학습 정리
SQL 함수
1. 숫자 함수
- abs, power(m,n) : m의 n제곱, round(m,n), mod(m,n):나머지, ceil, trunc() : 특정 자리 수 아래로 버림, floor : 소수점 아래
- nvl : 값이 null이면 값 설정(연산을 하려면 대체 값도 number로)
- nvl2 : 값이 null이 아니면 값, null이면 값
- coalesce : 조건 중, null이 아닌 최초의 컬럼 값
--nvl(값, null일 경우 대체할 값)
--nlv2(값, null이 아닌경우 대체할 값,null일 경우 대체)
select first_name, salary, commission_pct, manager_id, department_id
, salary + salary*nvl(commission_pct, 0)
,nvl2(commission_pct, '커미션있음','커미션0')
,coalesce(commission_pct, manager_id, department_id) "null이 아닌 최초 컬럼"
from employees; 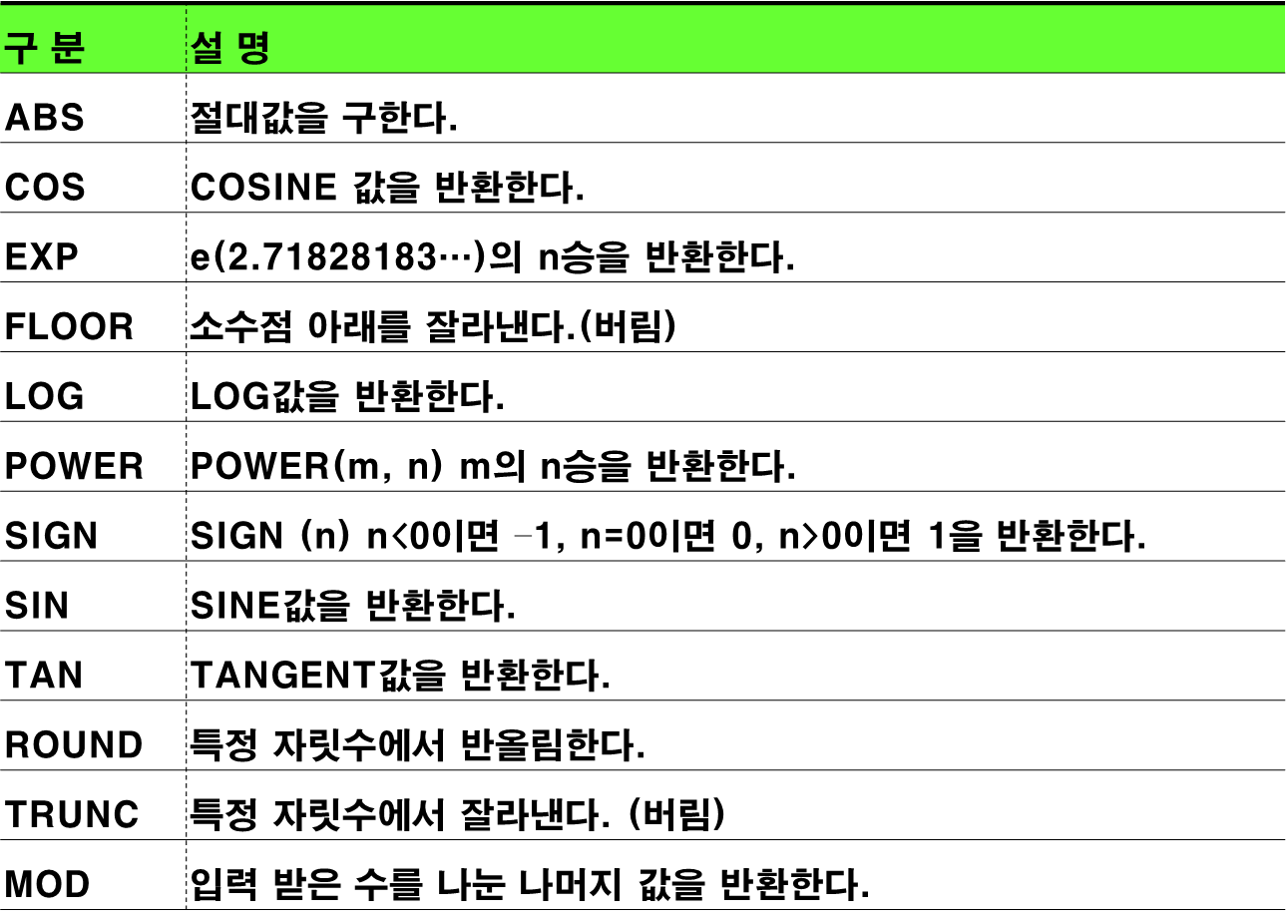
2. 문자 함수
- initcap : 각문자의 시작만 대문자로
- 인코딩 방식에 따라 문자길이 반환 & 자르는 함수의 결과 값 차이가 있음
- instr : 대상 문자열이나 칼럼에서 특정 문자가 나타나는 위치를 알려준다. (찾을 위치, 몇번째 발견 순서) 저장 가능
- trim => ltrim / rtrim 가능
select ' oracle ',
'*'||ltrim(' oracle ')||'*',
'*'||trim('A'from'AAAAAAAoracleAAAAAA')||'*' --특정문자도 검색하여 trim 가능
from dual;

3. 날짜 함수
- sysdate : 오라클 방식의 현재날짜
- getdate : mysql 방식의 현재날짜
select
to_char(sysdate,'yyyy-MM-dd hh:mi:ss') --2023-09-20 11:05:15
from dual;
--입사 기간 계산
select
first_name,
round(sysdate - hire_date,2) as "입사 일수",
floor(months_between(sysdate, hire_date)) as "입사한 개월수",
floor(months_between(sysdate, hire_date)/12) as "입사한 년수",
months_between('2023/05/15','2023/01/15')
from employees;
--month yeare 활용
select
first_name, hire_date,
round(hire_date,'MONTH') as "월반올림", -- month는 16일 부터 반올림
round(hire_date,'year') as "연올림", -- year는 7월 부터 반올림
ceil(to_date('2023/09/29') - sysdate) -- 날짜를 기준으로 일자 반환
from employees;
--nextday (날짜 인자값에서 최초로 나타나는 요일의 날짜 반환)
select sysdate, sysdate+1, next_day(sysdate, '화요일') --23/09/26
from dual;
--lastday(기준이 되는 날짜의 월의 마지말 일자 구하기)
4. 형변환 함수
select sysdate,
to_char(sysdate, 'yy-mm-dd am hh:mi:ss') "날짜->문자", --문자라 더하기 안됨
-- 아래는 초단위까지의 시간에 포맷을 주어서 날짜로 인식하여 계산은 되지만, 출력은 일까지만
to_date('2023-09-20 13:10:10','yyyy/mm/dd hh24:mi:ss')+1.4 "문자->날짜로"
from dual;
5. 통화 관련 함수
- 000,000,000 : 빈자리를 0으로 채움 / 999, 이건 숫자 안채움
- 포맷 숫자 뒤편에 L을 붙이면 각 국가의 통화기호 출력됨
- to_char 의 포맷으로 활용됨
6. 조건 함수
- decode : if문과 비슷, value가 조건과 같으면 설정 값 출력
- case :
select manager_id, decode(manager_id, 100, '스티븐',102,'니나',103,'렉스','기타') as "decode연습1"
from employees;
select manager_id
, decode(job_id, 'IT_PROG' , salary*1.1, 'FI_ACCOUNT', salary*1.2, salary*1.05) "decode 연습"
, case when manager_id=100 then '스티븐'
when manager_id = 102 then'니나'
when manager_id = 103 then'렉스'
else '기타' end "case 연습",
salary,
case when salary>15000 then 'A'
when salary between 10000 and 15000 then 'B'
when salary>=5000 and salary<10000 then 'C' else 'D' end "case연습3",
first_name,
case when length(first_name) >=7 then '이름이 길다' else '이름이 짧다' end
from employees;7. 그룹함수
- 함수 인자로 * 을 적으면 null 포함, 컬럼명 적으면 해당 컬럼만
- 중복되지 않는 행 갯수를 구하고 싶으면, distinct를 컬럼 앞에 작성
- group by
- select절에 참여한 컬럼이 group by 절에 반드시 있어야함. (selct절과 group by절 동일하면 편함)
- rollup : 소그룹간 합계
- cube : 모든 컬럼에 대해서 합계
- 실행 순서
select department_id as "dfdf", sum(salary) --5
from EMPLOYEEs --1
where salary >= 10000 --2
group by department_id --3
having sum(salary)>= 50000 --4
order by 1; --6

