sqld 준비 (9)
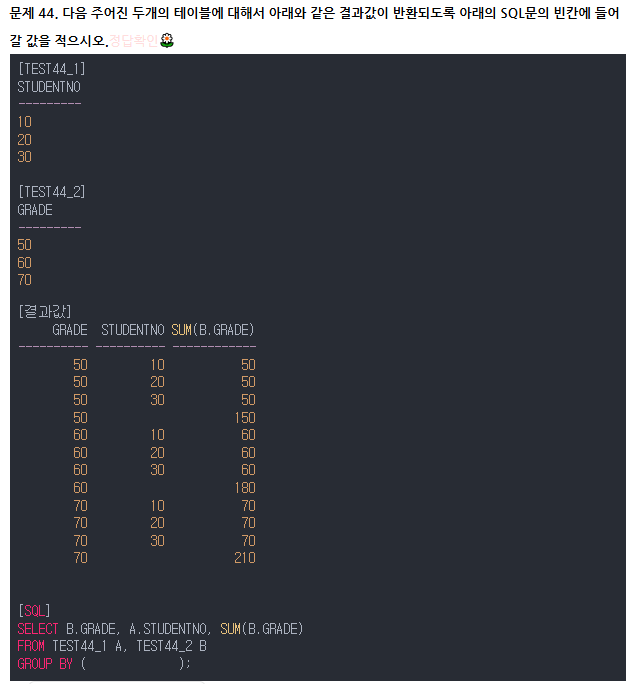
전체 합계가 없는거 보면 GROUPING SETS인걸 짐작할 수 있다.
여기서 문제는 GROUPING SETS안에 뭐가 들어가야 하는지다.
괄호안에는 출력값이 SUM이런건 들어갈 수가 없고 단순히 어느 조합을 넣을 건지만 정해주면 된다.
우선 GRADE와 STUDENTNO의 조합이 있는걸 알 수 있다. (둘이 동시에 나오기에)
그리고 해당 조합이 다 나오고 나면 GRADE와 SUM값만 나온다. 근데 위에서 SUM같은 출력값은 괄호안에 넣지 않는다고 했다.
그러면 GROUPING SETS(B.GRADE,(A.STUDENTNO,B.GRADE)) 이런식으로 적어야하는 것을 알 수 있다. 여기서 A.STUDENTNO와 B.GRADE의 순서나 (A.STUDENTNO,B.GRADE)와 B.GRADE의 순서는 중요치 않다.
단순히 어떤 조합인지 파악하면 될 뿐
전체합계 유무 ->
있다 -> GROUPING SETS 물론 GROUPING SETS((A,B),A,())이런식으로 하면 되긴 하지만 문제풀이를 위해 간단하게 생각하자
없다 -> ROLLUP, CUBE -> (A,B)를 넣었다고 할 때 B의 각 합계까지 나오면 CUBE 아니면 ROLLUP
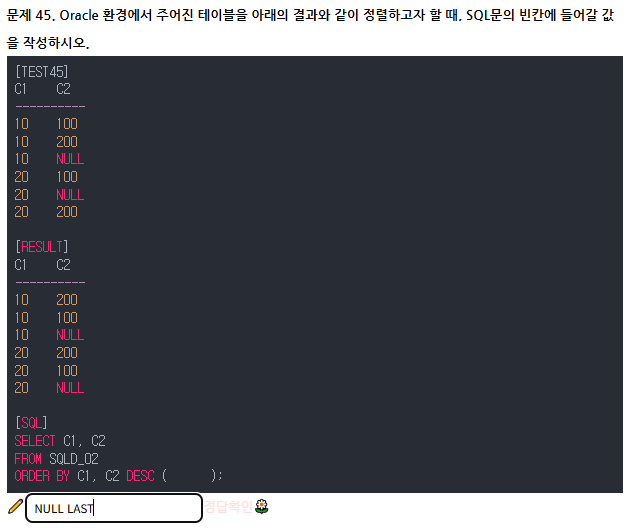
NULLS FIRST : 정렬하고자 하는 NULL 데이터들을 데이터 앞에 나오게 한다.
NULLS LAST : 정렬하고자 하는 NULL 데이터들을 데이터 뒤에 나오게 한다.
ASC(디폴트로 NULL값이 마지막에 옴)
DESC(디폴트로 NULL값이 맨 앞에 옴)
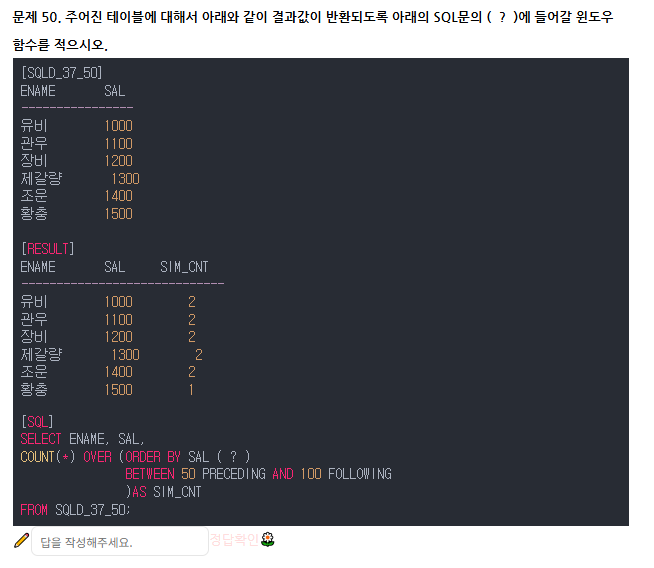
답 RANGE
그리고 유비가 2인 이유는 자기자신을 포함하기 때문
황충의 경우 -50 ~ + 100일때 자기자신밖에 해당하는 부분이 없기 때문에 1인것임.

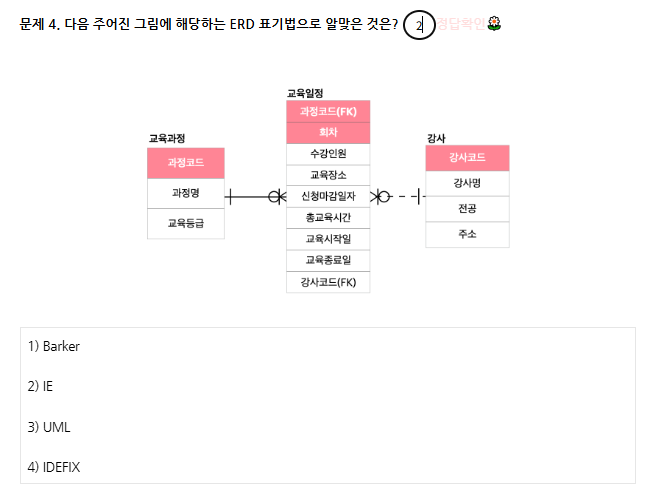
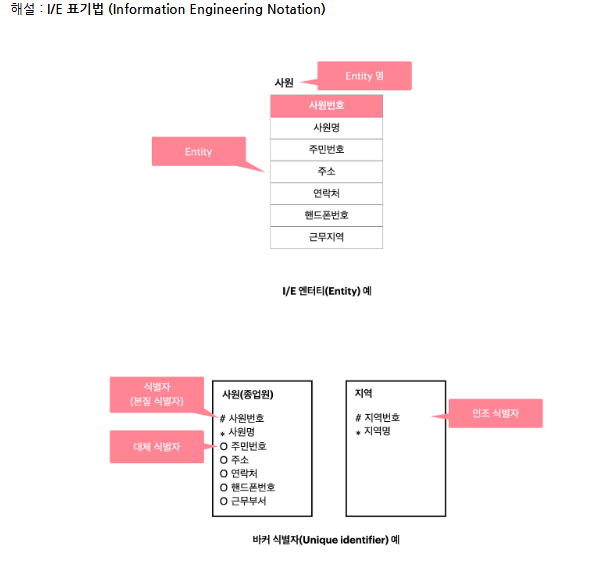
해설 : 3차 정규화 → 한 엔티티 안의 모든 주식별자가 아닌 속성들은 주식별자에 의존해야 한다. 속성에 종속적인(이전종속) 속성이 있다면 분리해야 한다.
중복을 제거하는건 오케이 but, 종속을 제거하는건 다치종속성이 유일

해설 : 슈퍼/서브타입 데이터의 특징은 공통점과 차이점을 고려하여 효과적으로 표현할 수 있다는 것이다.
즉, 공통의 부분을 슈퍼타입으로 모델링하고 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성에 대해서는 별도의 서브엔터티로 구분하여 업무의 모습을 정확하게 표현하면서 물리적인 데이터 모델로 변환을 할 때 선택의 폭을 넓힐 수 있는 장점이 있다.
슈퍼/서브 타입 관계의 변환
데이터량이 소량일 경우 성능에 영향을 미치지 않기 때문에 데이터처리의 유연성을 고려하여 1:1 관계를 유지한다.
그러나 데이터용량이 많아지는 경우 그리고 해당 업무적인 특징이 성능에 민감한 경우는 트랜잭션이 해당 테이블에 어떻게 발생되는지에 따라 3가지 변환방법을 참조하여 상황에 맞게 변환하도록 해야 한다.
모든 직원이 공통으로 가지는 정보가 있어요:
이름, 생년월일, 연락처
하지만 일부 직원은 정규직이고, 일부는 계약직이죠?
정규직만 연차일수, 연봉 있음
계약직만 계약기간, 시급 있음
✅ 이럴 때:
공통 정보는 슈퍼타입(Employee)
다른 속성은 서브타입(정규직, 계약직)
공통된 속성은 슈퍼타입으로 두고 세부적인 차이들은 서브타입으로 빼서 효율성을 높이는것이 핵심

서브쿼리란 하나의 SQL문 안에 포함되어 있는 도 다른 SQL문을 말한다.
서브쿼리는 메인쿼리의 컬럼을 모두 사용할 수 있지만, 메인쿼리는 서브쿼리의 컬럼을 사용할 수 없다.
질의 결과에 서브쿼리 컬럼을 표시해야 한다면 조인 방식으로 변환하거나 함수, 스칼라 서브쿼리 등을 사용해야 한다.
서브쿼리 사용시 주의사항
1. 서브쿼리를 괄호로 감싸서 사용한다.
2. 서브쿼리는 단일행(Single row) 또는 복수행 (Multiple row)비교 연산자와 함께 사용 가능하다. 단일행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하여야 하고 복수행 비교 연산자는 서브커리의 결과 건수와 상관없다.

낚시를 당했다 시험장에서 잘 보자
3번에 괄호가 이중인지 몰랐음...
2번과 ROLLUP(DNAME, YEAR) 이 두개는 같은 것
2번도 될 수 있다는걸 알고 기억해두자
FLOOR - 정수 이하로 내림
CEIL - 정수 이상으로 올림
ROUND(a,b) - b번째 자리에서 반올림
TRUNC - 소주점 이하 버림
가) 선행 테이블에서 주어진 조건을 만족하는 레코드를 필터링한다.
나) 선행 테이블의 조인 키를 기준으로 해시 함수를 적용하여 해시 테이블을 생성한다.
다) 1번, 2번 작업을 선행 테이블에서 조건을 만족하는 모든 행을 수행한다.
라) 후행 테이블에서 주어진 조건을 만족하는 레코드를 필터링한다.
마) 후행 테이블의 조인 키를 기준으로 해시 함수를 적용하여 선행 테이블에서 해시 함수 반환값과 같은 값을 반환하는 해당 버킷을 찾는다.
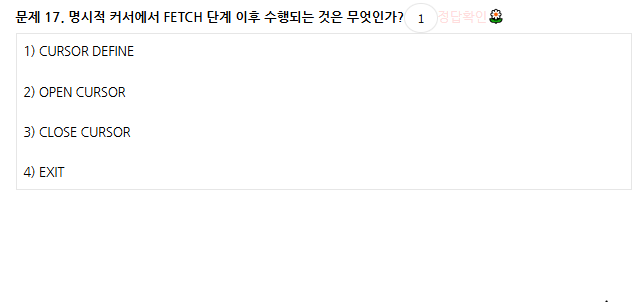
DECLARE -> OPEN -> FETCH -> CLOSE
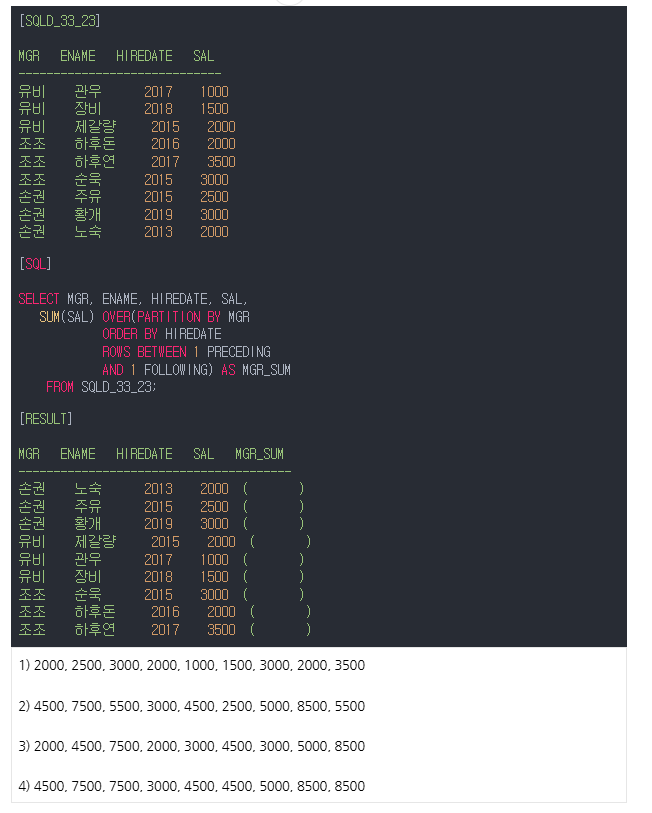
재정렬한다음에 값 더하는게 맞고 제일 중요한건 파티셔닝을 했기 때문에 예를 들어 손권 황개의 following과 유비 제갈량의 preceding은 없는거임
정답 2

B-tree 인덱스는 크게 브랜치(Branch) 블록과 리프(Leaf) 블록으로 구성됩니다.
브랜치 블록은 탐색 경로(분기용) 역할 → "어디로 가야 할지"만 알려줌
리프 블록은 실제 인덱스 항목 + 데이터 주소(ROWID)를 포함하고 있음
리프 블록은 인덱싱된 칼럼 값 기준으로 정렬됨
B-tree 인덱스는 각 인덱스 키마다 하나의 ROWID만 저장함 (또는 한 행에 대해 하나)
답 2

Hash Join은 반드시 동등 조인에서 사용
Hash Join은 작은 테이블을 먼저 메모리에 해시 테이블로 만들고 큰 테이블을 순차적으로 읽으며 매칭
풀스캔하기때문에 인덱스 불필요
랜덤 엑세스 부하 완화
ROLL
-
사용자에게 허가할 수 있는 권한들의 집합
-
롤을 이용하면 권한 부여와 회수를 쉽게 할 수 있다.
-
롤은 CREATE ROLE 권한을 가진 USER 에 의해서 생성된다.
-
한 사용자가 여러개의 ROLE을 ACCESS 할 수 있고, 여러 사용자에게 같은 ROLE 을 부여할 수 있다.
-
시스템 권한을 부여 & 취소할 때와 동일한 명령을 사용하여 사용자에게 부여하고 취소한다.
-
사용자는 ROLE에 ROLE을 부여할 수 있다.
-
Oracle DB를 설치하면 기본적으로 CONNECT, RESOURCE, DBA ROLE이 제공된다.
ROLE은 명령어가 아니라 객체(역할)입니다.
여러 권한을 모아서 만든 "권한 묶음"이에요.
즉, 관리 단위이지 명령어가 아님
ROLE은 DBA가 아니어도 CREATE ROLE 권한을 가진 사용자라면 생성 가능
권한이든 ROLE이든 모두 GRANT로 부여하고 REVOKE로 회수함
ROLE은 여러 사용자에게 같은 ROLE을 부여하는 것이 장점입니다.
예: "사원" 역할을 만든 뒤 여러 사원에게 똑같이 부여

-
절차적 데이터 조작어(procedural DML) : 사용자가 어떤 데이터를 원하고 해당 데이터를 얻으려면 어떻게 처리해야 하는지 명세함
PL/SQL이 여기에 속함 -
비절차적 데이터 조작어(nonprocedural DML) : 사용자가 어떤 데이터를 원하는지만 명세함- 호스트 프로그램 속에 삽입되어 사용되는 DML명령어들을 데이터 부속어(Data Sub Language)라고 한다.
우리가 흔히 아는 SELECT같은 애들이 여기에 속함
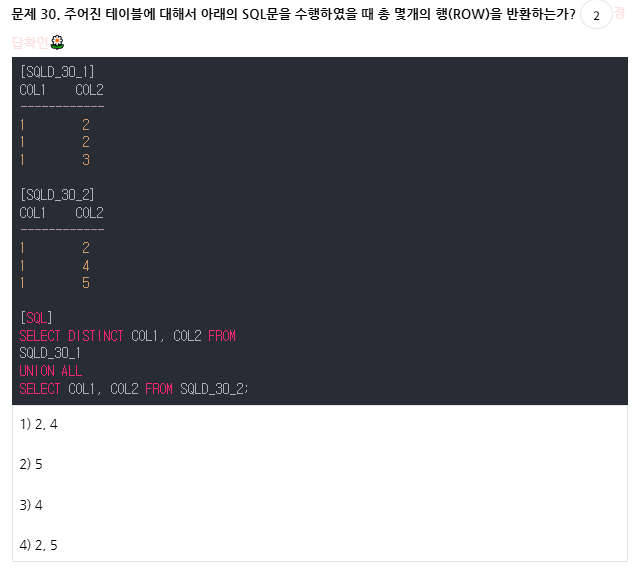
두개 컬럼이 모두 같을 때만 DISTINCT에 의해 중복제거됨 출제자 새끼 거의 심리학과...
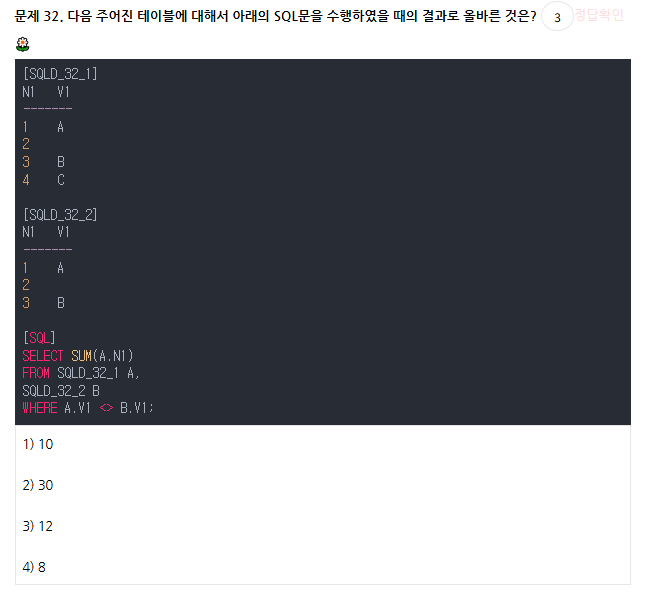
FROM에 테이블 그냥 나열하면 카티시안 곱 발생
일단 12개가 생겨버리고 여기서 소거해나가면서 N1값을 누적해나가야함
같거나 NULL인 부분과 비교할 경우를 빼고 다른 경우만 더해보자
3+4+1+4 = 12
답은 12

LPAD(값, 전체자리수, 채울문자)
LPAD('2', 2, '0') → '02'
LPAD('10', 2, '0') → '10'
