
웬만한 자료형은... 다 알지 않나?
라는 이 오만한 생각... 버려야 할 때가 됐다.
이거 뭔데요... 그리고 뭔가 묘하게 단어들이 달라져서 ㅋㅋㅋㅋ 너무 헷갈린다 킹받아 ㅋㅋㅋㅋㅋㅋ 그래서 일단 이것들 좀 정리하고 더 깊은 공부를 시작해보기로 결정... 흑흑
그냥 대충 내가 군집 자료형이라고 이름을 짓긴 했지만 정확한 분류는 아니다.
- Numeric = {Integer, Complex Number, Float}
- Dictionary
- Boolean
- Set
- Seqence Type = {Strings, List, Tuple}
원래 이런 분류가 있으나... 문자열은 앞서 했고, 그냥 한 번에... 정리하고 싶어서 ^^... 대충 군집 자료형이라고 하고, 이거 하나로 퉁칩니다.
📒 리스트 list
여러 가지 자료를 순서대로 저장할 수 있는 자료,
[]대괄호 내부에 자료를 넣어서 선언하며, 값은 변할 수 있다. 인덱스를 통해 값에 접근한다.
아니 이거 너무 JS 배열이잖아 이래서 헷갈린다고
array = [1, 23, "문자열", True]하지만 JS와 다른점으로는 같은 자료형이 아니어도 저장할 수 있다는 것이다.
선언이나 사용법은 일반적인 배열 사용법과 유사하다.
- 대괄호 내부에 넣는 자료는 요소라고 한다. (element)
- 인덱스를 사용한다.
- 대괄호 안에 음수를 넣어 뒤에서부터 요소를 선택 가능하다. (ex.
array[-1]→ 맨 뒤의 요소가 나온다.) - 리스트 접근 연산자 이중 사용 가능, 리스트 안에 리스트도 가능하다.
리스트 연산
+,*,len()리스트명.append(요소)|리스트명.insert(위치, 요소)extend()
👉 문자열 연산과 똑같이 동작
👉 인덱스를 사용 가능하기 때문에 원하는 위치에 요소를 집어넣을 수도 있다.
👉 한 번에 여러 요소를 추가할 때 사용하며, 매개변수로 리스트를 받는다.
* 연결 연산자(+)는 비파괴적이지만, append(), insert(), extend()는 파괴적으로 작동한다.
* 기본 자료형과 관련된 모든 것들은 비파괴적으로 작동한다.
* 리스트는 용량이 커질 수도 있기 때문에 프로그램 입장에서는 원본을 직접적으로 조작해서 용량이 급격히 커짐으로 인해 발생할 수도 있는 위험을 피하게 한다.
리스트 제거
del 리스트명[인덱스]|리스트명.pop(인덱스)리스트.remove(값)리스트.clear()
👉 1. 인덱스로 제거: del 키워드를 사용하는 경우 인덱스를 사용하기 때문에 범위 지정이 가능하고, pop 메서드의 경우 매개변수를 입력하지 않으면 -1로 취급해서 맨 뒤의 요소를 제거한다.
👉 2. 값으로 제거: 가장 먼저 발견되는 하나를 제거한다. (여러 개의 값을 제거하기 위해서는 반복문과 조합해서 사용)
👉 3. 내부의 요소 모두 제거
리스트 정렬
리스트.sort()
👉 기본 오름차순 정렬(내림차순은 매개변수에 reverse=True), 파괴적으로 동작한다.
리스트 내부 확인
값 [not] in 리스트
👉 리스트 내부에 해당 값이 없는지 확인
* 전개 연산자
리스트 내용을 전개해서 입력한다
JS 배열에서 ... 스프레드 연산자와 같은 역할이다!
a = [1, 2, 3, 4]
b = [*a, *a]
# b = [1, 2, 3, 4, 1, 2, 3, 4]또한 append() 함수와 같이 리스트에 요소를 추가할 때 코드를 비파과적으로 구현할 수 있게 한다.
a = [1, 2, 3, 4]
b = [*a, 5] # [1, 2, 3, 4, 5]리스트 컴프리헨션 (List Comprehension)
리스트를 쉽게, 짧게 한 줄로 만들 수 있는 파이썬의 문법
[(변수를 활용한 값) for (사용할 변수 이름) in (순회할 수 있는 값)]
even_numbers = [x for x in range(1, 11) if x % 2 == 0]
# 2, 4, 6, 8, 10in문에 나오는 순회할 수 있는 값(범위)에서 숫자를 하나씩 꺼내와 for문에 나오는 변수에 할당한다.
그리고 맨 앞에 나오는 변수를 활용한 값으로 리스트 생성...?!
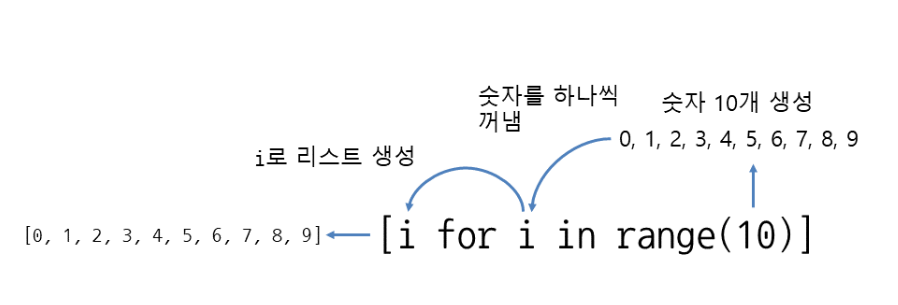
뒤에서부터 앞으로 온다고 생각하면 편할 것 같다. (* 출처)
중첩해서도 사용할 수 있다!
multiplication_table = [[i * j for j in range(1, 10)] for i in range (1, 10)]가장 바깥쪽 컴프리헨션문부터 처리한 다음 안으로 들어온다.
enumerate()
리스트를 순회하며 각 요소의 인덱스와 값을 한꺼번에 가져온다.
names = ["Alice}, "Bob", "Charlie"]
for index, name in enumerate(names):
print(f"{index}: {name}")zip()
여러 리스트를 동시에 순회, 각 리스트의 요소가 튜플 형태로 묶여 반환된다.
📓 딕셔너리 dict
키-값 쌍을 통해 데이터를 저장하는 데이터 타입,
{}로 묶으며 키를 통해 값에 빠르게 접근할 수 있다
변수 = {
키: 값,
키: 값,
...
키: 값
}이건 너무 객체죠...? 이름이... 너무 헷갈린다고요... 자바에서 자바스크립트 배울 때는 그럭저럭 이름들 비슷해서 이해는 할만 했는데 얜 왜 혼자 튀는거임 ㅠㅠ
- 리스트의 인덱스처럼 딕셔너리는 키를 통해 요소에 접근한다. ex.
dict_a["name"] - 리스트나 딕셔너리를 값으로 넣을 수 있다.
딕셔너리에 값 추가/제거
딕셔너리[새로운 키] = 새로운 값 | del 딕셔너리["제거할 키"]
딕셔너리 내부의 값 확인
in키워드get()
👉 in: 딕셔너리 내부에 키가 있는지 없는지를 확인할 때 사용
👉 get(): 딕셔너리의 키로 값을 추출하는 기능, 존재하지 않는 키에 접근할 경우 Key Error가 아닌 None을 출력
📜 범위 자료형 range
정수로 이루어진 범위를 만들 때 사용, 리스트와 딕셔너리만큼 for 반복문에서 많이 활용된다
range(A)
# 0부터 A-1까지의 정수 범위
range(A, B)
# A부터 B-1까지의 정수 범위
range(A, B, C)
# A부터 B-1까지의 정수 범위인데 앞뒤 숫자가 C만큼의 차이를 가짐 📔 튜플 tuple
리스트와 유사하나 불변 자료형
nums = (1, 2, 3, 4, 5)
- 여러 유형의 자료들을 순서대로 나열
- 읽기 전용, 수정 불가
- 소괄호로 생성
- 중복 허용
- 인덱스 사용
- 중첩 가능
* 요소가 하나 뿐인 튜플을 만들 때에는 뒤에 콤마를 추가해야 한다
ex. single_element_tuple = (5,)
그래서 이미 리스트가 있는데 튜플이 왜 필요할까? 이는 이후에 함수를 배우면 자세히 알게될 것! 우선 지금은 특징 몇 가지만 더 짚고 넘어갈 예정이다.
✔️ 괄호를 생략해도 튜플로 인식할 수 있는 경우는 괄호를 생략해도 된다
✔️ 튜플은 함수의 리턴에 많이 사용된다.
📚 세트 set
중복되지 않는 고유한 요소들을 저장하며
{}를 사용해서 저장하지만 순서가 없고, 집합연산에 유용하게 사용된다.
a = {1, 2, 3}
* 빈 집합을 만들 때에는 반드시 set()을 사용해야 한다. dictionary와 구분이 안되기 때문에...
왜 집합연산에 유용하게 사용되냐하면, set이 수학 용어로 '집합'이라는 뜻이다. ...세트라고 배웠던가?
- 무순서
- 고유함
- 변경 가능
- 다형성 : 서로 다른 데이터 타입의 항목을 저장할 수 있다.
연산자
| (합집합) | & (교집합) | - (차집합) | ^ (대칭차집합)
함수
요소 추가 add() (단일 요소 추가) } update()
요소 제거 remove() | discard() (→ discard는 요소가 없어도 오류가 발생하지 않는다) | clear() (모두 제거)
요소 추출 pop() (* 임의의 요소를 제거하고 반환 → 집합은 무순서이기 때문에)
요소 복사 copy()
요소 확인
in키워드issubset()|issuperset()isdisjoint()
👉 여기서도 in을 통해 집합에 요소가 있는지 확인이 가능하다
👉 issubset() : 한 집합이 다른 집합의 부분 요소를 포함하는지 | issuperset() : 한 집합이 다른 집합의 모든 요소를 포함하는지
👉 두 집합이 공통 요소가 없는지 확인 (공통요소 있으면 False, 없으면 True)
확실히 데이터 관리와 비교에 강하다. in 키워드를 사용할 때 성능 이점이 있다. (리스트, 튜플보다 빠름)
부분 집합 및 상위 집합 연산
C = {1, 2}
D = {1, 2, 3, 4}
# 부분집합
print(C <= D) # True
# 진 부분 집합
print(C < D) # True
# 상위 집합
print(D >= C) # True
# 진 상위 집합
print(D > C) # True
파이썬 집합 내포 Set Comprehension
기존의 반복 가능한 객체를 기반으로 집합을 간결하게 생성하는 방법
squares = {x**2 for x in range(1, 6)}파이썬 불변 집합 Frozen Set
불변 버전의 집합으로 생성 후에는 요소를 추가하거나 제거할 수 없다.
frozen_set = frozenset({1, 2, 3})느낀점
하... 진짜 비슷하면서 다른게 왤케 많고... 연산자도 내가 아는듯 모르는듯... 공부해야 할 것이 산더미다 ㅠ 미치겠다~ 하지만 그래도 계속 놓치지 않고 보다보니 알 것 같기도 하고... 기분탓인가? 흑흑... 그냥 지금은 닥치고 열심히 하는 수밖에 없는 것 같다. 아 ~ 근데 문법 너무 이상해 적응안돼 ㅋㅋㅋㅋ 너무 많게 느껴지고 정리할 엄두도 안나서 한동안 진땀을 빼고 있었다. 그나마 파이썬은 진도가 비교적 천천히 나가는 중이라 너무너무 다행이다. 엉엉 ㅠㅠ 파이팅...
본 포스팅은 글로벌소프트웨어캠퍼스와 교보DTS가 함께 진행하는 챌린지입니다.
