
Redis programming patterns
Redis 개발 패턴
Bulk Loading
Redis 프로토콜을 이용하여 대량으로 쓰기 작업을 하는 패턴
하나의 명령을 차례로 전송하여 연산을 하는 경우, 모든 명령의 RTT가 포함되어 있기 때문에 속도가 느리기 때문에 일반적인 Redis Client를 통해 대량으로 쓰기 작업(load)을 하는 것을 권장하지 않는다.
Pipelining을 통해 다량의 명령을 빠르게 수행할 수 있지만 대량의 데이터 쓰기 작업과 응답을 읽는 작업이 동시에 진행되어야 한다.
또, 적은 비율의 클라이언트에서만 non-blocking I/O를 지원하기 때문에 모든 클라이언트에서 bulk쓰기 처리량을 최대화 하기 위해선 Redis 프로토콜이 포함된 text 파일을 생성 후 전송하는 방법이 있다.
예를 들어, 수십억 개의 데이터를 추가하고자 할 때, 해당 명령이 포함된 파일을 Redis 프로토콜 형식으로 생성 하고 Redis에 전송하면 된다.
redis-cli의 pipe mode를 통해 전달 가능하다.
SET Key0 Value0
SET Key1 Value1
...
SET Key100000000 Value100000000> cat data-insert.txt | redis-cli --pipe
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 1000000netcat을 통해 전달도 가능하지만, 응답 여부나 오류 발생 여부를 확인 할 수 없어서
--pipe를 통해 전달하는 것을 권장한다
Redis protocol은 아래 예시처럼 작성 할 수 있다.
*<args><cr><lf>
$<len><cr><lf>
<arg0><cr><lf>
<arg1><cr><lf>
...
<argN><cr><lf>SET keyA valueA 를 프로토콜로 작성하면 아래와 같다.
*3<cr><lf> # *3은 인자의 개수가 3개
$3<cr><lf>
SET<cr><lf>
$4<cr><lf> # "keyA"의 길이
keyㅁ<cr><lf>
$6<cr><lf>
valueA<cr><lf> # "valueA"의 길이Java에서 사용하면 아래와 같이 만들 수 있다.
public String generateRedisProtocol(String... cmd) {
StringBuilder proto = new StringBuilder();
proto.append("*").append(cmd.length).append("\r\n");
for (String arg : cmd) {
proto.append("$").append(arg.getBytes().length).append("\r\n");
proto.append(arg).append("\r\n");
}
return proto.toString();
}
generateRedisProtocol("SET", "keyA", "valueA", "SET", "key", "value);Distributed locks
분산락으로 사용하기
분산락이란 서로 다른 프로세스에서 공유 자원에 접근할 때, 원자성을 보장하기 위해 사용하는 방법
Redis로 DLM(Distributed Lock Manager)을 구현한 여러 라이브러리가 존재하고, Java의 구현체는 Redisson이 있다.
Docs에서는 Redis로 분산 잠금을 어떻게 구현하는 지 보단 표준적인 알고리즘에 대해 설명하고 있다.
Safety and Liveness Guarantees
Redis에선 분산락을 구현 할 때, 최소한 세가지 속성을 보장하며 설계한다고 한다.
Safety property: 하나의 클라이언트만 락 획득이 가능 하다.Liveness property A: Deadlock free. 리소스가 잠겨있거나 클라이언트간 충돌이 발생해도 결과적으로 항상 락을 획득 가능 하다.Liveness property B: 내결함성. Redis 노드가 가동 중인 한, 클라이언트는 잠금을 획득하고 해제할 수 있다.https://en.wikipedia.org/wiki/Safety_and_liveness_properties
Why Failover-based Implementations Are Not Enough
장애조치 기반 구현이 부족한 이유.
일반적은 Redis 기반 분산락 라이브러리의 현재 상황에 대해 살펴보자.
일반적으로 키를 생성하여 락을 구현하고, 만료 기능(expire)를 통해 유효 기간을 설정하여 락을 해제하는 식으로 구현된다.
이러한 구현 방식은 일반적으로 잘 동작하지만, SPOF가 존재한다. 만약 master redis다 다운되는 상황에서 비동기로 replica되기 때문에 안전성 보장이 깨질 수 있다.
아래 예시를 보면,
- ClientA 가 마스터에서 잠금을 획득한다.
- 특정키에 대한 쓰기가 복제본으로 relica 되기 전에 다운 된다.
- 복제본이 승격 된다.
- ClientB가 특정키에 대해 접근하며 락을 획득한다.
=> ClientA와 ClientB가 모두 락을 획득하는 안전성 보장이 깨지게 된다.
Redis에선 이러한 상황을 개선하는 방식을 제안한다.
Correct Implementation with a Single Instance
단일 Redis 환경에서 구현하기
제일 간단하게 락을 구현하는 방법은 아래와 같이 NX와 PX옵션을 통해 키를 생성하는 것이다.
SET resource_name random_value NX PX 30000
위 명령을 통해 key가 존재하지 않은 경우에만 생성하며, 30초의 유효시간을 가진다. 이때 값은 유니크한 값이어야 한다. 유니크한 랜덤값으로 락을 점유한 client와 락을 해제하려는 client가 동일하게 보장하기 위함이다.
기본적으로 Lua를 통해 락을 생성한 client만이 해당 락을 해제하는 로직을 작성 할 수 있다.
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endStandAlone 환경에서는 비교적 간단하게 lock을 구현 할 수 있다.
The Redlock Algorithm
StandAlone이 아닌 한개의 여러 Redis가 운영되는 환경에서는 RedLock 알고리즘을 통해 분산락을 구현 할 수 있다. 여러 Redis master로 운영되는 환경에서는 각각의 노드들은 독립적이며 복제나 조정 시스템은 없다고 가정한다.
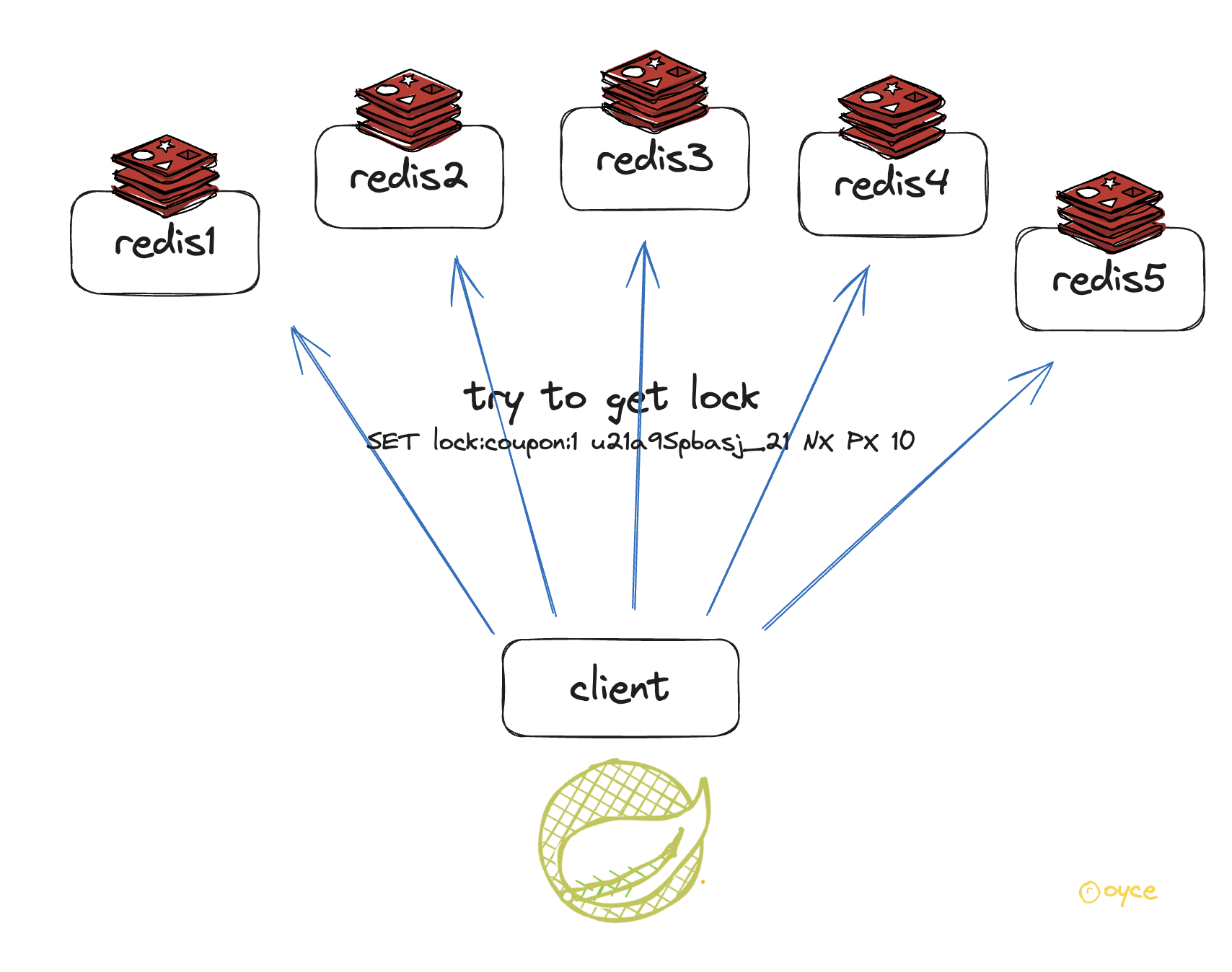
분산 환경에서 분산락을 획득하기 위해 클라이언트는 다음 작업을 수행 한다.
- 락 획득을 시도하려고 하는 현재 시간을 밀리초 단위로 가져온다.
- 모든 Redis 인스턴스에 순차적으로 잠금을 획득 요청을 보낸다.
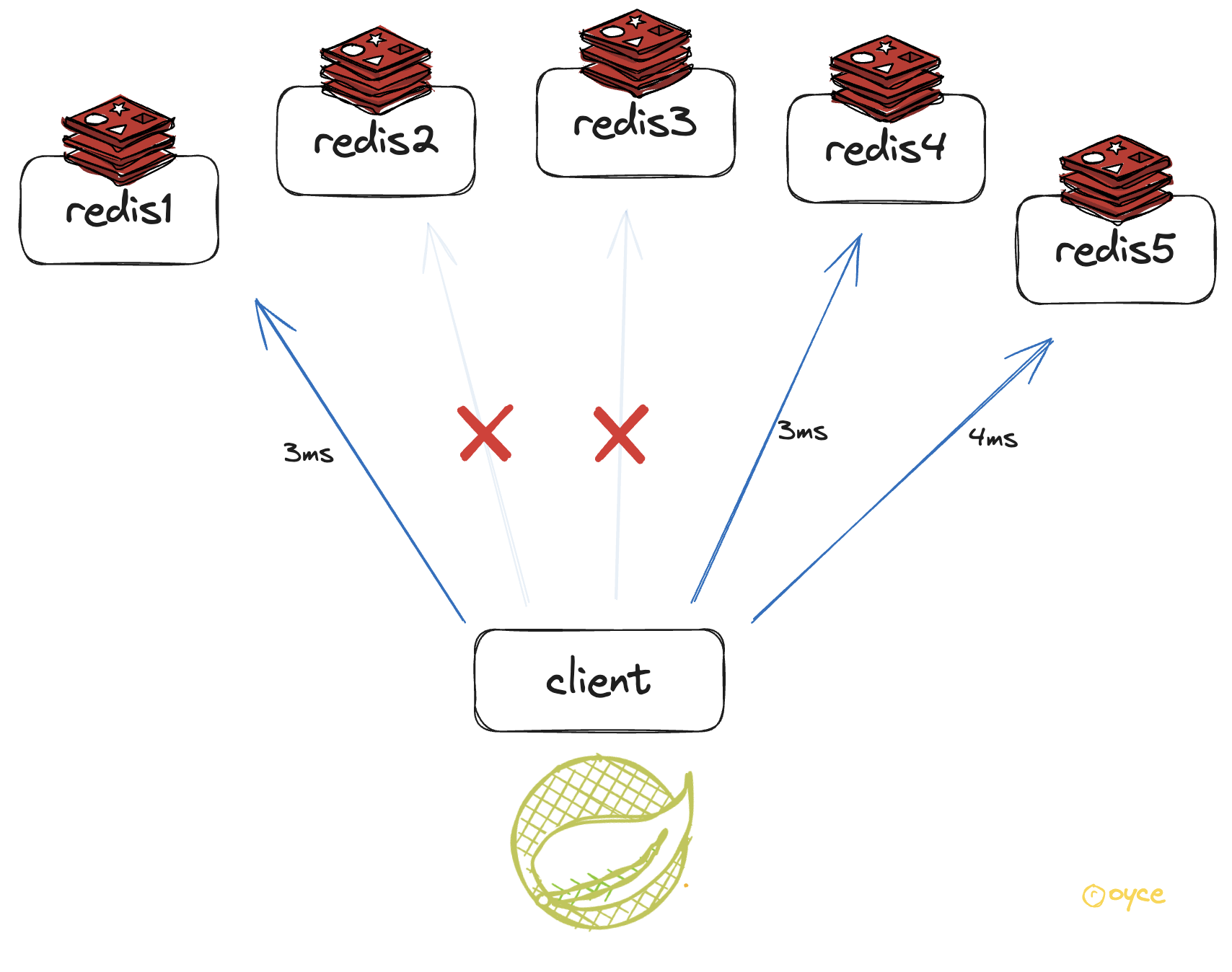
- 1번 단계에서 얻은 시간과 락 획득 요청 응답이 온 시간으의 차이를 통해 경과한 시간을 구한다.
- Client가 Redis노드로부터 특정 수치 이상의 잠금을 획득 하고, 락을 획득 하기까지 경과한 총 시간이 키 유효시간보다 적은 경우 잠금을 획득한 것으로 간주한다.
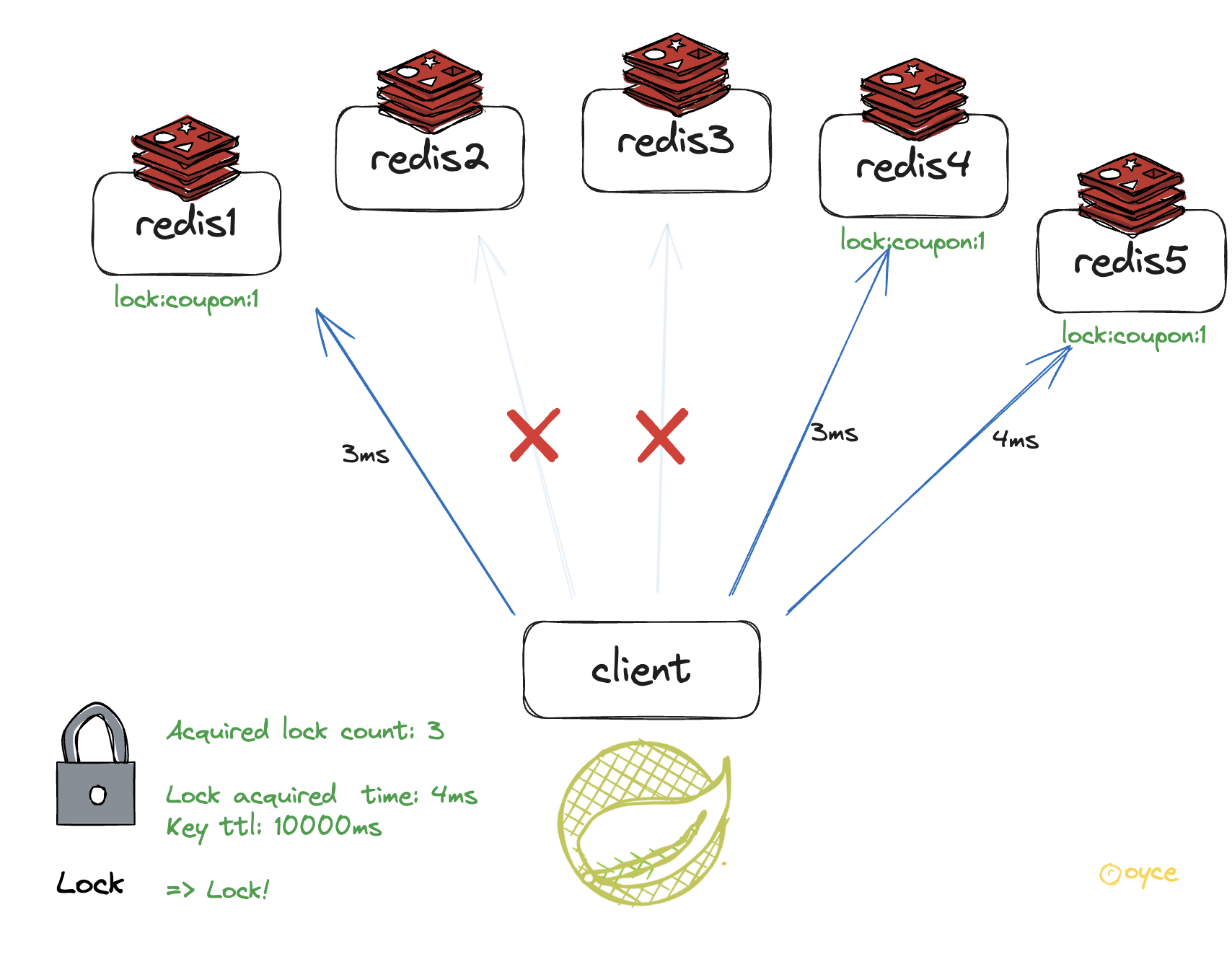
- 잠금을 획득한 경우, 잠금의 유효 시간은 3단계에서 계산한 대로 초기 유효 시간에서 경과 시간을 뺀 값으로 간주 한다.
- 만약 Client가 잠금을 획득하지 못한 경우, 클라이언트는 모든 인스턴스의 잠금을 해제한다.
이 과정에서 시간
락 획득을 위해 모든 Redis 노드에 락 획득 요청을 보낸다.
락 획득 요청 결과
위 그림처럼, 5개의 노드중에 3개의 노드로부터 락을 획득하고 지정한 키 만료 시간보다 획득하는데 적은 시간이 경과된 경우 이 클라이언트는 락을 획득 한 것으로 간주한다.
기존 락 유효시간(10,000ms) + 락을 얻는데 걸린 시간인 (4ms) 을 합하여 락 유효시간을 설정합니다.
Redlock 알고리즘은 각 클라이언트와 Redis 노드간의 시계가 동일하게 작동하는 것을 가정하고 동작하므로, 실제 환경에서는 동기화된 시계에 대해서도 고려하여야 한다.
클라이언트가 락을 획득하지 못한 경우 무작위 지연 시간 후에 다시 시도한다. 또, 클라이언트들은 여러 노드에 대한락 획득 시도가 빠를 수록 락을 획득할 가능성이 높아지므로 멀티플렉싱을 통해 N개의 Redis에 SET명령을 수행하는 것이 이상적이다.
Performance, Crash Recovery and fsync
기본적으로 락 획득 요청을 멀티플렉싕하여 지연 시간을 줄여 성능을 높힐 수 있다. 이 과정에서 분산 Redis 환경에서 장애가 발생하면 고려해야 할 상황이 있다.
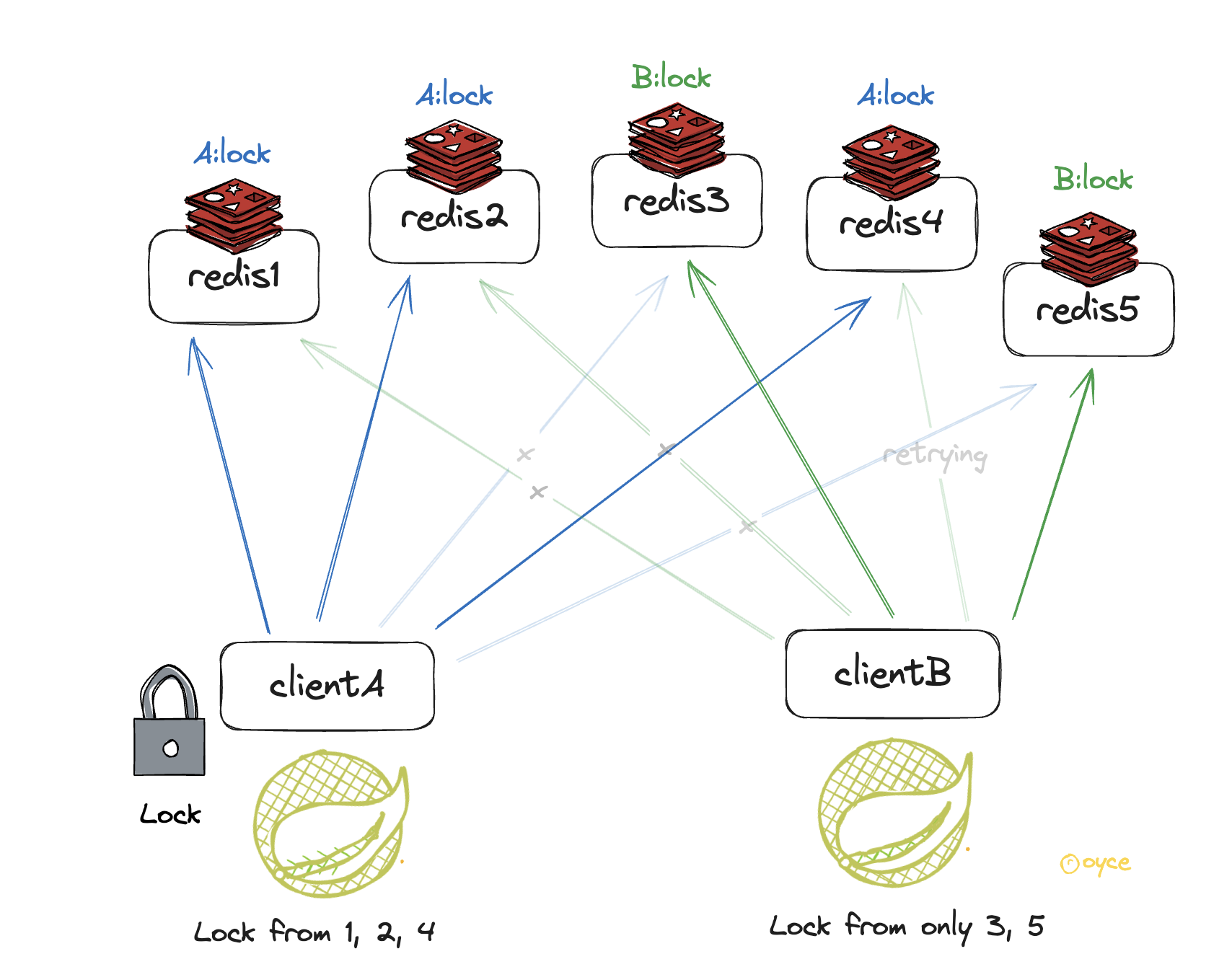
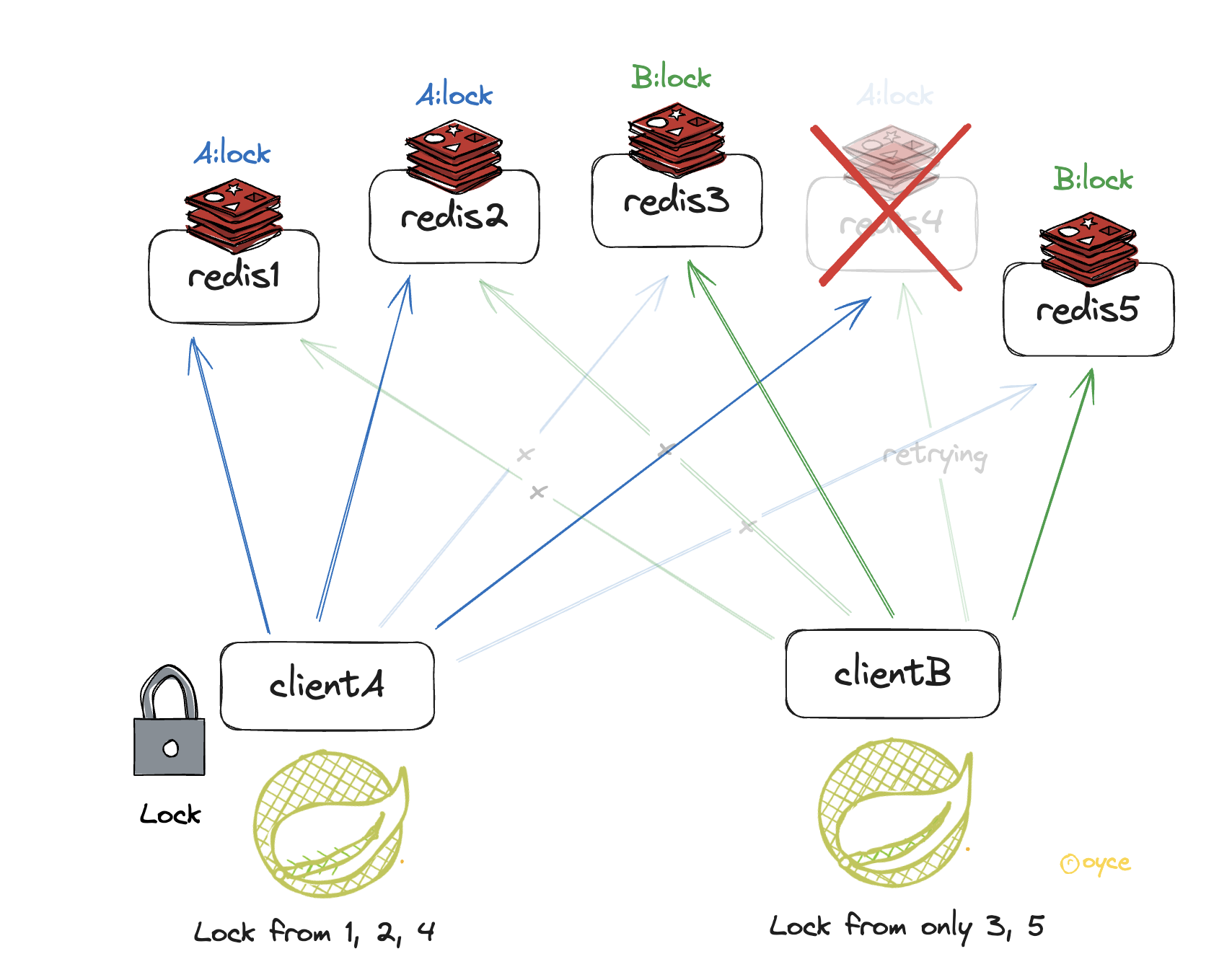
5개의 Redis 노드에서 ClientA가 3개의 노드(A, B, C)로부터 Lock을 얻어 분산락을 획득했다고 해보자.
이 상황에서 Redis 노드 3번이 종료되어 key가 휘발되어 사라졌고, 다시 복구되어 실행 되었다.
이때, ClientB가 2개의 노드(D, E)로부터 락을 얻었고 방금 재부팅된 C에서도 락을 획득하여 (총 3개) 분산락을 획득 할 수 있다.
ClientA와ClientB가 분산 Redis환경에서 분산락 획득을 시도한다.
5개중에 3개를 획득한 A가 결과적으로 분산락을 획득했고, B는 재시도 과정을 수행중이다.
ClientA가 락을 가지고 작업을 수행하는 중, Redis node4번이 다운 된다. A가 락으로 설정한 KeyA가 휘발된다.
node4번의 장애가 복구 되었다. 이때,ClientB가 복구된 node4번으로부터 락을 획득하였고, 총 3개의 락을 얻은 B도 분산락을 얻게되는 락 안전성이 깨지게 된다.
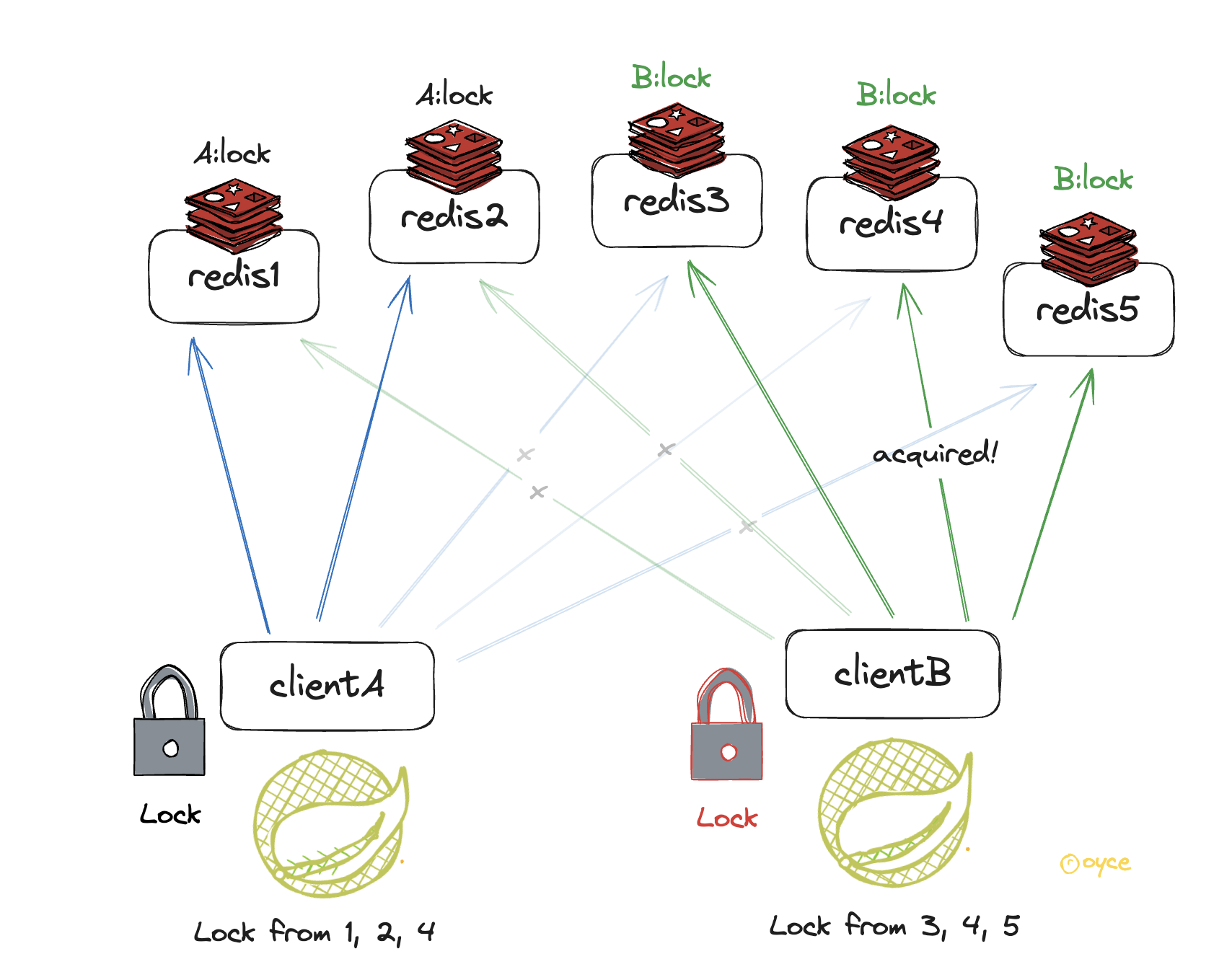
이런 경우 AOF를 통해 개선하거나 fsync=always옵션을 통해 락에 대한 안전성을 보장할 수 있다. 이 과정에서 성능에 영향을 미칠 수 있다.
위 그림에서 Redis node4번이 복구 될 때, 쓰기 작업이 수행된 키도 휘발되지 않고 복구하며 실행 된다면 ClientB는 락을 획득 하지 못하게 된다.
다른 방법으로는 다운된 Redis노드를 일반적인 키 만료 시간보다 더 늦게 사용할 수 있도록 구성하면 된다.
키의 만료시간이 10초라면, Redis node4의 복구를 10초 이후에 하여 락이 해제 되는 시간을 보장하는 것이다.
이런 경우, 안전성을 위해 성능 저하가 발생하게 되는데 이 부분을 고려하여 운영 환경에 맞게 구성하면 될 것 같다.
Secondary indexing
Redis는 정확하게 key-value 형태의 스토리지라기 보단 더 복잡한 데이터 구조를 가지고 있으며 API 수준에서는 Key를 기준으로 주소가 지정된다. 기본적으로는 Key를 통한 데이터 접근만 제공하긴 하지만, 복합인덱스를 비롯한 여러 Secondary index를 사용할 수 있다.
Redis에서 인덱스를 구현하고 유지하는 것을 고려하기 전에 복잡한 쿼리가 필요한 경우 관계형DB가 더 나은지 고려할 필요가 있다.
Simple numeric indexes with sorted sets
가장 쉽게 Secondary index를 구현하는 방법은 각 요소에 점수(숫자)를 할당하고, 해당 점수로 정렬된 데이터를 사용하는 것이다. => (Sorted set)
ZADD, ZRANGE, BYSCORE의 키워드를 통해 이러한 종류의 인덱스를 구축하고 검색 할 수 있다.
예를 들어, 나이와 이름을 저장한 데이터에서 나이를 통해 조회를 하고 싶은 경우 아래와 같이 구성 할 수 있다.
> ZADD myindex 25 Manuel
> ZADD myindex 18 Anna
> ZADD myindex 35 Jon
> ZADD myindex 67 Helen
> ZRANGE myindex 20 40 BYSCORE # 나이를 통해 조회
1) "Manuel"
2) "Jon"REV를 통해 역순으로 범위 검색도 가능하다.
Using objects IDs as associated values
Sorted Set에서 제공하는 score numberic이 아닌 필드를 인덱싱 하려면 아래처럼 사용 가능하다.
> HMSET user:1 id 1 username antirez ctime 1444809424 age 38
> HMSET user:2 id 2 username maria ctime 1444808132 age 42
> HMSET user:3 id 3 username jballard ctime 1443246218 age 33
> ZADD user.age.index 38 1
> ZADD user.age.index 42 2
> ZADD user.age.index 33 3user.age.index를 통해 찾고자 하는 userId를 조회 한 뒤, 해당 아이디로 Set에서 데이터를 검색 할 수 있다.
값을 변경해야 하는 경우, 두 key에 모두 반영해야 한다.
HSET user:1 age 39
ZADD user.age.index 39 1Lexicographical indexes
숫자 뿐만 아니라 사전식 정렬을 통해서도 구현 할 수 있다. Redis는 내부적으로 문자열을 memcmp()을 통해 바이너리 데이터를 비교한다. foo < foobar가 더 크다.
> ZADD myindex 0 baaa
> ZADD myindex 0 abbb
> ZADD myindex 0 aaaa
> ZADD myindex 0 bbbbSorted Set에서는 score가 동일하면 value의 값으로 정렬된다.
> ZRANGE myindex 0 -1
1) "aaaa"
2) "abbb"
3) "baaa"
4) "bbbb"BYSCORE 대신, BYLEX를 통해 사전순 범위 검색이 가능하다.
> ZRANGE myindex [a (b BYLEX
1) "aaaa"
2) "abbb"[는 inclusive, (는 exclusive 이다.
위 구문은 a <= value < b 의 값을 조회하는 것으로 볼 수 있다.
+ 와 - 도 제공되는 특수 문자이다.
ZRANGE myindex [b + BYLEX
1) "baaa"
2) "bbbb"이런 속성을 활용해서 다양한 방법으로 인덱스를 사용할 수 있다.
Composite indexes
다른 RDBMS에서 그렇듯, 여러 필드에 대한 인덱스도 구성 할 수 있다.
방의 가격과 방의 상품 검색을 위해 인덱스를 구성한다면 아래와 같이 구성 할 수 있다.
만약 room:price:product_id를
> ZADD myindex 0 0056:0028.44:90
> ZADD myindex 0 0034:0011.00:832
> ZRANGE myindex [0056:0010.00 [0056:0030.00 BYLEXZRANGE를 통해 56번 방에 있는 모든 제품의 가격이 10달러에서 30달러 사이인 제품을 매우 쉽게 얻을 수 있다.
