
1. EarlyStopping
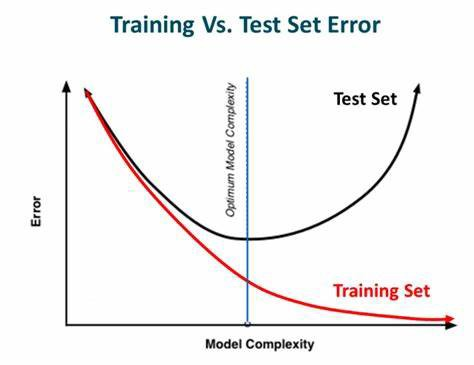
모델 학습 중에 기준점을 두어 기준점 동안 유의미하게 성능이 좋아지지 않을 때 학습을 종료하는 기능이다.
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from sklearn.model_selection import train_test_split
import tensorflow as tf
import numpy as np
import keras, os
# 데이터 불러오기
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
print(X_train.shape, X_test.shape)
# 데이터 정규화
X_train = X_train / 255.
X_test = X_test /255.
# 검증 데이터 셋 만들기
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=.25, random_state=2)
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
# 학습시킨 데이터를 저장
checkpoint_filepath = "FMbest.hdf5"
# overfitting을 방지하기 위해서 학습 중 early stop을 수행하기 위해 earlystop 정의
# Validation Set의 손실 함수를 기준으로 10회 이상 성능이 좋아지지 않을시 학습을 종료함
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
# Validation Set의 손실 함수를 기준으로 최적의 모델 저장
save_best = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath, monitor='val_loss', verbose=1, save_best_only=True,
save_weights_only=True, mode='auto', save_freq='epoch', options=None)
# 모델 학습 코드 + early stop + Best model
model.fit(X_train, y_train, batch_size=64, epochs=100, verbose=1,
validation_data=(X_val,y_val),
callbacks=[early_stop, save_best])2. Weight Decay
가중치가 너무 커지는 것을 방지하고 감소시켜 두어 훈련 데이터에 과적합을 하지 않도록 해주는 기술이다.
규제 방법
L1, L2에 대한 설명 참고자료1
L1, L2에 대한 설명 참고자료2
from tensorflow.keras import regularizers
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64,
kernel_regularizer=regularizers.l2(0.01), # L2 norm regularization
activity_regularizer=regularizers.l1(0.01)), # L1 norm regularization
Dense(10, activation='softmax')
])
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=10, verbose=1,
validation_data=(X_val,y_val))다음과 같이 Dense layer에 규제방법을 추가해준다.
3. Weight Constraints
가중치의 크기를 제한하여 특정 데이터에 과적합 되는 것을 방지한다.
from tensorflow.keras.constraints import MaxNorm
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01),
kernel_constraint=MaxNorm(2.)), ## add constraints
Dense(10, activation='softmax')
])
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=10, verbose=1,
validation_data=(X_val,y_val))kernel_constraint의 파라미터로 추가해준다.
4. Dropout
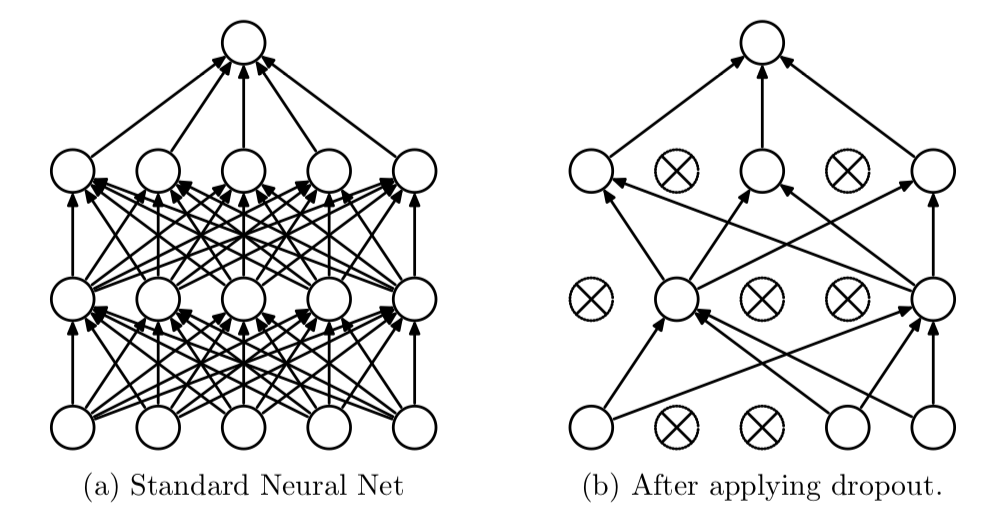
앞의 방식들과 다르게 Layer를 추가하는 방식을 사용한다.
확률적으로 노드 연결을 강제적으로 끊어 임시로 차단된 상태에서 결과를 예측하게 한다.
from tensorflow.keras.layers import Dropout
from tensorflow.keras.constraints import MaxNorm
from tensorflow.keras import regularizers
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64,
kernel_regularizer=regularizers.l2(0.01), ## l2 regularizaion
activity_regularizer=regularizers.l1(0.01), ## l1 regularizaion
kernel_constraint=MaxNorm(2.)), ## constraint
Dropout(0.5), ## add dropout 0.5 == 50% node off
Dense(10, activation='softmax')
])
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
model.summary()
model.fit(X_train, y_train, batch_size=30, epochs=10, verbose=1,
validation_data=(X_test,y_test))
조금씩 천천히