Gemma-2-2B-IT 소개
Gemma-2-2B-IT는 자연어를 이해하고 생성할 수 있도록 설계된 고급 언어 모델입니다. 이 모델을 파인튜닝하면 특정 도메인에 맞춘 질문-응답 시스템, 대화형 에이전트 등 다양한 NLP 솔루션을 만들 수 있습니다. 특히 이 모델은 의회 회의록 같은 특정 도메인 데이터로 학습하여 맞춤형 응답을 생성할 수 있도록 도와줍니다.
이번 글에서는 Gemma-2-2B-IT 모델을 파인튜닝하는 전체 과정을 단계별로 상세히 설명합니다. 데이터셋 준비, 하이퍼파라미터 조정, 학습 최적화 기술, 그리고 실제 평가 방법까지 포함하여 파인튜닝 워크플로우 전반을 이해할 수 있을 것입니다. 또한, 파인튜닝된 모델을 실제 프로젝트에 활용하는 방법에 대해서도 알아보겠습니다.
Keras, Tensorflow 그리고 pytorch로 각각 fine-tuning을 진행했습니다. 여기서는 pytorch를 중심으로 설명하겠습니다.
목차
- 파인튜닝 준비하기
- 개발 환경 설정
- 필요한 라이브러리 설치
- 모델 불러오기
- 파인튜닝 과정
- 데이터셋 선택
- 데이터 전처리
- 하이퍼파라미터 설정
- LoRA 기법 적용
- 코드 살펴보기
- 평가
- 샘플 출력 분석
- 한계점 및 개선 사항 논의
- 벤치마크 테스트
- 실제 활용
- 기존 프로젝트에 통합하기
- 도전 과제와 고려 사항
- 결론
- 주요 발견 요약
- 향후 개발 방향
- 참고 자료 및 리소스
파인튜닝 준비하기
개발 환경 설정
Kaggle Notebook을 사용해 실험을 진행하고, Google Colab이나 GPU 서버를 활용하여 최적의 계산 성능을 보장하는 것을 권장합니다. 특히 GPU 서버를 사용할 경우 대형 모델의 학습 시간을 크게 단축할 수 있습니다. Python과 머신러닝 개념에 익숙해야 하며, 모델 학습 시 자원 최적화와 관련된 기본적인 지식을 갖추고 있는 것이 유리합니다.
필요한 라이브러리 설치
프로젝트에 필요한 주요 라이브러리는 다음과 같습니다. 이 라이브러리들은 모델 로딩, 데이터셋 관리, 학습 프로세스 최적화 등 파인튜닝의 다양한 단계에서 필수적으로 사용됩니다:
- Transformers:
pip install transformers - Datasets:
pip install datasets - Accelerate:
pip install accelerate - PyTorch:
pip install torch
Transformers 라이브러리는 사전 학습된 모델과 NLP 도구들을 제공하여 파인튜닝을 쉽게 할 수 있게 해줍니다. Datasets 라이브러리는 다양한 형식의 데이터셋을 쉽게 로드하고 전처리할 수 있는 기능을 제공하며, Accelerate는 멀티 GPU 환경에서 학습을 가속화하는 데 유용합니다.
모델 불러오기
transformers 라이브러리를 활용하여 Gemma-2-2B-IT 모델과 토크나이저를 불러옵니다. 토크나이저는 입력 텍스트를 모델이 이해할 수 있는 형식으로 변환하는 역할을 합니다. 이를 통해 모델 학습의 시작점을 설정하게 됩니다:
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)모델과 토크나이저를 불러오면 모델의 가중치와 구성 요소가 메모리에 로드되며, 이후 커스터마이즈를 위해 준비됩니다.
파인튜닝 과정
데이터셋 선택
파인튜닝에 사용된 데이터셋은 의회 회의록으로, 대화형 모델을 학습하기에 적합한 구조를 갖추고 있습니다. 이 데이터셋은 의회 내 논의된 내용에 대한 맥락, 질문, 답변을 포함하고 있어 모델이 의회 관련 질문에 응답할 수 있도록 도와줍니다. 특정 도메인 데이터셋을 사용함으로써, 모델은 해당 도메인에 특화된 지식을 학습하고 이에 기반한 맞춤형 응답을 생성할 수 있습니다.
데이터 전처리
데이터 전처리는 모델 학습의 기초가 되는 작업입니다. 날짜 열 분리, 데이터 타입 변환, 누락된 값 채우기 등 다양한 전처리 작업을 수행하여 데이터 일관성을 유지했습니다. 이를 통해 학습 중 불필요한 오류가 발생하지 않도록 했습니다. 또한, 토큰화를 통해 텍스트를 모델이 처리할 수 있는 형식으로 변환했으며, 불필요한 텍스트와 잡음을 제거해 학습 효율성을 높였습니다.
하이퍼파라미터 설정
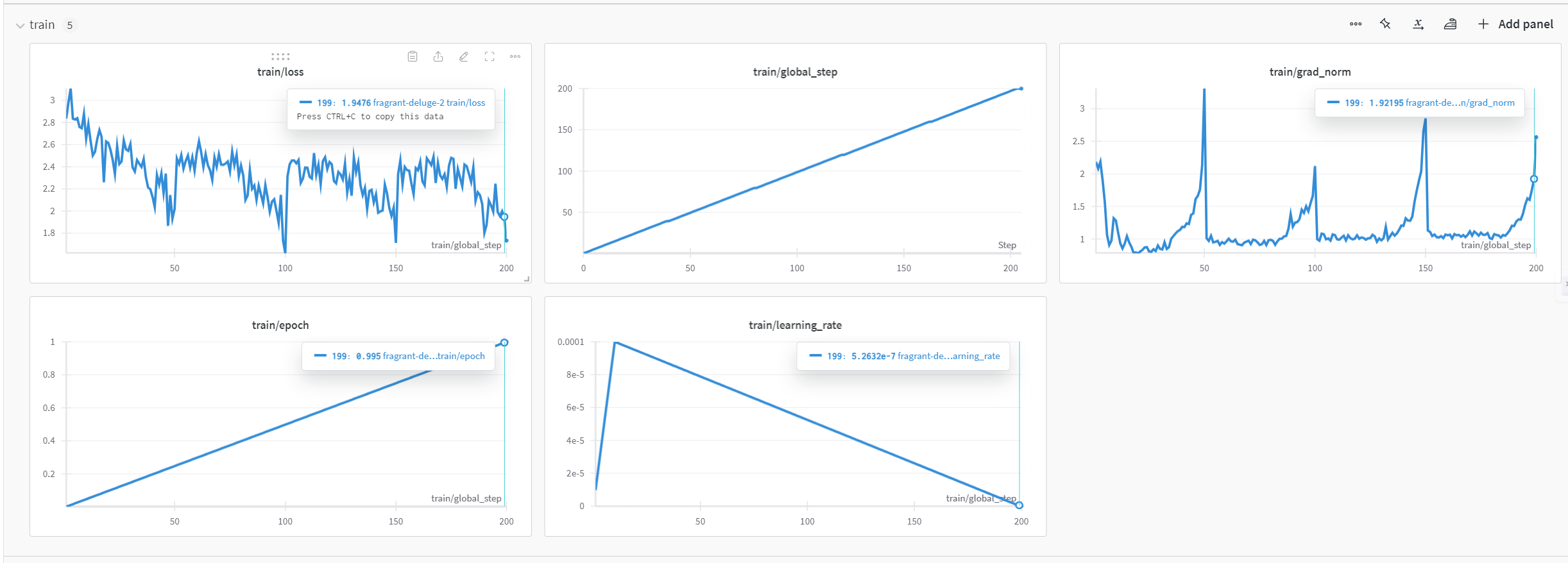
하이퍼파라미터 설정은 모델 성능을 최적화하기 위한 핵심 단계입니다. 학습률, 에포크 수, 배치 크기 등 다양한 하이퍼파라미터를 신중하게 설정해야 합니다. 이번 프로젝트에서는 학습률을 5e-5로 설정하여 학습 속도와 정확도 간의 균형을 맞췄으며, 에포크 수는 1로 설정하여 충분한 학습 반복을 통해 모델의 일반화 성능을 극대화했습니다. 배치 크기는 사용 가능한 자원을 고려하여 설정하여, 각 훈련 단계에서의 계산 효율성을 높였습니다.
LoRA 기법 적용
LoRA(Low-Rank Adaptation) 기법을 적용하여 제한된 하드웨어 자원에서 대형 모델을 효율적으로 학습할 수 있도록 했습니다. LoRA는 학습 가능한 파라미터 수를 줄이고, 메모리 사용량을 최소화하면서도 높은 학습 성능을 유지할 수 있게 합니다. 이 방법은 대형 모델을 훈련할 때 특히 유용하며, 메모리 제약이 있는 상황에서도 원활하게 모델을 파인튜닝할 수 있도록 도와줍니다. LoRA는 낮은 랭크 행렬로 파라미터를 근사함으로써 학습 효율을 극대화합니다.
코드 살펴보기
다음은 주요 코드 구성 요소에 대한 설명입니다. 모델과 토크나이저를 로딩한 후, 데이터셋을 정의하고 학습을 준비하는 방법을 설명합니다.
- 학습 인자 설정: 학습 인자는 모델 학습 과정의 성공적인 진행을 위해 중요한 역할을 합니다. 여기서는 학습률, 배치 크기, 에포크 수, 평가 전략 등 다양한 파라미터가 설정되었습니다. 다음은 학습 인자를 설정하는 코드입니다:
# Setting Hyperparameters
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=1e-4,
weight_decay=0.01,
fp16=True,
bf16=False,
group_by_length=True,
report_to="wandb"
) 모델 학습 시 필요한 다양한 하이퍼파라미터를 설정하여 최적화된 학습을 보장합니다. 특히, gradient_accumulation_steps와 optim 설정을 통해 학습 효율성을 높였습니다.
- SFTTrainer 설정:
SFTTrainer는 모델 학습 과정을 간편하게 관리하고 최적화하기 위해 사용됩니다. 학습 데이터셋, 평가 데이터셋, 토크나이저 및 기타 학습 관련 파라미터들을 설정하여 모델 학습을 진행합니다:
# Setting SFT parameters
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=test_dataset,
peft_config=peft_config,
max_seq_length=1024,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing=False,
formatting_func=generate_prompt
)
model.config.use_cache = False
trainer.train()학습에 필요한 데이터셋, 토크나이저, 파라미터 등을 설정한 후 trainer.train()을 호출하여 실제 학습을 시작합니다. use_cache 설정을 통해 훈련 중 캐시 사용을 비활성화하여 학습 안정성을 높였습니다.
- 데이터셋 로드 및 준비: 학습과 평가에 사용할 데이터를 로드하고 전처리합니다. 데이터셋은 JSON 형식으로 로드되며, 이를 Shuffle하고 선택적으로 일부 데이터를 샘플링합니다. 데이터셋에 대한 포맷팅도 수행하여, 각 행을 시스템, 사용자, 어시스턴트 역할로 정의하는 템플릿을 적용합니다:
import os
from tqdm.notebook import tqdm
import json
from datasets import load_dataset
# 파일 경로 설정
train_file_path = '/kaggle/input/minutes-of-national-assembly-jsonl/train_data.jsonl'
test_file_path = '/kaggle/input/minutes-of-national-assembly-jsonl/validation_data.jsonl'
# train_data.jsonl 로드
train_dataset = load_dataset('json', data_files={'train': train_file_path}, split='train')
train_dataset = train_dataset.shuffle(seed=65).select(range(800)) # 1000개 샘플만 사용 (데모용)
# validation_data.jsonl을 test 데이터셋으로 사용
test_dataset = load_dataset('json', data_files={'test': test_file_path}, split='test')
test_dataset = test_dataset.shuffle(seed=65).select(range(200))
# 데이터 포맷을 정의하는 함수 (template 적용)
def format_chat_template(row):
row_json = [
{"role": "system", "content": row["context"]}, # context를 system 메시지로
{"role": "user", "content": row["context_summary"]["summary_q"]}, # question을 user 메시지로
{"role": "assistant", "content": row["context_summary"]["summary_a"]} # answer를 assistant 메시지로
]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False) # text 필드에 채팅 템플릿 적용
return row
# map 함수를 사용하여 train 및 test 데이터셋에 템플릿 적용
train_dataset = train_dataset.map(format_chat_template, num_proc=4)
test_dataset = test_dataset.map(format_chat_template, num_proc=4)
# 처리된 데이터셋 확인
print(f'Number of train samples: {len(train_dataset)}')
print(f'Number of test samples: {len(test_dataset)}')학습 및 평가에 필요한 데이터셋을 로드하고 적절히 전처리하여 모델 학습에 사용할 수 있는 형식으로 준비합니다.
이러한 과정은 모델이 학습하는 동안 데이터 일관성을 유지하고, 학습 효율성을 극대화하는 데 중요한 역할을 합니다.
평가
Q : 납세자보호담당관의 역할은 조사중지 건수에 의해만 평가되어야 하는 것인가요?
A : 납세자보호담당관의 역할은 조사중지 건수에 의한 평가가 아니라, 납세자의 권익을 보호하고 납세자의 입장에서 납세자 편에서 법을 잘 모르는 사람들 이런 사람들을 위한 어떻게 보면 납세자 변호사 역할을 하는 것이기 때문에 조사중지 건수가 아니라 납세자의 권익 보호에 대한 효과를 평가하는 것이 중요합니다.
샘플 출력 분석
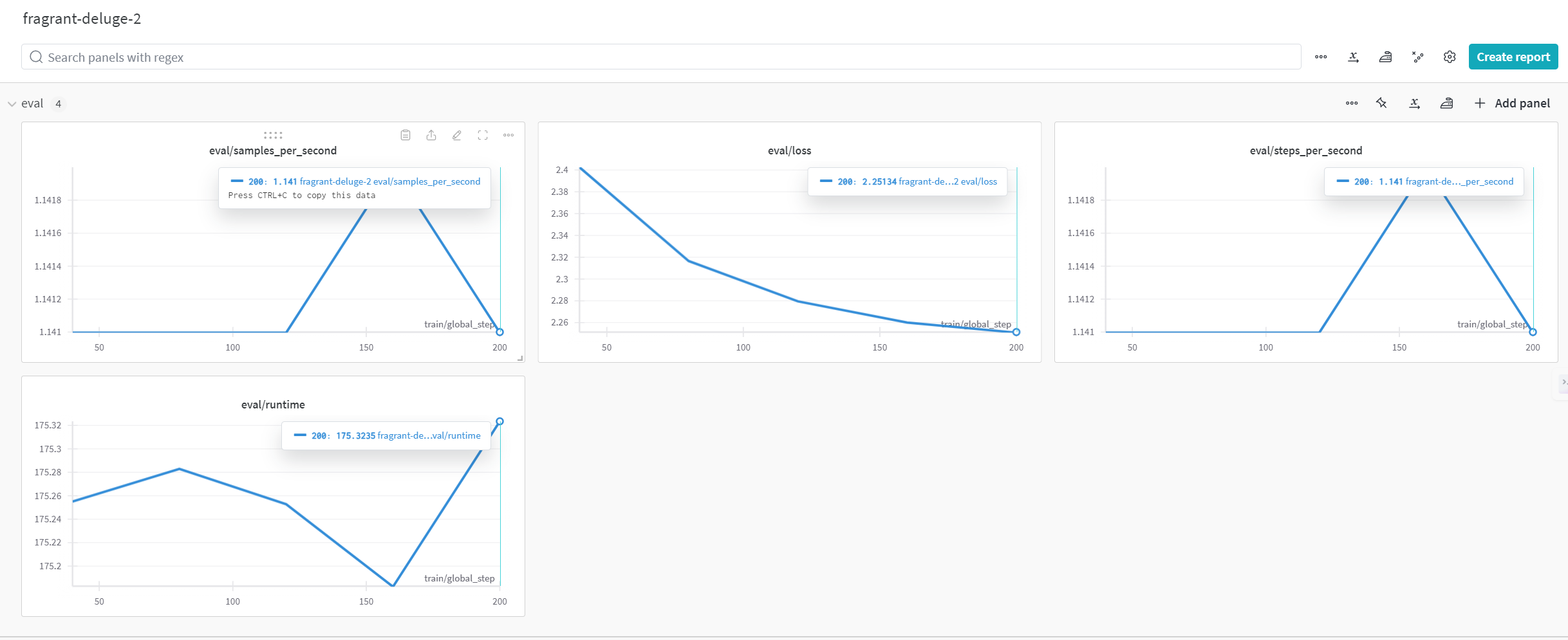
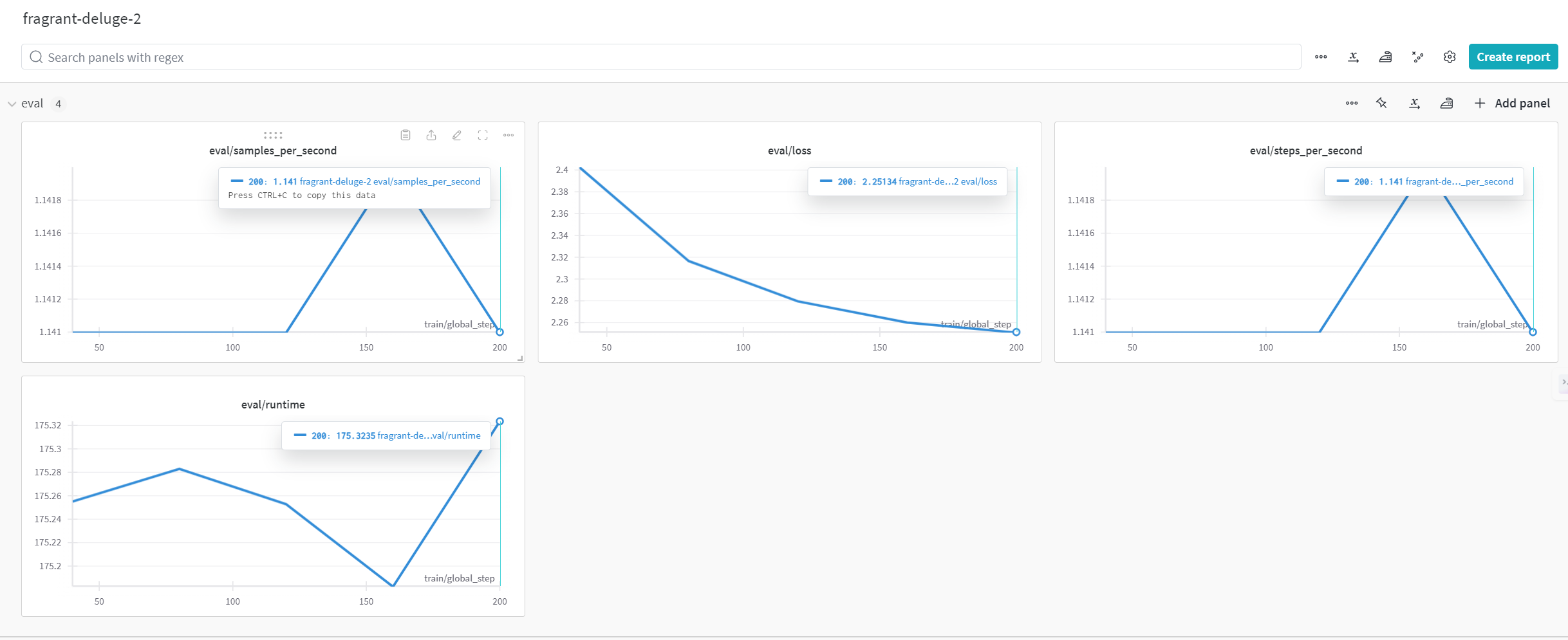
파인튜닝 후 의회 회의록 질문을 사용해 모델을 평가했습니다. 모델의 응답은 맥락을 이해하고 적절한 응답을 생성하는 능력이 향상된 것을 보여줍니다. 특히 특정 도메인 지식을 활용해 일관성 있는 답변을 생성하는 데 유의미한 성과를 보였습니다. 다만 정확한 답변을 내놓은 뒤, 같은 말을 반복하는 점은 추후 수정해나가야 할 점입니다.
한계점 및 개선 사항 논의
GPU Memory의 한계와 가용 리소스의 한계로 충분한 학습을 진행하기는 어려운 부분이 있었습니다. 답변의 첫 부분은 정확하다가 후반으로 갈 수록 같은 말을 반복하는 경향을 보였습니다. 모델은 복잡한 의회 언어를 잘 이해했지만, 일부 모호한 표현에 대해서는 부정확한 해석을 내놓는 경우가 있었습니다. 이는 데이터셋의 다양성을 확장함으로써 개선할 수 있는 부분입니다. 예를 들어, 더 많은 의회 토론 샘플을 포함하거나, 추가적인 전처리 작업을 통해 데이터 품질을 높임으로써 이러한 한계점을 해결할 수 있습니다. 또한, 커리큘럼 학습 기법을 적용해 모델이 점진적으로 어려운 언어적 패턴을 학습하도록 할 수 있습니다.
벤치마크 테스트
Wandb를 사용해 loss값이 줄어드는 것을 확인했습니다. 정확도와 같은 파인튜닝된 모델은 원래의 사전 학습 모델과 비교했을 때 응답 정확도와 일관성에서 상당한 개선을 보였습니다. 특히 도메인 특화된 응답 생성에서 탁월한 성능을 나타내었으며, 이는 의회 회의록과 같은 특정 분야에 대한 이해도를 높이기 위한 파인튜닝의 효과를 잘 보여줍니다. 학습 시간과 자원 사용량 측면에서도 LoRA 기법을 통해 자원 효율성을 크게 개선할 수 있었습니다.
실제 활용
기존 프로젝트에 통합하기
파인튜닝된 Gemma-2-2B-IT 모델은 다양한 입법 관련 도구에 통합될 수 있습니다. 예를 들어, 의회 토론을 분석하고 요약하는 시스템에 통합하여 시민들에게 정보를 제공하거나, 입법자들이 필요한 정보를 빠르게 찾을 수 있도록 지원할 수 있습니다. 이 모델을 API 형태로 제공하면 실시간 쿼리와 응답 생성을 지원할 수 있으며, 챗봇 인터페이스와 결합해 다양한 질문에 대해 답변하는 대화형 시스템으로도 활용될 수 있습니다.
도전 과제와 고려 사항
이 모델을 실제 프로젝트에 적용할 때는 몇 가지 도전 과제를 고려해야 합니다. 예를 들어, 의회 용어의 복잡성과 특정 문맥에서의 모호함은 여전히 해결해야 할 과제입니다. 또한, GPU 메모리 사용을 최적화하고 모델의 추론 속도를 높이기 위해 추가적인 최적화 작업이 필요할 수 있습니다. 더 많은 epoch과 batch size를 가져갈 수 있도록 개선해야 합니다. 최적의 hyper parameter 값을 찾는 방법도 발전해야 합니다.
Conclusion
1. Fine-tuning using Keras, tf
Insights
- The use of TPU accelerated the training process, allowing faster experimentation with model fine-tuning.
- Keras and Tensorflow provided easy integration with TPU, simplifying the process of handling large datasets and complex models like Gemma2-intruct-2B.
- Fine-tuning the model on the National Assembly minutes dataset demonstrated the potential to develop a specialized QnA chatbot for analyzing and understanding parliamentary activities.
Limitations
- Overfitting was a concern due to the limited size of the dataset, impacting the model's ability to generalize to unseen data.
Implications
- Developing a specialized chatbot for analyzing parliamentary minutes can enhance transparency and public access to legislative processes.
- A well-trained model on such data could assist in summarizing complex political discussions and answering public queries more efficiently.
- Further improvements, such as expanding the dataset and optimizing hyperparameters, could lead to a more robust and reliable system.
2. Fine-tuning using pytorch
Conclusion:
The notebook fine-tunes the Gemma-2-2b-it model on National Assembly minutes, focusing on generating legislative QnA responses. The combination of memory-efficient techniques like quantization and resource tracking through W&B makes this pipeline effective for fine-tuning large models.
1. Key Insights
- Memory Efficiency: 4-bit quantization enables training large models on limited GPU memory, making large-scale model fine-tuning more accessible.
Experiment Tracking: W&B integration ensures that you can monitor the training process and compare different runs, which is critical for improving model performance. - Scalability: Using Hugging Face’s model hub allows easy deployment and reuse of the fine-tuned model for downstream tasks, ensuring that others can leverage your work.
2. Limitations
- Model Size: Despite 4-bit quantization, working with very large models like Gemma-2-2b-it can still be challenging on lower-end GPUs, and further memory optimization may be needed.
- CUDA Memory Issues: In the case of CUDA out-of-memory (OOM) errors, further adjustments such as gradient accumulation or reducing batch sizes may be necessary to prevent crashes during training.
- Experiment with Smaller Batches: If CUDA OOM errors persist, experiment with reducing the batch size or using gradient checkpointing.
3. Next Steps
- Explore Additional Data Augmentation: Incorporating more legislative records or synthetic data could improve model performance, especially for niche queries.
- Hyperparameter Tuning: You could explore additional tuning of learning rates, warmup steps, and optimizer settings to further improve the fine-tuning results.
- Experiment with Larger Batches
참고 자료 및 리소스
Deploying the model to hugging-face
reference link:
fine-tuning:
-
blogs:
https://www.datacamp.com/tutorial/fine-tuning-gemma-2
https://devocean.sk.com/blog/techBoardDetail.do?ID=165703&boardType=techBlog
https://issul.tistory.com/447
dataset:
- https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=71795
Kaggle
Keras, TF
