
[정답이 아니라 풀이 기록입니다.]
광고의 길이인 n이 들어온다. 광고에 문구 L을 무한히 반복하고 임의의 n칸을 잘라낸 문자열이 광고 문자열로 주어질 때, 가능한 L의 최소 길이를 구하여라.
접근
- 입력으로 들어온 n자리 문자열이 문구로 시작한다고 생각합니다.
- 문구를 넣었지만 광고의 길이를 채우지 못했다면 채울 때 까지 반복됩니다.
- 문구는 1자리에서 n자리까지 가능합니다.
구현
반복
문구는 반복됩니다.
만약 문구가 [ a b c d ] 이고 광고의 길이가 6이라면 [ a b c d a b ]와 같이 길이를 채우게 반복 됩니다.
그렇기에 문구가 광고의 길이보다 짧다면 문구의 접두사가 문구 뒤에서 다시 접미사로 나타나게 되고, 광고 문자열 전체에서 접두사와 접미사가 1글자라도 일치하는 구간이 생기게 됩니다.
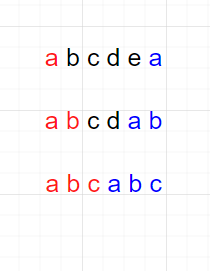
문구가 6글자 -> 반복을 통해 0칸 채움 -> 접미사와 접두사 0글자 일치
문구가 5글자 -> 반복을 통해 1칸 채움 -> 접미사와 접두사 1글자 일치
문구가 4글자 -> 반복을 통해 2칸 채움 -> 접미사와 접두사 2글자 일치
문구가 3글자 -> 반복을 통해 3칸 채움 -> 접미사와 접두사 3글자 일치
위로 부터 접미사와 접두사가 최대로 일치할 때, 접미사 부분이 길이를 채우게 문구가 반복된 부분이라는 것을 얻을 수 있습니다.
즉, 접미사와 접두사가 최대로 일치하는 길이를 찾고, 그것을 문자열 길이에서 빼주면 문구의 길이를 구할 수 있습니다.
KMP
그럼 이제 접미사와 접두사가 최대로 일치하는 길이를 찾아봅시다.
이 때 KMP가 사용 됩니다.
문자열 검색 알고리즘인 KMP는 문자열을 검색할 때 최적화를 위해 pi배열이란 것을 사용합니다.
pi배열은 문자열의 0~i번의 범위에서 접미사 == 접두사가 될 수 있는 것 중 가장 긴 길이를 pi[i]에 저장하는 배열로, 이 문제는 pi배열을 생성하면 답을 구할 수 있습니다.
코드는 아래와 같습니다.
int pi[1000002];
void kmp(const char* a) {
int l = strlen(a);
int i = -1;
int j = 0;
pi[j] = -1;
while (j < l) {
if (i == -1 || a[i] == a[j]) {
pi[++j] = ++i;
}
else {
i = pi[i];
}
}
}답 출력
kmp를 통해 pi배열 값을 구하고 나면
pi[n]에 광고 문자열의 접미사와 접두사가 최대로 일치하는 길이가 저장되어 있습니다.
그렇기에 n에서 pi[n]을 뺀 뒤 출력합니다.
int main() {
scanf("%d",&n);
cin>>in;
kmp(in.c_str());
printf("%d",n - pi[n]);
}마무리
코드는 이게 P4가 맞나 싶을 정도로 간단한데, 좀 많이 헤맸습니다.
접두사 접미사로 접근하는게 어렵네요.
끝

우와 이해가 한 번에 되었어요!