0. Cache
0.0. Cache architecture
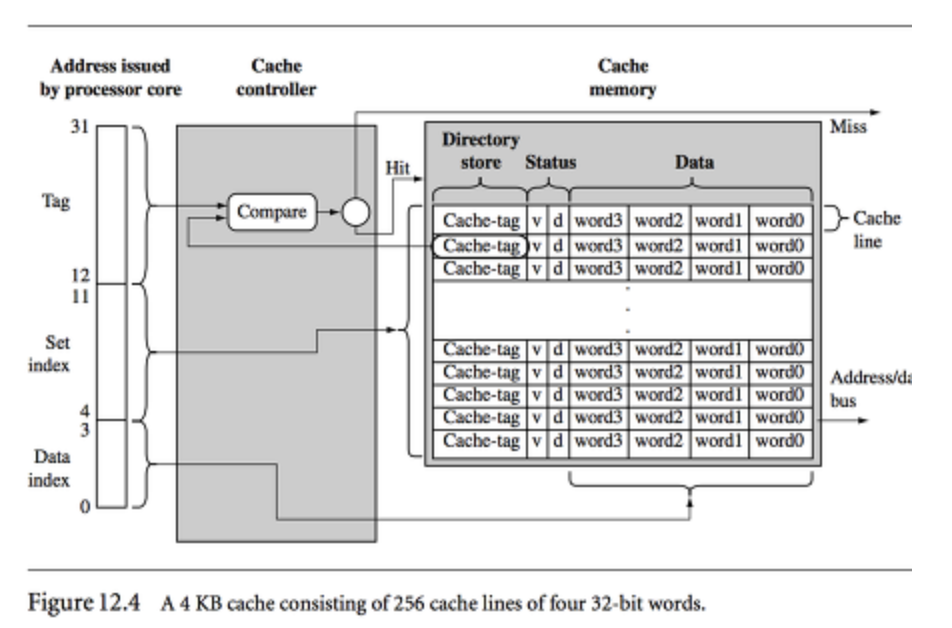
캐시는 캐시 컨트롤러와 캐시 메모리로 구성된다.
캐시 컨트롤러는 hw로 구현된 캐시알고리즘을 따른다.
캐시 알고리즘은 크게 캐시 히트율 최대화, 메모리 평균접근시간 감소, 캐시 메모리 용량 활용 최적화등을 목적으로 데이터의 지역성을 활용한다.
0.1. Cache Metrics
- cache hit
CPU에서 요청한 데이터가 캐시에 존재하는 경우 - hit latency
hit가 발생해 캐싱된 데이터를 가져올 때 소요되는 시간을 의미 - cache miss
요청한 데이터가 캐시에 존재하지 않는 경우 - miss latency
miss가 발생해 상위 캐시에서 데이터를 가져오거나(L1 캐시에 데이터가 없어서 L2 캐시에서 데이터를 찾는 경우) 메모리에서 데이터를 가져올 때 소요되는 시간
- 평균접근시간(Average access time)
Average_access_time = Hit_rate*Hit_latency +Miss_rate×Miss_latency- Hit_rate, Miss_rate
Cache_acesses = Cache_hits+Cache_misses
Hit_rate = Cache_hits/Cache_acesses
Miss_rate = Cache_misses/Cache_acesses0.2. 캐시 일관성 문제(cache coherence)
** 캐시 일관성
여러 개의 캐시 메모리가 공유 데이터를 일관되게 유지하는 성질.
cpu1의 캐시에서 메인 메모리에 있는 데이터인 data1을 갱신하기 위해 cpu1_cache를 갱신후 메인 메모리에 기록하는 것이 지연된 상태로 cpu2로 제어권이 넘어간다면, cpu2가 data1을 캐시에 복사할 때 참조하는 값은 갱신되기전 값이므로 문제가 된다. 이를 캐시 일관성 문제라고 한다.
캐시 일관성 문제를 해결하기 위한 기본적인 기법은 버스 스누핑(bus snooping)기법이다.
버스 스누핑 기법으로 캐시는 자신과 메모리를 연결하는 버스의 통신 상황을 계속 모니터링한다. 캐시 데이터에 대한 변경이 발생하면, 자신의 복사본을 삭제하거나 갱신한다.
0.3. 캐시 친화성(cache ainity)
** 캐시 친화성
한 프로세서나 코어가 특정 캐시 라인을 선호하거나 사용하는 성질. 이를 통해 데이터의 지역성이 높아지므로 캐시 히트율이 올라간다.
CPU에서 실행될 때 프로세스는 해당 CPU 캐시와 TLB(캐시)에 상당한 양의 상태 정보를 올려 놓게 된다. 그래서 다음 번에 프로세스가 실행될 때 동일한 CPU에서 실행되는 것이 유리하다.
즉 멀티프로세서 스케줄러는 스케줄링 결정을 내릴 때 가능한 한 프로세스를 동일한 CPU에서 실행하려고 노력하는 방향으로 결정해야하고,
이를 캐시 친화성을 고려한다고 한다.
** TLB(translation look-aside buffer, 변환색인버퍼)
변환 색인 버퍼는 가상 메모리 주소를 물리적인 주소로 변환하는 속도를 높이기 위해 사용되는, 주소변환캐시이다.
멀티프로세서 시스템의 스케줄러의 기본적인 개발 방법 2가지를 소개한다.
1. 단일 큐 스케줄링
2. 멀티 큐 스케줄링
이외에도 병렬 작업 스케줄링, 작업 그룹 스케줄링, 동적 스케줄링 등이 있다.
1.0. 단일 큐 멀티프로세서 스케줄링(single queue multiprocessor scheduling, SQMS)
단일 프로세서 스케줄링의 기본 프레임워크를 그대로 사용한다.
기존 정책을 다수 CPU에서 동작하도록 변경하려면, 예를 들어 현재 사용 가능한 CPU의 수에 따라 한 번에 해당 수만큼 작업을 선택하면 된다.
여러 개의 프로세서가 동일한 큐에 접근하여 작업을 선택하고 실행하는 방식을 표현하기위해 '단일 큐'라는 용어를 사용한다.
그러므로 단일 프로세서 스케줄링 기법인 기본 프레임워크가 실제로 여러 개의 큐를 사용하는 MLFQ(Multi-Level Feedback Queue)인 경우도 여전히 멀피트로세서는 SQMS기법을 사용하고 있는 것이다.
단점은 다음과 같다.
-
확장성 결여
SQMS 코드가 단일 큐를 접근할 때 (즉, 실행시킬 다음 작업을 찾을 때) 동기화를 위해 스케쥴러는 코드에 락을 삽입해야한다.
그러나 시스템의 CPU 개수가 증가할수록 락에 의한 성능저하(동기화 오버헤드)가 커진다. -
캐시 친화성 고려한 정책의 구현 복잡성

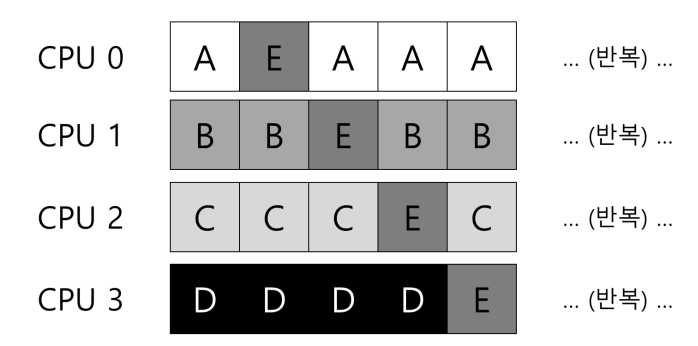
특정 작업들에 대해서 캐시 친화성을 고려하여 스케줄링하고 다른 작업들은 오버헤드를 균등하게 하기 위해 여러 군데로 분산시키는 정책을 사용하는 것은 구현이 복잡하다.
2.0. 멀티 큐 멀티프로세서 스케줄링(multi-queue multiprocessor scheduling, MQMS)
CPU마다 큐를 하나씩 둔다.
각 큐는 특정 스케줄링 기법을 따르며 작업이 시스템에 들어가면 하나의 스케줄링 큐에 배치된다. 배치될 큐(작업이 cpu를 선택)의 결정방법도 정해야한다.
각각이 독립적으로 스케줄 되기 때문에 단일 큐 방식에서 보았던 동기화 문제를 피할 수있다.
즉, 확장성이 좋다.
CPU 개수가 증가할수록, 큐의 개수도 증가하므로 락과 캐시 경합 (cache contention)은 더 이상 문제가 되지 않는다.
또한, MQMS는 작업이 같은 CPU에서 계속 실행되기 때문에 본질적으로 캐시 친화적이다. 캐시친화적이므로 캐시일관성을 유지하기도 쉽다.
** 캐시친화적일수록 캐시일관성을 유지하기 쉬운 이유
캐시 친화성이 낮은 경우, 데이터가 여러 캐시 메모리에 복사되어 있으므로
동일한 데이터를 여러 캐시 메모리에서 동시에 수정하기가 어렵다.
** 캐시 경합
data race와 유사하게, 멀티프로세서 시스템에서 여러 프로세서나 스레드가 동시에 동일한 캐시 라인에 액세스하고 수정하려고 하는 상황
그러나 단점은 있다. 멀티 큐 기반 방식의 근본적인 문제는
워크로드의 불균형이다.
cpu간의 갖고 있는 큐가 다르기 때문에
어떤 큐에서는 과도한 작업을 할 수 있고,
어떤 큐는 idle(유휴)상태가 될 수 있다.
워크로드 불균형을 해소하려면 작업을 다른 큐로(한 CPU에서 다른 CPU로) 옮기는 행위가 필요하다. 이를 이주(migration)라고 부른다.
작업에 대한 지속적인 이주를 위해 사용될 수 있는 다양한 이주패턴이 존재한다.
이주의 필요 여부는 작업훔치기(work stealing)라는 기술로 검사할 수 있다.
작업훔치기는 작업의 개수가 낮은 큐가 가끔 다른 큐에 훨씬 많은 수의 작업이 있는지를 검사하는 기술이다.
물론 작업훔치기로 큐를 검사하는 오버헤드와 워크로드 불균형을 둘 다 고려하여 적절한 주기로 검사하는 것이 필요하다.
3.0. Linux 멀티프로세서 스케줄러
Linux에서는 멀티프로세서 스케줄러로 O(1), CFS, BFS를 사용한다.
O(1), CFS(Completely Fair Scheduler)는 멀티 큐,
BFS(Batched Fair Scheduler)는 단일 큐를 사용한다.
O(1) 스케줄러는 우선순위 기반 스케줄러이다.
프로세스의 우선순위를 시간에 따라 변경하여 우선순위가 가장 높은 작업을 선택하여 다양한 목적을 만족시킨다. 특히, 상호 작용을 가장 우선시 한다.
-> MLFQ에 가까움
CFS는 결정론적 비례배분 방식이다.
-> stride 스케줄링에 가까움
BFS는 단일 큐 방식이며 또한 비례배분 방식이다.
그러나 Earliest Eligible Virtual Deadline
First(EEVDF)라고 알려진 더 복잡한 방식에 기반을 둔다.
https://github.com/remzi-arpacidusseau/ostep-translations/tree/master/korean
https://jiming.tistory.com/192
https://parksb.github.io/article/29.html
