Adsp 준비 (8)

이 전체를 익명화라 한다.
데이터마스킹 : 홍길동→홍XX
가명처리 : 홍길동→임꺽정
총계처리 : 10점,20점,30점 -> 평균 20점
데이터 값 삭제 : 서울시 강남구 -> 서울시
데이터 범주화 : 29세 -> 20세~30세

복습용
정밀도(Precision) : 예측값이 True인 것에 대해 실제값이 True인 지표
예상을 얼마나 정밀하게 했나
재현율, 민감도(Sensitivity) : 실제값이 True인 것에 대해 예측값이 True인 지표
역순으로 추적하면 재현이 얼마나 정확한가

LOOCV는 k=n의 경우
전체 데이터를 'k'개의 동일한 크기의 부분집합(subsets)으로 나누고, 이 중 하나의 부분집합을 검증 데이터로, 나머지 'k-1'개의 부분집합을 학습 데이터로 사용하는 과정을 k번 반복하는 방식이다.
일반적으로 k의 값은 5나 10을 사용하는 것이 일반적이며, 데이터셋의 크기가 작을 때 유용

텍스트마이닝: 비구조화된 텍스트에서 구조화된 데이터로 변환하는 방법
corpus 코퍼스: 텍스트 데이터를 분석하기 위해 모아놓은 텍스트 덩어리

① 모형 검정에는 F검정이 사용된다. ❌
F검정(F-test)는 선형 회귀(Linear Regression)에서 사용됩니다.
로지스틱 회귀에서는 이탈도(Deviance) 검정이나 우도비 검정(Likelihood Ratio Test, LRT)이 사용됩니다.
③ Softmax 함수를 사용하여 종속 변수를 전체 실수 범위로 확장하여 분석한다. ❌
Softmax 함수는 다중 분류(Multi-class Classification)에서 사용되지만, 종속변수를 실수 범위로 확장하는 것이 아니라, 확률 값으로 변환하는 역할을 합니다.
④ 모형 탐색 방법에는 최소 자승법(최소 제곱법)이 있다. ❌
최소 자승법(OLS, Ordinary Least Squares)은 선형 회귀에서 사용되며,
로지스틱 회귀에서는 최대 우도 추정법(MLE, Maximum Likelihood Estimation)이 사용됩니다.

애초에 합집합 - 교집합으로 합집합 확률을 구하는데 니는 왜 3번을 골랐노... 진짜 미치겠다
근원사건은 첨 듣긴했어 물론 외워두자

ANOVA : 분산을 분석해서 평균 차이를 본다
ANOVA는 범주형이기 때문에 애초에 연속형이 아니라 선형적이지 않다.
그렇기에 양의 상관관계인지 음의 상관관계인지 알려면 여기에 더해 회귀분석을 해야한다.
회귀분석은 X(독립변수)가 Y(종속변수)에 얼마나 많은 영향을 주는지 알기 위해 하는 분석
Mean sq은 MSE로 이는 평균제곱오차이다.
2998인 이유는 자유도는 기본적으로 N-1이기 때문

Cook's Distance(쿡의 거리)는 회귀분석에서 이상치(outlier)나 영향력이 큰 관측값을 찾기 위한 지표입니다.
"이 데이터 한 개를 빼고 회귀모형을 다시 돌렸을 때,
→ 회귀선이 얼마나 달라지는가?
→ 많이 바뀌면 영향력 큼 → Cook's Distance 값이 큽니다"
0에 가까울수록 영향 거의 없고 1이면 왜곡주의

은닉층이 많으면 과소적합, 적으면 과대적합
은닉층은 필터같은 역할을 중간에서 해주는데
이러한 필터가 너무 많으면 새로운 데이터가 들어왔을 때 학습 데이터랑 너무 다를 경우 분류를 잘 못해줌 학습은 1,2,3,4로 딱딱 나뉘는걸로 시켰는데 갑자기 1인지 2인지 애매모호한 데이터가 새로 들어오면 제대로 반영안하는것
반대로 이러한 필터가 너무 없어서 데이터가 분류가 제대로 안되는게 과소적합 커피를 내리는데 필터 없이 내린다고 생각해보셈 불순물이 얼마나 많겠음

걍 그려서 풀어보셈
총 경우의 수는 8
그중에 앞면이 한번만 나오려면
앞면이 두번 이상 나오는 경우와 한번도 안나오는 경우를 제외
그러면 결국 각 자리에 한번씩 나오는 경우가 분모가 되는 거임
T T T
T T F
T F T
F T T
T F F
F T F
F F T
F F F
여기서 T가 한번만 들어간 것만 카운트하라는 말
그건 3개고 결과는 3/8

다차원척도법에서 적합도 수준을 나타내는 척도인 스트레스 (STRESS)는 0과 1 사이의 값을 취하며, 0으로 작아질수록 적합된 모형이 적절하다고 판단
데이터들의 유사성 또는 비유사성과 같은 데이터들의 정보 속성을 파악하여 공간상에 표현하기 위해 사용
한마디로 축소가 아니라 공간상에 나타내려고 쓴다.

이산 → 불연속 → 시그마
연속 → 적분(인테그랄)
답 1

공표연내
공통화: 암묵지 지식을 다른 사람에게 알려줌
표출화: 암묵지 지식을 메뉴얼이나 문서로 전환
연결화: 교재, 메뉴얼에 새로운 지식 추가
내면화: 만들어진 교재, 메뉴얼에서 다른 사람의 암묵지를 터득

조온나 말장난 문제 이건 출제자한테 계약서들고 사기쳐도 할 말 없음
2번 보기의 경우 N이 커지면 표본이 커지면서 점점 A의 확률과 가까워짐 이거시 빈도주의 확률 또는 통계적 확률
절대도수: 사건이 일어난 횟수 자체 (ex. 6번)
상대도수: 사건이 일어난 비율 (ex. 0.6)

유의수준: 귀무가설을 기각하게 되는 확률의 크기
유의확률(p-value): 귀무가설이 사실인데 기각하게 되는 확률, p-value값이 작을수록 기각할 가능성이 높아진다
1종 2종 비유
1종 오류: 이새키 괜히 가오잡으려고 1종 따네 ㅋㅋ 그러다 나중에 친구들끼리 여행갈 때 인원이 너무 많아서 걔가 운전하는 1종 봉고차 탐
아 ㅋㅋ 괜히 깠네
2종 오류: 그래 요새는 2종도 괜찮아
이랬다가 운전미숙으로 사고남
깠어야되는데 너무 오냐오냐했네

검정통계량: 표본 결과가 이상한 정도
기각역: 검정통계량이 이 기각역의 범위 안에 들어가면 귀무가설 기각
왜케 극단적이야 이건 안믿는다.
상향식 접근방법은 비지도 학습과 프로토타이핑 방법으로 구분
하향식 접근방법은 지도 학습, 모형기반 분석

표본 상관 계수 값의 제곱 값과 같음
그래서 R^2임
중요
상관계수에 제곱한게 결정계수

차원을 축소하는 과정에서 일부 거리 왜곡은 발생할 수밖에 없다.


데이터에 매몰되지 말자 비즈니스에 집중


값을 작게 만드니까 로그 변환해서 오른쪽 꼬리 긴 분포에 사용
값을 크게 만드니까 제곱, exp로 왼쪽 꼬리 긴 분포에 사용
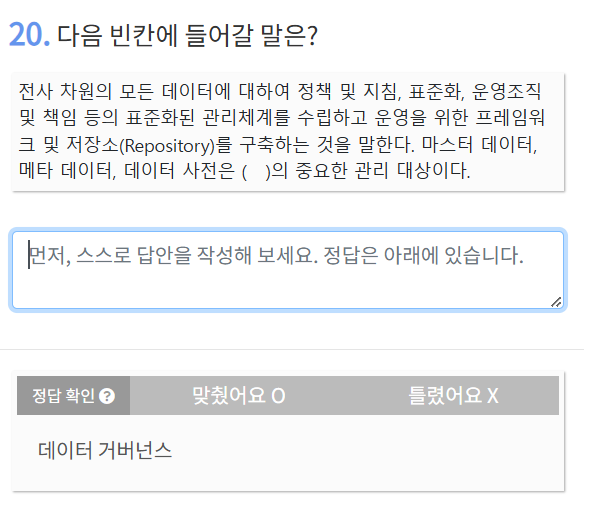
데이터 전체적으로 관리하려고 하면 데이터 거버넌스

β > 1 : Recall에 더 중요도를 둠
β < 1 : Precision에 더 중요도를 둠
β = 1 : F1 Score (정밀도와 재현율이 동일하게 반영됨)
쌍곡탄젠트: 비선형이며, -1에서 1사이의 값으로 실수를 압축하는 함수
시그모이드는 항상 0이상 값이 나오는데 반해
쌍곡탄젠트는 -1에서 1사이가 나와 학습에 더 유리한 경우가 많음
요인분석: 여러 변수 안에 숨어 있는 공통된 요인을 찾아내는 기법
앙상블 기법: 여러 모델을 합쳐서 더 나은 하나의 모델을 만드는 기법
ex) 배깅, 부스팅, 스태킹
Boosting:
M1 → M2 → M3 → 최종 결과
AdaBoost:
1) 틀린 데이터에 가중치↑
2) 다음 모델이 그것을 더 잘 맞추게 학습
XGBoost:
1) 이전 모델의 오차(잔차)를 수학적으로 미분
2) 그걸 줄이도록 다음 트리를 학습 (그래디언트 방식)
앙상블 기법 (Ensemble Methods)
├── Bagging (병렬 결합)
│ └── Random Forest
├── Boosting (순차 결합)
│ ├── AdaBoost
│ ├── Gradient Boosting
│ └── XGBoost (Gradient Boosting의 확장)

K값이 커질수록 더 많은 이웃을 참고하여 예측하므로 모델이 단순해지고 과소적합 문제가 발생할 수 있음



엘보우방법은 군집 내 분산의 감소율이 급격히 줄어드는 지점을 최적 군집수로 결정합니다.


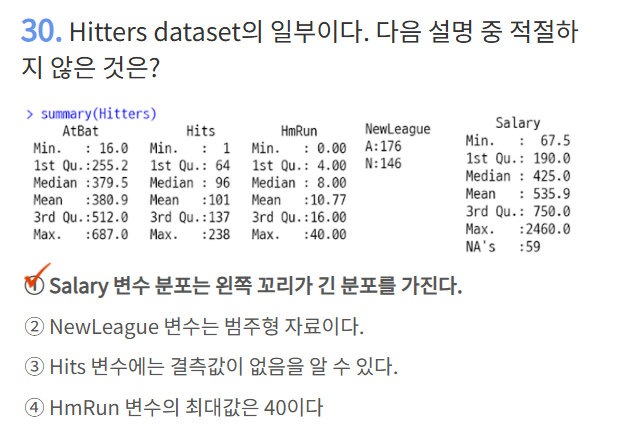
Mean값이 Median보다 크면 오른쪽 긴 꼬리
만약에 NA같은 값이 들어가 있으면 그건 결측값이 있는거임
NewLeague는 이진범주형 자료

학습이 아닌 테스트 데이터에 대한 예측 성능을 향상시킴
카이제곱 검정 -> 이론적 분포가 실제 관측치와 일치하는지 그 차이를 보는것
기대값과 관측값 차이가 크면 카이제곱 통계량이 증가하고 그럼 유의확률이 낮아져 귀무가설 기각 가능성이 올라감
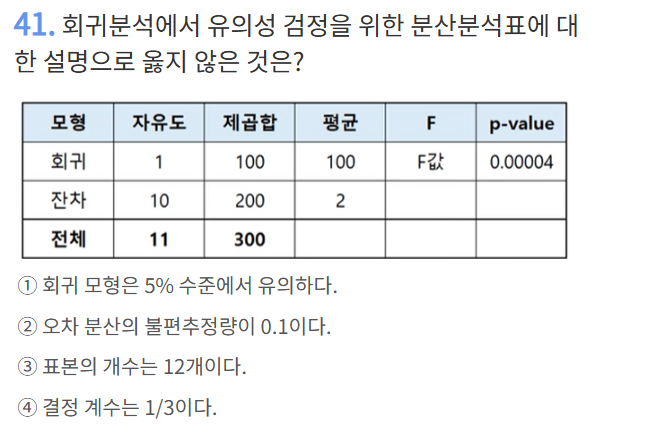

분석 기회 구조화(3가지)
유저스토리 정의, 목표가치 구체화, 분석질문 구체화(유목분)
역전파때 나가리되면 기울기 소실
레이어가 모든 입력에 같은 출력을 하면 신경망 레이어 소실

통합해서 저장하고 공유했다가 변화하면 다시 반복

난이도가 가지고 있는 특성을 다 제외해야할듯

항상 데이터와 분석이 목적이 되면 안됨
비즈니스가 먼저고 데이터와 분석은 수단이뿐임
이런 유형은 다 데이터에 치우친 광기가 보이면 오답임
지지도: 동시에 산거 / 전체 구매
신뢰도: a 산거 전체 혹은 b 산거 전체 / 전체 구매
향상도: 지지도 / 신뢰도 a * 신뢰도 b

훈련(학습)데이터 : 진짜 학습할때만
검증 데이터: 웬만한거 여기서 다함 과적합 방지 파인튜닝 등등
평가 데이터: 전체 데이터의 10~20퍼 사용 예측력 봄
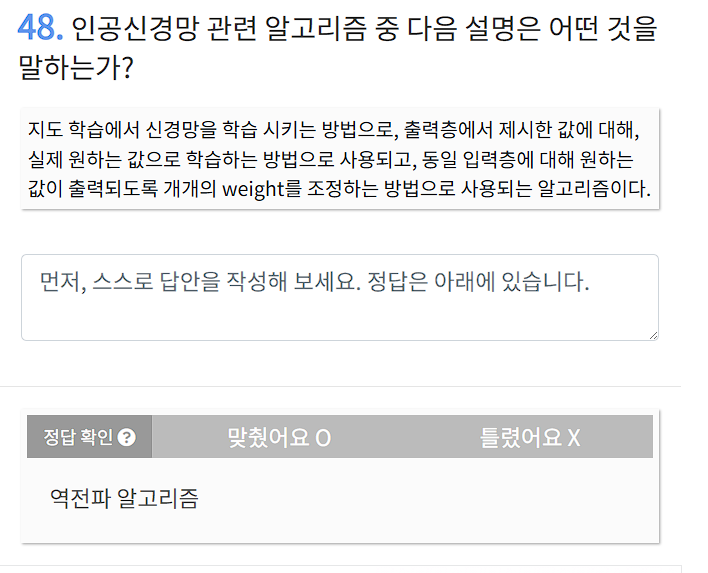

표본오차는 표본 추출 방법에 따라 여러 값으로 나타나지만,
보통은 표본의 크기에 반비례한다. 즉, 표본의 크기가 증가하면 표본오차가 작아지는 것이다.
그렇기 때문에 충분한 크기의 표본을 대상으로 연구를 진행해야 한다.
표본오차가 표본 선택이 잘못됨으로써 발생하는 오차라고 한다면,
비표본오차는 자료를 집계하고 정리하는 단계에서 발생하게 되는 오차다.

| 구분 | 모수 검정 | 비모수 검정 |
|---|---|---|
| 📊 분포 가정 | 정규분포 등 가정 필요 | ❌ 분포 가정 없음 |
| 📦 데이터 조건 | 연속형, 정규분포 필요 | 순서형, 범주형 등도 OK |
| 📈 예 | t-test, ANOVA 등 | 윌콕슨 검정, 카이제곱, 맨휘트니 등 |
| 🧪 활용 | 표본 수 많고 정규성 만족할 때 | 표본 적거나 정규성 불확실할 때 |
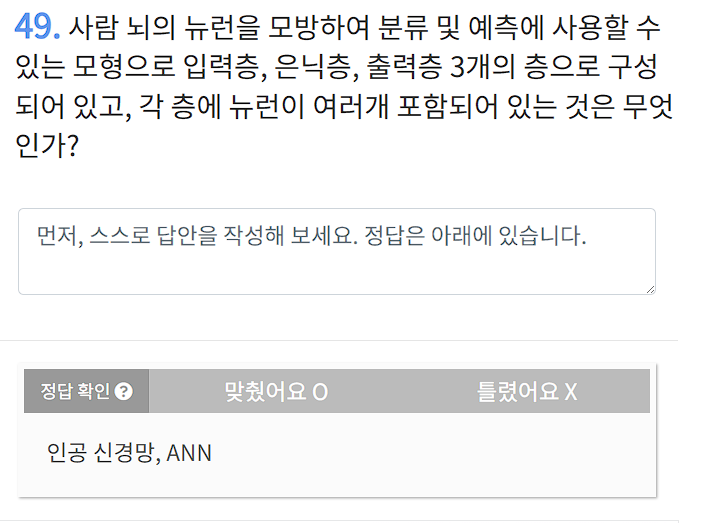
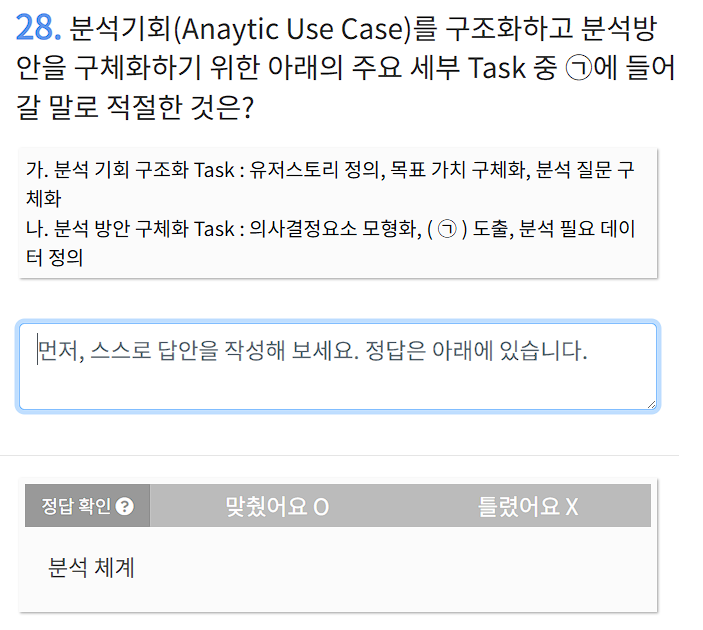
기획 구조화 task: 스토리, 구체화
방안 구체화 task: 분석 체계, 모형화,

인분 분분분 IT
