
📄 목차
- 데이터 정리
- 무의미한 정보 없애기
- pivot_table 활용
- 인덱스 설정
- value 설정
- column 설정
- aggfunc 활용
- 기타 기능
- pip, conda 명령
- 반복문 이용하여 데이터 정리
- Seaborn
1. 데이터 정리
무의미한 정보 없애기
- 데이터에 자리만 차지하는, 즉 정보가 없는 빈칸의 행/열들이 존재할 수 있음 이를 정리하는 과정


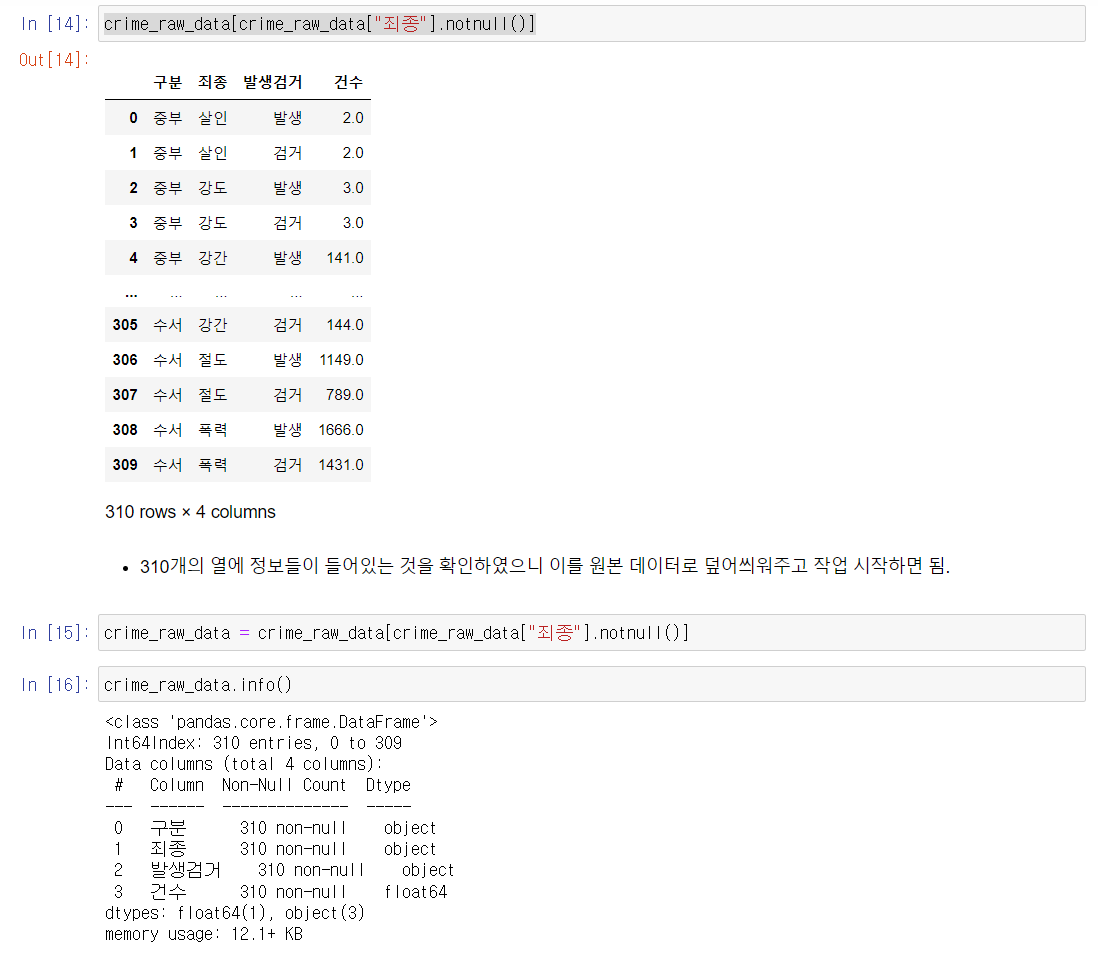
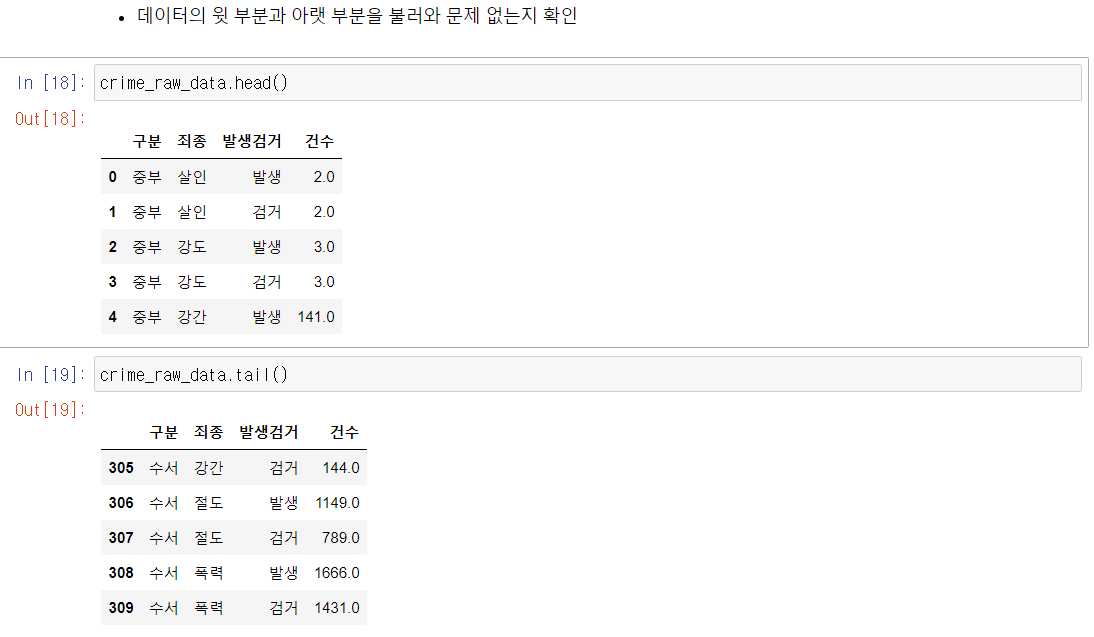
- 데이터를 불러 .info()로 먼저 확인
- 데이터 열 중에서 특정 값을 불러서 isnull() 확인 (null/NaN이면 True 반환함)
- 반대로 notnull() 이용하여 유의미한 데이터 확인
- 다시 변수에 dataName [ dataName [ "열 이름 ] .notnull() ] 할당하여 데이터 변경 후 사용
pivot_table 활용
- .pivot_table(index="", columns="", values="", aggfunc="")
- 먼저 특정 변수로 데이터를 불러온 상황하에 진행

- 특정 column을 인덱스롤 설정하는 방법
- pd.pivot_table(변수, index="columnName")
- 변수.pivot_table(index="columnName")
- 멀티 인덱스 설정
- 변수.pivot_table(index=["columnName1", "columnName2"])
- 인덱스로 삼을 컬럼 이름을 리스트 안에 넣으면 됨.
- Value 설정 (보이고 싶은 특정 값들)
- index와 마찬가지로 특정하게 보이고 싶은 열 이름을 넣어주면 됨.
- aggfunc을 넣어주지 않으면 기본 mean을 반환함
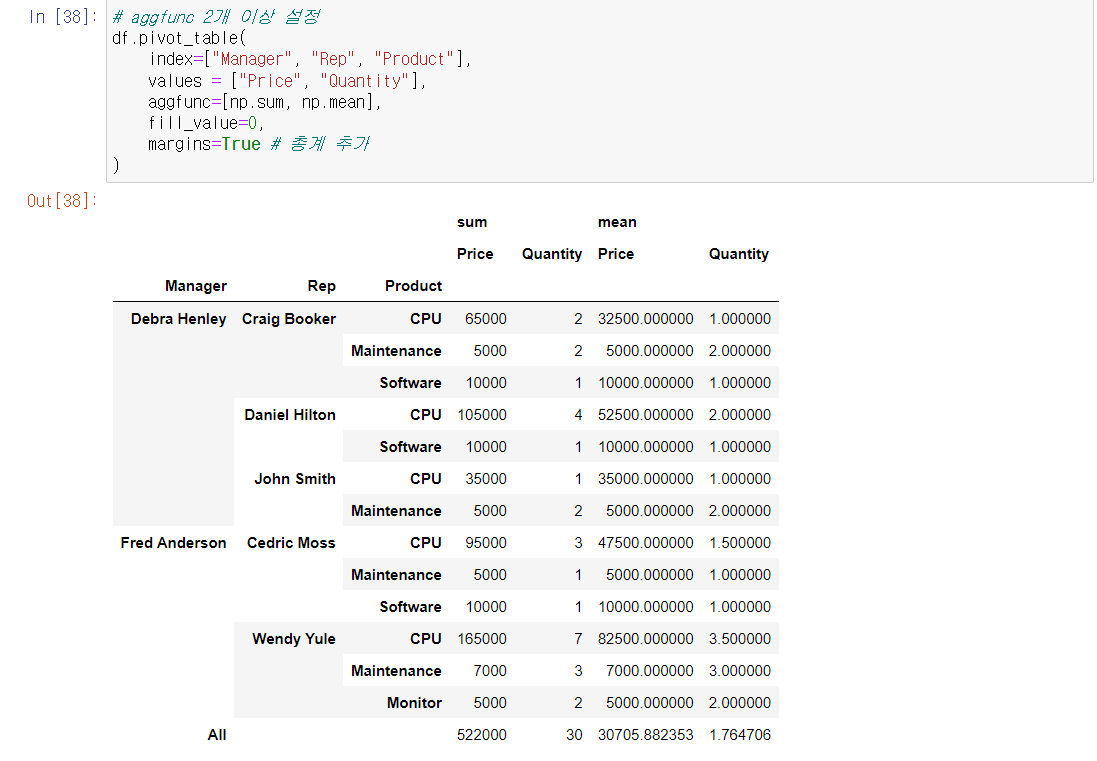
- 멀티 인덱스처럼 2개 이상 설정 가능
- columns 설정 (보이고 싶은 열들)
- index와 마찬가지로 보이고 싶은 열의 이름을 넣으면 됨. 각 값들이 어떤 내용과 관련되어 있는지 보여줌.
- aggfunc 설정 (값 가공)
- aggfunc=np.sum을 이용하면 해당 인덱스와 관련된 모든 값을 더하여 보여줌
- 멀티 인덱스처럼 2개 이상 설정 가능
- 기타 기능
- fill_value=""
- NaN이 반환되는 칸에 원하는 값을 집어넣음
- margins=True
- 값들의 총계를 가장 마지막에 추가함
- fill_value=""
2. pip, conda명령
pip 명령
- python 공식 모듈 관리자
- pip list: 현재 설치된 모듈 리스트 반환
- pip install moduleName: 모듈 설치
- pip uninstall moduleName: 모듈 삭제
conda 명령
- 아나콘다 환경을 사용할 때 사용
pip를 사용하면 conda 환경에서 관리가 정확하지 않을 수 있으므로, 아나콘다 환경을 사용할 경우에는 가급적 conda 명령으로 모듈 관리 추천.- conda list: 설치된 모듈 리스트
- conda install moduleName: 모듈 설치
- conda uninstall moduleName: 모듈 제거
- conda install -c channelName moduleName: 지정된 배포 채널에서 모듈 설치
- 모든 모듈이 깔끔하게 설치되지는 않음
- 서울시 구별 데이터를 정리하는데, 지역구에 대한 데이터가 필요하여 google cloud 와 geocoding api 등을 이용함.
- conda 환경에서 google maps를 활용하기 위해서는 해당 모듈을 다운로드 받으면 됨.
- gmaps.geocode("장소 이름", language="ko") 사용하면 원하는 장소의 주소와 geological info들이 나옴.
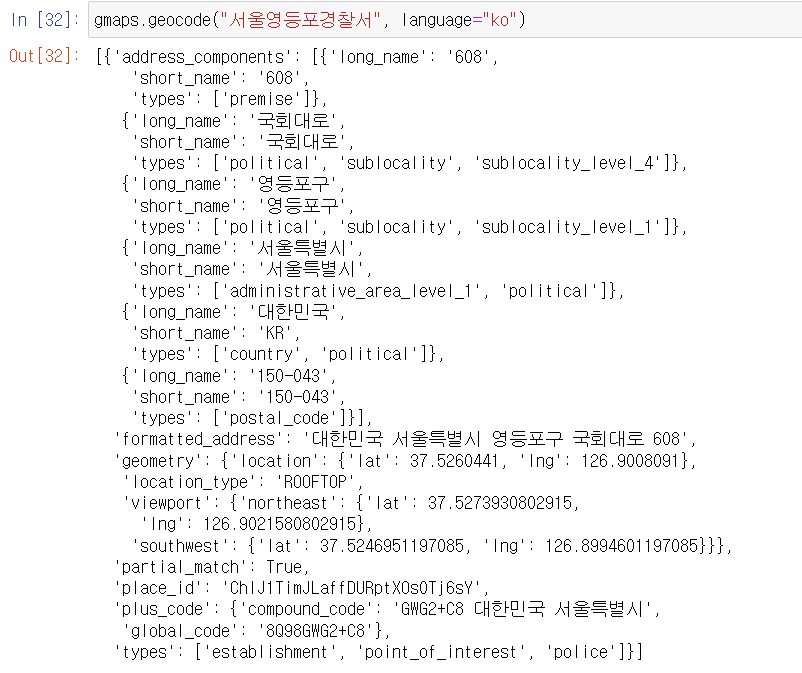
- 우리는 여기서
- formatted_address >> 구 이름 가져오기 위해
- location[lat], location[lng] 를 가져옴
- 우리는 여기서
3. 반복문 이용하여 데이터 정리
- pandas의 데이터 프레임은 대부분 2차원
- .iterrows()를 사용하면 편리함
- e.g. for idx, cont in dataName.iterrows():
- columnName을 변경하기 위해 for문을 사용하였음

- dataName.columns.get_level_values(level)[idx] 형식임.
- 맨 위가 0 레벨, 그 다음이 1레벨...
- 맨 왼쪽은 index이므로 제외되는 것 유의.
4. Seaborn
- seaborn은 import하는 것만으로도 효과를 줌
- 보통 sns로 import함.
- seaborn.set_style("white")
- 바탕 흰색, 그리드 없앰
- seaborn.set_style("dark")
- 바탕 어두운색, 그리드 없앰
- seaborn.set_style("whitegrid")
- 바탕 흰색, 그리드 有
- seaborn.despine()
- 그래프 테두리 좌측, 아래만 남김
- seaborn에는 실습용 데이터가 몇 가지 내장되어 있음. (eg. tips, flights, iris...)
- seaborn.boxplot()
- boxplot() 괄호 안에 x, y값, 데이터 지정 가능
- hue="" 구분 지어줌
- palette= "" 색상 코드 입력
- seaborn.swarmplot()
- 내부 내용은 boxplot과 비슷함
- 다만 데이터를 점 형식으로 나열해줌
- 통계 지표를 보일 때 boxplot과 같이 쓰이면 효과적 (둘 다 장단점이 있기에...)
- seaborn.lmplot()
- 경향성 파악할 때 사용되는 그래프
- seaborn.heatmap()
- 전체 경향 파악할 떄 사용되는 그래프
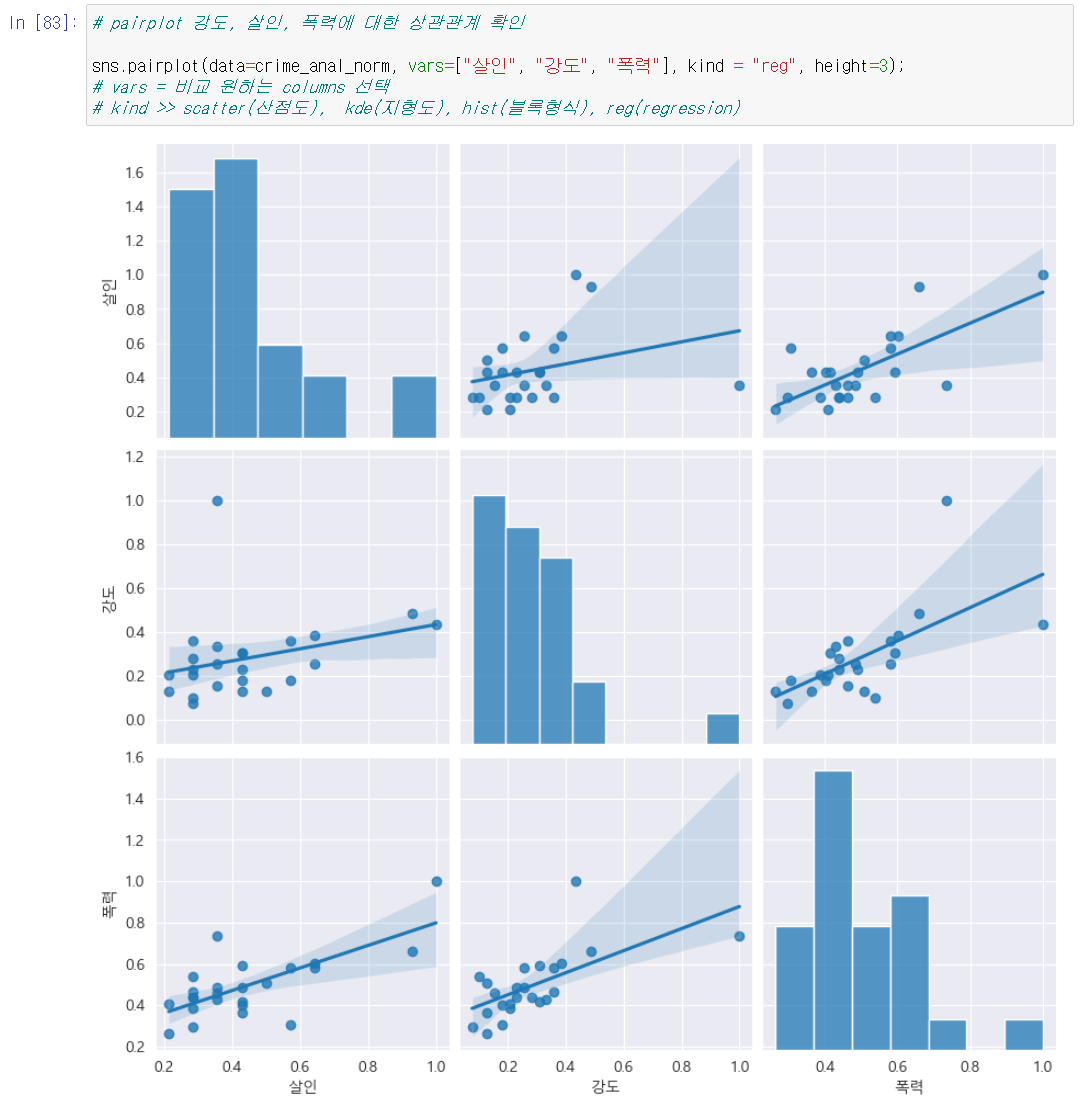
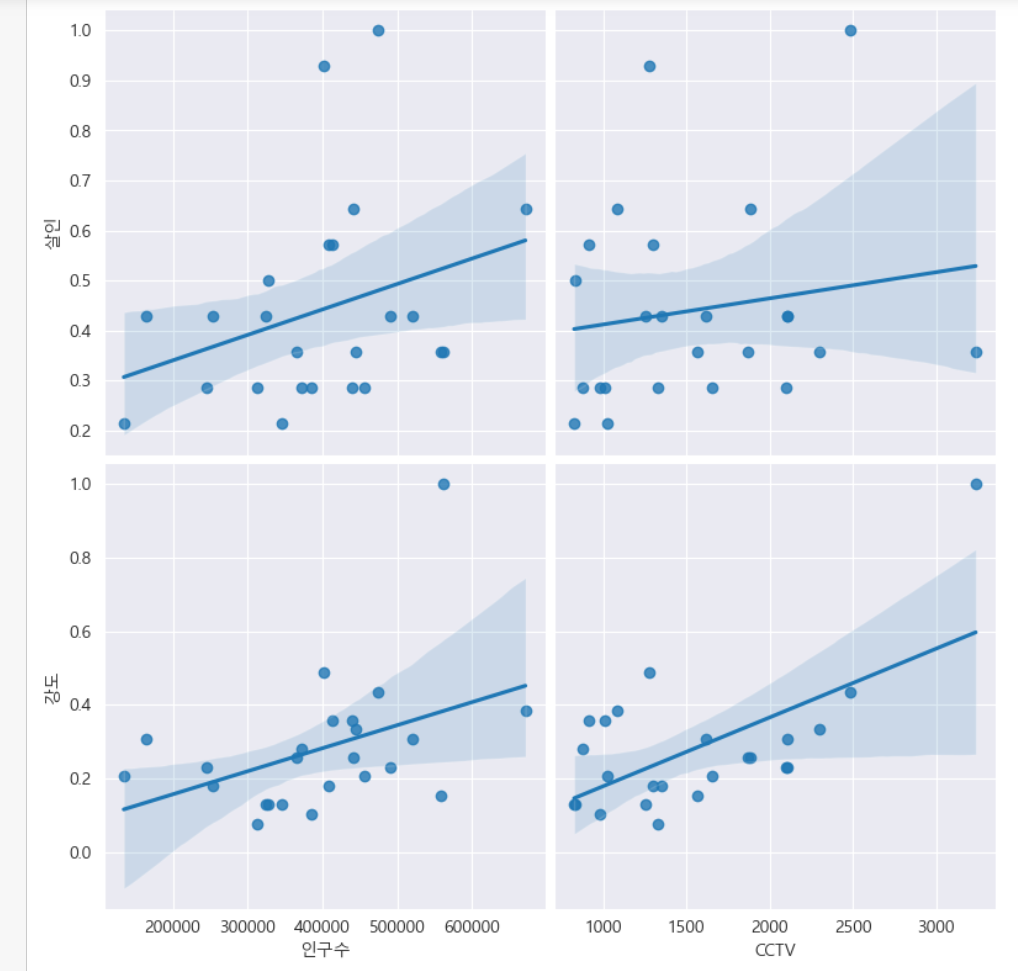
- seaborn.pairplot()
- 다수의 컬럼을 비교하는 함수

- hue로 데이터 구분지었을 때, 다양한 색깔로 표시 됨.
- 원하는 컬럼만 pairplot 할 수도 있음
- 다수의 컬럼을 비교하는 함수
- Jupyter Notebook에서 진행한 실습



새싹 데이터 분석가 https://github.com/KulangK