
Chapter 01. 컴퓨터 구조 시작하기
01-1. 컴퓨터 구조를 알아야 하는 이유
- 컴퓨터 구조를 이해하면 문제 해결 능력이 향상된다.
- 컴퓨터 구조를 이해하면 문법만으로는 알기 어려운 성능/용량/비용을 고려하며 개발 할 수 있다.
01-2. 컴퓨터 구조의 큰 그림
컴퓨터가 이해하는 정보
- 데이터 : 컴퓨터가 이해하는 숫자, 문자, 이미지, 동영상과 같은 정적인 정보를 가리켜 데이터(data)라고 한다.
- 명령어 : 데이터를 움직이고 컴퓨터를 작동시키는 정보이다.
즉, 명령어는 컴퓨터를 작동시키는 정보이고, 데이터는 명령어를 위해 존재하는 일종의 재료이다.
컴퓨터의 4가지 핵심 부품
- CPU(중앙처리장치)
CPU는 메모리에 저장된 명령어를 읽어 들이고, 읽어 들인 명령어를 해석하고, 실행하는 부품이다. CPU 내부 구성 요소 중 가장 중요한 3가지이다.
- ALU(산술논리연산장치) : 컴퓨터 내부에서 수행되는 대부분의 계산 수행
- 레지스터 : CPU 내부의 작은 임시 저장 장치
- 제어장치 : 제어 신호라는 전기 신호를 내보내고 명령어를 해석하는 장치
-
메모리(주기억장치)
메모리는 현재 실행되는 프로그램의 명령어와 데이터를 저장한다.
프로그램이 실행되기 위해서는 반드시 메모리에 저장되어 있어야 한다.
메모리에 저장된 값의 위치는 주소로 알 수 있다. -
보조기억장치
메모리보다 크기가 크고 전원이 꺼져도 저장된 내용을 잃지 않는 메모리를 보조할 저장 장치
메모리가 현재 '실행되는' 프로그램을 저장한다면, 보조기억장치는 '보관할' 프로그램을 저장한다고 생각해도 좋다. -
입출력장치
마이크, 스피커, 프린터, 마우스, 키보드처럼 컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환하는 장치를 말한다.
지금까지 설명한 컴퓨터의 핵심 부품들은 모두 메인보드(마더보드)라는 판에 연결된다. 메인보드에는 앞서 소개한 부품을 비롯한 여러 컴퓨터 부품을 부착할 수 있는 슬롯과 연결 단자가 있다.
메인보드에 연결된 부품들은 서로 정보를 주고받을 수 있는데, 이는 메인보드 내부에 버스라는 통로가 있기 때문이다. 컴퓨터 내부에는 다양한 종류의 버스(통로)가 있는데 그 가운데 컴퓨터의 네 가지 핵심 부품을 연결하는 가장 중요한 버스는 시스템 버스이다.
Chapter 02. 데이터
02-1. 0과 1로 숫자를 표현하는 방법
정보 단위
컴퓨터가 이해하는 가장 작은 정보 단위를 비트(bit)라고 한다. 전구 한 개로 (꺼짐) 혹은 (켜짐), 두 가지 상태를 표현할 수 있듯 1비트는 0 또는 1, 두 가지 정보를 표현할 수 있다. n비트는 2n가지의 정보를 표현 할 수 있다.
이진법
- 수학에서 0과 1로 모든 숫자를 표현하는 방법을 이진법(binary)라고 한다.
- 숫자가 1을 넘어가는 시점에서 자리 올림을 하여 1보다 큰 수도 표현할 수 있다.
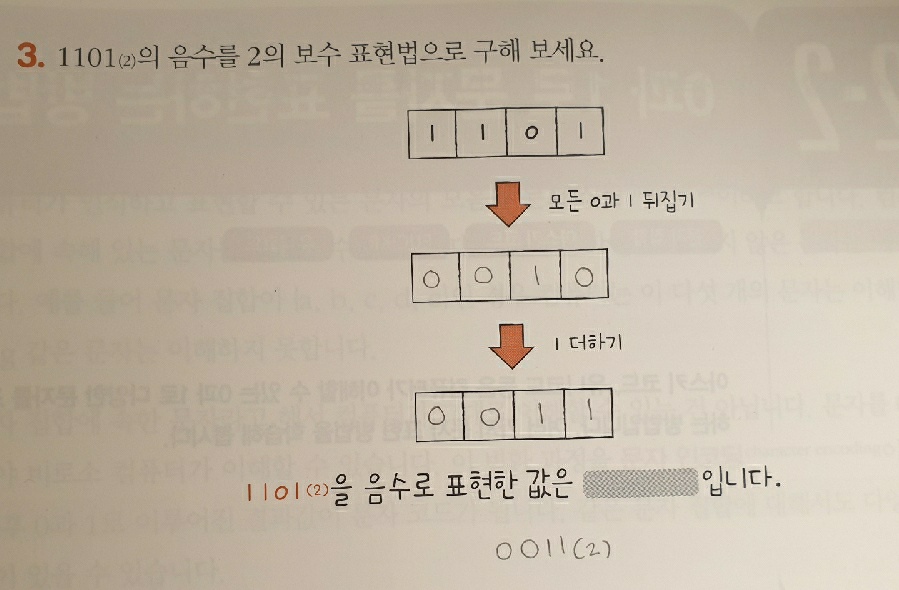
- 음수를 표현하는 방법은 2의 보수를 구해 이 값을 음수로 간주한다. 2의 보수를 매우 쉽게 표현하자면 '모든 0과 1을 뒤집고, 거기에 1을 더한 값'이다.
- 컴퓨터 내부에서 어떤 수를 다룰 때는 양수인지 음수인지를 구분하기 위해 플래그를 사용한다.
- 이진수 표현법 : 이진수 끝에 아래첨자 (2) 또는 이진수 앞에 0b를 붙여준다.
십육진법
- 수가 15를 넘어가는 시점에 자리 올림을 하는 숫자 표현 방식이다.
- 십진수 10, 11, 12, 13, 14, 15를 십육진법 체계에서는 A, B, C, D, E, F로 표기한다.
- 십육진법을 사용하는 주된 이유 중 하나는 이진수를 십육진수로, 십육진수를 이진수로 변환하기 쉽기 때문이다.
- 십육진수 표현법 : 십육진수 끝에 아래첨자 (16) 또는 십육진수 앞에 Ox를 붙여준다.
02-2. 0과 1로 문자를 표현하는 방법
문자 집합과 인코딩
- 컴퓨터가 인식하고 표현할 수 있는 문자의 모음을 문자 집합이라고 한다.
- 문자를 0과 1로 변환해야 비로소 컴퓨터가 이해할 수 있으며, 이 변환 과정을 문자 인코딩이라고 한다.
- 인코딩 후 0과 1로 이루어진 결과값이 문자 코드가 된다.
- 인코딩의 반대 과정, 즉 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정은 문자 디코딩이라고 한다.
아스키 코드
- 아스키는 초창기 문자 집합 중 하나로, 영어 알파벳과 아라비아 숫자, 그리고 일부 특수 문자를 포함한다.
- 아스키 문자들은 각각 7비트로 표현되는데, 7비트로 표현할 수 있는 정보의 가짓수는 2⁷개로, 총 128개의 문자를 표현할 수 있다.
EUC-KR
- 한국을 포함한 영어권 외의 나라들은 자신들의 언어를 0과 1로 표현할 수 있는 고유한 문자 집합과 인코딩 방식이 필요하다고 생각했다. 이런 이유로 등장한 한글 인코딩 방식이다.
- 한글 인코딩 방식에는 완성형(한글 완성형 인코딩)과 조합형(한글 조합형 인코딩)이 존재한다.
- 완성형 인코딩 방식은 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식이다.
- 조합형 인코딩 방식은 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열을 할당하여 그것들의 조합으로 하나의 글자 코드를 완성하는 인코딩 방식이다. 다시 말해 초성, 중성, 종성에 해당하는 코드를 합하여 하나의 글자 코드를 만드는 인코딩 방식이다.
- EUC-KR은 대표적인 완성형 인코딩 방식이며 2바이트 크기의 코드를 부여한다.
유니코드와 UTF-8
- 유니코드는 EUC-KR보다 훨씬 다양한 한글을 포함하며 대부분 나라의 문자, 특수문자, 화살표나 이뫼콘까지도 코드로 표현할 수 있는 통일된 문자 집합이다.
- 유니코드는 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합이며, 문자 인코딩 세계에서 매우 중요한 역할을 맡고 있다.
- 유니코드의 인코딩 방법 중 가장 대중적인 것은 UTF-8이다.
Chapter 03. 명령어
03-1. 소스 코드와 명령어
고급 언어와 저급 언어
- '사람을 위한 언어'를 고급 언어라고 한다. 우리가 알고 있는 대부분의 프로그래밍 언어가 고급 언어에 속한다.
- 반대로 컴퓨터가 직접 이해하고 실행할 수 있는 언어를 저급 언어라고 한다. 컴퓨터가 이해하고 실행할 수 있는 언어는 오직 저급 언어뿐이다.
- 고급 언어로 작성된 소스 코드가 실행되려면 반드시 저급 언어, 즉 명령어로 변환되어야 한다.
저급 언어의 종류
- 기계어 : 0과 1의 명령어 비트로 이루어진 언어
- 어셈블리어 : 0과 1로 표현된 명령어(기계어)를 읽기 편한 형태로 번역한 언어
컴파일 언어와 인터프리터 언어
컴파일 언어
- 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급 언어이다. 대표적인 컴파일 언어로는 C가 있다.
- 컴파일 언어로 작성된 소스 코드는 코드 전체가 저급 언어로 변환되는 과정을 거치는데 이 과정을 컴파일(compile)이라 하고, 그것을 수행해주는 도구를 컴파일러(compiler)라고 한다.
- 컴파일러를 통해 저급 언어로 변환된 코드를 목적 코드(object code)라고 한다.
인터프리터 언어
- 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어이다. 대표적인 인터프리터 언어로는 python이 있다.
- 소스 코드를 한 줄씩 저급 언어로 변환하여 실행해 주는 도구를 인터프리토(interpreter)라고 한다.
일반적으로 인터프리터 언어는 컴파일보다 느리다.
현대의 많은 프로그래밍 언어 중에는 컴파일 언어와 인터프리터 언어 간의 경계가 모호한 경우가 많다.
03-2 명령어의 구조
연산 코드와 오퍼랜드
명령어는 연산 코드(연산자)와 오퍼랜드(피연산자)로 구성되어 있다. 즉 연산 코드는 '명령어가 수행할 연산'을 말하고, '연산에 사용할 데이터' 또는 '연산에 사용할 데이터가 저장된 위치'를 오퍼랜드라고 한다.
오퍼랜드
- 오퍼랜드 필드에는 숫자와 문자 등을 나타내는 데이터 또는 메모리나 레지스터 주소가 올 수 있다.
- 연산에 사용할 데이터를 직접 명시하기보다는, 많은 경우 연산에 사용할 데이터가 저장된 위치, 즉 메모리 주소나 레지스터 이름이 담긴다.
- 오퍼랜드 필드를 주소필드라고도 부른다.
- 오퍼랜드는 명령어 안에 하나도 없을 수도 있고, 한 개만 있을 수도 있고, 두 개 또는 세 개 등 여러 개가 있을 수도 있다.
연산코드
가장 기본적인 연산 코드 유형은 데이터 전송, 산술/논리 연산, 제어 흐름 변경, 입출력 제어로 나눌 수 있다.
-
데이터 전송
- MOVE: 데이터를 옮겨라
- STORE: 메모리에 저장하라
- LOAD (FETCH): 메모리에서 CPU로 데이터를 가져와라
- PUSH: 스택에 데이터를 저장하라
- POP: 스택의 최상단 데이터를 가져와라 -
산술/논리 연산
- ADD/ SUBSTRACT/ MULTIPLY/ DIVIDE: 덧셈/ 뺄셈/ 곱셈/ 나눗셈을 수행하라.
- INCREMENT/ DECREMENT: 오퍼랜드에 1을 더하라/ 오퍼랜드에 1을 빼라
- AND/ OR/ NOT: AND/ OR/ NOT 연산을 수행하라
- COMPARE: 두 개의 숫자 또는 TRUE/ FALSE 값을 비교하라 -
제어 흐름 변경
- JUMP: 특정 주소로 실행 순서를 옮겨라
- CONDITIONAL JUMP: 조건에 부함할 때 특정 주소로 실행 순서를 옮겨라
- HALT: 프로그램의 실행을 멈춰라
- CALL: 되돌아올 주소를 저장한 채 특정 주소로 실행 순서를 옮겨라
- RETURN: CALL을 호출할 때 저장했던 주소로 돌아가라 -
입출력 제어
- READ(INPUT): 특정 입출력 장치로부터 데이터를 읽어라
- WRITE(OUTPUT): 특정 입출력 장치로 데이터를 써라
- START IO: 입출력 장치를 시작하라
- TEST IO: 입출력 장치의 상태를 확인하라
주소 지정 방식
주소 지정 방식이은 유효 주소를 찾는 방법을 말한다. 유효 주소란 연산 코드에 사용할 데이터가 저장된 위치, 즉 연산의 대상이 되는 데이터가 저장된 위치를 유효 주소라고 한다.
즉시 주소 지정 방식
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식.
- 표현할 수 있는 데이터의 크기가 작아지는 단점이 있지만, 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는 과정이 없기 때문에 이하 설명할 주소 지정 방식들보다 빠르다.
직접 주소 지정 방식
- 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식.
- 오퍼랜드 필드에서 표현할 수 있는 데이터의 크기는 즉시 주소 지정 방식보다 더 커졌지만, 오퍼랜드 필드의 길이가 연산 코드의 길이만큼 짧아져 표현 할 수 있는 유효 주소에 제한이 생길 수 있다.
간접 주소 지정 방식
- 유효 주소의 주소를 오퍼랜드 필드에 명시하는 방식.
- 두 번의 메모리 접근이 필요하기 때문에 앞서 설명한 주소 지정 방식들보다 일반적으로 느리다.
레지스터 주소 지정 방식
- 직접 주소 지정 방식과 비슷하게 연산에 사용할 데이터를 젖아한 레지스터를 오퍼랜드 필드에 직접 명시하는 방식.
- 일반적으로 CPU 외부에 있는 메모리에 접근하는 것보다 CPU 내부에 있는 레지스터에 접근하는것이 더 빠르기 때문에 레지스터 주소 지정 방식은 직접 주소 지정 방식보다 빠르게 데이터에 접근 할 수 있다.
- 다만, 표현할 수 있는 레지스터 크기에 제한이 생길 수 있다는 직접 주소 지정 방식과 비슷한 문제를 공유한다.
레지스터 간접 주소 지정 방식
- 연산에 사용할 데이터를 메모리에 저장하여 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방식.
- 유효 주소를 찾는 과정이 간접 주소 지정 방식과 비슷하지만, 메모리에 접근하는 횟수가 한 번으로 줄어든다는 차이이자 장점이 있다.
📌기본미션: p.51 확인 문제 3번, p.65 확인 문제 3번 풀고 인증하기
p.51 확인 문제 3번

p.65 확인 문제 3번
📌선택미션: p.100 스택과 큐의 개념을 정리하기
스택(stack)이란 한쪽 끝이 막혀있는 통과 같은 저장 공간이다. 데이터를 차곡차곡 저장하고, 저장한 자료를 빼낼 때는 마지막응로 저장한 데이터부터 빼낸다. 스택은 '나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식(후입선출)'이라는 점에서 LIFO 자료 구조라고도 부른다.
이때 스택에서 새로운 데이터를 저장하는 명령어가 PUSH, 스택에 저장된 데이터를 꺼내는 명령어가 POP이다.
스택과 달리 양쪽이 뚫려 있는 통과 같은 저장 공간을 큐(queue)라고 한다. 큐는 한쪽을오는 데이터를 저장하고, 다른 한쪽으로는 먼저 저장한 순서대로 데이터를 빼낸다. 큐는 '가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식(선입선출)'이라는 점에서 FIFO 자료 구조라고도 부른다.
