Adsp 준비 (2)


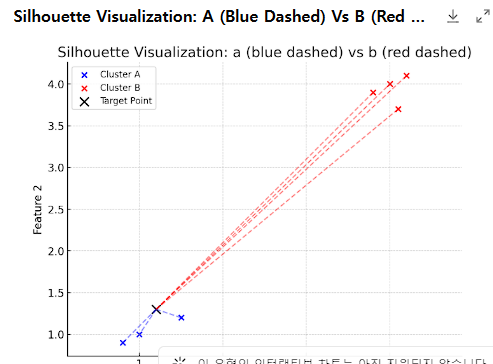
파란점(내부관계)은 가까울 수록 좋고 빨간점(외부관계)은 멀수록 좋음
파란점이 가깝다는건 그만큼 군집화가 잘된다는것
빨간점이 멀다는건 그만큼 클러스터끼리 구분이 잘되어있다는것
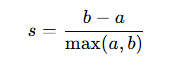
그래서 해당 공식을 살펴보면 b가 a보다 크고 a값이 작을 수록 1에 수렴한다는 것을 알 수 있고 그것이 클러스터에 잘 녹아들었다는 근거


문제탐색→문제정의→해결방안→타당성검토

KB < MB < GB < TB < PB < EB < ZB < YB
크엠지티피이지와이

성과 x

Precision은 활용 vs 안정 이라는 기준으로 나눌 수 있는 개념이 아님.
Accuracy는 전체 정답률(정답 개수 / 전체 예측 수)일 뿐이지, "안정적"을 나타내는 지표는 아님.
오히려 Precision과 Recall은 상황에 따라 더 중요도가 바뀜:
스팸 필터 → Precision 중요 (틀리게 정답이라고 하면 큰일)
암 진단 → Recall 중요 (놓치면 안 되니까)

공분산은 무한대로 값이 늘어남 그래서 이게 얼마나 차이가 많이나는건지 알아채기가 모호함

이상적인 분류기 → FPR=0, TPR=1 → (0, 1)
ROC Curve에서 왼쪽 위 모서리 = 완벽한 분류기 위치

과적합 방지 : 의사결정나무 가지치기

K-means 군집은
군집 개수를 사전에 설정, inertia를 사용하여 그래프를 그리고 elbow기법으로 최적의 k를 정한다


① Q-Q plot → ✅ 정규성 확인 방법 맞음
Quantile-Quantile plot
이론적 정규분포와 실제 데이터의 분위수를 비교
직선 형태로 나타나면 정규성을 띤다고 판단함
② 결정 계수 (R²) → ❌ 정규성과 관련 없음
회귀 분석에서 예측값이 실제값을 얼마나 잘 설명하는지를 나타냄
정규성 판단과는 무관, 모델 적합도 평가 지표임
③ 히스토그램 → ✅ 정규성 확인 가능
데이터 분포를 시각화해서 종 모양인지 확인할 수 있음
다만 시각적 판단이라 주관적일 수 있음
④ 첨도와 왜도 → ✅ 정규성 판단에 사용
첨도: 뾰족한 정도 (정규분포 = 첨도 0 기준)
왜도: 좌우 비대칭 정도 (정규분포 = 왜도 0 기준)
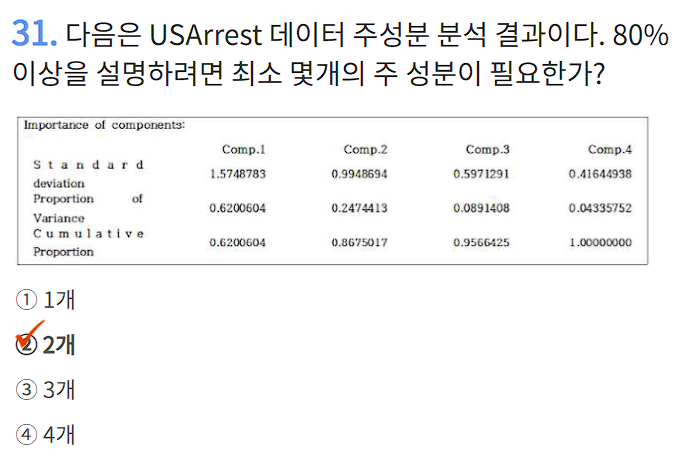
"Cumulative Proportion" 열은 누적 설명력(= 각 주성분까지 누적 설명한 비율)을 나타냄
80% 이상을 설명하려면 누적 비율이 0.8 이상이 되는 지점을 찾으면 됨
각 주성분까지의 누적 설명력은:
1개 사용 → 62.06% (불충분)
2개 사용 → 86.75% (✔️ 80% 이상)
3개 사용 → 95.66%
4개 사용 → 100%
단순히 이전꺼에다 더해서 누적을 만들고 그 비율이 0.8 이상이면 되는것
1.5는 진즉에 충족하고
0.6따리 두개는 그 다음 comp2에서 각각 0.2, 0,8을 더하므로 0.8이상이 되어 충족

단순 연관분석과 다르게 시간적 순서(Timeline)가 존재하며, 원인과 결과의 흐름을 고려할 수 있음



• 다층 신경망 (Deep Neural Network)에서 은닉층이 너무 많을 경우, 역전파(backpropagation) 과정에서 기울기(gradient)가 점점 작아지는 현상이 발생합니다.
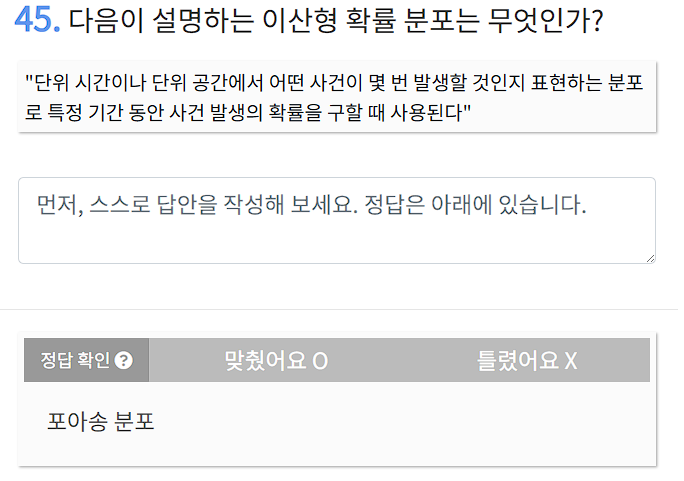
• 이로 인해 앞쪽 은닉층 (즉, 입력층에 가까운 층)에서는 가중치가 제대로 업데이트되지 않게 되어, 모델 학습이 제대로 이루어지지 않습니다.

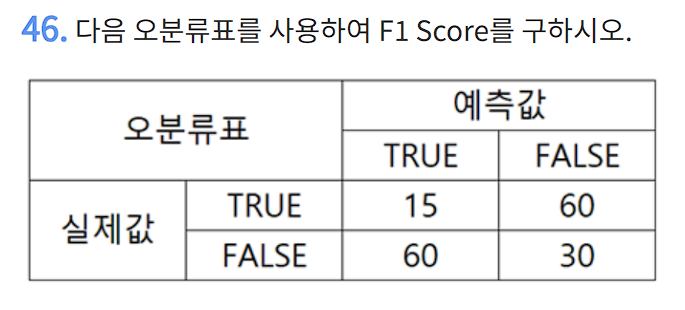
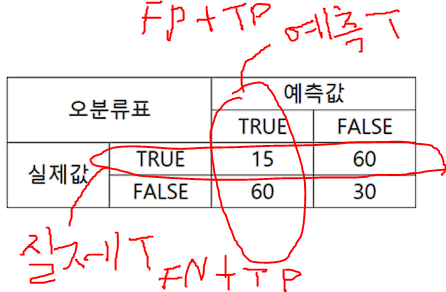
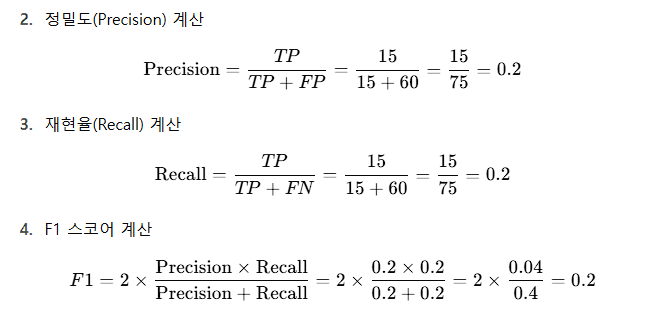
연근매워
연결 정도(degree) 중심성
근접(closeness) 중심성
매개(betweenness) 중심성
위세(eigenvector) 중심성


ARIMA (Autoregressive Integrated Moving average)
ARIMA(p, d, q)모형의 정상성 시계열 변환 방법
d=0이면, ARMA(p, q) 모형이며 정상성을 만족
p=0이면, IMA(d, q) 모형이며 d번 차분하면 MA(q)모형을 따른다.
q=0이면, IAR(p, d) 모형이며, d번 차분하면 AR(p)모형을 따른다.
MA 이동평균, AR자기회귀모형
AR(p): 자기회귀(AutoRegressive) → 과거 값이 현재에 영향을 줌
I(d): 차분(Integrated) → 비정상성을 제거하기 위해 몇 번 차분했는가
MA(q): 이동평균(Moving Average) → 과거 오차(예측 오류)가 현재에 영향을 줌

① K-Means
군집화(clustering) 알고리즘
데이터를 K개의 그룹으로 나눔
비지도학습
중심 기반 거리로 그룹 나눔
② Single Linkage Method
계층적 군집화(Hierarchical Clustering) 방법 중 하나
가장 가까운 두 클러스터 간의 거리로 합치는 방식
군집화 목적
③ DBSCAN
밀도 기반 군집화(Density-Based Spatial Clustering)
밀도가 높은 지역을 하나의 군집으로 묶음
비지도학습, 군집화 목적
✅ ④ 주성분분석 (PCA, Principal Component Analysis)
차원 축소(dimensionality reduction) 기법
고차원 데이터를 낮은 차원으로 투영해서 정보를 압축
목적은 군집화가 아니라 데이터 요약, 시각화, 전처리

① “표본 크기가 커질수록 신뢰구간이 줄어든다” → ✔️ 맞는 설명
표본이 커질수록 표준오차가 작아져 → 신뢰구간(± 범위)이 좁아짐
더 정밀한 추정 가능
② “99% 신뢰수준의 구간이 95%보다 길다” → ✔️ 맞는 설명
더 높은 신뢰를 얻기 위해선 더 넓은 구간을 잡아야 함
즉, 99% 신뢰구간은 95%보다 항상 넓음
③ “신뢰수준은 다수의 신뢰구간이 모수값을 포함하는 비율” → ✔️ 맞는 설명
95% 신뢰수준이란 건 이런 뜻:
“동일한 방식으로 무한히 많은 표본을 뽑아 신뢰구간을 만든다면, 그 중 **약 95%는 진짜 모수값을 포함할 것이다.”
즉, 확률은 신뢰구간이 맞출 확률, 모수 자체에 대한 확률은 아님
❌ ④ “추정값이 신뢰구간 안에 있을 확률이 95%다”
→ 틀린 설명!
모수(parameter)는 고정된 값이므로 “확률”의 대상이 아님
참고로 모수는 전체의 진짜 평균
신뢰구간은 매번 표본에 따라 바뀌는 것이고,
추정값이 구간 안에 있을 확률이 아니라
"이렇게 구한 신뢰구간 중 95%는 모수를 포함할 것"이라는 의미임

피어슨 상관계수는 두 변수 간의 직선 관계의 강도를 나타냄
값 범위: -1 ~ 1
+1: 완전한 양의 상관
0: 관계 없음
-1: 완전한 음의 상관
| 변수쌍 | 상관계수 |
|---|---|
| Balance & Limit | 0.93 ← 가장 강함 |
| Balance & Income | 0.46 |
| Balance & Age | 0.015 (거의 0, 관계 없음) |
| 나머지들 | 대부분 0.0~0.5 수준 |

✅ 혼합분포모형(Mixture Model)이란?
데이터가 여러 개의 확률분포(예: 여러 개의 가우시안)로부터 생성되었다고 가정
대표적인 예: GMM (Gaussian Mixture Model)
✅ 최대 가능도 추정(MLE)이란?
"현재 관측된 데이터가 나올 가능성이 가장 높은 파라미터를 찾는 방법"
예: 평균과 분산을 어떻게 설정해야 이 데이터가 나올 가능성이 제일 높을까?
✅ EM 알고리즘(Expectation-Maximization)이란?
GMM 같은 혼합 모델에서 MLE를 풀기 위해 사용하는 알고리즘
파라미터가 숨겨져 있을 때(예: 어떤 클러스터에 속하는지 모름), 반복적으로 기대값 계산(E-step) → 최대화(M-step)하는 방식
| 알고리즘 | 설명 | MLE/확률 기반? |
|---|---|---|
| K-means | 거리 기반, 비확률적 | ❌ |
| DBSCAN | 밀도 기반 군집화 | ❌ |
| K-medoids | K-means 변형 (중심 대신 대표점 사용) | ❌ |
| EM | 확률 모델 기반 / MLE 사용 | ✅ 정답 |
softmax란?
여러 출력값을 0~1 사이의 확률값으로 변환해 줌
모든 출력값의 총합이 1이 되게 만들어서 확률 분포로 바꿔줌
각 클래스가 정답일 확률을 의미함 → 즉, 사후 확률
① 항등 함수 (identity)
출력 = 입력
회귀 문제에서 사용 (예: y값 예측)
확률 아님, 스케일 조정도 안 됨
② ReLU (Rectified Linear Unit)
주로 은닉층에 사용
확률 출력과는 무관
③ sigmoid
이진 분류(binary classification)에서는 확률로 해석 가능
하지만 다중 클래스 문제에서는 부적합
(여러 출력값을 따로 0~1로 바꾸면 총합이 1이 안 됨)
