모로 나를 난처하게 만든 문제라고 생각한다.
어떤 방법을 써도 DFS로는 좀처럼 해결이 되지 않았는데, 결국은 풀어서 다행이라 생각한다.
