Goal
- 분할 정복 알고리즘을 이해한다.
- 연습을 통해, 본 알고리즘을 문제 상황에 적용하는 방법을 학습한다.
1. Divide and Conquer?
왜 분할 정복을 사용하는가?
Time Complexity의 n이 증가할 수록 연산 시간, 메모리 측면에서 고비용 발생함
하나의 큰 Problem을 Sub problem으로 나눠서 연산
input size가 큰 경우에는 n이 기하급수적으로 증가할 수 있다.
따라서, 최상의 경우를 산정하였을 때 분할 정복 알고리즘을 쓰는 게 유리하다고 할 수 있을 것이다.
즉, 전체적인 연산시간과 메모리 사용량이 줄어드는 이점을 바탕으로 함
반론
단, input size가 작다면? 이러한 알고리즘을 사용하는 것이 비효율적이라고 할 수 있다. 왜냐면 O(n) 시간복잡도를 가지는 알고리즘 보다 항상 빠르지 않기 때문
비효율적인 이유
- 재귀 호출 스택에 따른 메모리 사용량
- 알고리즘 구현의 복잡성
- 입력크기가 작은 경우 시간 복잡도 간의 편차가 거의 없음
- 입력 데이터에 따라 시간 복잡도 상승 가능성
알고리즘 : Two-step
분할 (divide)
- 우리가 해결해야 하는 문제가 너무 크고 복잡하다고 가정한다면 많은 계산 시간과 연산 작업이 수반 될 것이다.
- 이를 해결하고자, 기존의 문제를 더 작고 관리하기 쉽도록 분할한다.
정복 (conquer) 그리고 결합(merging).
- 분할된 하위 문제를 각각 해결한다.
- 보통은 재귀적으로 수행할 수 있다.
- 하위 문제의 해결을 결합하여 최종적인 문제의 해결을 얻는다.
시나리오
분할
- 입력 크기 N을 세 그룹으로 나눈다. 각 그룹의 크기는 N/2로 가정
- 분할된 그룹은 각각 A, B, C로 산정한다.
정복
- 각 그룹에 대해 다시 분할 정복 알고리즘을 재귀적으로 호출한다.
- 인풋에 대한 분할이 불가능할 때까지 재귀적으로 반복
- 재귀적인 반복을 통해 하위문제는 절반으로 쪼개지게 된다.
- 첫번째 depth : N/2
- 두번째 depth : N/2^2
- 세번째 depth : N/2^3
- 네번째 depth : N/2^4
- 다섯번째 depth : N/2^5
- 이 경우 K를 기준으로 로그시간으로 증가함을 알 수 있음
- 첫번째 depth : log2(2)
- 두번째 depth : log4(2)
- 세번째 depth : log8(2)
- 네번째 depth : log16(2)
- 다섯번째 depth : log32(2)
병합
- 각 그룹에서 반환된 결과를 병합하여 최종 결과를 얻는다.
- 병합 단계에서 추가적인 시간 복잡도가 발생할 수 있다.
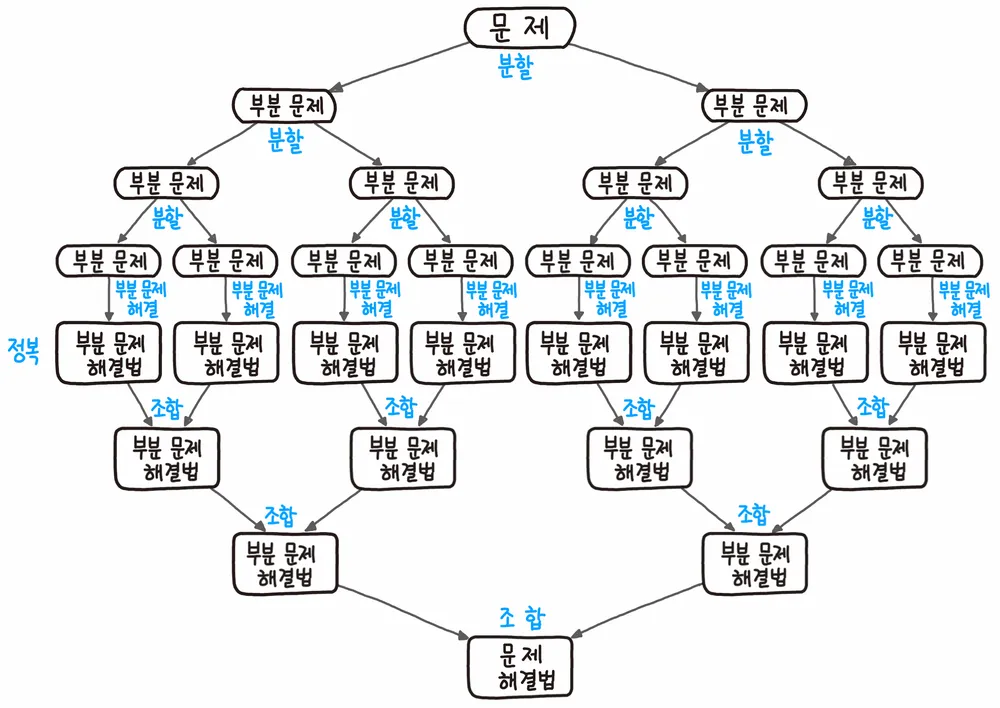
출처 나무위키
분할 정복 사용시
- 어떻게 분할할 것인가? -> 각각의 문제가 독립적인 것이 좋음
- 어떻게 부분 문제를 해결할 것인가?
- 어떻게 부분 문제 해결법을 문제에 병합할 것 인가?
결국, 각 step에서 시간복잡도를 줄이기 위한 효율성을 생각해야함.
분량 조절 실패로 다음 글에서 분할 정복을 이용하는 알고리즘 예시를 살펴보도록 하겠다.
