가끔 한국어를 적으려다가 실수로 영어를 길게 적는 케이스가 많았다.
(...)
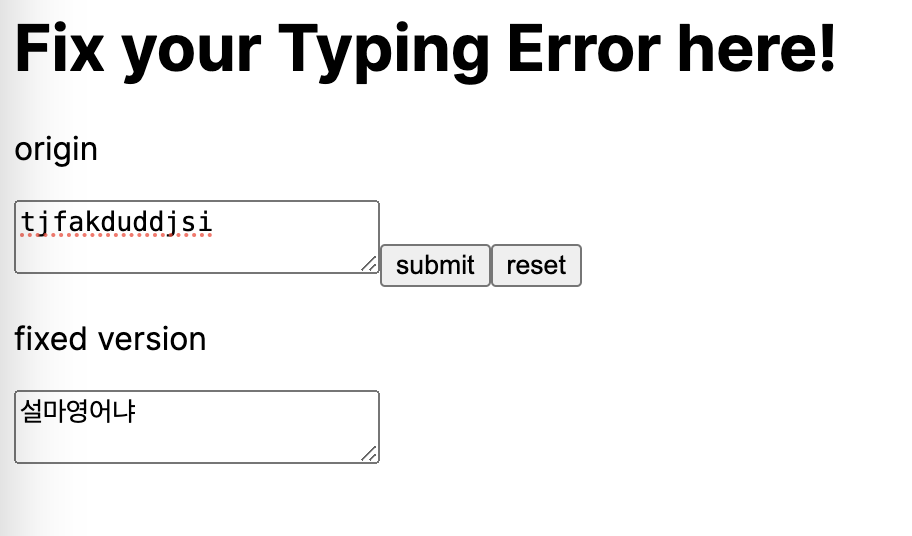
그래서 영타 변환기를 만들어봤다.
How to make it?
알고리즘을 세 파트로 나누었다.
1) 알파벳을 한글에 매칭시키기
dkssud -> 'ㅇ ㅏ ㄴ ㄴ ㅕ ㅇ'2) 한국어 음절로 나누기
'ㅇ ㅏ ㄴ ㄴ ㅕ ㅇ' -> ['ㅇ ㅏ ㄴ', 'ㄴ ㅕ ㅇ']3) 나눈 음절 유니코드에 맞춰 한글로 변환하기
['ㅇ ㅏ ㄴ', 'ㄴ ㅕ ㅇ'] -> '안녕'순서대로 코드를 보자.
1. 알파벳을 한글에 매칭시키기
자바스크립트 자료형의 조회 성능을 고려서하여,
알파벳 - 한글 매칭은 자료형 Map을 이용하였다.
export const KOREAN_DICTIONARY = new Map([
['q','ㅂ'], ['Q', 'ㅃ'], ['w', 'ㅈ'], ['W','ㅉ'],
['e','ㄷ'], ['E','ㄸ'], ['r','ㄱ'], ['R','ㄲ'], ['t','ㅅ'],
['T','ㅆ'], ['y','ㅛ'], ['u','ㅕ'], ['i','ㅑ'], ['o','ㅐ'],
['p','ㅔ'], ['a','ㅁ'], ['s','ㄴ'], ['d','ㅇ'], ['f','ㄹ'],
['g','ㅎ'], ['h','ㅗ'], ['j','ㅓ'], ['k','ㅏ'], ['l','ㅣ'],
['z','ㅋ'], ['x','ㅌ'], ['c','ㅊ'], ['v','ㅍ'], ['b','ㅠ'],
['n','ㅜ'], ['m','ㅡ'], ['O','ㅒ'], ['P','ㅖ'], ['Y','ㅛ'],
['U','ㅕ'], ['I','ㅑ'], ['H','ㅗ'], ['J','ㅓ'], ['K','ㅏ'],
['L','ㅣ'], ['B','ㅠ'], ['N','ㅜ'], ['M','ㅡ'], ['A','ㅁ'],
['S','ㄴ'], ['D','ㅇ'], ['F','ㄹ'], ['G','ㅎ'], ['Z','ㅋ'],
['X','ㅌ'], ['C','ㅊ'], ['V','ㅍ']
])
/** get a korean character matched an english character*/
export const handleEnglishCharacterMatch = (englishText: string) => {
let koreanTextArray: string[] = [];
for(const char of englishText){
const matchedKoreanChar = KOREAN_DICTIONARY.get(char);
if(matchedKoreanChar){
koreanTextArray.push(matchedKoreanChar);
} else {
koreanTextArray.push(char)
}
}
return koreanTextArray;
}
2.한국어 음절로 나누기
여기가 좀 머리가 아팠는데,
한국어 자음 모음이 끊어지는 경우의 수를 파악하였다.
const isJungseong = (char: string) => JUNGSEONG.has(char);
const isChoseong = (char: string) => CHOSEONG.has(char);
const isJongseong = (char: string) => JONGSEONG.has(char);
/** Check if the current character is the end of a word */
const isEndOfWord = (currentChar: string, nextChar: string | undefined, prevChar: string | undefined): boolean => {
// 중성 + 초성
if (isJungseong(currentChar) && nextChar && isChoseong(nextChar)) {
return true;
}
// 종성 + 초성
if (isJongseong(currentChar) && nextChar && isChoseong(nextChar)) {
return true;
}
// 초성 + 초성 or 초성 + undefined
if (isChoseong(currentChar) && (!nextChar || isChoseong(nextChar))) {
return true;
}
// 초성 + 중성 + 종성
if (prevChar && isChoseong(prevChar) && isJungseong(currentChar) && nextChar && (isChoseong(nextChar) || isJongseong(nextChar))) {
return true;
}
return false;
};
/** split korean characters into syllables */
koreanCharacterArray.reduce((acc: string[], char, i, array) => {
const nextChar = array[i + 1];
const prevChar = array[i - 1];
// 현재 문자와 다음 문자를 기준으로 음절 경계를 판단하여 음절을 분리
if (i === array.length - 1 || isEndOfWord(char, nextChar, prevChar)) {
acc.push(array.slice(start, i + 1).join(''));
start = i + 1;
}
// 자음 하나로 묶기: 단일 자음이 있는 경우 이전 음절과 합침
const lastWord = acc[acc.length - 1];
if (lastWord && lastWord.length === 1 && isChoseong(lastWord) && acc.length > 1) {
const mergedWord = acc[acc.length - 2] + lastWord;
acc.splice(acc.length - 2, 2, mergedWord);
}
return acc;
}, words);특히 한국어에는 이중 자음, 이중 모음이 있어
해당 부분은 따로 처리해주었다.
/** convert dubble letter */
const processWord = (word: string): string => {
const wordArray = word.split('');
const processDoubleLetter = (arr: string[], startIndex: number, isDoubleFunc: (char: string) => boolean, makeListFunc: (subArr: string[]) => string): void => {
if (isDoubleFunc(arr[startIndex]) && isDoubleFunc(arr[startIndex + 1])) {
const original = arr[startIndex];
arr[startIndex] = makeListFunc(arr.slice(startIndex, startIndex + 2));
if (original !== arr[startIndex]) {
arr.splice(startIndex + 1, 1);
}
}
};
if (wordArray.length > 2 && isChoseong(wordArray[0]) && isJungseong(wordArray[1])) {
processDoubleLetter(wordArray, 1,isJungseong, makeJungseongList);
}
if (wordArray.length >= 4 && isJongseong(wordArray[2]) && isJongseong(wordArray[3])) {
processDoubleLetter(wordArray, 2, isJongseong, makeJongseongList);
}
return wordArray.join('');
};3. 나눈 음절 유니코드에 맞춰 한글로 변환하기
여기가 가장 간단했다.
유니코드로 가볍게 변환해주었다.
/** change split character to korean */
const combineKoreanCharacter = (characterArray: string[]): string => {
const [choseong, jungseong, jongseong] = characterArray;
const choseongIndex = CHOSEONG.get(choseong) as number;
const jungseongIndex = JUNGSEONG.get(jungseong) as number;
const jongseongIndex = JONGSEONG.get(jongseong) || 0;
const hangulChar = String.fromCharCode(0xAC00 + (choseongIndex * 21 * 28) + (jungseongIndex * 28) + jongseongIndex)
return hangulChar;
}완성
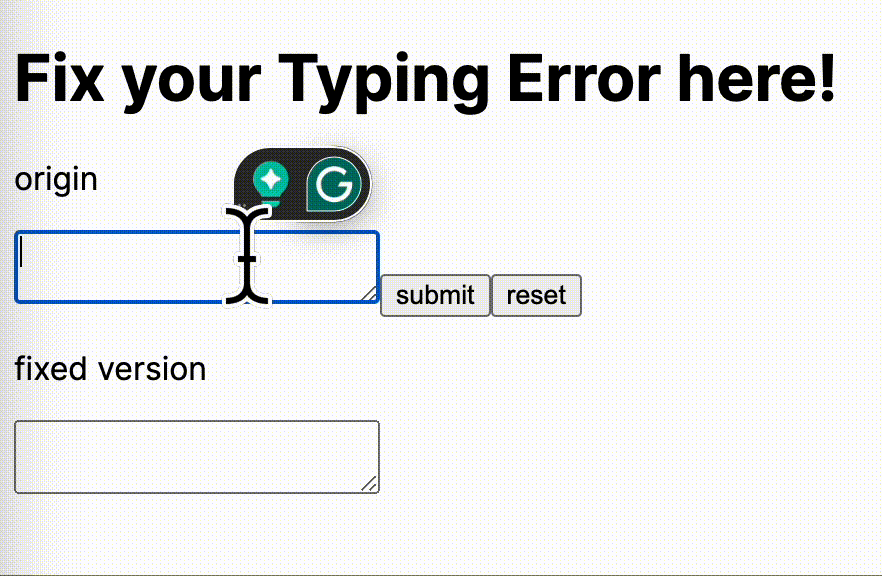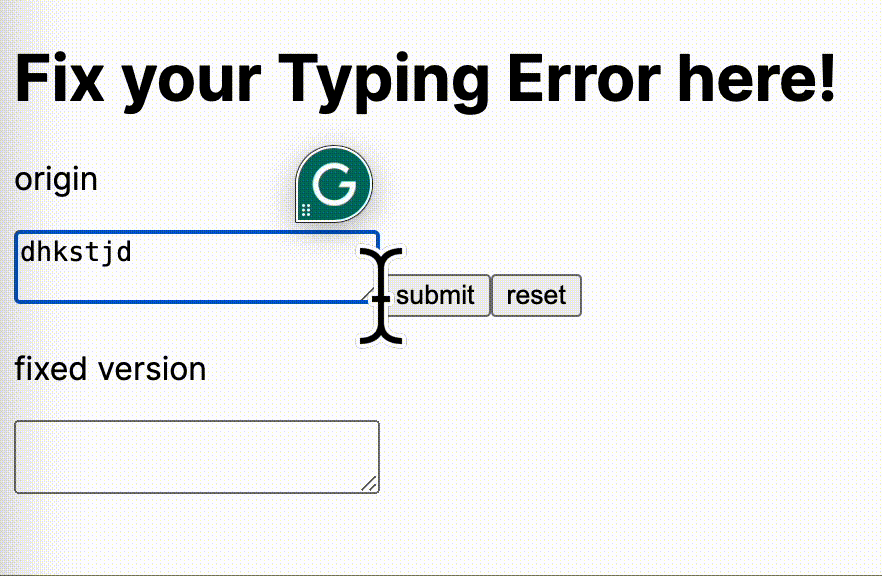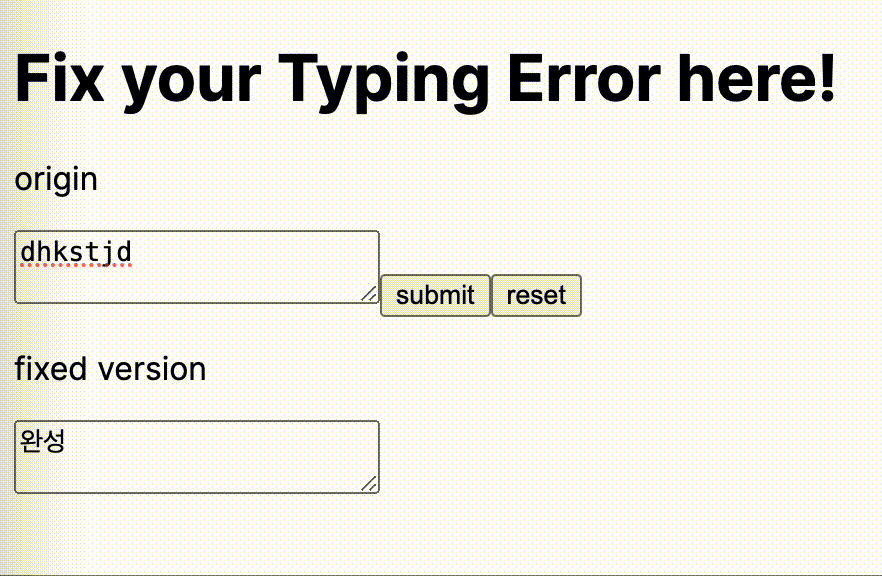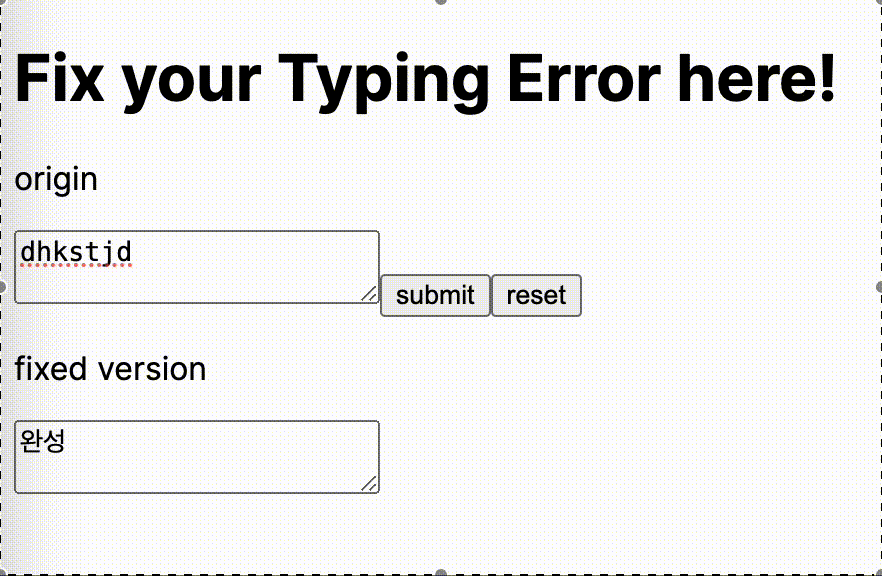
전체 코드는 여기서 확인할 수 있다.
https://github.com/roum02/Fix-your-errors
다음주는 배포해와야지..

이제는 이것저것 먹어요