sqld 준비 (2)
한 개의 엔터티는 2개 이상의 인스턴스 집합
한 개의 엔터티는 2개 이상의 속성을 가짐
한 개의 속성은 1개의 속성값을 가짐
그럼 한 개의 인스턴스는? 엔터티의 모든 속성을 가지는 거임
속성의 분류: 기본, 설계, 파생 속성
기본: 업무로부터 추출한 모든 일반적인 속성
설계: 업무를 규칙화하기 위해 새로 만들거나 변형, 정의하는 속성 ex) 일련번호
파생: 다른 속성에 영향을 받아 발생하는 속성, 빠른 성능을 낼 수 있도록 원래 속성의 값을 계산 ex) 합
도메인: 각 속성이 가질 수 있는 값의 범위 ex) 5글자
속성의 명명
1. 해당업무에서 사용하는 이름 부여
2. 서술식 속성명은 사용 금지
3. 약어 사용 금지
4. 전체 데이터모델에서 유일성 확보
관계: 엔터티의 인스턴스 사이의 논리적인 연관성으로서 존재의 행태로서나 행위로서 서로에게 연관성이 부여된 상태
존재의 의한 관계 ex)소속된다
행위에 의한 관계 ex)주문한다
페어링: 엔터티 안에 인스턴스가 개별적으로 관계를 가지는 것
UML에는 연관관계와 의존관계가 있는데, 연관(존재적)관계는 항상 이용하는 관계이고 의존관계는 상대방 행위에 의해 발생하는 관계이다.
ERD에서는 존재적 관계와 행위에 의한 관계를 구분하지 않고 표기했지만 UML에서는 이를 구분하여 연관관계는 실선, 의존관계는 점선으로 표현
관계의 표기법
관계명: 관계의 이름
관계차수: 1:1, 1:M, M:N
관계선택성(관계선택사양): 필수관계, 선택관계
관계 체크사항
1. 2개의 엔터티 사이에 관심있는 연관 규칙o?
2. 2개의 엔터티 사이에 정보의 조합 발생o?
3. 업무기술서, 장표에 관계연결에 대한 규칙 서술o?
4. 업무기술서, 장표에 관계연결을 가능케 하는 동사o?
식별자: 엔터티내에서 인스턴스를 구분하는 구분자
식별자는 논리 데이터 모델링 단계에 사용
key는 물리 데이터 모델링 단계에 사용
식별자의 특징: 유일성, 최소성, 불변성, 존재성
1. 주식별자에 의해 모든 인스턴스들이 유일하게 구분
2. 주식별자를 구성하는 속성의 수는 유일성을 만족하는 최소의 수가 되어야 함
3. 지정된 주식별자의 값은 자주 변하지 않아야 함
4. 주식별자가 지정이 되면 반드시 값이 들어와야 함
실별자 분류
대표성 여부: 주식별자, 보조식별자
주식별자: 엔터티 내에서 각 어커런스를 구분할 수 있는 구분자, 타 엔터티와 참조관계를 연결할 수 있음.
보조식별자: 어커런스를 구분할 수 있는 구분자이나 대표성을 가지지 못해 참조관계 연결 불가
스스로 생성여부: 내부 식별자, 외부 식별자
내부식별자: 스스로 생성되는 식별자
외부식별자: 타 엔터티로부터 받아오는 식별자
속성의 수: 단일 식별자, 복합 식별자
단일 식별자: 하나의 속성으로 구성
복합식별자: 2개 이상의 속성으로 구성
대체 여부: 본질식별자, 인조식별자
본질 식별자: 업무에 의해 만들어지는 식별자
인조 식별자: 인위적으로 만든 식별자
주식별자 도출기준
1. 해당 업무에서 자주 이용되는 속성임
2. 명칭, 내역 등과 같이 이름으로 기술되는 것들은 x
3. 복합으로 주식별자로 구성할 경우 너무 많은 속성x
식별자 관계식별자 관계



1(A)
- ├── 3(C)
└── 2(B)- └── 4(D)
답 C

맨 밑에 줄 부터 해보면
일단 C1이 2인 곳에서 노드를 시작하자
C2중심으로 봤을 때 C1과 같은게 있으면 연결
즉, 이말은 처음 C1이 2인 곳에서 C2와 같은 C1이 있으면 이를 연결하자는 말이다.
그래서 JOHN과 KING이 여기에 해당되는데
여기서 WHERE절이 들어와 버린다. C1이 2가 아닌 것만 출력을 하라고 하니 C1이 2인 JOHN을 뺀 KING만 출력이 되는 것이다.
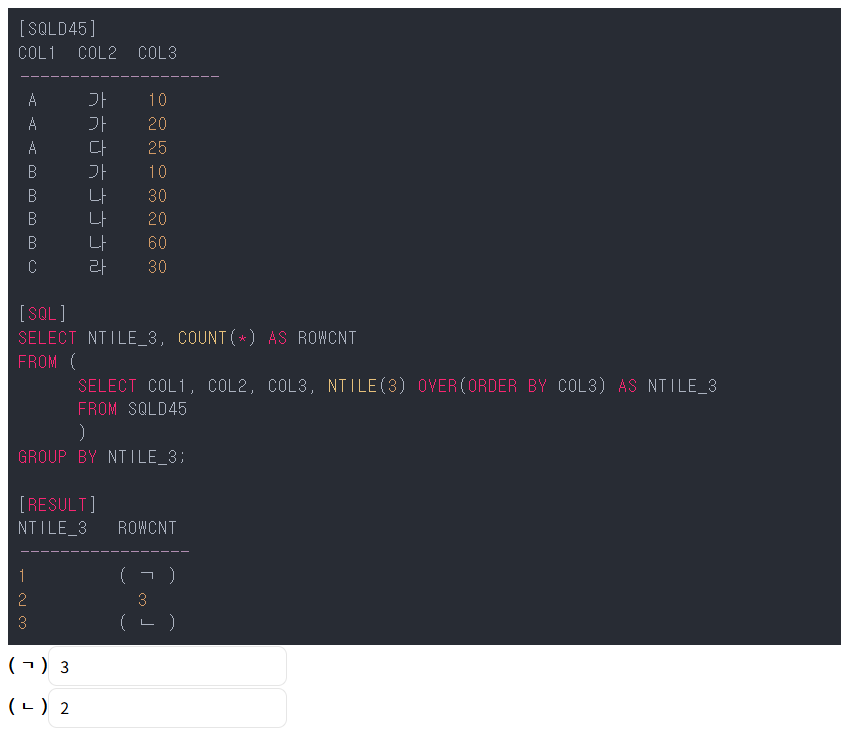
NTITLE(n)은 테이블을 n개로 쪼개서 본다는 말이다.
OVER는 여기서 n개로 쪼갤 때 어떻게 쪼갤지 조건을 주는 부분이다.
그렇게 되면 row가 총 8개가 있으니까
3개로 쪼개면 3 3 2 가 된다.
이걸 GROUP BY로 묶어서 COUNT를 하면
결과값은 ROWCNT 3 3 2가 되는 것이고
ㄱ과ㄴ에 들어갈 값은 3 2가 된다.

BETWEEN 0 PRECEDING AND 50 FOLLOWING은
0 PRECEDING 자기 자신 포함
50 FOLLOWING 50큰 값
이 뜻이다.
따라서 일단 N1을 오름차순으로 정렬해놓고
그다음에 차례차례 자기자신과 50을 더한 값이 테이블에 있는지를 비교하며 내려가야한다.
E의 경우 50과 50+50=100 [50,100]이 모두 테이블에 있으므로 cnt=2가 되는것이고 D의 경우 자기자신이 450은 있지만 500은 테이블에 존재하지 않기 때문에 450만 카운트되어 cnt=1이 되는것이다.
이렇게 범위로 주어졌을 때는 RANGE를 써야한다.
ROW의 경우 행의 갯수로 범위를 정하기 때문에 여기서 쓰는건 아님
