
🗃️ RAM의 특징과 종류
🪧 RAM의 특징
휘발성 저장 장치 (volatile memory)
RAM에 저장되는 데이터 → 실행할 프로그램의 명령어와 데이터
⚠️ 전원을 끄면 저장된 명령어와 데이터가 모두 날아간다!
비휘발성 저장 장치는 전원이 꺼져도 저장된 내용이 유지된다
→ 하드 디스크, SSD, CD-ROM, USB 메모리와 같은 보조기억장치
→ 하지만 함정! CPU는 보조기억장치에 직접적으로 접근할 수 없다.
이러한 특성들로 인해
➡️ 비휘발성 저장 장치 (보조기억장치) : '보관할 대상'을 저장
➡️ 휘발성 저장 장치 (RAM) : '실행할 대상'을 저장
📑 RAM의 용량과 성능
만일 CPU가 실행하고 싶은 프로그램이 보조기억장치에 있다면?!
〰️ RAM으로 복사하여 저장한 뒤에 실행!
그럼 이때,
📉 RAM의 용량이 적다면?
보조기억장치에서 실행할 프로그램을 가져오는 일이 잦아 실행 시간이 길어진다 ㅠㅠ
📈 RAM의 용량이 충분히 크다면?
보조기억장치에서 많은 데이터를 가져와서 미리 RAM에 저장할 수 있기 때문에 실행 시간이 빨라진다! 또한 많은 프로그램을 동시에 실행하는데 유리하다.
하지만 그렇다고 용량이 필요이상으로 커졌을 때 속도가 그에 비례하여 증가하지는 않는다...
✳️ RAM의 종류
✅ DRAM
시간이 지나면 저장된 데이터가 점차 사라지는 RAM
- Dynamin RAM의 준말
- 저장된 데이터가 동적으로 변하는(=사라지는) RAM
- 일정 주기로 데이터를 재활성화(다시 저장) 해야 함
- 하지만 소비 전력이 비교적 낮고, 저렴하고, 집적도(빽빽하게 만드는 정도)가 높기 때문에 대용량으로 설계하기 편함 → 일반적으로 메모리로써 사용한다
✅ SRAM
저장된 데이터가 변하지 않는 RAM
- Static RAM의 준말
- 시간이 지나도 데이터가 사라지지 않음 → 주기적으로 데이터를 재활성화할 필요도 없음
- 하지만 SRAM도 전원이 공급되지 않으면 저장된 내용이 날아가기도 한다
- 일반적으로 속도도 더 빠르다
- 집적도가 낮고, 소비전력도 크고, 가격도 더 비싸다 → '대용량으로 만들어질 필요는 없지만 속도가 빨라야 하는 저장장치'에 사용된다 (캐시 메모리에서 사용됨)
✅ SDRAM
클럭 신호와 동기화된, 발전된 형태의 DRAM
- 클럭 타이밍에 맞춰 CPU와 정보를 주고받을 수 있음
- 클럭마다 CPU와 정보를 주고받을 수 있음
✅ DDR SDRAM
대역폭을 넓혀 속도를 빠르게 만든 SDRAM
- 최근 가장 흔히 사용된다
- 대역폭이란? 데이터를 주고받는 길의 너비
- SDRAM에 비해 두 배의 대역폭으로 한 클럭당 두 번씩 CPU와 데이터를 주고받을 수 있다 → 전송 속도가 두 배 가량 빠름!
- DDR2 SDRAM → DDR SDRAM의 두 배 (처음꺼보다 네 배)
- DDR3 SDRAM → 두 배 증가
- DDR4 SDRAM → 두 배 증가 (SDR SDRAM보다 열여섯 배 넓은 대역폭) ➡️요즘 흔하게 사용하는 메모리
📥 메모리의 주소 공간
📮 물리 주소와 논리 주소
CPU와 실행중인 프로그램은 현재 무엇이 어디에 저장되어 있는지, 메모리의 저장 주소를 전부 다 알까? NO!
메모리에 저장된 정보는 시시각각 변한다!
새롭게 실행되는 프로그램이 시시때때로 적재되고, 실행이 끝난 프로그램은 삭제된다
또, 실행할 때마다 적재되는 주소가 달라질 수도 있다
🏷️ 물리주소
정보가 실제로 저장된 하드웨어상의 주소
→ 메모리가 사용
🏷️ 논리주소
실행 중인 프로그램 각각에게 부여된 0번지부터 시작되는 주소
→ CPU와 실행 중인 프로그램이 사용
→ 프로그램마다 같은 논리 주소가 얼마든지 있을 수 있다
CPU가 메모리와 상호작용하기 위해서는 논리주소와 물리주소간의 변환이 있어야 한다
📭 메모리 관리 장치(MMU)
CPU가 발생시킨 논리 주소에 베이스 레지스터 값을 더하여 논리 주소를 물리 주소로 변환
예를 들어서 베이스 레지스터에 15000이 저장되어 있는 상황에서 CPU가 발생시킨 논리주소가 100번지라면? → 물리주소 15100번지로 변환
- 베이스 레지스터: 프로그램의 가장 작은 물리 주소, 프로그램의 첫 물리 주소를 저장
- 논리 주소: 프로그램의 시작점으로부터 떨어진 거리
🗄️ 메모리 보호 기법
프로그램의 논리 주소 영역을 벗어난 명령어는 실행되어선 안된다!
이상한 곳에 엉뚱한 값을 저장할 수도 있고, 자신과 전혀 관련 없는 프로그램 정보를 삭
제할 수도 있기 때문이다
다른 프로그램의 영역을 침범할 수 있는 명령어는 위험하다!
→ 논리 주소 범위를 벗어나는 명령어 실행을 방지하고 실행 중인 다른 프로그램에 영향을 받지 않도록 보호해야 한다
🏷️ 한계 레지스터
➡️ 논리주소의 최대 크기를 저장한다
프로그램의 물리주소 범위 - 베이스 레지스터 값 이상, 베이스 레지스터 값 + 한계 레지스터 값 미만
⚠️ CPU가 접근하려는 논리 주소는 한계 레지스터가 저장한 값보다 크면 안된다
→ 프로그램의 범위에 벗어난 메모리 공간에 접근하는 것과 같기 때문
😀 CPU는 메모리에 접근하기 전에 접근하고자 하는 논리 주소가 한계 레지스터보다 작은지를 항상 검사해야 한다
→ 만약 한계 레지스터보다 높은 논리 주소에 접근하려고 한다면?! 인터럽트(트랩)를 발생시켜 실행 중단
✔️ 실행 중인 프로그램의 독립적인 실행 공간을 확보
✔️ 하나의 프로그램이 다른 프로그램을 침범하지 못하게 보호
📥 캐시 메모리
저장 장치는 일반적으로 아래의 두 명제를 따른다
- CPU와 가까운 저장 장치는 빠르고, 멀리 있는 장치는 느리다
- 속도가 빠른 저장 장치는 저장 용량이 적고, 가격이 비싸다
→ CPU와 가장 가까운 레지스터: 일반적으로 RAM보다 용량은 작지만 접근 시간이 압도적으로 빠르고 가격이 비싸다
→ USB 메모리보다 CPU에 더 가까운 RAM은 접근 시간이 훨씬 더 빠르지만, 같은 용량이라고 할지라도 가격은 더 비싸다
낮은 가격대의 대용량 저장 장치 ⚠️느림
빠른 메모리 ⚠️용량이 적은데 가격은 비쌈
➡️ 컴퓨터는 다양한 저장 장치를 모두 사용한다
🔺 저장 장치 계층 구조
CPU에 얼마나 가까운가를 계층적으로 나타낼 수 있다
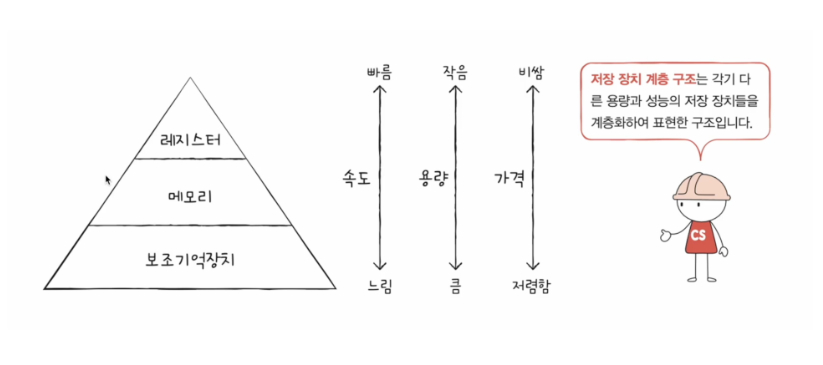
위의 계층으로 올라갈수록 CPU와 가깝고 용량은 작지만 빠름 그리고 비쌈
아래 계층으로 내려갈수록 CPU와 멀고 용량은 크지만 느림 그리고 저렴
📥 캐시 메모리
CPU가 메모리에 접근하는 속도는 레지스터에 접근하는 속도보다 느리다!
그러나... 프로그램을 실행하다보면 메모리에 계속 접근해야 할 수밖에 없음
😀 캐시 메모리 등장!
CPU와 메모리 사이에 위치하고, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치
➡️ CPU의 연산 속도와 메모리 접근 속도 차이를 조금이나마 줄이기 위해 탄생
그렇다면 어떻게 속도 차이를 줄일 수 있을까?!
메모리에서 CPU가 사용할 일부 데이터를 미리 캐시 메모리에 가지고 와서 활용!
→ 캐시 메모리에 CPU가 필요로 하는 데이터가 있다면 필요한 데이터로의 접근 시간을 줄일 수 있다
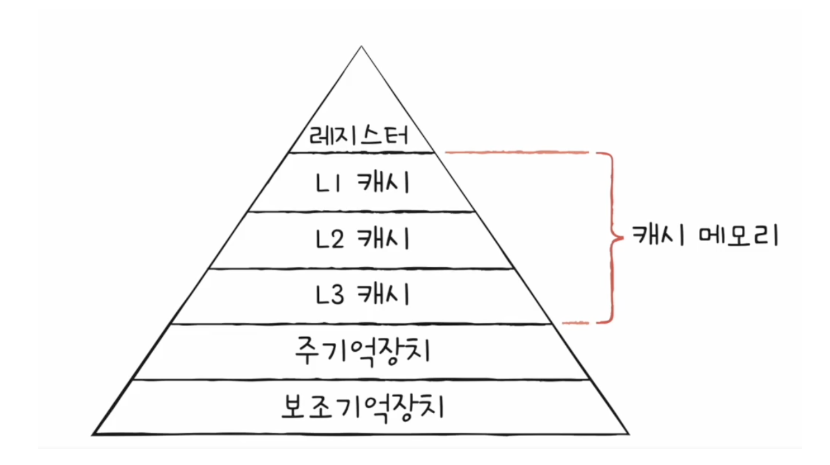
컴퓨터 내부에는 여러 개의 캐시 메모리가 있다!
CPU(코어)와 가까운 순서대로 계층 구성
- L1캐시 (코어와 가장 가까움)
- L2 캐시 (그 다음)
- L3 캐시 (그 다음)
일반적으로 L1, L2는 코어 내부, L3는 코어 외부에 위치
➡️ 캐시 메모리의 용량은 L1~L3 순으로 커짐
➡️ 속도는 그 반대 (L3~L1)
➡️ 가격도 L3~L1 순으로 비싸짐
CPU가 메모리 내에 데이터가 필요하다고 판단
✔️ L1 먼저 체크 (해당 데이터가 있는지)
✔️ 없다면 L2, L3 순으로 데이터 검색
L1 캐시와 L2 캐시는 코어마다 고유한 캐시 메모리로 할당
L3 캐시는 여러 코어가 공유하는 형태로 사용된다
분리형 캐시
L1I - 명령어만 저장
L1D - 데이터만 저장
➡️ 조금이라도 접근 속도를 빠르게 만들기 위해서 분리!
🔺 다시 정리하는 저장 장치 계층 구조!
➿ 참조 지역성 원리
캐시 메모리는 메모리보다 용량이 작다... 때문에 메모리에 있는 모든 내용을 가져다가 저장할 수 없다
♟️ 메모리가 보조기억장치의 일부를 복사하여 저장하는 것처럼 캐시 메모리도 메모리의 일부를 복사하여 저장
🔆 캐시 히트
- 보조기억장치는 전원이 꺼져도 기억할 대상을 저장
- 메모리는 실행 중인 대상을 저장
- 캐시 메모리는 CPU가 사용할 법한 대상을 예측하여 저장
자주 사용될 것으로 예측한 데이터가 실제로 들어맞아 캐시 메모리 내 데이터가 CPU에서 활용되는 경우를 말한다
🔅 캐시 미스
예측이 틀려 메모리에서 필요한 데이터를 직접 가져와야 하는 경우를 말한다
➡️ 캐시 미스가 자주 발생하면 성능이 떨어짐!
✔️ 캐시 적중률
캐시가 히트되는 비율
캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
➿ 참조 지역성의 원리
그렇다면 CPU가 사용할 법한 데이터는 어떻게 알 수 있을까?
딱 한 가지 원칙에 따른다
➡️ 참조 지역성의 원리
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향
- CPU는 접근한 메모리 공간 근처를 접근하려는 경향
최근에 접근했던 메모리 공간에 다시 접근하려는 경향? = 시간 지역성
CPU는 변수가 저장된 메모리 공간을 언제든 다시 참조할 수 있다
✔️ 최근에 접근했던 (변수가 저장된) 메모리 공간을 여러 번 다시 접근할 수 있다
접근한 메모리 공간 근처를 접근하려는 경향? = 공간 지역성
CPU가 실행하려는 프로그램은 보통 관련 데이터들끼리 한데 모여서 저장
➡️ 캐시 메모리는 이렇게 참조 지역성의 원리에 입각해 CPU가 사용할 법한 데이터를 예측한다!
